ElasticSearch第三弹之存储原理
我们上文中介绍的ES内部索引的写处理流程是在ES的内存中执行的,而数据被分配到特定的主、副分片上之后,最终是存储到磁盘上的,这样在断电的时候就不会丢失数据。具体的存储路径可在配置文件 ../config/elasticsearch.yml 中进行设置,默认存储在安装目录的 Data文件夹下。建议不要使用默认值,因为若 ES 进行了升级,则有可能导致数据全部丢失。文件配置如下:
path.data: /path/to/data //索引数据
path.logs: /path/to/logs //日志记录
那么ES是怎么将索引从内存中同步到磁盘上的呢?今天我们就来说一下ES的存储原理(搬着小板凳坐好)。
我们先设想一下,ES是否是直接调用 Fsync 物理性地写入磁盘?答案是否定的,如果是直接写入磁盘,磁盘的 I/O 消耗会严重影响性能,那么当写数据量大的时候会造成 ES 停顿卡死,查询也无法做到快速响应, ES 就不会被称为近实时全文搜索引擎了。那么问题来了,ES 是采用什么方式存储的呢?
首先我们先来说几个概念,然后再具体介绍下它的整个流程及细节处理,方便大家更好的理解。
段
索引文档被拆分成多个子文档,则每个子文档叫作段。段提出来的原因是:在早期全文检索中为整个文档集合建立了一个很大的倒排索引,并将其写入磁盘中。如果索引有更新,就需要重新全量创建一个索引来替换原来的索引。这种方式在数据量很大时效率很低,并且由于创建一次索引的成本很高,所以对数据的更新不能过于频繁,也就不能保证时效性。
特点
索引文档是以段的形式存储在磁盘上的,每一个段本身都是一个倒排索引,并且段具有不变性,一旦索引的数据被写入硬盘,就不能再修改。
那么问题来了,不能修改,如何实现增删改呢?
- 新增:新增很好处理,由于数据是新的,所以只需要对当前文档新增一个段就可以了。
- 删除:段是不可改变的,所以既不能把文档从旧的段中移除,也不能修改旧的段来进行文档的更新。取而代之的是每个提交点(定义会在下边给出)会包含一个 .del 文件,文件中会列出这些被删除文档的段信息。当一个文档被 “删除” 时,它实际上只是在 .del 文件中被标记删除。一个被标记删除的文档仍然可以被查询匹配到,但它会在最终结果被返回前从结果集中移除。
- 更新:更新相当于是删除和新增这两个动作组成。当一个文档被更新时,旧版本文档被标记删除,文档的新版本被索引到一个新的段中。可能两个版本的文档都会被一个查询匹配到,但被删除的那个旧版本文档在结果集返回前就已经被移除。
> 一个Lucene索引会包含一个提交点和多个段,段被写入到磁盘后会生成一个提交点,提交点是一个用来记录所有提交后段信息的文件。一个段一旦拥有了提交点,就说明这个段只有读的权限,失去了写的权限。ES在启动或重新打开一个索引的过程中使用这个提交点来判断哪些段隶属于当前分片。
段的优势
- 不需要锁。如果你从来不更新索引,你就不需要担心多进程同时修改数据的问题。
- 一旦索引被读入内核的文件系统缓存,便会留在哪里,由于其不变性。只要文件系统缓存中还有足够的空间,那么大部分读请求会直接请求内存,而不会命中磁盘。这提供了很大的性能提升。
- 其它缓存(像
Filter缓存),在索引的生命周期内始终有效。它们不需要在每次数据改变时被重建,因为数据不会变化。 - 写入单个大的倒排索引允许数据被压缩,减少磁盘 I/O 和需要被缓存到内存的索引的使用量。
段的缺点
- 当对旧数据进行删除时,旧数据不会马上被删除,而是在 .del 文件中被标记为删除。而旧数据只能等到段更新时才能被移除,这样会造成大量的空间浪费。
