(数据科学学习手札126)Python中JSON结构数据的高效增删改操作
本文示例代码及文件已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
在上一期文章中我们一起学习了在Python中如何使用jsonpath库,对JSON格式数据结构进行常规的节点条件查询,可以满足日常许多的数据处理需求。
而在上一期结尾处,我提到了还有其他JSONPath功能相关的进阶Python库,在今天的文章中,我就将带大家学习更加高级的JSON数据处理方式。

2 基于jsonpath-ng的进阶JSON数据处理方法
jsonpath-ng是一个功能强大的Python库,它整合了jsonpath-rw、jsonpath-rw-ext等第三方JSONPath拓展库的实用功能,使得我们可以基于JSONPath语法,实现更多操纵JSON数据的功能,而不只是查询数据而已,使用pip install jsonpath-ng进行安装:
2.1 JSON数据的增删改
jsonpath-ng中设计了一些方法,可以帮助我们实现对现有JSON数据的增删改操作,首先我们来学习jsonpath-ng中如何定义JSONPath模式,并将其运用到对数据的匹配上,依然以上篇文章的数据为例:
import json
from jsonpath_ng import parse
# 读入示例json数据
with open('json示例.json', encoding='utf-8') as j:
demo_json = json.loads(j.read())
# 构造指定JSONPath模式对应的解析器
parser = parse('$..paths..steps[*].duration')
# 利用解析器的find方法找到目标数据中所有满足条件的节点
matches = parser.find(demo_json)
# 利用value属性取得对应匹配结果的值
matches[0].value

而基于上面产生的一些对象我们就可以实现对JSON数据的增删改:
2.1.1 对JSON数据进行增操作
在jsonpath-ng中对JSON数据添加节点,思想是先构造对原先不存在的节点进行匹配的解析器对象,利用find_or_create方法处理原始JSON数据:
# 构造示例数据
demo_json = {
'level1': [
{
'level2': {}
},
{
'level2': {
'level3': 12
}
}
]
}
# 构造规则解释器,所有除去最后一层节点规则外可以匹配到的节点
# 都属于合法匹配结果,会在匹配结果列表中出现
parser = parse('level1[*].level2.level3')
matches = parser.find_or_create(demo_json)
demo_json
在find_or_create操作之后,demo_json就被修改成下面的结果:

