MapReduce04 框架原理Shuffle
MapReduce 框架原理
1.InputFormat可以对Mapper的输入进行控制
2.Reducer阶段会主动拉取Mapper阶段处理完的数据
3.Shuffle可以对数据进行排序、分区、压缩、合并,核心部分。
4.OutPutFomat可以对Reducer的输出进行控制
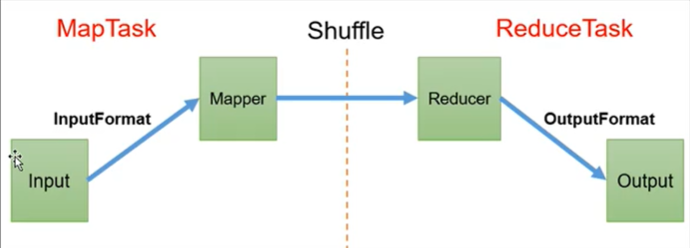
2 MapReduce工作流程
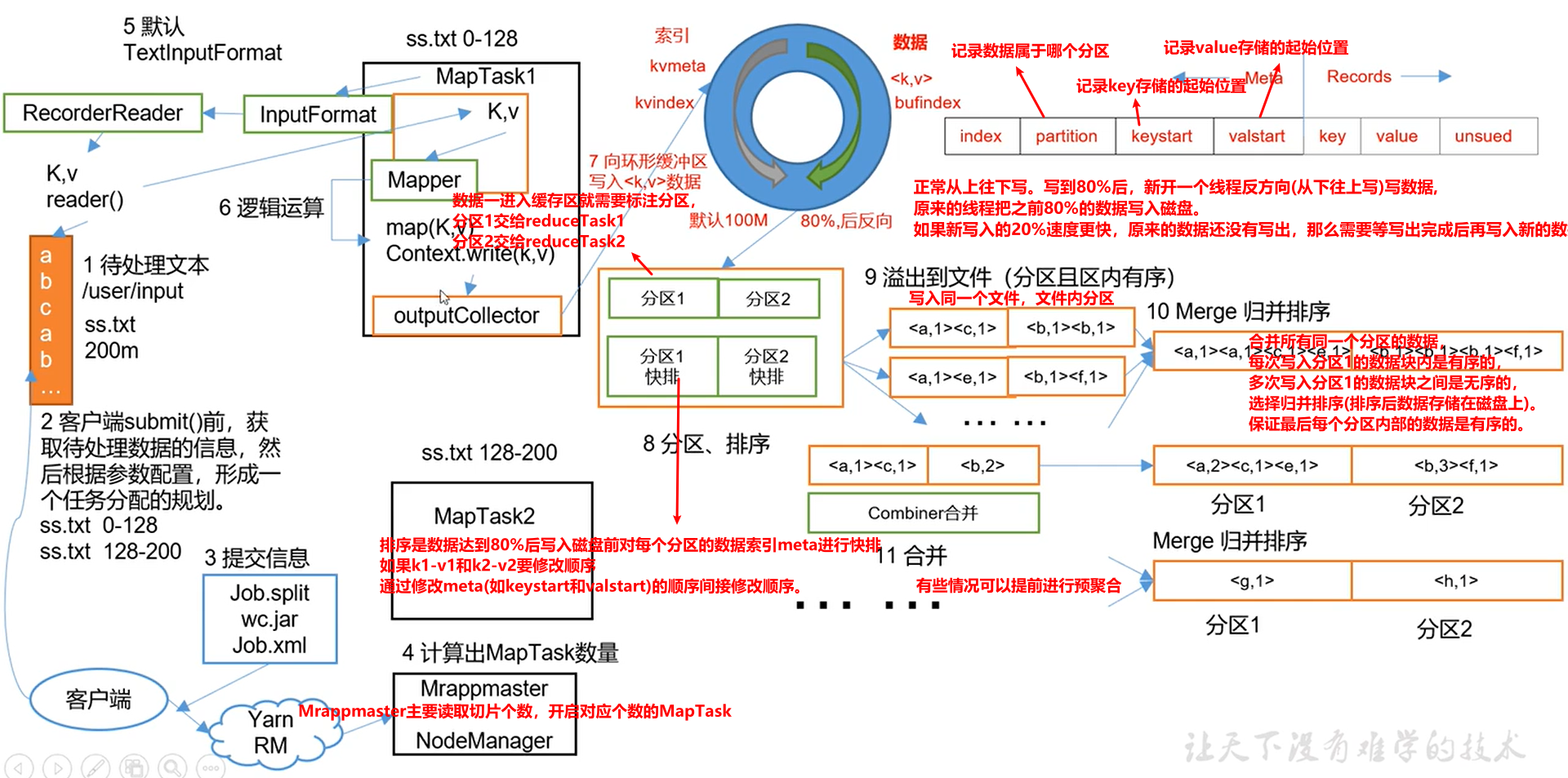
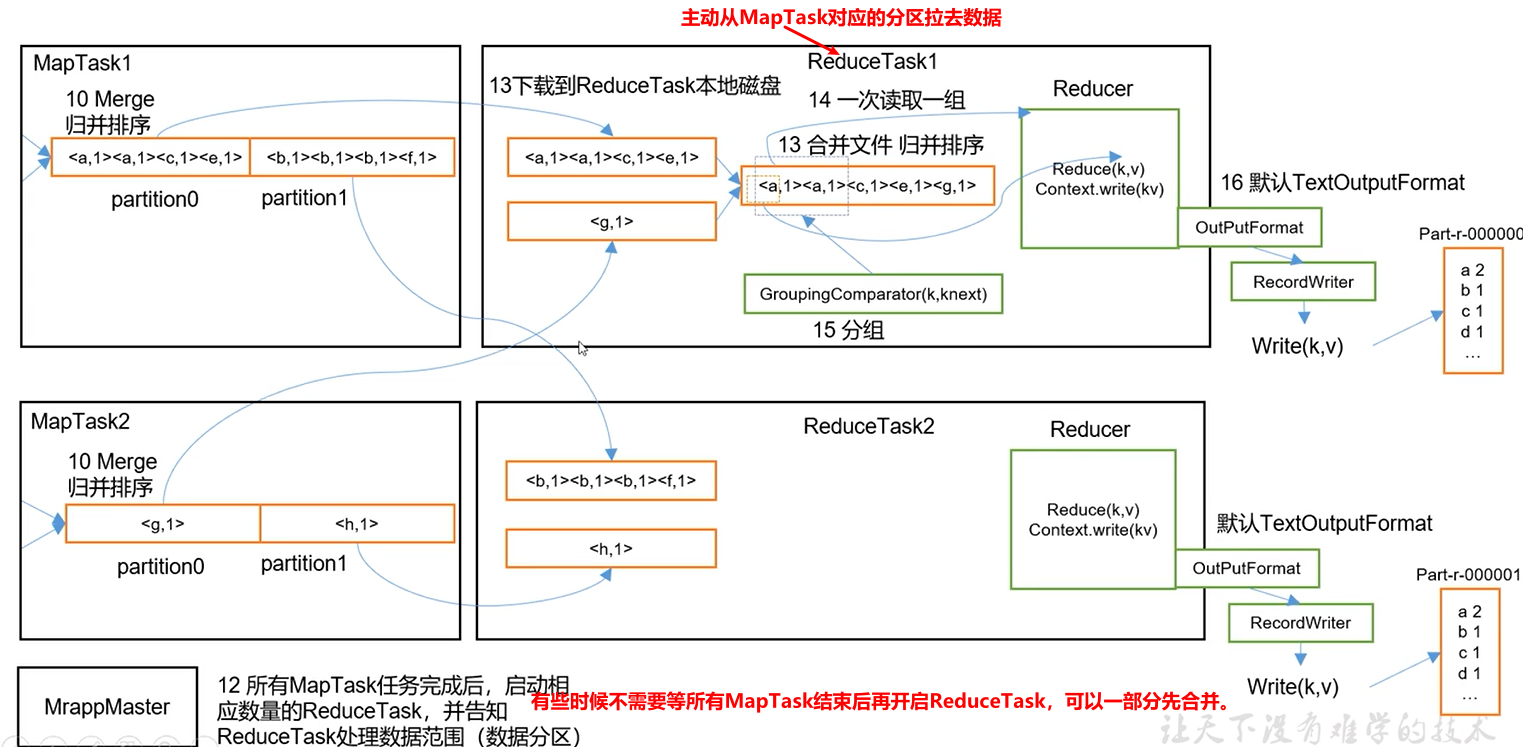
3 Shuffle机制(重点)
3.1 Shuffle机制
Map方法之后,Reduce方法之前的数据处理(洗排)过程称为Shuffle。、
如果把ReduceTask设置成0,不进行ruduce,因为shuffle阶段也会消失
MapTask进程对每一个<K,V>调用一次map()方法
ReduceTask进程对每一组相同k的<k,v>组调用一次reduce()方法。
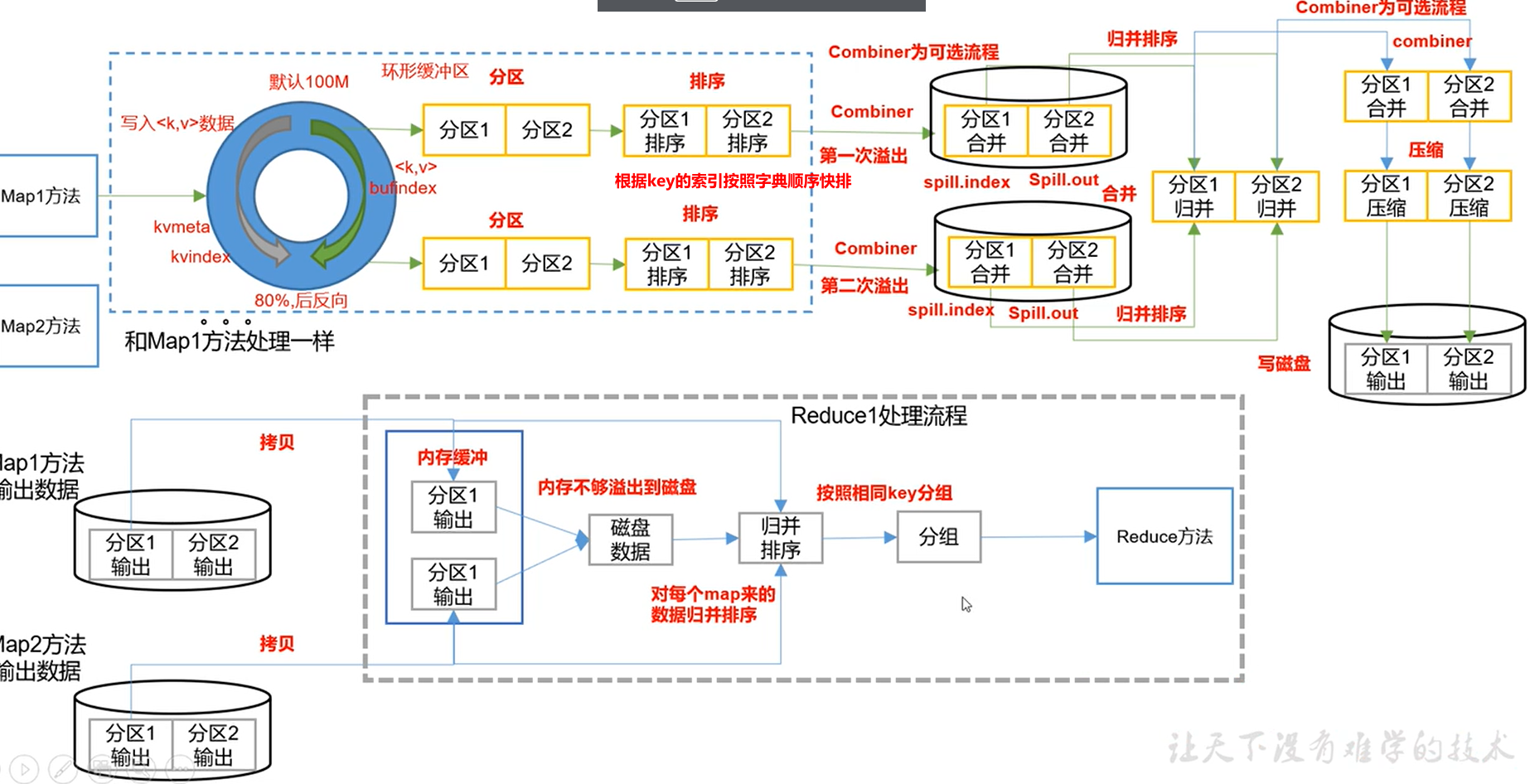
3.2 Partition分区
问题
要求统计结果按照条件输出到不同的文件中,比如:统计结果135开头的输入到一个文件、136开头的输入一个文件。
默认Partitioner分区
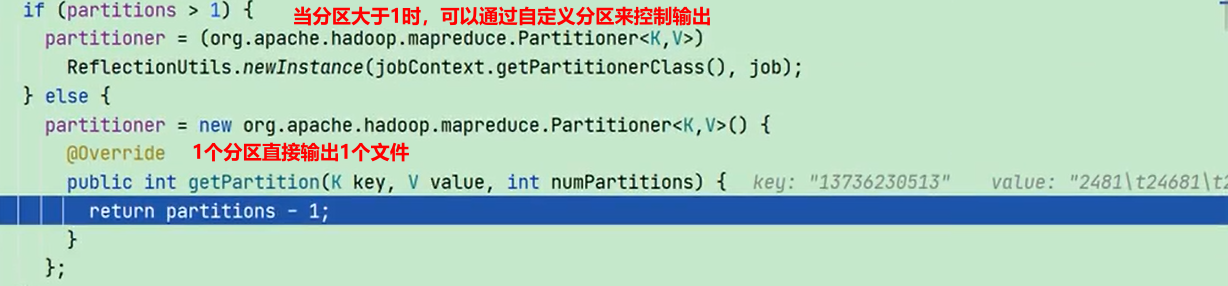
下面代码是分区大于1的情况下默认的分区类,自定义的分区实际上替换的是这个。
public class HashPartitioner<K,V> extends Partitioner<K,V>{
public int getPartition(K key,V value,int numReduceTask){
//默认分区是根据key的hashCode对ReduceTasks个数取模得到的,用户没法控制key存储到哪个分区。
//key.hasCode() & Integer.MAX.VALUE 用于控制key最大不超过Integer.MAX.VALUE
retrun(key.hasCode() & Integer.MAX.VALUE)%numReduceTask;
}
}
自定义Partitioner分区
1.自定义类继承Partitioner,重写getPartition()方法
public class CustomPartitioner extends Partitioner<K,V>{
@Override
public int getPartition(K key,V value,int numReduceTask){
//控制分区代码逻辑
return partition;
}
}
2.在Job驱动中,设置分区类为自定义的Partitioner
job.setPartitionerClass(CustomPartitioner.class);
3.在Job驱动中,要根据自定义Partitioner的逻辑设置相应数量的ReduceTask
如果setNumReduceTasks=1,直接走else。
