Hive(十)【窗口函数】
一.定义
官网介绍:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+WindowingAndAnalytics
窗口函数属于sql中比较高级的函数,mysql从8.0版本才支持窗口函数,mysql5.6,5.7都有窗口函数,oracle 里面一直支持窗口函数,hive也支持窗口函数
窗口函数=函数+窗口
窗口:函数在运算时,我们可以指定函数运算的数据范围
Hive中以下函数是窗口函数:
窗口函数:
LEAD LEAD(col,n, default_val):往后第n行数据 col 列名 ;n 往后第几行 默认为1 ; 默认值 默认null
LAG LAG(col,n,default_val):往前第n行数据 ; col 列名 n 往前第几行 默认为1; 默认值 默认null
FIRST_VALUE 在当前窗口下的第一个值 FIRST_VALUE (col,true/false) 如果设置为true,则跳过空值。
LAST_VALUE 在当前窗口下的最后一个值 FIRST_VALUE (col,true/false)如果设置为true,则跳过空值。
标准聚合函数
- COUNT
- SUM
- MIN
- MAX
- AVG
分析排名函数
RANK() 排序相同时会重复,总数不会变
DENSE_RANK() 排序相同时会重复,总数会减少
ROW_NUMBER() 会根据顺序计算
NTILE():根据窗口排序,将数据分为n组,若查找前50%,则条件为n/2组
二.语法
(1)窗口函数 over([partition by 字段] [order by 字段] [ 窗口语句])
partition by 给查出来的结果集按照某个字段分区,分区以后,开窗的大小最大不会超过分区数据的大小
一旦分区之后,我们必须在单个分区内指定窗口。
order by 给分区内的数据按照某个字段排序
(2)窗口语句
(ROWS | RANGE) BETWEEN (UNBOUNDED | [num]) PRECEDING AND ([num] PRECEDING | CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
(ROWS | RANGE) BETWEEN CURRENT ROW AND (CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
(ROWS | RANGE) BETWEEN [num] FOLLOWING AND (UNBOUNDED | [num]) FOLLOWING
