JAVA 对象的创建与克隆
一、对象的4种创建方式
- new 创建
- 反射
- 克隆
- 反序列化
二、通过new创建对象
一般情况下,对象通过new 关键字创建,首先会在堆上给对象分配空间,然后执行构造函数进行一系列的初始化,在分配的内存空间上为一众属性赋值;完成初始化后再将堆区对象的引用传递给栈区,最终参与程序的运行。
三、反射
调用Java.lang.Class或者java.lang.reflect.Constructor类的newInstance()实例方法。
四、克隆对象
它分为深拷贝和浅拷贝,通过调用对象的 clone方法,进行对象的克隆(拷贝)
我们可以看到 clone 方法的定义
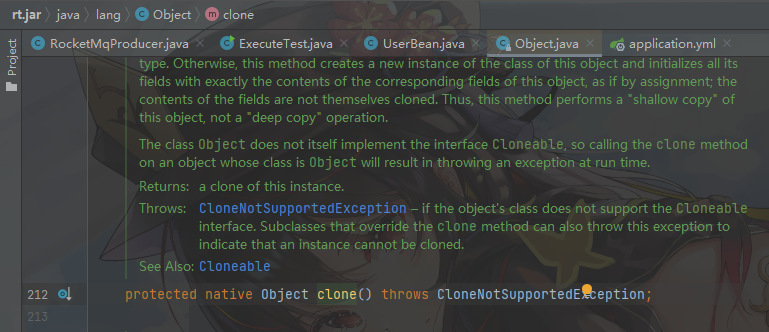
首先它是一个 native 方法
它被 protected 修饰,那么,它的访问权限就只有它的子类或者[同包:java.lang.*];
虽然说类都继承自Object,当对象A引用对象B,A没法调用:B.clone() { B -> Object.clone() } 的,因为,Object上的clone()方法被protected修饰,
若A一定要访问B的clone()方法:B重写clone()为public修饰、或者通过public方法将 clone() 访问权限传递出去。
此外我们还需要实现:Cloneable接口,我们可以看它的定义,实际上空无一物,可以把Cloneable视为一个标记,若不实现它,当我们调用重写的clone方法进行克隆时会抛出异常:[java.lang.CloneNotSupportedException]

clone不会调用类的构造方法,它只是复制堆区上的对象信息。
为了测试 clone 我定义了两个类:
用户信息:UserBean
package com.bokerr.canaltask.po;
import lombok.AllArgsConstructor;
import lombok.Data;
import java.io.Serializable;
@Data
@AllArgsConstructor
public class UserBean implements Cloneable, Serializable {
private static final long serialVersionUID = 2022010901L;
/** 基本类型、不可变类型 */
private int age;
private int sex;
private String name;
private String home;
/** 引用类型 */
private SubInfo subInfo;
public UserBean(){}
/***
* 重写 clone 为 public 让任意对象都有 clone的访问权限
* */
@Override
public UserBean clone(){
UserBean clone = null;
try{
clone = (UserBean) super.clone();
} catch (CloneNotSupportedException e){
e.printStackTrace();
}
return clone;
}
}
附加信息类:SubInfo
package com.bokerr.canaltask.po;
import lombok.AllArgsConstructor;
import lombok.Data;
import java.io.Serializable;
@Data
@AllArgsConstructor
public class SubInfo implements Cloneable, Serializable {
private static final long serialVersionUID = 2022010902L;
/**
* SubInfo 类的属性都是基本类型、不可变对象(String)
* */
private String work;
private Integer salary;
private int idNum;
public SubInfo(){}
/**
* 此处通过public 方法对外提供对象clone方法访问权限
* */
public SubInfo selfClone(){
try{
return (SubInfo) clone();
} catch (CloneNotSupportedException e){
e.printStackTrace();
}
return null;
}
/*@Override
public SubInfo clone(){
try{
return (SubInfo) super.clone();
} catch (CloneNotSupportedException e){
e.printStackTrace();
}
return null;
}*/
}
浅拷贝
我们需要知道,单纯调用一个对象的clone方法,它进行的是:"浅表复制",当对象的属性都是基本类型或者不可变(final)类型时是没有问题的;但是存在可变对象引用时,对它的拷贝并不是一个深层的拷贝,它只拷贝该对象的引用,这样就会造成原对象和克隆对象的修改,都会反映到该引用对象上。
关于浅拷贝看如下测试代码:
package com.bokerr.canaltask.workerrun;
import com.bokerr.canaltask.po.SubInfo;
import com.bokerr.canaltask.po.UserBean;
public class ExecuteTest {
public static void main(String[] args){