job.setNumReduceTasks(2);
自定义Partition分区案例
需求
将统计结果按照手机号开头输出到不同文件(分区)中
输入数据:D:\hadoop_data\input\inputpartition文件
期望输出数据:手机号136、137、138、139开头的分别放入一个文件中,剩下的放入一个文件中
需求分析
输入数据
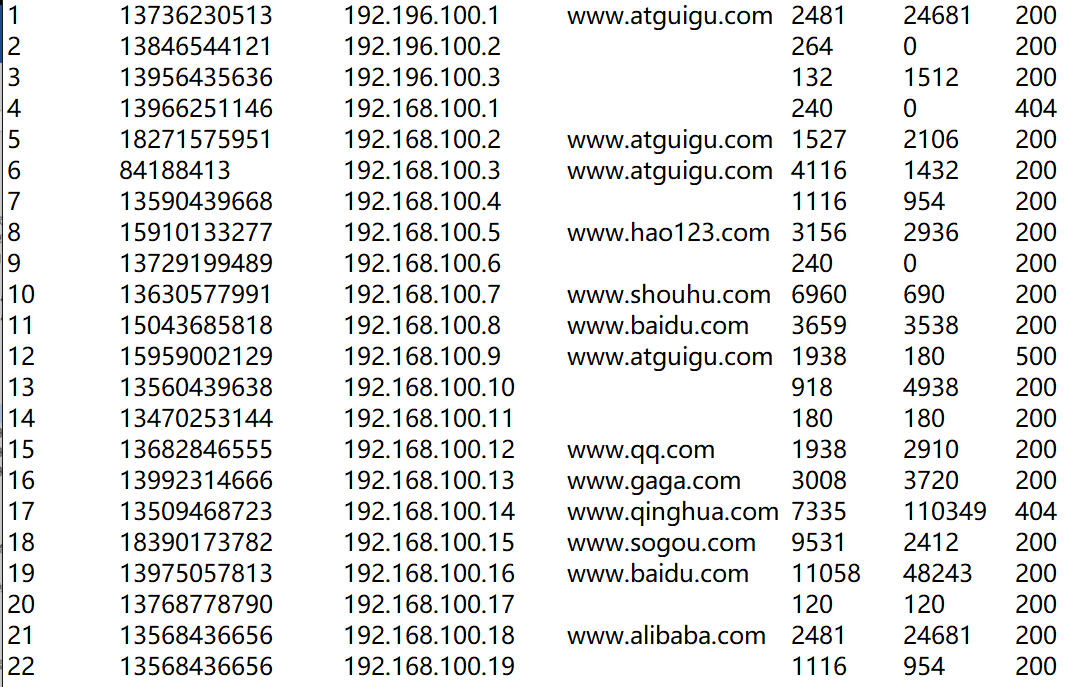
输出数据
文件1 136开头的数据
文件2 137开头的数据
文件3 138开头的数据
文件4 139开头的数据
文件5 其他
自定义分区
分区0 136
分区1 137
分区2 138
分区3 139
分区4 其他
设置使用自定义分区,指定ReduceTasks的数量为5
案例实现
1.使用之前序列化的代码
2.新增ProvicePartitioner类
ProvicePatitioner.class
package ranan.mapreduce.partition;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class ProvincePartitioner extends Partitioner<Text,FlowBean> {
@Override
public int getPartition(Text text, FlowBean flowBean, int numPartitions) {
//text是手机号
String phone = text.toString().substring(0,3);
int partition;
//防止空指针异常,常量写在前面
if("136".equals(phone)){
partition=0;
}else if("137".equals(phone)){
partition=1;
}else if("138".equals(phone)){
partition=2;
}else if("139".equals(phone)){
partition=3;
}else {
partition=4;
}
return partition;
}
}
小技巧:字符串比较相等时,把常量写在前面可以防止空指针异常。
FlowDriver.class 新增一下代码
//设置使用自定义类
job.setPartitionerClass(ProvincePartitioner.class);
//设置ReduceTasks的个数
job.setNumReduceTasks(5); //有5个分区,可以设置5到5以上
//修改输入路径
输出结果
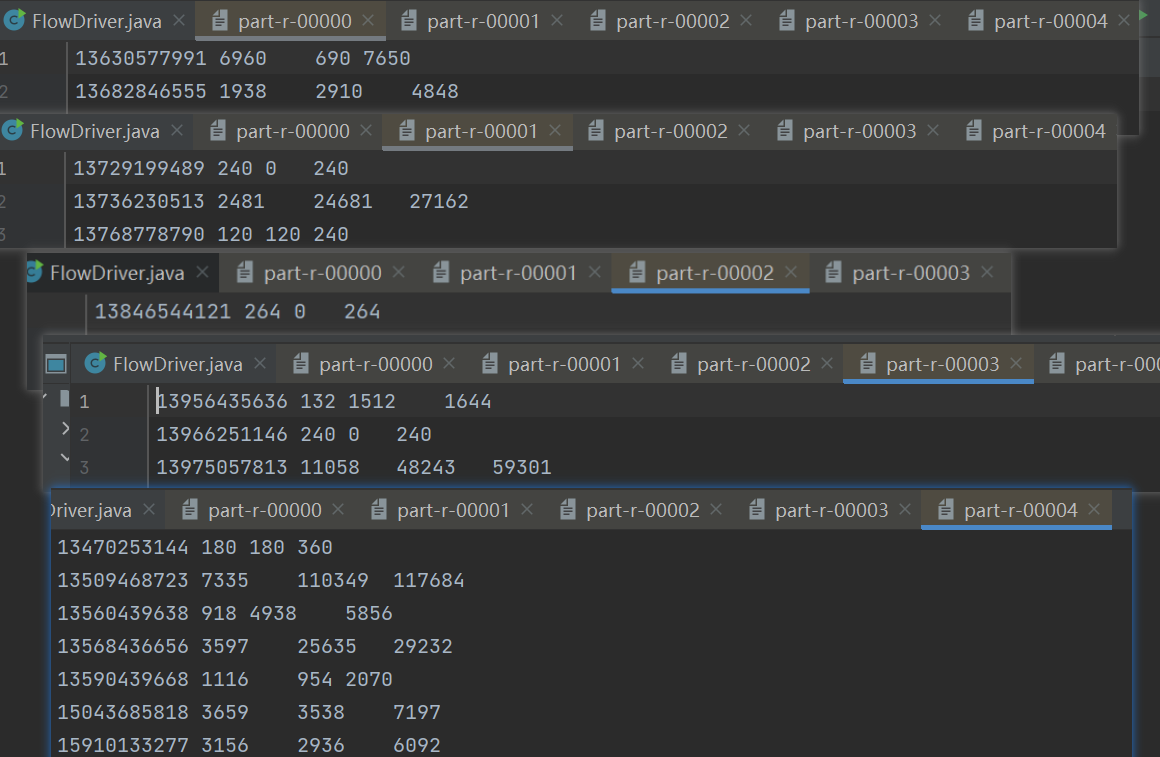
总结
1.ReduceTask的数量>getPartition结果的数,则会产生几个空的输出文件。
2.1<ReduceTask的数量<getPartition结果的数,有一部分分区数据没有地方放,报错。
3.ReduceTask的数量=1,最终只会产生一个输出文件。
4.分区号必须从0开始累加
3.3 WritableComparable排序
概述