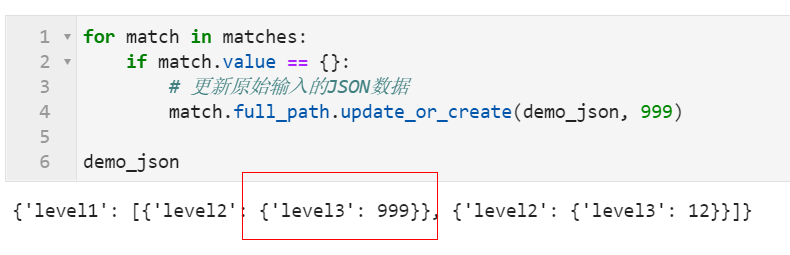
接下来的事情就很简单了,只需要在matches结果中进行遍历,遇到value属性为{}的,就运用full_path.update_or_create()方法对原始JSON数据进行更新即可,比如这里我们填充999:
for match in matches:
if match.value == {}:
# 更新原始输入的JSON数据
match.full_path.update_or_create(demo_json, 999)
demo_json
2.1.2 对JSON数据进行删操作
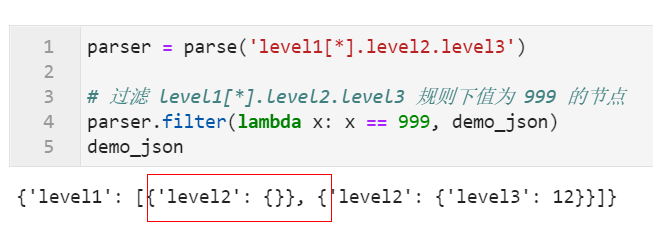
当我们希望对JSON数据中指定JSONPath规则的节点予以删除时,可以使用到parse对象的filter()方法传入lambda函数,在lambda函数中进行条件判断,返回的即为删除指定节点之后的输入数据。
以上一步增操作后得到的demo_json为例,我们来对其level1[*].level2.level3值为999的予以过滤:
parser = parse('level1[*].level2.level3')
# 过滤 level1[*].level2.level3 规则下值为 999 的节点
parser.filter(lambda x: x == 999, demo_json)
demo_json
可以看到结果正是我们所预期的:
2.1.3 对JSON数据进行改操作
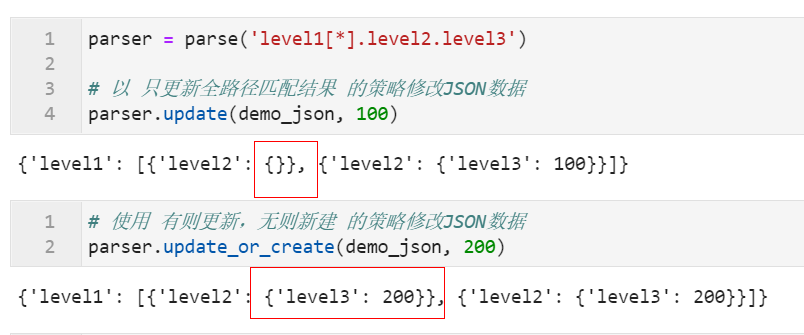
对JSON数据中的指定节点进行改操作非常的简单,只需要使用parse对象的update或update_or_create方法即可,使用效果的区别如下所示,轻轻松松就可以完成两种策略下的节点更新操作:
jsonpath-ng中还有一些丰富的功能,这里就不再赘述,感兴趣的读者朋友可以前往https://github.com/h2non/jsonpath-ng查看。
以上就是本文的全部内容,欢迎在评论区与我进行讨论~
(数据科学学习手札126)Python中JSON结构数据的高效增删改操作的更多相关文章
- (数据科学学习手札32)Python中re模块的详细介绍
一.简介 关于正则表达式,我在前一篇(数据科学学习手札31)中已经做了详细介绍,本篇将对Python中自带模块re的常用功能进行总结: re作为Python中专为正则表达式相关功能做出支持的模块,提供 ...
- (数据科学学习手札42)folium进阶内容介绍
一.简介 在上一篇(数据科学学习手札41)中我们了解了folium的基础内容,实际上folium在地理信息可视化上的真正过人之处在于其绘制图像的高度可定制化上,本文就将基于folium官方文档中的一些 ...
- (数据科学学习手札47)基于Python的网络数据采集实战(2)
一.简介 马上大四了,最近在暑期实习,在数据挖掘的主业之外,也帮助同事做了很多网络数据采集的内容,接下来的数篇文章就将一一罗列出来,来续写几个月前开的这个网络数据采集实战的坑. 二.马蜂窝评论数据采集 ...
- (数据科学学习手札80)用Python编写小工具下载OSM路网数据
本文对应脚本已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 我们平时在数据可视化或空间数据分析的过程中经常会 ...
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
- (数据科学学习手札49)Scala中的模式匹配
一.简介 Scala中的模式匹配类似Java中的switch语句,且更加稳健,本文就将针对Scala中模式匹配的一些基本实例进行介绍: 二.Scala中的模式匹配 2.1 基本格式 Scala中模式匹 ...
- (数据科学学习手札69)详解pandas中的map、apply、applymap、groupby、agg
*从本篇开始所有文章的数据和代码都已上传至我的github仓库:https://github.com/CNFeffery/DataScienceStudyNotes 一.简介 pandas提供了很多方 ...
- (数据科学学习手札90)Python+Kepler.gl轻松制作时间轮播图
本文示例代码及数据已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 Kepler.gl作为一款强大的开源地理信 ...
- (数据科学学习手札44)在Keras中训练多层感知机
一.简介 Keras是有着自主的一套前端控制语法,后端基于tensorflow和theano的深度学习框架,因为其搭建神经网络简单快捷明了的语法风格,可以帮助使用者更快捷的搭建自己的神经网络,堪称深度 ...
随机推荐
- java入门了解、安装jdk及软件的选择
学习编程,一些必要的dos命令还是需要掌握的. 以下只是列出常用的: cd 目录路径: 进入一个目录 cd .. 进入父目录 dir 查看本目录下的文件和子目录列表 cls 清除屏幕命令 上下键 ...
- 【spring源码系列】之【Bean的生命周期】
为源码付出的每一分努力都不会白费. 1. Bean的实例化概述 前一篇分析了BeanDefinition的封装过程,最终将beanName与BeanDefinition以一对一映射关系放到beanDe ...
- Terraform入门教程,示例展示管理Docker和Kubernetes资源
我最新最全的文章都在南瓜慢说 www.pkslow.com,欢迎大家来喝茶! 1 简介 最近工作中用到了Terraform,权当学习记录一下,希望能帮助到其它人. Terraform系列文章如下: T ...
- 我是怎么写 Git Commit message 的?
目录 作用 用的什么规范? type scope subject body footer 参考文章 用的什么辅助工具? 作用 编写格式化的 commit message 能够大大提高代码的维护效率. ...
- Oracle查询wm_concat返回[oracle.sql.CLOB@7D6414ed]之坑!
在orcale中使用wm_concat函数将字段分组连接. 在linux环境下需要将wm_concat(字段)进行to_char(wm_concat(字段))处理.
- easyui的combobox的onChange事件的实现
easyui的combobox的onChange事件的实现,直接上代码: <div style="display:inline;margin-left:15px;"> ...
- 锁&事务
一.概述: 锁:是计算机协调多个进程或线程并发访问某一资源的机制,数据库中最重要的资源.数据库既要保证并发性,又要保证数据的一致性,所以锁机制也更复杂.在计算机科学中,锁(lock)或互斥(mutex ...
- Redhat 6.9 升级SSH到OpenSSH_8.6p1完整文档
这个文章是转载,原文连接在这个:https://www.cnblogs.com/xshrim/p/6472679.html 这个问题遇到过,下面可以解决 ----------------------- ...
- 交通规则:HOV车道
多乘员车道的限行时间一般为工作日上下班高峰,车上只有一个人时不能走该车道
- Intellij idea 设置关闭自动更新
目录结构: File -> Settings- -> Appearance & Behavior -> System Settings -> Updates 把Auto ...