常见用法:rows between unbounded preceding and unbounded following
两种特殊情况
当指定ORDER BY缺少WINDOW子句时,WINDOW规范默认为RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW。
如果同时缺少ORDER BY和WINDOW子句,则WINDOW规范默认为ROW BETWEENUND UNBOUNDED PRECEDING和UNBOUNDED FOLLOWING。
三.需求练习一
需求说明
根据用户的消费记录统计一下需求
name orderdate cost
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94
需求1: 查询在2017年4月份购买过的顾客及总人数
需求3: 查询顾客的购买明细及月购买总额
需求3: 上述的场景, 将每个顾客的cost按照日期进行累加
需求4: 查询顾客购买明细以及上次的购买时间和下次购买时间
需求5: 查询顾客每个月第一次的购买时间 和 每个月的最后一次购买时间
数据准备
消费记录数据:business.txt
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94
建表
create table business(
name string,
orderdate string,
cost int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
导数据
load data local inpath "/opt/module/hive/datas/business.txt" into table business;
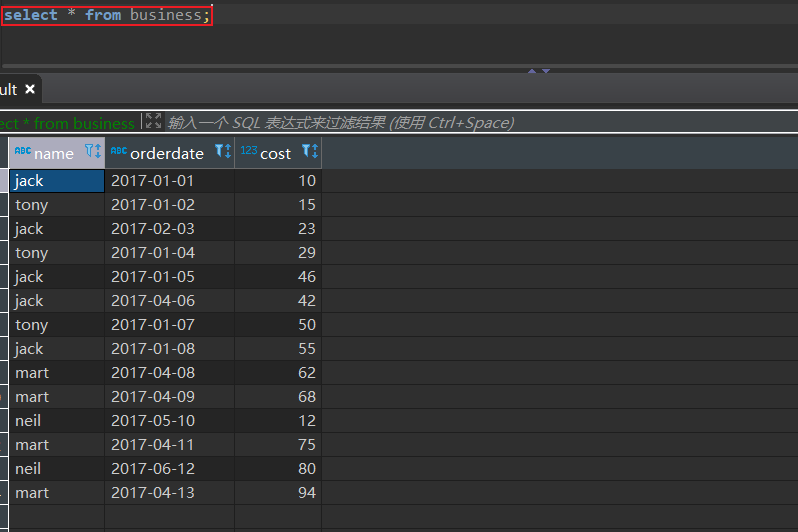
查询验证表数据
select * from business;
作为练习可以使用本地模式:set hive.exec.mode.local.auto=true;
count,sum
需求1
查询在2017年4月份购买过的顾客及总人数
select
name,
count(*) over()
from business
where substring(orderdate,1,7)='2017-04'
group by name;
结果

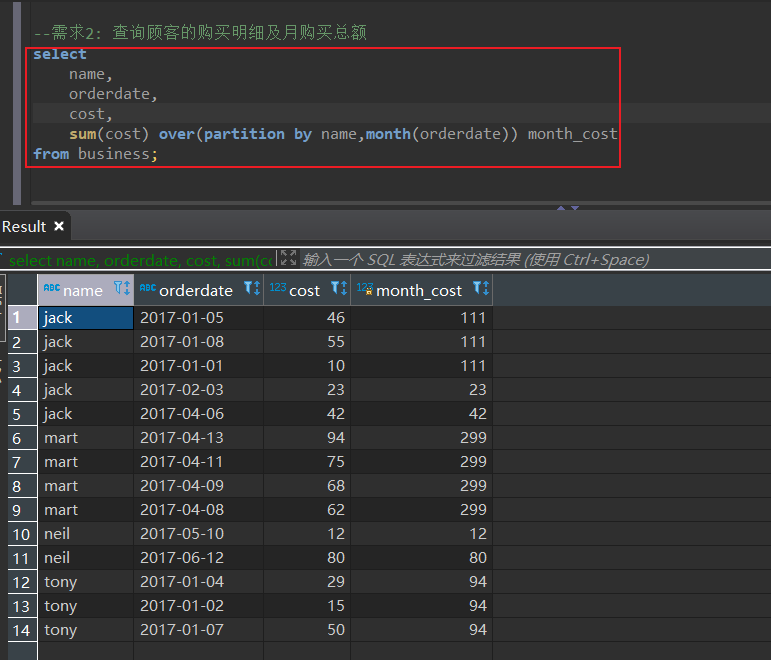
需求2
查询顾客的购买明细及月购买总额
select
name,
orderdate,
cost,
sum(cost) over(partition by name,month(orderdate)) month_cost