MapTask和ReduceTask均会对数据按照key进行排序,该操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。
默认排序是按照字典顺序排序,默认排序方法是快速排序。
对于MapTask,它会将处理的结果暂时放到环形缓冲区,当环形缓存区使用率达到一定阈值后(80%),再对缓冲区中的数据进行一次快排。并将这些有序数据溢写到磁盘上。当所有数据处理完毕后,它会对磁盘上所有文件进行归并排序。
对于ReduceTask,它从每个MapTask上远程拷贝相应的数据文件,如果文件大小超过一定阈值,则合并后溢写磁盘上,否则存储在内存中。如果磁盘上文件数目达到一定阈值,则进行一次归并排序以生成一个更大文件。所有数据拷贝完毕后,ReduceTask统一对内存和磁盘上的所有数据进行一次归并排序。
自定义排序WritableComparable原理分析
bean对象做为key传输,需要实现WritableComparable接口重写compareTo方法,就可
以实现排序。WritableComparable是继承了Writable接口的
public interface WritableComparable<T> extends Writable, Comparable<T> {
}
public class FlowBean implements WritableComparable <FlowBean> {
@Override
public int compareTo(FlowBean bean) {
int result;
//按照总流量大小,倒序排列
if (this.sumFlow >bean.getSumFlow()) {
result =-1;
}else if (this.sumFlow < bean.getSumFlow()) {
result = 1;
}else {
result = 0;
}
return result;
}
}
1.WritableComparable 排序案例实操(全排序)
需求
根据序列化案例产生的结果文件再此对总流量进行倒序排序
输入数据D:\hadoop_data\input\inputpartition文件
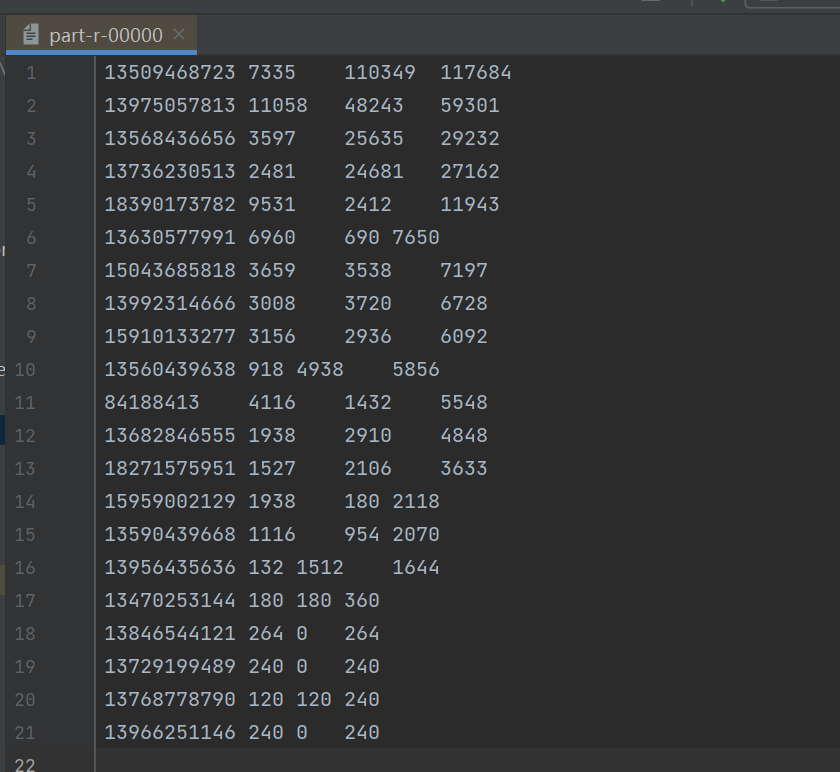
第一次处理后的数据 part-r-00000,在这个文件的基础上,按总流量进行倒序排序。
期望输出数据

一般需要进行两次MapReduce,因为是按照key排序,第一次MapReduce的key是电话号码,算出总流量,第二次MapReduce的key是FlowBean对象里的总流量。
需求分析
需求:根据手机的总流量进行倒序排序
输入数据

输出数据

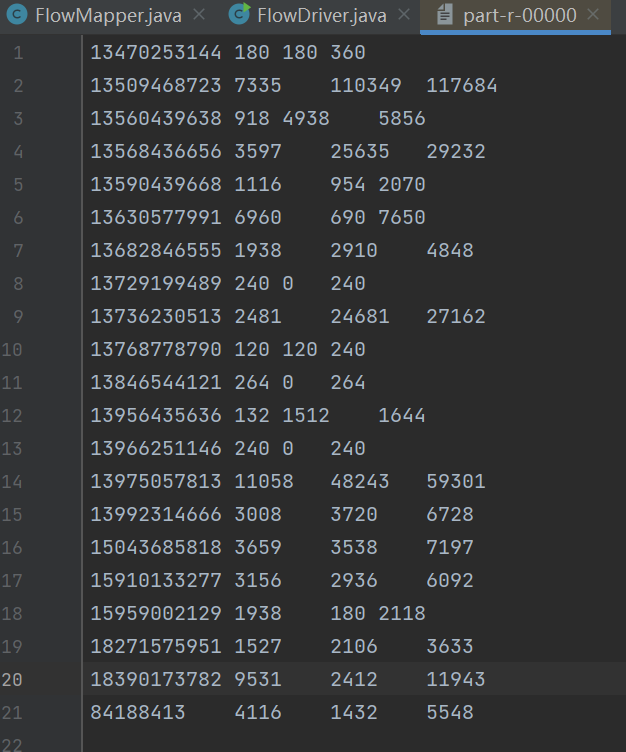
代码实现
FlowBean 类
package ranan.mapreduce.writableComparable;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* 1、定义类实现writable接口
* 2、重写序列化和反序列化方法
* 3、重写空参构造
* 4、toString方法