- 若有一条数据频繁的更新,每次更新都是新增新的标记旧的,则会有大量的空间浪费。
- 每次新增数据时都需要新增一个段来存储数据。当段的数量太多时,对服务器的资源例如文件句柄的消耗会非常大。
- 在查询的结果中包含所有的结果集,需要排除被标记删除的旧数据,这增加了查询的负担。
Refresh(刷新)
在 ES 中,写入和打开一个新段的轻量的过程叫做 Refresh (即ES内存刷新到文件缓存系统)。ES首先会将文档加载到ES的内存缓冲区(当段在内存中时,就只有写的权限,而不具备读数据的权限,意味着不能被检索),当达到默认的时间(1 秒钟)或者内存的数据达到一定量时,会触发一次刷新(Refresh),这时数据就会被加载到文件缓存系统(操作系统的内存),创建新的段并将段打开以供搜索使用。这就是为什么我们说 ES 是近实时搜索,因为文档的变化并不是立即对搜索可见,但会在一秒之内变为可见。这就会存在一个问题:当你索引了一个文档然后尝试搜索它,但却没有搜到。这个问题的解决办法是用 refresh API 执行一次手动刷新。配置如下:
POST /_refresh //刷新(Refresh)所有的索引。
POST /blogs/_refresh //只刷新(Refresh) blogs 索引。
注: 当写测试的时候,手动刷新很有用,但是不要在生产环境下每次索引一个文档都去手动刷新。
尽管刷新是比提交轻量很多的操作,它还是会有性能开销,并不是所有的情况都需要每秒刷新:当你使用 ES 索引大量的日志文件时,你可能想优化索引速度而不是近实时搜索,这时可以在创建索引时在 Settings 中通过调大 refresh_interval = "30s" 的值,降低每个索引的刷新频率,设值时需要注意后面带上时间单位,否则默认是毫秒,如果是1毫秒无疑会使你的集群陷入瘫痪。当 refresh_interval=-1 时表示关闭索引的自动刷新。配置如下:
PUT /my_logs
{
"settings": {
"refresh_interval": "1s" //每秒刷新 my_logs 索引
}
}
> refresh_interval 可以在既存索引上进行动态更新。 在生产环境中,当你正在建立一个大的新索引时,可以先关闭自动刷新,待开始使用该索引时,再把它们调回来。
段合并
由于自动刷新流程每秒会创建一个新的段,这样会导致短时间内的段数量暴增。而段数目太多会带来较大的麻烦。每一个段都会消耗文件句柄、内存和 CPU 运行周期。更重要的是,每个搜索请求都必须轮流检查每个段然后合并查询结果,所以段越多,搜索也就越慢。ES 通过在后台定期进行段合并来解决这个问题。小的段被合并到大的段,然后这些大的段再被合并到更大的段(这些段既可以是未提交的也可以是已提交的)。
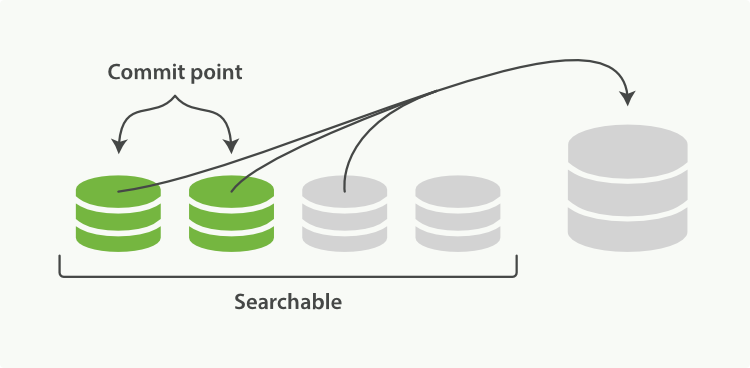
启动段合并不需要你做任何事,进行索引和搜索时会自动进行:
1、 当索引的时候,刷新(refresh)操作会创建新的段并将段打开以供搜索使用;
2、 合并进程选择一小部分大小相似的段,并且在后台将它们合并到更大的段中,这并不会中断索引和搜索;
3、 “一旦合并结束,老的段被删除” 说明合并完成时的活动:新的段被刷新(flush)到了磁盘,写入一个包含新段且排除旧的和较小的段的新提交点,那些旧的已删除文档从文件系统中清除,被删除的文档(或被更新文档的旧版本)不会被拷贝到新的大段中。
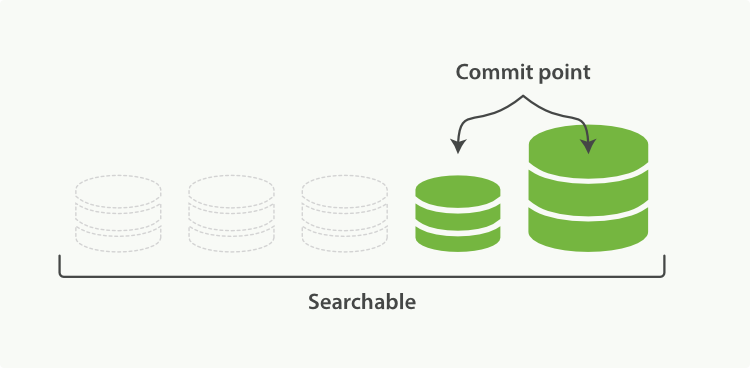