from business;
lag,lead
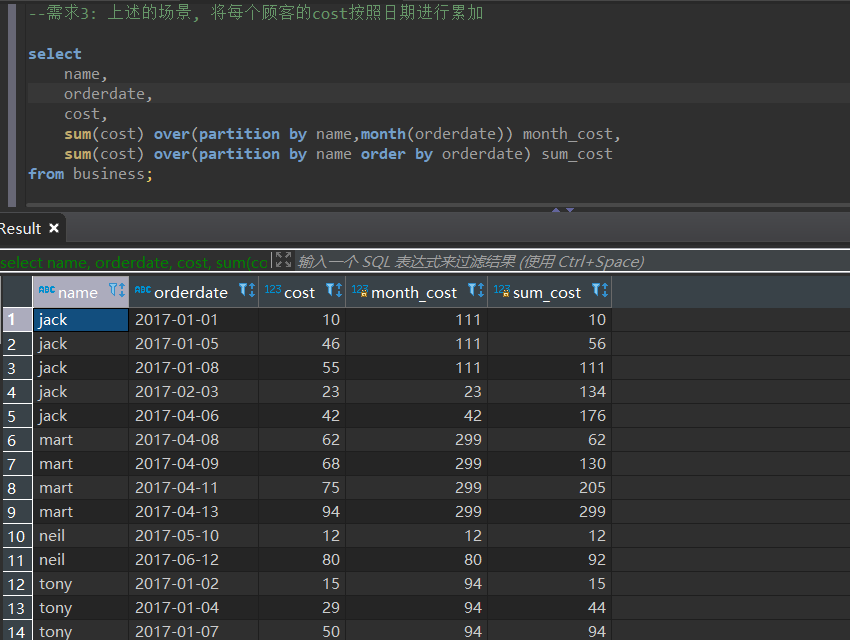
需求3
上述的场景,将每个顾客的cost按照日期进行累加
select
name,
orderdate,
cost,
sum(cost) over(partition by name,month(orderdate)) month_cost,
sum(cost) over(partition by name order by orderdate) sum_cost
from business;
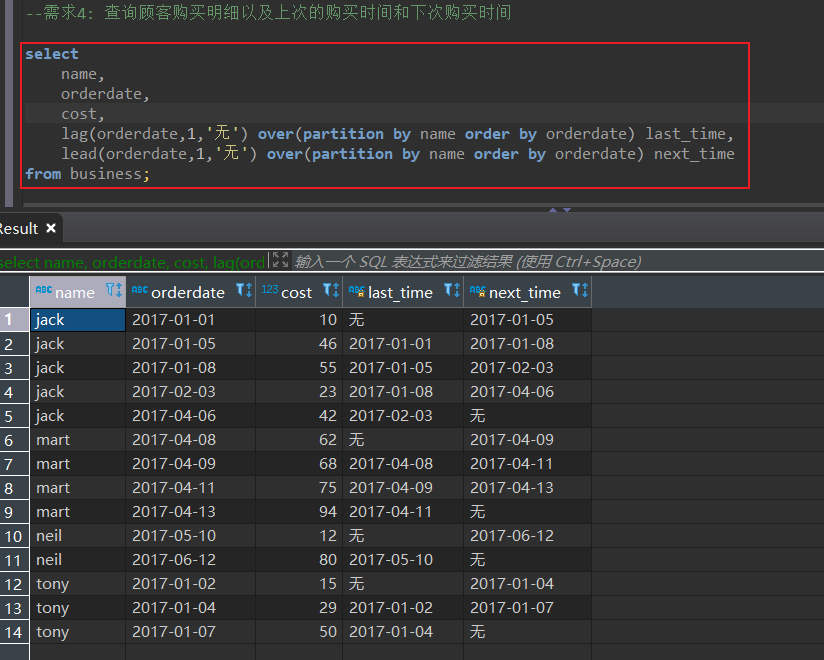
需求4
查询顾客购买明细以及上次的购买时间和下次购买时间
select
name,
orderdate,
cost,
lag(orderdate,1,'无') over(partition by name order by orderdate) last_time,
lead(orderdate,1,'无') over(partition by name order by orderdate) next_time
from business;
first_value,last_value
需求5
注意:LAST_VALUE和FIRST_VALUE 需要自定义windows字句,否则出现错误
select
name,
orderdate,
first_value(orderdate,false) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING) first_time,
last_value(orderdate,false) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING ) last_time
from business;

四.需求练习二
需求说明
计算成绩排名
name subject score
孙悟空 语文 87
孙悟空 数学 95
孙悟空 英语 68
大海 语文 94
大海 数学 56
大海 英语 84
宋宋 语文 64
宋宋 数学 86
宋宋 英语 84
婷婷 语文 65
婷婷 数学 85
婷婷 英语 78
数据准备
原始数据:score.txt
孙悟空 语文 87
孙悟空 数学 95
孙悟空 英语 68
大海 语文 94
大海 数学 56
大海 英语 84
宋宋 语文 64
宋宋 数学 86
宋宋 英语 84
婷婷 语文 65
婷婷 数学 85
婷婷 英语 78
建表
create table score(