*/
public class FlowBean implements WritableComparable<FlowBean> {
private long upFlow; // 上行流量
private long downFlow; // 下行流量
private long sumFlow; // 总流量
// 空参构造
public FlowBean() {
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
public void setSumFlow() {
this.sumFlow = this.upFlow + this.downFlow;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
@Override
public void readFields(DataInput in) throws IOException {
this.upFlow = in.readLong();
this.downFlow = in.readLong();
this.sumFlow = in.readLong();
}
@Override
public String toString() {
return upFlow + "\t" + downFlow + "\t" + sumFlow;
}
@Override
public int compareTo(FlowBean bean) {
int result;
//按照总流量大小,倒序排列
if (this.sumFlow >bean.getSumFlow()) {
result =-1;
}else if (this.sumFlow < bean.getSumFlow()) {
result = 1;
}else {
result = 0;
}
return result;
}
}
FlowMapper 类
package ranan.mapreduce.writableComparable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FlowMapper extends Mapper<LongWritable, Text, FlowBean, Text> {
private FlowBean outK = new FlowBean();
private Text outV = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取一行
String line = value.toString();
//进行切割
String [] str = line.split("\t");
//封装
outV.set(str[0]);
outK.setUpFlow(Long.parseLong(str[1]));
outK.setDownFlow(Long.parseLong(str[2]));
outK.setSumFlow();
context.write(outK,outV);
}
}
FlowReducer 类