UserBean userBean1 = new UserBean();
userBean1.setAge(25);
userBean1.setSex(1);
userBean1.setName("bokerr");
userBean1.setHome("贵州铜仁");
SubInfo subInfo1 = new SubInfo();
subInfo1.setIdNum(3423);
subInfo1.setSalary(Integer.valueOf(15000));
subInfo1.setWork("coder");
userBean1.setSubInfo(subInfo1);
System.out.println("userBean-orign:" + userBean1);
UserBean userBean2 = userBean1.clone();
userBean2.setHome("贵州贵阳");
userBean2.setAge(26);
SubInfo subInfo2 = userBean2.getSubInfo();
subInfo2.setSalary(Integer.valueOf(25000));
subInfo2.setWork("manager");
subInfo2.setIdNum(100002);
System.out.println("######################");
System.out.println("userBean-orign:" + userBean1);
System.out.println("userBean-clone:" + userBean2);
}
}
UserBean 的 clone 方法定义如下,我们可以看见它只调用了super.clone 而对 super.clone 的返回值没做任何修改:
@Override
public UserBean clone(){
UserBean clone = null;
try{
clone = (UserBean) super.clone();
} catch (CloneNotSupportedException e){
e.printStackTrace();
}
return clone;
}
输出如下,结合测试code,我们可以发现,克隆得到的对象对 SubInfo 的修改同样体现到了原对象引用的 SubInfo 对象上,因为调用 super.clone 只是一个 "浅表复制"
userBean-orign:UserBean(age=25, sex=1, name=bokerr, home=贵州铜仁, subInfo=SubInfo(work=coder, salary=15000, idNum=3423))
######################
userBean-orign:UserBean(age=25, sex=1, name=bokerr, home=贵州铜仁, subInfo=SubInfo(work=manager, salary=25000, idNum=100002))
userBean-clone:UserBean(age=26, sex=1, name=bokerr, home=贵州贵阳, subInfo=SubInfo(work=manager, salary=25000, idNum=100002))
深拷贝
深拷贝生成的对象,必须拥有完全独立的对象内存空间,拷贝对象和原对象上的修改,都不会影响对方;
前边提到通过 super.clone 调用 Object上的clone方法实际上进行的只是一个浅拷贝
为了实现深拷贝我们则必须修改 UserBean 的clone 方法:
/***
* 重写 clone 为 public 让任意对象都有 clone的访问权限
* */
@Override
public UserBean clone(){
UserBean clone = null;
try{
clone = (UserBean) super.clone();
/** SubInfo.selfClone() 提供SubInfo对象clone()方法权限 */
/** 克隆可变引用对象 SubInfo,并赋值给 super.clone() 返回的:UserBean 完成深拷贝 */
SubInfo cloneSub = this.subInfo.selfClone();
clone.setSubInfo(cloneSub);
} catch (CloneNotSupportedException e){
e.printStackTrace();
}
return clone;
}
实际上除此之外,测试代码一成不变,然后我们来看现在的输出,可以发现对克隆对象的引用对象:SubInfo 的修改,并未使原对象的SubInfo变化
userBean-orign:UserBean(age=25, sex=1, name=bokerr, home=贵州铜仁, subInfo=SubInfo(work=coder, salary=15000, idNum=3423))
######################
userBean-orign:UserBean(age=25, sex=1, name=bokerr, home=贵州铜仁, subInfo=SubInfo(work=coder, salary=15000, idNum=3423))
userBean-clone:UserBean(age=26, sex=1, name=bokerr, home=贵州贵阳, subInfo=SubInfo(work=manager, salary=25000, idNum=100002))
此时问题来了:你可能会说假如我的对象进行了多层引用呢,且引用了多个对象该怎么办呢?那我只能一个一个去重写 clone 方法么?
