python爬虫--案例分析之针对简单的html文件
python爬虫常用的库:Python 库(urllib、BeautifulSoup、requests、scrapy)实现网页爬虫
python爬虫最简单案例分析: 对一个html文件进行分解,获取里面想要的数据
- <html lang="en">
- <head>
- <meta charset="UTF-8"/>
- <title>测试bs4</title>
- </head>
- <body>
- <div>
- <p>百里守约</p>
- </div>
- <div class="song">
- <p>李清照</p>
- <p>王安石</p>
- <p>苏轼</p>
- <p>柳宗元</p>
- <a href="http://www.song.com/" title="赵匡胤" target="_self">
- <span>this is span</span>
- 宋朝是最强大的王朝,不是军队的强大,而是经济很强大,国民都很有钱</a>
- <a href="" class="du">总为浮云能蔽日,长安不见使人愁</a>
- <img src="http://www.baidu.com/meinv.jpg" alt=""/>
- </div>
- <div class="tang">
- <ul>
- <li><a href="http://www.baidu.com" title="qing">清明时节雨纷纷,路上行人欲断魂,借问酒家何处有,牧童遥指杏花村</a></li>
- <li><a href="http://www.163.com" title="qin">秦时明月汉时关,万里长征人未还,但使龙城飞将在,不教胡马度阴山</a></li>
- <li><a href="http://www.126.com" alt="qi">岐王宅里寻常见,崔九堂前几度闻,正是江南好风景,落花时节又逢君</a></li>
- <li><a href="http://www.sina.com" class="du">杜甫</a></li>
- <li><a href="http://www.dudu.com" class="du">杜牧</a></li>
- <li><b>杜小月</b></li>
- <li><i>度蜜月</i></li>
- <li><a href="http://www.haha.com" id="feng">凤凰台上凤凰游,凤去台空江自流,吴宫花草埋幽径,晋代衣冠成古丘</a></li>
- </ul>
- </div>
- </body>
- </html>
- import requests
- from lxml import etree
- tree = etree.parse("E:\odoo14\odoo14\myaddons\demo.html") # 获取html文件
- tang_info = tree.xpath("//div[@class='tang']/ul/li/a/text()") # 获取标签里的文本
- print('tang_info', tang_info)
- # "tang_info ['清明时节雨纷纷,路上行人欲断魂,借问酒家何处有,牧童遥指杏花村', '秦时明月汉时关,万里长征人未还,但使龙城飞将在,不教胡马度阴山', '岐王宅里寻常见,崔九堂前几度闻,正是江南好风景,落花时节又逢君', '杜甫', '杜牧', '凤凰台上凤凰游,凤去台空江自流,吴宫花草埋幽径,晋代衣冠成古丘']"