name string,
subject string,
score int)
row format delimited fields terminated by "\t";
导数据
load data local inpath '/opt/module/hive/datas/score.txt' into table score;
验证表数据
select * from score;
rank,dense_rank,row_number
需求1
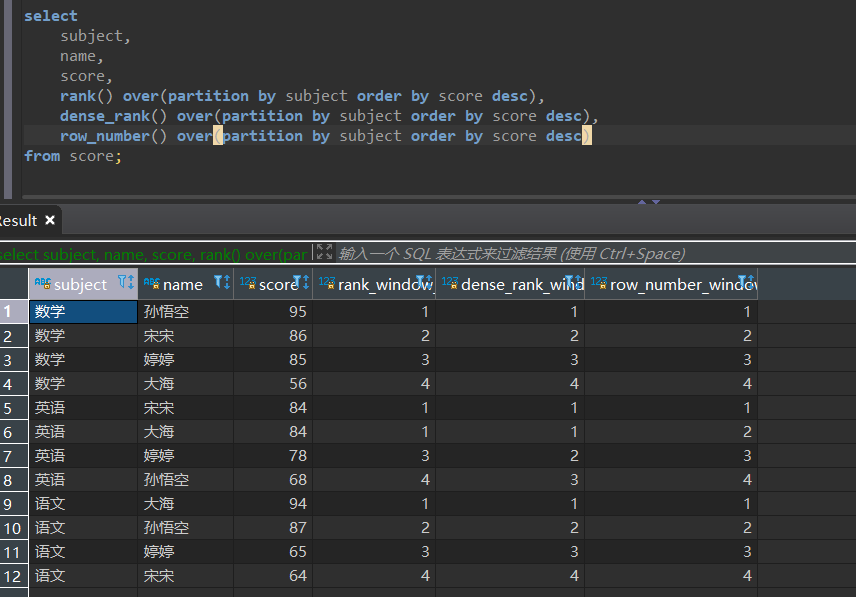
计算各科成绩排名
select
subject,
name,
score,
rank() over(partition by subject order by score desc),
dense_rank() over(partition by subject order by score desc),
row_number() over(partition by subject order by score desc)
from score;
ntile
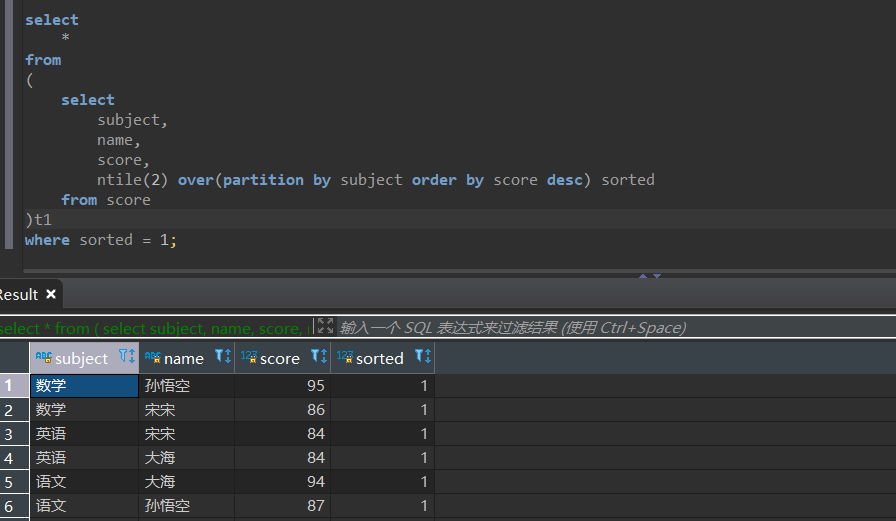
需求2
查看各科成绩前50%的学生成绩
select
*
from
(
select
subject,
name,
score,
ntile(2) over(partition by subject order by score desc) sorted
from score
)t1
where sorted = 1;
Hive(十)【窗口函数】的更多相关文章
- Hive分析窗口函数(一) SUM,AVG,MIN,MAX
Hive分析窗口函数(一) SUM,AVG,MIN,MAX Hive分析窗口函数(一) SUM,AVG,MIN,MAX Hive中提供了越来越多的分析函数,用于完成负责的统计分析.抽时间将所有的分析窗 ...
- 【Hadoop离线基础总结】hive的窗口函数
hive的窗口函数 概述 hive中一般求取TopN时就需要用到窗口函数 专业窗口函数一般有三个 rank() over dense rank() over row_number() over 实例 ...
- Hive学习之路 (十六)Hive分析窗口函数(四) LAG、LEAD、FIRST_VALUE和LAST_VALUE
数据准备 数据格式 cookie4.txt cookie1, ::,url2 cookie1, ::,url1 cookie1, ::,1url3 cookie1, ::,url6 cookie1, ...
