mysql join语句的执行流程是怎么样的
mysql join语句的执行流程是怎么样的
join语句是使用十分频繁的sql语句,同样结果的join语句,写法不同会有非常大的性能差距。
select * from t1 straight_join t2 on (t1.a=t2.a);a字段都有索引
TRAIGHT_JOIN语法能指定使用左边的表作为join语句的驱动表,join是让执行器自动选择。以上语句会选择t1作为驱动表。
join语句,mysql内部执行时候会采用2中算法。一个是NLJ(Index Nested-Loop Join)。一个是BNL(Block Nested-Loop Join)
NLJ:在join语句执行过程中,如果可以使用到被驱动表的索引,我们称之为“Index Nested-Loop Join”,简称 NLJ。
驱动表是走全表扫描,而被驱动表是走树搜索,所以驱动表行数越小越好。扫描行数多,性能影响更大,因此应该让小表来做驱动表。
如果驱动表有索引,被驱动表没有索引,这种情况下,驱动表全表扫描后,去被驱动表中匹配where语句的条件,在被驱动表找一条数据又是全表扫描。这样整个join扫描行数会内指数级别扩大。这种叫“Simple Nested-Loop Join”算法。
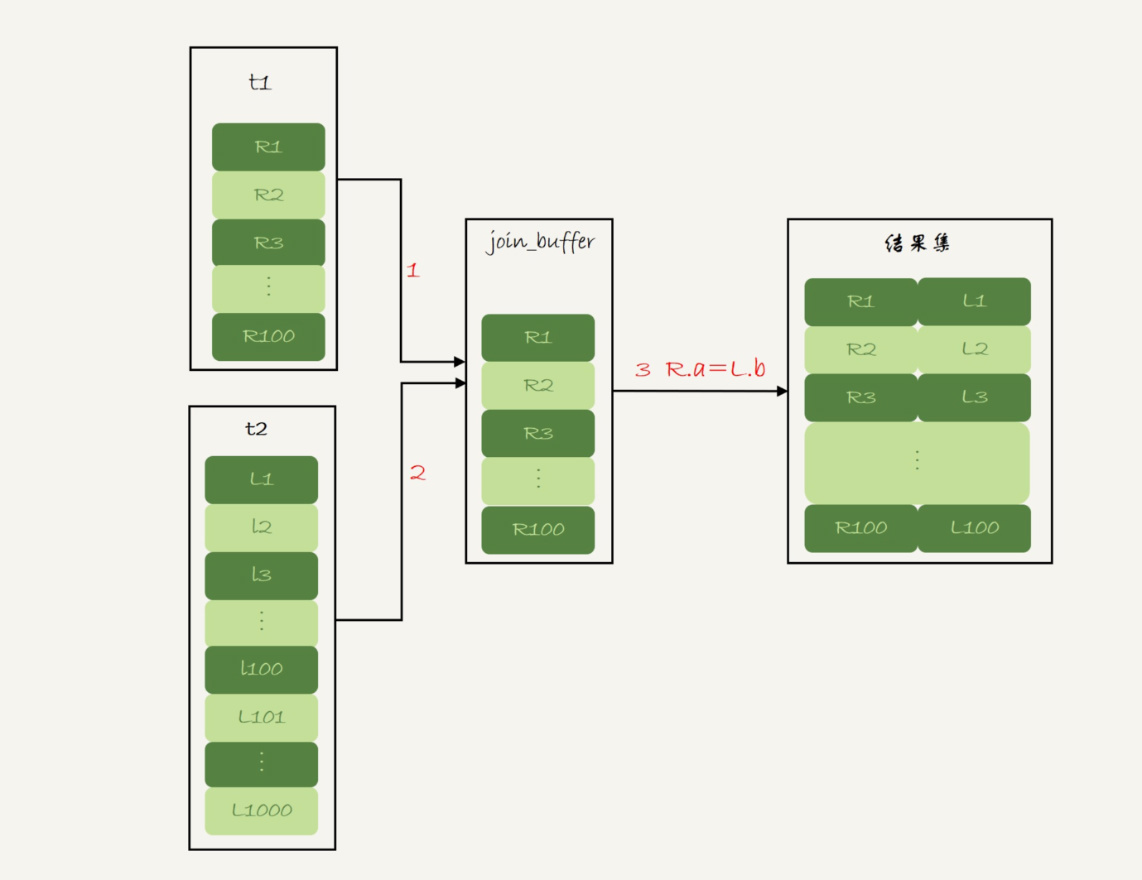
基于第五点,这种情况太笨重。所以msql没有采用”Simple Nested-Loop Join”算法,而是叫“Block Nested-Loop Join”的算法,简称 BNL。被驱动表没有索引情况下,他的逻辑流程是这样的:
把表 t1 的数据读入线程内存 join_buffer 中,由于我们这个语句中写的是 select *,因此是把整个表 t1 放入了内存;
扫描表 t2,把表 t2 中的每一行取出来,跟 join_buffer 中的数据做对比,满足 join 条件的,作为结果集的一部分返回。
explain语句查询出来会有
use join buffer (block nested loop)关键字join语句采用BNL算法,虽然对表 t1(100行) 和 t2(1000行) 都做了一次全表扫描,因此总的扫描行数是1100。由于 join_buffer 是以无序数组的方式组织的,因此对表 t2 中的每一行,都要做 100 次判断,总共需要在内存中做的判断次数是:100*1000=10 万次。对比simple Nested-Loop Join算法他是在内存中做对比计算。能大大提供性能。