- song_info = tree.xpath("//div[@class='song']/p/text()") #找到div的class 是song的,标签是p的文本
- print('song_info', song_info)
- # 结果 "song_info ['李清照', '王安石', '苏轼', '柳宗元']"
- song_src = tree.xpath("//div[@class='song']/img/@src") #找 到div的class 是song的,的img属性
- print('song_src', song_src) # song_src ['http://www.baidu.com/meinv.jpg']
song_src_a = tree.xpath("//div[@class='song']/a/text()")
print('song_src_a', song_src_a)
# song_src_a ['\n ', '\n 宋朝是最强大的王朝,不是军队的强大,而是经济很强大,国民都很有钱', '总为浮云能蔽日,长安不见使人愁']
关于xpath路径的写法:XPath(全称XML Path Languang),即XML路径语言,是一种在XML文档中查找信息的语言。
1、/ 表示从根节点选取
2、// 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
3、@ 选取属性 返回所指元素的文本内容。
4、text() 返回所指元素的文本内容
4.1、string() 函数会得到所指元素的所有节点文本内容,这些文本讲会被拼接成一个字符串。
4.3、data():data()函数和string()函数通用,而且不建议经常使用data()函数,有数据表明,该函数会影响XPath的性能。
注意:爬取内容都为数字的时候只能使用data(),不能使用text()或 string(),因为XPath不支持字符串做数学运算。
案例:song_info = tree.xpath("//div[@class='song']/p/text()") #找到div的class 是song的,标签是p的文本
5.查找页面上第一个form元素://form[1]
6.查找页面上id为loginForm的form元素://form[@id=‘loginForm’]
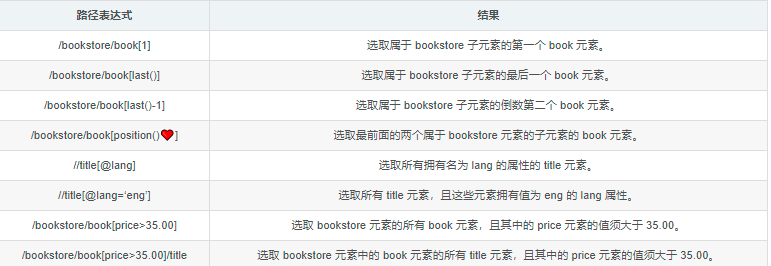
7、/bookstore/book[1] 选取属于 bookstore 子元素的第一个 book 元素。
8、/bookstore/book[last()] 选取属于 bookstore 子元素的最后一个 book 元素。
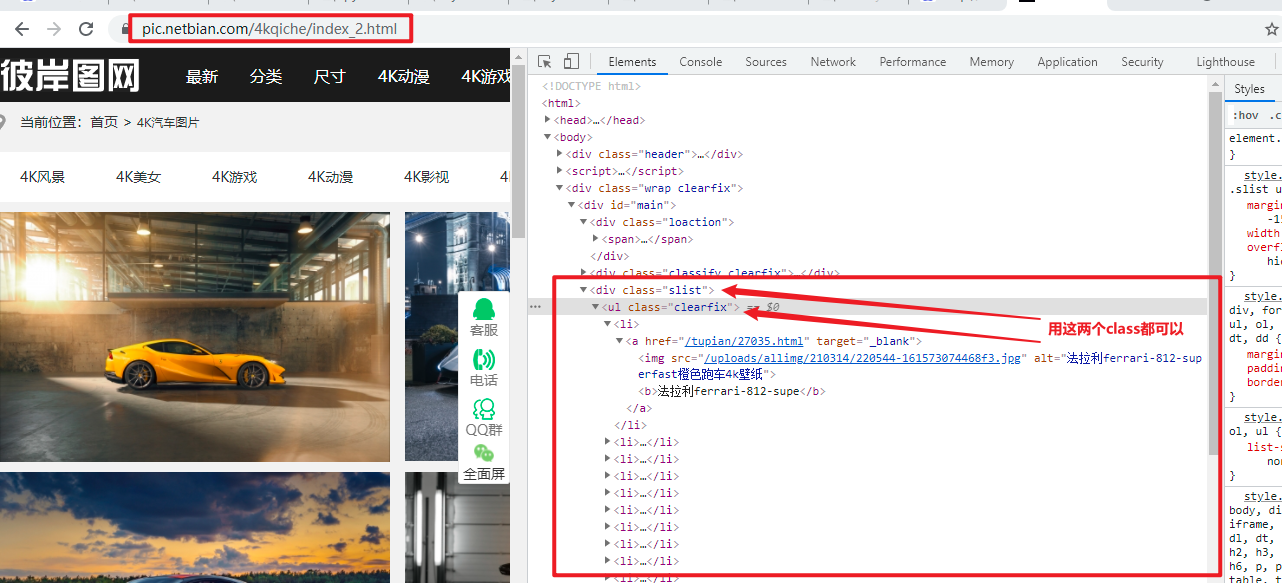
案例2:分析结构:
链接:首页 url = 'http://pic.netbian.com/4kqiche/'
- 后面分页:url = 'https://pic.netbian.com/4kqiche/index_%s.html' % page
- import requests
- from lxml import etree
- headers = {
- 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
- }
- # url = 'http://pic.netbian.com/4kdongman/'