段合并的计算量庞大,需要消耗大量的I/O和CPU资源,并会拖累写入速率,如果任其发展会影响搜索性能。ES 在默认情况下会对合并流程进行资源限制,所以搜索仍然有足够的资源很好地执行。限流阈值默认是20MB/s,如果是SSD,可以考虑100-200MB/s;如果是机械磁盘而非SSD,需要增加设置 index.merge.scheduler.max_thread_count: 1。因为机械磁盘在并发 I/O 支持方面比较差,所以我们需要降低每个索引并发访问磁盘的线程数。这个设置允许 max_thread_count + 2 个线程同时进行磁盘操作,也就是设置为 1 允许三个线程,SSD默认是 Math.min(3, Runtime.getRuntime().availableProcessors() / 2),支持很好;如果在做批量导入,不在意搜索,可以设置为none。配置如下:
PUT /_cluster/settings
{
"persistent" : {
"indices.store.throttle.max_bytes_per_sec" : "100mb"
}
}
optimize API
optimize API大可看做是强制合并 API。它会将一个分片强制合并到 max_num_segments 参数指定大小的段数目。这样做的意图是减少段的数量(通常减少到一个)来提升搜索性能。
optimize API不应该被用在一个活跃的索引--一个正积极更新的索引:后台合并流程已经可以很好地完成工作,optimizing 会阻碍这个进程,不要干扰它!在特定情况下,使用 optimize API 颇有益处。例如在日志这种用例下,每天、每周、每月的日志被存储在一个索引中,老的索引实质上是只读的;它们也并不太可能会发生变化。在这种情况下,使用optimize优化老的索引,将每一个分片合并为一个单独的段就很有用了,这样既可以节省资源,也可以使搜索更加快速。
POST /logstash-2014-10/_optimize?max_num_segments=1 //合并索引中的每个分片为一个单独的段
> 请注意,使用 optimize API 触发段合并的操作不会受到任何资源上的限制。这可能会消耗掉你节点上全部的I/O资源,使其没有余力来处理搜索请求,从而有可能使集群失去响应。 如果你想要对索引执行 optimize,你需要先使用分片分配把索引移到一个安全的节点,再执行。
Translog
为了提升写的性能,ES 并没有每新增一条数据就增加一个段到磁盘上,而是采用延迟写的策略。等文件系统中有新段生成之后,在稍后的时间里再被刷新到磁盘中并生成提交点。虽然通过延时写的策略可以减少数据往磁盘上写的次数提升了整体的写入能力,但是我们知道文件缓存系统也是内存空间,属于操作系统的内存,只要是内存都存在断电或异常情况下丢失数据的危险。为了避免丢失数据,ES 添加了事务日志(Translog),事务日志记录了所有还没有持久化到磁盘的数据。
translog 默认是每5秒被 fsync 刷新到硬盘,或者在每次写请求完成之后执行(index, delete, update, bulk)操作也可以刷新到磁盘。在每次请求后都执行一个 fsync 会带来一些性能损失,尽管实践表明这种损失相对较小(特别是bulk导入,它在一次请求中平摊了大量文档的开销)。对于一些大容量的偶尔丢失几秒数据问题也并不严重的集群,使用异步的 fsync 还是比较有益的。我们可以通过设置 durability 参数为 async 来启用:
PUT /my_index/_settings
{
"index.translog.durability": "async",