join_buffer 的大小是由参数
join_buffer_size设定的,默认值是 256k。如果放不下表 t1 的所有数据话,策略很简单,就是分段放。就是放多少先处理多少先作为结果集返回,然后清空join_buffer,继续读取后面的数据。所以考虑到join_buffer大小有限,让小表作为驱动表,分段情况下,分段次数少。也应该让小表作为驱动表。
在决定哪个表做驱动表的时候,应该是两个表按照各自的条件过滤,过滤完成之后,计算参与 join 的各个字段的总数据量,数据量小的那个表,就是“小表”,应该作为驱动表。
join语句优化:
mysql在join语句时,内部做了一些优化,即:Multi-Range Read 优化 (MRR)。这个优化的主要目的是尽量使用顺序读盘。原理是:mysql的索引数据目录中,都是有序的,我们读入数据后,按主键排下序。这样就极大可能在磁盘是顺序读盘。这引入了read_rnd_buffer ,它的大小是由 read_rnd_buffer_size 参数控制的。
如果你想要稳定地使用 MRR 优化的话,需要设置set optimizer_switch="mrr_cost_based=off"。(官方文档的说法,是现在的优化器策略,判断消耗的时候,会更倾向于不使用 MRR,把 mrr_cost_based 设置为 off,就是固定使用 MRR 了。)explain语句也会有
use MRR关键字在使用BNL算法时候,引擎是一行一行读取数据。这样就用不上MRR算法优化,所以采取了BKA (Batched Key Access)算法。他可以一次性从驱动表多读一些数据,这些数据临时放在join_buff中。(之前BNL算法用不上join_buff,就利用了这个空间)。
NBL算法优化后的BKA算法后,执行流程如下:
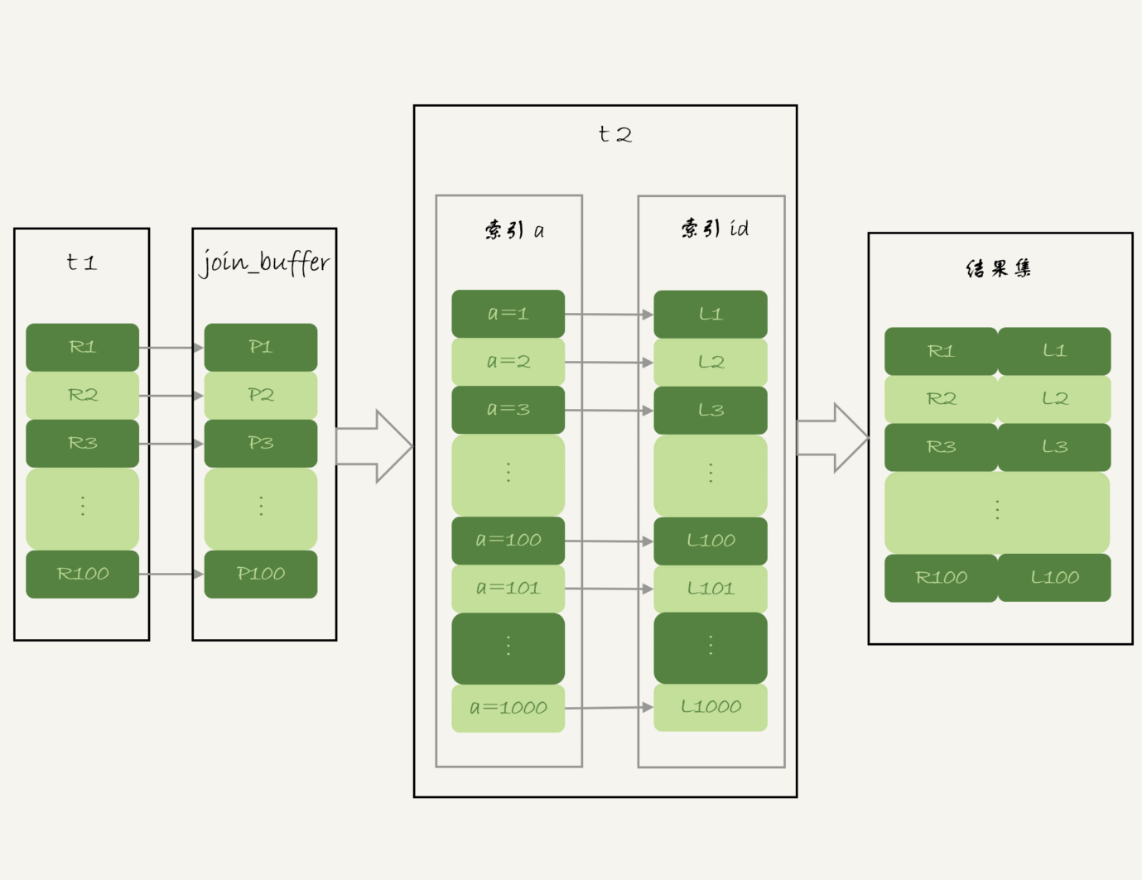
如果 join buffer 放不下 P1~P100 的所有数据,就会把这 100 行数据分成多段执行上图的流程。如果要使用 BKA 优化算法的话,你需要在执行 SQL 语句之前,先设置
set optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';前两个参数的作用是要启用 MRR。这么做的原因是,BKA 算法的优化要依赖于 MRR。BNL算法数据太大,稍不主机就会极大影响mysql服务性能,导致Buffer Pool命中率变低。大表 join 操作虽然对 IO 有影响,但是在语句执行结束后,对 IO 的影响也就结束了。但是,对 Buffer Pool 的影响就是持续性的,需要依靠后续的查询请求慢慢恢复内存命中率。
BNL 算法对系统的影响主要包括三个方面:
- 可能会多次扫描被驱动表,占用磁盘 IO 资源;
- 判断 join 条件需要执行 M*N 次对比(M、N 分别是两张表的行数),如果是大表就会占用非常多的 CPU 资源;
- 可能会导致 Buffer Pool 的热数据被淘汰,影响内存命中率。
BNL算法优化:
- BNL 转 BKA算法,在驱动表和被驱动表建索引,如果不方便建索引(数据大,join语句不频繁),可以人工主动使用临时表中转,拆分多个语句转化成BKA算法。
- hash join。条件匹配是n x m级别计算,如果 join_buffer 里面维护的不是一个无序数组,而是一个哈希表的话,那么就不是 10 亿次判断,而是 100 万次 hash 查找。mysql不支持哈希 join。并且,MySQL 官方的 roadmap,也是迟迟没有把这个优化排上议程。备注:mysql8.0已经支持
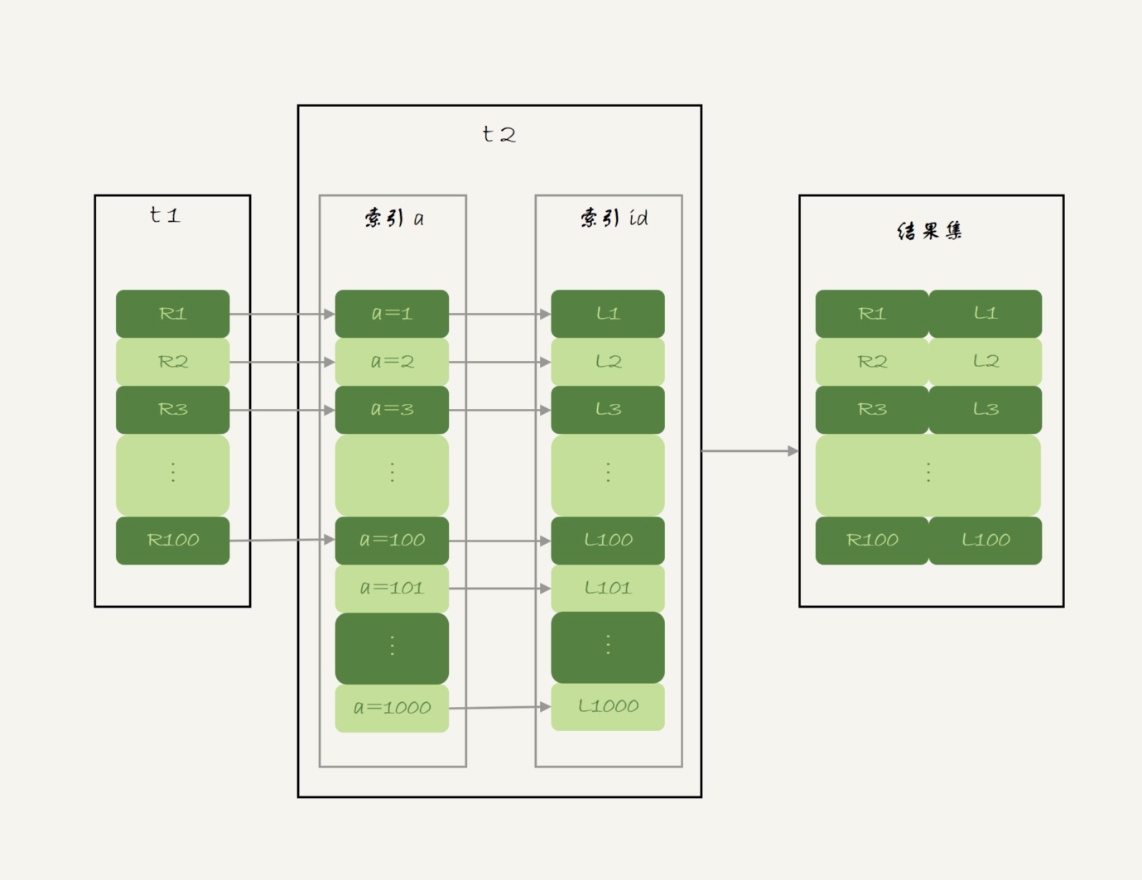
执行流程:
- 从表 t1 中读入一行数据 R;
- 从数据行 R 中,取出 a 字段到表 t2 里去查找;
- 取出表 t2 中满足条件的行,跟 R 组成一行,作为结果集的一部分;
- 重复执行步骤 1 到 3,直到表 t1 的末尾循环结束。
mysql join语句的执行流程是怎么样的的更多相关文章
- mysql update语句的执行流程是怎样的
update更新语句流程是怎么样的 update更新语句基本流程也会查询select流程一样,都会走一遍. update涉及更新数据,会对行加dml写锁,这个DML读锁是互斥的.其他dml写锁需要等待 ...
- 步步深入:MySQL架构总览->查询执行流程->SQL解析顺序
前言: 一直是想知道一条SQL语句是怎么被执行的,它执行的顺序是怎样的,然后查看总结各方资料,就有了下面这一篇博文了. 本文将从MySQL总体架构--->查询执行流程--->语句执行顺序来 ...
- MySQL架构总览->查询执行流程->SQL解析顺序