- for page in range(1, 23):
- if page == 1:
- url = 'http://pic.netbian.com/4kqiche/'
- else:
- url = 'https://pic.netbian.com/4kqiche/index_%s.html' % page
- response = requests.get(url=url, headers=headers)
- # response.encoding = 'utf-8' #手动设定响应数据的编码
- page_text = response.text
- # 数据解析(图片地址,图片名称)
- tree = etree.HTML(page_text)
- # li_list = tree.xpath('//div[@class="slist"]/ul/li')
- li_list = tree.xpath('//ul[@class="clearfix"]/li')
- print('------------page--------------:', page)
- for li in li_list:
- # 局部内容解析一定是以./开头。etree和element都可以调用xpath
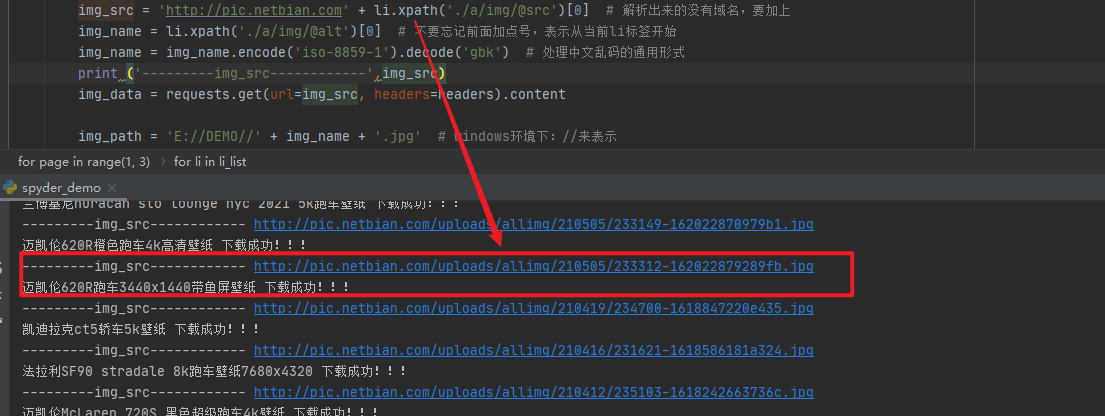
- img_src = 'http://pic.netbian.com' + li.xpath('./a/img/@src')[0] # 解析出来的没有域名,要加上
- img_name = li.xpath('./a/img/@alt')[0] # 不要忘记前面加点号,表示从当前li标签开始
- img_name = img_name.encode('iso-8859-1').decode('gbk') # 处理中文乱码的通用形式
- img_data = requests.get(url=img_src, headers=headers).content
- img_path = 'E://DEMO//' + img_name + '.jpg' # windows环境下://来表示
- with open(img_path, 'wb') as fp:
- fp.write(img_data)
- print(img_name, '下载成功!!!')
python爬虫--案例分析之针对简单的html文件的更多相关文章
- python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图 一.分析网站 1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏. 2.按F12打开开发者工具,刷新网页,这时网页回弹到综合 ...
- Python爬虫教程-14-爬虫使用filecookiejar保存cookie文件(人人网)
Python爬虫教程-14-爬虫使用filecookiejar保存cookie文件(人人网) 上一篇介绍了利用CookieJar访问人人网,本篇将使用filecookiejar将cookie以文件形式 ...
- 【Python爬虫案例】用Python爬取李子柒B站视频数据
一.视频数据结果 今天是2021.12.7号,前几天用python爬取了李子柒的油管评论并做了数据分析,可移步至: https://www.cnblogs.com/mashukui/p/1622025 ...