package ranan.mapreduce.partition;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowReducer extends Reducer<FlowBean,Text,Text,FlowBean> {
@Override
protected void reduce(FlowBean key, Iterable<Text> values, Reducer<FlowBean, Text, Text ,FlowBean>.Context context) throws IOException, InterruptedException {
for(Text value:values){
//这里是不需要合并key的,输出的key是手机号,输出的value是FlowBean
context.write(value,key);
}
}
}
FlowDriver 类
package ranan.mapreduce.partition;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FlowDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1 获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 设置jar
job.setJarByClass(FlowDriver.class);
// 3 关联mapper 和Reducer
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
// 4 设置mapper 输出的key和value类型
job.setMapOutputKeyClass(FlowBean.class);
job.setMapOutputValueClass(Text.class);
// 5 设置最终数据输出的key和value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 6 设置数据的输入路径和输出路径
FileInputFormat.setInputPaths(job, new Path("D:\\hadoop_data\\input\\inputpartition"));
FileOutputFormat.setOutputPath(job, new Path("D:\\hadoop_data\\output"));
// 7 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
输出结果
2.二次排序
需求:如果总流量相同,按上行流量从小到大排序
//写法1
@Override
public int compareTo(FlowBean bean) {
int result;
//按照总流量大小,倒序排列
if (this.sumFlow >bean.sumFlow) {
return -1;
}else if (this.sumFlow < bean.sumFlow) {
return 1;
}else {