"index.translog.sync_interval": "5s"
}
这个选项可以针对索引单独设置,并且可以动态进行修改。如果你决定使用异步 translog 的话,你需要保证在发生crash时,丢失掉 sync_interval 时间段的数据也无所谓。如果你不确定这个行为的后果,最好是使用默认的参数( "index.translog.durability": "request" )来避免数据丢失。
Flush
执行一个提交并且截断 translog 的行为在ES中被称作一次flush。分片每30分钟被自动刷新(flush)或者在 translog 太大的时候也会刷新。可以通过设置translog 文档来控制这些阈值,flush API 可以被用来执行一个手工的刷新(flush):
POST /blogs/_flush //刷新(flush) blogs 索引。
POST /_flush?wait_for_ongoing //刷新(flush)所有的索引并且并且等待所有刷新在返回前完成。
总结
最后我们来说一下添加了事务日志后的整个存储的流程吧:
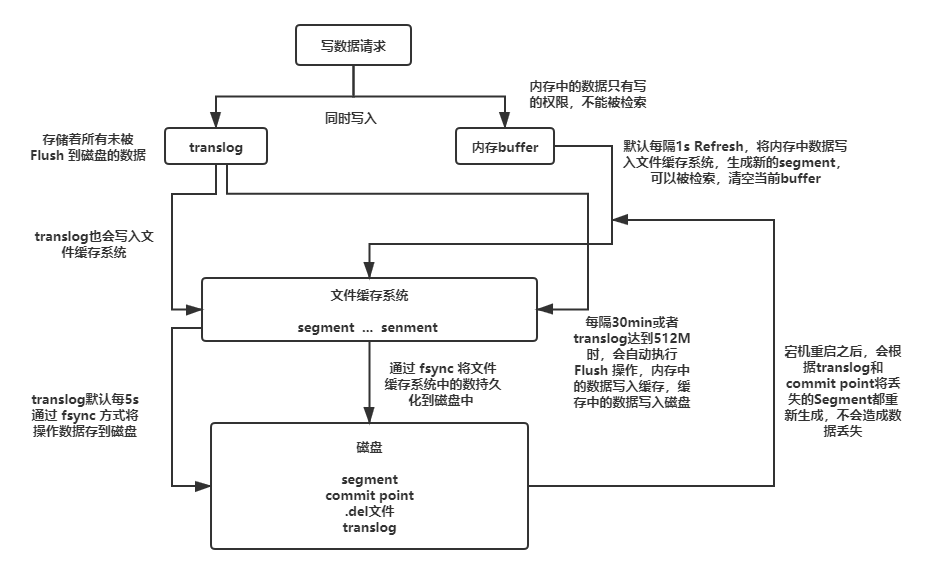
- 一个新文档被索引之后,先被写入到内存中,但是为了防止数据的丢失,会追加一份数据到事务日志中。不断有新的文档被写入到内存,同时也都会记录到事务日志中(日志默认存储到文件缓存系统,每五秒刷新一下到本地磁盘,但是会导致数据丢失,也可以设置参数每个请求都同步,但是性能下降)。这时新数据还不能被检索和查询。
- 当达到默认的刷新时间或内存中的数据达到一定量后,会触发一次
Refresh,将内存中的数据以一个新段形式刷新到文件缓存系统中并清空内存。这时虽然新段未被提交到磁盘,但是可以提供文档的检索功能且不能被修改。 - 随着新文档索引不断被写入,当日志数据大小超过
512M或者时间超过30分钟时,会触发一次Flush。内存中的数据被写入到一个新段同时被写入到文件缓存系统,文件系统缓存中数据通过Fsync刷新到磁盘中,生成提交点,日志文件被删除,创建一个空的新日志。 - 通过这种方式当断电或需要重启时,
ES不仅要根据提交点去加载已经持久化过的段,还需要读取Translog里的记录,把未持久化的数据重新持久化到磁盘上,避免了数据丢失的可能。
阿Q正在将ES的知识做一个系统的学习与讲解,后续还会持续输出ES的相关知识,如果你感兴趣的话,可以关注微信公众号“阿Q说代码”!也可以加我微信qingqing-4132,期待你的到来!
ElasticSearch第三弹之存储原理的更多相关文章
- elasticsearch 基础 —— 分布式文档存储原理
路由一个文档到一个分片中 当索引一个文档的时候,文档会被存储到一个主分片中. Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片 ...
- Java并发必知必会第三弹:用积木讲解ABA原理
Java并发必知必会第三弹:用积木讲解ABA原理 可落地的 Spring Cloud项目:PassJava 本篇主要内容如下 一.背景 上一节我们讲了程序员深夜惨遭老婆鄙视,原因竟是CAS原理太简单? ...
- Elasticsearch系列---Elasticsearch的基本概念及工作原理
基本概念 Elasticsearch有几个核心的概念,花几分钟时间了解一下,有助于后面章节的学习. NRT Near Realtime,近实时,有两个层面的含义,一是从写入一条数据到这条数据可以被搜索 ...