是的你如果使用 clone 方法可能,你确实需要那样去处理。
假如,存在如下以对象A为根节点的引用关系:
A -> B
C -> E -> F
G -> G
D -> H
I -> J -> K
我相信处理深拷贝的人会疯掉的。。。。
那么有更省事的方法么? 当然有,那就是下一节提到的反序列化。
五、反序列化
java中的序列化是将对象转化成一个二进制字节序列,它可以持久化到磁盘文件,也可通过网络进行传输;
而反序列化是指将该二进制字节序列,重新还原成一个对象并加载到内存中的过程。
对象的反序列化过程中,没有调用任何构造函数,整个对象都是通过将,文件流中取得的数据恢复,从而得来。
序列化只保存对象的属性状态,而不会保存对象的方法。
只有实现了Serializable接口的类才能被序列化,官方建议自定义一个SerialversionUID,若用户没有自定义SerialversionUID那么会生成默认值;序列化和反序列化就是通过对比其SerialversionUID来进行的,一旦SerialversionUID不匹配,反序列化就无法成功
如果一个类的属性包含对象引用,那么被引用的对象也将被序列化,[被引用的对象也必须实现Serializable接口,否则会抛出异常:java.io.NotSerializableException]
被 static和transient修饰的变量不会被序列化,可以理解为:static是类属性存在于方法区而不在堆区;transient常用于修饰涉及安全的信息,它只能和Serializable接口一起使用,比如:用户密码,不应该让它序列化之后在网络上传输。
参考代码
package com.bokerr.canaltask.workerrun;
import com.bokerr.canaltask.po.NoCloneInfo;
import com.bokerr.canaltask.po.SubInfo;
import com.bokerr.canaltask.po.UserBean;
import org.apache.commons.lang3.SerializationUtils;
import java.util.Arrays;
public class ExecuteTest {
public static void main(String[] args){
UserBean userBean1 = new UserBean();
userBean1.setAge(25);
userBean1.setSex(1);
userBean1.setName("bokerr");
userBean1.setHome("贵州铜仁");
SubInfo subInfo1 = new SubInfo();
subInfo1.setIdNum(3423);
subInfo1.setSalary(Integer.valueOf(15000));
subInfo1.setWork("coder");
userBean1.setSubInfo(subInfo1);
System.out.println("序列化前" + userBean1);
/** 对象序列化为二进制字节序列 */
byte[] serializeBytes = SerializationUtils.serialize(userBean1);
/** 反序列化还原为Java对象 */
UserBean userBeanSer = SerializationUtils.deserialize(serializeBytes);
userBeanSer.getSubInfo().setSalary(800000);
userBeanSer.getSubInfo().setWork("CTO");
System.out.println("反序列化" + userBeanSer);
System.out.println(userBean1 == userBeanSer);
}
}
输出:
序列化前UserBean(age=25, sex=1, name=bokerr, home=贵州铜仁, subInfo=SubInfo(work=coder, salary=15000, idNum=3423))
反序列化UserBean(age=25, sex=1, name=bokerr, home=贵州铜仁, subInfo=SubInfo(work=CTO, salary=800000, idNum=3423))
false
我们可以发现最终输出了:subInfo.work=CTO subInfo.salary=800000,对反序列化得到的对象引用的SubInfo对象的修改,并未影响到原对象,所以可以通过反序列化进行对象的深拷贝。
六、补充
PS*有一说一:lombok 是真的好用,虽然 set、get 方法可以自动生成,但是用 lombok后明显代码更简洁了 ;
commons-lang3 它是apache的一个工具包,我用的序列化工具来自它。
可能有小伙伴不了解,我还是贴一下Maven依赖吧,虽然我知道大家都人均大佬了。
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.12.0</version>
</dependency>
JAVA 对象的创建与克隆的更多相关文章
- 图解JAVA对象的创建过程
前面几篇博文分别介绍了JAVA的Class文件格式.JVM的类加载机制和JVM的内存模型,这里就索性把java对象的创建过程一并说完,这样java对象的整个创建过程就基本上说明白了(当然你要有基础才能 ...
- 深入理解Java对象的创建过程:类的初始化与实例化
摘要: 在Java中,一个对象在可以被使用之前必须要被正确地初始化,这一点是Java规范规定的.在实例化一个对象时,JVM首先会检查相关类型是否已经加载并初始化,如果没有,则JVM立即进行加载并调用类 ...
- (转)深入理解Java对象的创建过程
参考来源:http://blog.csdn.net/justloveyou_/article/details/72466416 摘要: 在Java中,一个对象在可以被使用之前必须要被正确地初始化,这一 ...