if(this.upFlow>bean.upFlow){
return 1;
}else if(this.upFlow<bean.upFlow){
return -1;
}
else {
return 0;
}
}
}
//写法2
@Override
public int compareTo(FlowBean bean) {
int result;
//按照总流量大小,倒序排列
if (this.sumFlow == bean.sumFlow) {
//如果相同按上行流量从小到大排序
return (int)(this.upFlow - bean.upFlow);
}else {
return (int)(bean.sumFlow-this.sumFlow);
}
}
3.区内排序
需求:136 137 138 139 其他 分5个区,每个区按总流量降序排,相同按上行流量从小到大排序
用上面的代码其余不变,增加类ProvincePartitioner.class
package ranan.mapreduce.writableComparable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
import ranan.mapreduce.partition.FlowBean;
public class ProvincePartitioner extends Partitioner<FlowBean,Text> {
@Override
public int getPartition(FlowBean flowBean,Text text,int numPartitions) {
//text是手机号
String phone = text.toString().substring(0,3);
int partition;
//防止空指针异常,常量写在前面
if("136".equals(phone)){
partition=0;
}else if("137".equals(phone)){
partition=1;
}else if("138".equals(phone)){
partition=2;
}else if("139".equals(phone)){
partition=3;
}else {
partition=4;
}
return partition;
}
}
在FlowDriver挂载分区
//挂载分区
job.setPartitionerClass(ProvincePartitioner.class);
job.setNumReduceTasks(5);
Combiner合并(可选)
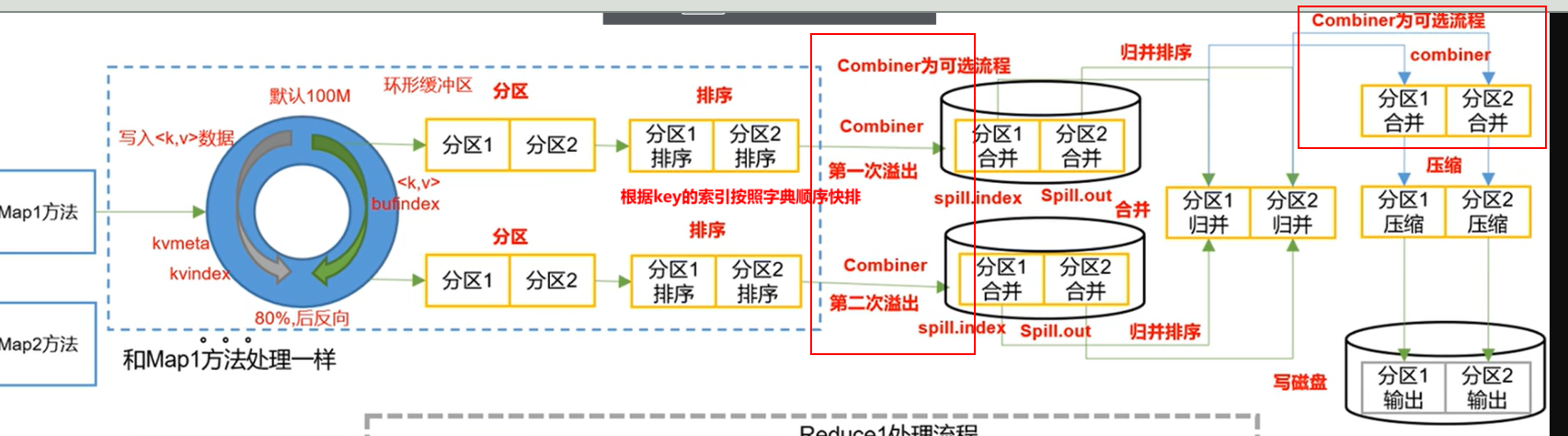
提前对(a,1)(a,1) 进行合并成(a,2),帮助MapReduce先处理一点,提高效率。
说明:
1.Combiner是MR程序中Mapper和Reducer之外的一种组件
2.Combiner组件的父类是Reducer
3.和Reducer的区别在于运行的位置,Combiner是在每一个MapTask所在节点运行,Reduce是接受全局所有Mapper的输出结果。