- Hadoop(六)之HDFS的存储原理(运行原理)
前言 其实说到HDFS的存储原理,无非就是读操作和写操作,那接下来我们详细的看一下HDFS是怎么实现读写操作的! 一.HDFS读取过程 1)客户端通过调用FileSystem对象的open()来读取希 ...
- 『PyTorch』第三弹重置_Variable对象
『PyTorch』第三弹_自动求导 torch.autograd.Variable是Autograd的核心类,它封装了Tensor,并整合了反向传播的相关实现 Varibale包含三个属性: data ...
- flash存储原理
norflash 带有 SRAM接口,有足够的地址引脚来寻址,可以很容易地存取其内容每一字节:nandflash器件使用复杂的IO口串行的存取数据,读写操作采用512字节的块(也就是读/写某个字节,必 ...
- 重新学习MySQL数据库3:Mysql存储引擎与数据存储原理
重新学习Mysql数据库3:Mysql存储引擎与数据存储原理 数据库的定义 很多开发者在最开始时其实都对数据库有一个比较模糊的认识,觉得数据库就是一堆数据的集合,但是实际却比这复杂的多,数据库领域中有 ...
- 解析如何利用ElasticSearch和Redis检索和存储十亿信息
如果从企业应用的生存率来看,选择企业团队信息作为主要业务,HipChat的起点绝非主流:但是如果从赚钱的角度上看,企业市场的高收益确实值得任何公司追逐,这也正是像JIRA和Confluence这样的智 ...
- Memcache启动&存储原理&集群
一. windows下安装启动 首先将memcache的bin文件夹增加到Path环境变量中.方便后面使用命令: 然后运行 memcached –dinstall 命令安装memcache的服务: 然 ...
随机推荐
- 提升Idea启动速度与Tomcat日志乱码问题
提升Idea启动速度与Tomcat日志乱码问题 前言 由于重装了一次Idea,所以有些设置时间就忘了,在此做个记录,以便以后忘记后可以来翻阅 Idea启动速度 一.将Idea所在的 安装文件夹 在wi ...
- ES6学习笔记(1)- 块级作用域
1. var声明变量和变量提升(Hoisting)机制的问题 在JS中通过var关键字声明的变量,无论在函数作用域中亦或是全局作用域中,都会被当成当前作用域顶部的变量,和就是所谓的提升机制(Hoist ...
- js toFixed
为什么(2.55).toFixed(1)等于2.5? 上次遇到了一个奇怪的问题:JS的(2.55).toFixed(1)输出是2.5,而不是四舍五入的2.6,这是为什么呢? 进一步观察: 发现,并不是 ...
- 欢迎参加3月活动:AWS 在线研讨会与阿里云 RISC-V 应用创新大赛
3月份我们在帮合作云厂商 Amazon Web Services(AWS) 与阿里云推广2个活动,欢迎感兴趣的园友参加. 活动一:亚马逊云科技在线研讨会:借助 DGL 实现实时欺诈检测 博客园专属报名 ...
- Envoy 部署类型
目录 Envoy 网络拓扑及请求流程 1. 术语 2. 网络拓扑 3. 配置 4. 更高层的架构 5. 请求流程 1. Listener TCP 接收 2. 侦听器过滤器链和网络过滤器链匹配 3.TL ...
- 9、Spring教程之AOP
那我们接下来就来聊聊AOP吧! 1.什么是AOP AOP(Aspect Oriented Programming)意为:面向切面编程,通过预编译方式和运行期动态代理实现程序功能的统一维护的一种技术.A ...
- ARFoundation - 实现物体旋转, 平移,缩放
ARFoundation - 实现物体旋转, 平移,缩放 本文目的是为了确定在移动端怎样通过单指滑动实现物体的旋转,双指实现平移和缩放. 前提知识: ARFoundation - touch poin ...
- Go 语言入门教程,共32讲,6小时(已完结)
Go语言入门教程,共32讲,6小时(完结) 在B站:https://www.bilibili.com/video/BV1fD4y1m7TD/
- SpringCloud(六)分布式事务
在分布式系统中,分布式事务基本上是绕不开的, 分布式事务是指事务的参与者.支持事务的服务器.资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上 .其实就可以简单理解成在分布式系统中实现事务 ...
- 批量SSH key-gen无密码登陆认证脚本 附件脚本
# 批量实现SSH无密码登陆认证脚本 ## 问题背景 使用为了让linux之间使用ssh不需要密码,可以采用了数字签名RSA或者DSA来完成.主要使用ssh-key-gen实现. 1.通过 ssh-k ...