- Java对象的创建及使用
Java对象的创建及使用 对象是类的具体实例(instance),是真实存在的个体:
- Java对象的创建过程:类的初始化与实例化
一.Java对象创建时机 我们知道,一个对象在可以被使用之前必须要被正确地实例化.在Java代码中,有很多行为可以引起对象的创建,最为直观的一种就是使用new关键字来调用一个类的构造函数显式地创建对象 ...
- java 对象 :创建
灵感来自effective java 关于对象,是java的核心,如何有效的创建其实是一个值得关注的地方. 1.静态工厂:这是一个值得关注的,并且应该时刻考虑的方法. 优点:1.他是有名字的,这个是如 ...
- java --- 对象的创建过程
java 对象创建的过程 存在了继承关系之后,对象创建过程如下: 1.分配空间.要注意的是,分配空间不光是分配子类的空间,子类对象中包含的父类对象所需要的空间,一样在这一步统一分配.在分配的空间的时候 ...
- 2 Java对象的创建过程
JAVA中创建对象直接new创建一个对象,对么对象的创建过程是怎样的呢? 程序运行过程中有许多的对象被创建出来.那么对象是如何创建的呢? 一 对象创建的步骤 1 遇到new指令时,检查这个指令的参数是 ...
- Java对象的创建
学了很久的java,是时候来一波深入思考了.比如:对象是如何在JVM中创建,并且被使用的.本文主要讲解下new对象的创建过程.要想更深入的了解建议去认认真真的看几遍<深入理解Java虚拟机> ...
随机推荐
- 第10组-Alpha冲刺 总结
1.基本情况 组长博客链接:https://www.cnblogs.com/cpandbb/p/14007413.html 答辩总结: ·产品偏离了最开始的方向,地图和刷一刷功能做得没那么好,外卖订单 ...
- 日志收集系统系列(四)之LogAgent优化
实现功能 logagent根据etcd的配置创建多个tailtask logagent实现watch新配置 logagent实现新增收集任务 logagent删除新配置中没有的那个任务 logagen ...
- Java实现163邮箱发送邮件到QQ邮箱
注:图片如果损坏,点击文章链接:https://www.toutiao.com/i6812973124141711876/ 先创建一个maven的普通项目 添加依赖,附在文档末尾 其中几个注意的地方 ...
- 记一次 WinDbg 分析 .NET 某工厂MES系统 内存泄漏分析
一:背景 1. 讲故事 上个月有位朋友加微信求助,说他的程序跑着跑着就内存爆掉了,寻求如何解决,截图如下: 从聊天内容看,这位朋友压力还是蛮大的,话说这貌似是我分析的第三个 MES 系统了,看样子 . ...
- Redis之持久化方式详解
背景:Redis之所以能够在技术革新发展迅速的时代超越Memcache等其他Nosql数据库,最主要的一点是Redis提供数据持久化,能够根据持久化策略将缓存数据灵活的写到磁盘上,更好地满足了当下海量 ...
- 【漏洞复现】CVE-2022–21661 WordPress核心框架WP_Query SQL注入漏洞原理分析与复现
影响版本 wordpress < 5.8.3 分析 参考:https://blog.csdn.net/qq_46717339/article/details/122431779 在 5.8.3 ...
- 【Java】抽象类与抽象方法
文章目录 抽象类与抽象方法 abstract关键字的使用 abstract修饰类:抽象类 abstract修饰方法:抽象方法 abstract使用上的注意点: 抽象类的匿名子类 模板方法设计模式 抽象 ...
- CAX软件资产管理
CAX软件其实指的是计算机辅助设计软件统称,即CAD.CAM.CAE.CAPP.CAS.CAT.CAI等各项技术的综合叫法,因为这些技术的缩写基本都是以CA为起始,X则表示所有.也就是说,CAX实际上 ...
- 《剑指offer》面试题14- I. 剪绳子
问题描述 给你一根长度为 n 的绳子,请把绳子剪成整数长度的 m 段(m.n都是整数,n>1并且m>1),每段绳子的长度记为 k[0],k[1]...k[m] .请问 k[0]*k[1]* ...
- 《剑指offer》面试题63. 股票的最大利润
问题描述 假设把某股票的价格按照时间先后顺序存储在数组中,请问买卖该股票一次可能获得的最大利润是多少? 示例 1: 输入: [7,1,5,3,6,4] 输出: 5 解释: 在第 2 天(股票价格 = ...