- Hive学习之路 (十五)Hive分析窗口函数(三) CUME_DIST和PERCENT_RANK
这两个序列分析函数不是很常用,这里也练习一下. 数据准备 数据格式 cookie3.txt d1,user1, d1,user2, d1,user3, d2,user4, d2,user5, 创建表 ...
- Hive学习之路 (十四)Hive分析窗口函数(二) NTILE,ROW_NUMBER,RANK,DENSE_RANK
概述 本文中介绍前几个序列函数,NTILE,ROW_NUMBER,RANK,DENSE_RANK,下面会一一解释各自的用途. 注意: 序列函数不支持WINDOW子句.(ROWS BETWEEN) 数据 ...
- hive之窗口函数
窗口函数 1.相关函数说明 COVER():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变化 CURRENT ROW:当前行 n PRECEDING:往前n行数据 n FOLLO ...
- hive的窗口函数1
Hive中提供了越来越多的分析函数,用于完成负责的统计分析.抽时间将所有的分析窗口函数理一遍,将陆续发布.今天先看几个基础的,SUM.AVG.MIN.MAX.用于实现分组内所有和连续累积的统计. 1. ...
- 【Hive】窗口函数
我们都知道在sql中有一类函数叫做聚合函数,例如sum().avg().max()等等, 这类函数可以将多行数据按照规则聚集为一行,一般来讲聚集后的行数是要少于聚集前的行数的. 但是有时我们想要既显示 ...
- hive 中窗口函数row_number,rank,dense_ran,ntile分析函数的用法
hive中一般取top n时,row_number(),rank,dense_ran()这三个函数就派上用场了, 先简单说下这三函数都是排名的,不过呢还有点细微的区别. 通过代码运行结果一看就明白了. ...
随机推荐
- linked-list-cycle-ii leetcode C++
Given a linked list, return the node where the cycle begins. If there is no cycle, returnnull. Follo ...
- JAVA笔记3__字符串String类/对象一对一关联
import java.lang.String; import java.util.Scanner; public class Main { public static void main(Strin ...
- 攻防环境配置大全(iss/apache/nginx/tomcat/jboss/weblogic)
一.IIS/apache/nginx/tomcat 介绍 1.asp aspx 只能在微软系统的iis中间件运行 [asp+IIS+access(扩展名为mdb)].aspx+mssql+iis结合, ...
- Kubernetes(k8s)部署redis-cluster集群
Redis Cluster 提供了一种运行 Redis 安装的方法,其中数据 在多个 Redis 节点之间自动分片. Redis Cluster 还在分区期间提供了一定程度的可用性,这实际上是在某些节 ...
- Electron结合React,在渲染进程中使用 node 模块
Electron结合React,在渲染进程中使用 node 模块 问题 将create-react-app与electron集成在了一个项目中.但是在React中无法使用electron.当在Reac ...
- SpringBoot Actuator — 埋点和监控
项目中看到了有埋点监控.报表.日志分析,有点兴趣想慢慢捣鼓一下 1. 数据埋点 监控机器环境的性能和业务流程或逻辑等各项数据,并根据这些数据生成对应的指标,那么我们就称为数据埋点.比如我们想知道某个接 ...
- Mac下查看 Java 安装目录位置和安装数量
/usr/libexec/java_home -V 第一个红框是安装数量, 第二个红框是目前正在使用的 JDK 版本位置
- Android Activity Deeplink启动来源获取源码分析
一.前言 目前有很多的业务模块提供了Deeplink服务,Deeplink简单来说就是对外部应用提供入口. 针对不同的跳入类型,app可能会选择提供不一致的服务,这个时候就需要对外部跳入的应用进行区分 ...
- 系统调用篇——SSDT
写在前面 此系列是本人一个字一个字码出来的,包括示例和实验截图.由于系统内核的复杂性,故可能有错误或者不全面的地方,如有错误,欢迎批评指正,本教程将会长期更新. 如有好的建议,欢迎反馈.码字不易, ...
- Netcat基础使用
netcat命令选项 本文参考文章链接 本文参考文章链接1 本文参考文章链接2 本文参考文章链接3 常用命令选项 ## 网络模式和代理相关 -l 监听,作服务器.不填时作客户端. -u UDP模式.不 ...