4.Combiner的意义是对每一个MapTask的输出进行局部汇总,以减少网络传输量
5.Combiner能够应用的前提是不能影响最终的业务逻辑,并且Combiner输出的KV应该跟Reducer输入的kv类型对应起来。
下图是不可以使用的场景

3.4 自定义Combiner案例
需求
基于WordCount案例,统计过程中对每一个MapTask的输出进行局部汇总,以减小网络传输量,采用Combiner功能
数据输入:D:\hadoop_data\input\combiner
//combiner.txt
xx rr
dd rr
yy rr
xx dd
期望结果
在Map阶段处理数据
<rr,3>
<xx,2>
<yy,1>
<dd,2>
方案1
1.增加一个WordCountCombiner类继承Reducer
2.在WordCountCombiner中 单词汇总、将统计结果输出
1.增加一个WordCountCombiner类继承Reducer
package ranan.mapreduce.combiner;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/*
1.继承Reducer在Combiner在Map阶段,输入的数据是Map传递过来的(Map的输出),输出给Reduce(Reduce的输入)
*/
public class WordCountCombiner extends Reducer <Text,IntWritable,Text, IntWritable> {
//2.重写reduce方法,遇见不同的key执行一次reduce
private IntWritable outV = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum =0;
for (IntWritable num:values) {
sum += num.get(); //num转化成int类型
}
outV.set(sum);
context.write(key,outV);
}
}
2.在job中进行配置,增加如下代码
job.setCombinerClass(WordCountCombiner.class);
3.执行结果,符合预期
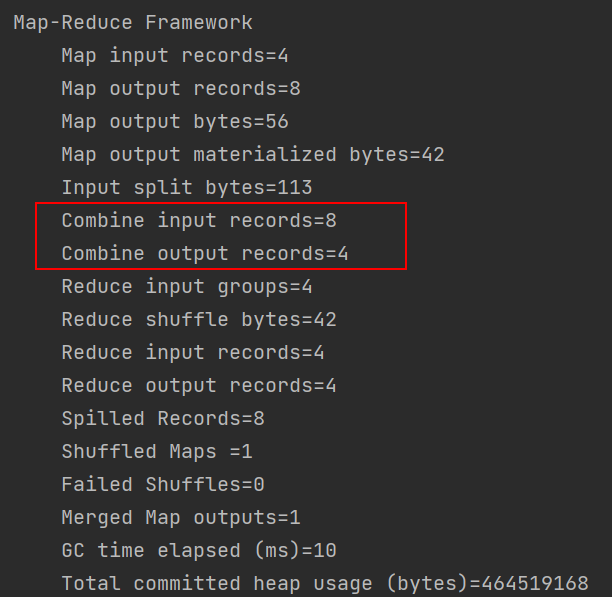
4.补充
如果把ReduceTask设置成0,不进行ruduce,shuffle阶段也会消失
方案2
我们发现WordCountReducer和WordCountCombiner实现的逻辑是一样的,所以将WordCountReducer作为Combiner,在WordCountDriver驱动类中指定。
job.setCombinerClass(WordCountReducer.class);
MapReduce04 框架原理Shuffle的更多相关文章
- MapReduce框架原理--Shuffle机制
Shuffle机制 Mapreduce确保每个reducer的输入都是按键排序的.系统执行排序的过程(Map方法之后,Reduce方法之前的数据处理过程)称之为Shuffle. partition分区 ...
- Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区
MapReduce工作流程 1.准备待处理文件 2.job提交前生成一个处理规划 3.将切片信息job.split,配置信息job.xml和我们自己写的jar包交给yarn 4.yarn根据切片规划计 ...
- Hadoop| MapperReduce02 框架原理
MapReduce框架原理 MapReduce核心思想 1)分布式的运算程序往往需要分成至少2个阶段. 2)第一个阶段的MapTask并发实例,完全并行运行,互不相干. 3)第二个阶段的ReduceT ...
- 简述MapReduce计算框架原理
1. MapReduce基本编程模型和框架 1.1 MapReduce抽象模型 大数据计算的核心思想是:分而治之.如下图所示.把大量的数据划分开来,分配给各个子任务来完成.再将结果合并到一起输出.注: ...
- java大数据最全课程学习笔记(6)--MapReduce精通(二)--MapReduce框架原理
目前CSDN,博客园,简书同步发表中,更多精彩欢迎访问我的gitee pages 目录 MapReduce精通(二) MapReduce框架原理 MapReduce工作流程 InputFormat数据 ...
- MapReduce框架原理
MapReduce框架原理 3.1 InputFormat数据输入 3.1.1 切片与MapTask并行度决定机制 1.问题引出 MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个J ...
- MapReduce05 框架原理OutPutFormat数据输出
目录 4.OutputFormat数据输出 OutputFormat接口实现类 自定义OutputFormat 自定义OutputFormat步骤 自定义OutputFormat案例 需求 需求分析 ...
- MapReduce03 框架原理InputFormat数据输入
目录 1 InputFormat数据输入 1.1 切片与MapTask并行度决定机制 问题引出 MapTask并行度决定机制 Job提交流程源码 切片源码 1.2 FileInputFormat切片机 ...
- Spark Shuffle原理、Shuffle操作问题解决和参数调优
摘要: 1 shuffle原理 1.1 mapreduce的shuffle原理 1.1.1 map task端操作 1.1.2 reduce task端操作 1.2 spark现在的SortShuff ...
随机推荐
- 洛谷 P6075 [JSOI2015]子集选取
链接:P6075 前言: 虽然其他大佬们的走分界线的方法比我巧妙多了,但还是提供一种思路. 题意: %&¥--@#直接看题面理解罢. 分析过程: 看到这样的题面我脑里第一反应就是DP,但是看到 ...
- cf2A Winner(implementation)
题意: N个回合. 每个回合:name score[名为name的这个人得了score分(可负可正)]. 问最后谁的累积分数是最高的.设为M.如果有好几个都得了M,找出这几个人中哪个最早回合累积分数超 ...
- poj 3041 Asteroids(最小点覆盖)
题意: N*N的矩阵,有K个敌人,坐标分别是(C1,C1),.....,(Rk,Ck). 有一个武器,每发射一次,可消掉某行或某列上的所有的敌人. 问消灭所有敌人最少需要多少发. 思路: 二分建图:左 ...
- Tcpdump 常用命令、参数记录
一.介绍 一个关于Centos Tcpdump 的个人工作总结. 二.参数介绍: 1. -i: 指定要进行抓包的网卡 2.-s0 :表示每个报文的大小是接收到的指定大小,如果没有这个选项,则超过 ...
- 解决虚拟机安装linux系统无法全屏问题 & vmtools安装
修改设置 1) 如下图右单击虚拟机名,选择[settings-],调出虚拟机设置界面. 2) 在设置界面选择[hardware]->[CD/DVD2(IDE)]->[Connection] ...
- 开发规范 - UML图
依赖关系是用一套带箭头的虚线表示,他通常描述一个对象在运行期间会用到另一个对象的关系.如图为例码农只有在工作的时候才会用到 Mac 电脑,所以这种依赖关系是依赖于运行状态的.通常情况下是在程序里面通过 ...
- Effective Python(3)- 了解 bytes 与 str 的区别
Python 有两种类型可以表示字符序列 bytes:实例包含的是原始数据,即 8 位的无符号值(通常按照 ASCII 编码标准来显示) str:实例包含的是 Unicode 码点(code poin ...
- js实现全选与全部取消功能
function checkAll() { //把所有参与选择的checkbox使用相同的name,这里为"num_iid" var eles = document.getE ...
- Python 爬取 猫眼
1. import requests import re import pymongo MONGO_URL='localhost'#建立连接 MONGO_DB='Maoyan'#创建数据库 clien ...
- [bzoj5417]你的名字
先考虑l=1,r=|s|的部分分,需要求出t每一个前缀的不是s子串的最长后缀,记作pp[k],有以下限制:1.pp[pos[k]]<len(pos[k]表示k的某一个结束位置),因为不能被匹配 ...