- 简单python爬虫案例(爬取慕课网全部实战课程信息)
技术选型 下载器是Requests 解析使用的是正则表达式 效果图: 准备好各个包 # -*- coding: utf-8 -*- import requests #第三方下载器 import re ...
- 【Python爬虫案例学习】分析Ajax请求并抓取今日头条街拍图片
1.抓取索引页内容 利用requests请求目标站点,得到索引网页HTML代码,返回结果. from urllib.parse import urlencode from requests.excep ...
- 【Python爬虫案例学习】python爬取淘宝里的手机报价并以价格排序
第一步: 先分析这个url,"?"后面的都是它的关键字,requests中get函数的关键字的参数是params,post函数的关键字参数是data, 关键字用字典的形式传进去,这 ...
- 【Python爬虫案例学习】Python爬取天涯论坛评论
用到的包有requests - BeautSoup 我爬的是天涯论坛的财经论坛:'http://bbs.tianya.cn/list.jsp?item=develop' 它里面的其中的一个帖子的URL ...
- 【Python爬虫案例学习】下载某图片网站的所有图集
前言 其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup. 其实就几行代码,但希望没有开发基础的人也能一下子看明白,所以大神请绕行. 基本环境配置 python 版本:2.7 ...
- python爬虫案例:使用XPath爬网页图片
用XPath来做一个简单的爬虫,尝试爬取某个贴吧里的所有帖子,并且将该这个帖子里每个楼层发布的图片下载到本地. # -*- coding:utf-8 -*- import urllib import ...
随机推荐
- Halcon 纹理缺陷检测 apply_texture_inspection_model
在纹理中找瑕疵.基于高斯混合模型(GMM)分类器的纹理检查模型,适用于图像金字塔,可以分析纹理的多个频率范围. [要求]训练样本,必须完美无瑕疵. [步骤] 1.创建模型 create_texture ...
- 【NX二次开发】获取尺寸信息UF_DRF_ask_draft_aid_text_info
获取尺寸信息UF_DRF_ask_draft_aid_text_info 例如获取下面这三个的尺寸信息. 图1 输出结果: 10 <T+0.1!-0.1> 图2 输出结果: 10 < ...
- Pytest学习笔记5-conftest.py的用法
前言 在之前介绍fixture的文章中,我们使用到了conftest.py文件,那么conftest.py文件到底该如何使用呢,下面我们就来详细了解一下conftest.py文件的特点和使用方法吧 什 ...
- golang 模板语法使不解析html标签及特殊字符
场景 有时候需要使用go的模板语法,比如说用go 去渲染html页面的时候,再比如说用go的模板搞代码生成的时候.这时候可能会遇到一个麻烦,不想转译的特殊字符被转译了. 我遇到的情况是写代码生成器的时 ...
- ECMAScript 2021 正式确认
ECMAScript 2021 主要包含内容: ECMAScript 2021 于2021年6月22日获得 ECMA International 的批准.ECMAScript 是标准化的 JavaSc ...
- Xmanager6 企业版安装
Xmanager6 企业版安装 链接:https://pan.baidu.com/s/1QZOD0iPd4WbVHBVXIbJ-fw 提取码:ebkl 一.安装教程 1.1 下载解压,双击安装exe主 ...
- 16 自动发布PHP项目
#!/bin/bash export PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin PHP_NAME=$1 DATE ...
- Docker:docker部署redis
docker镜像库拉取镜像 # 下载镜像 docker pull redis:4.0 查看镜像 # 查看下载镜像 docker images 启动镜像 # 启动镜像 docker run --na ...
- 计算机网络体系结构整理-第二单元IP技术
IP技术 1.IPV4 Ipv4的报头格式 Ipv4地址分为ABCDE类, 类别 IP地址范围 私有IP地址范围 A 0.0.0.0-127.255.255.255 10.0.0.0-10.255.2 ...
- C语言:按相反顺序输出字符
#include <stdio.h> void pailie(int n) { char next; if (n<=1) { next=getchar(); putchar(next ...