Reference: https://www.cnblogs.com/annsshadow/p/5037667.html 前言: 一直是想知道一条SQL语句是怎么被执行的,它执行的顺序是怎样的,然后 ...
- 步步深入MySQL:架构->查询执行流程->SQL解析顺序!
一.前言 一直是想知道一条SQL语句是怎么被执行的,它执行的顺序是怎样的,然后查看总结各方资料,就有了下面这一篇博文了. 本文将从MySQL总体架构--->查询执行流程--->语句执行顺序 ...
- Mysql修改语句的运行流程
执行修改语句前要先连接数据库,这是连接器的工作. 接下来,分析器会通过词法和语法解析知道这是一条更新语句.优化器决定要使用 ID 这个索引.然后,执行器负责具体执行,找到这一行,然后更新. Mysql ...
- 让MySQL为我们记录执行流程
让MySQL为我们记录执行流程 我们可以开启profiling,让MySQL为我们记录SQL语句的执行流程 查看profiling参数 shell > select @@profilin ...
- 1020关于mysql一个简单语句的执行流程
MySQL的语句执行顺序 转自http://www.cnblogs.com/rollenholt/p/3776923.html MySQL的语句一共分为11步,如下图所标注的那样,最先执行的总是FRO ...
- Mysql查询语句的运行流程
我们先看一下MYsql的基本架构示意图: 大体来说,MySQL 可以分为 Server 层和存储引擎层两部分. Server 层包括连接器.查询缓存.分析器.优化器.执行器等,涵盖 MySQL 的大多 ...
- mysql查询语句的执行顺序(重点)
一 SELECT语句关键字的定义顺序 SELECT DISTINCT <select_list> FROM <left_table> <join_type> JOI ...
随机推荐
- python pip/anaconda使用笔记
Switch to Chinese conda Source, config file is in ~/.condarc conda config --add channels https://mir ...
- linux多次登录失败锁定账户
2021-07-22 1.配置对系统进行失败的ssh登录尝试后锁定用户帐户 # 配置登录访问的限制 vi /etc/pam.d/system-auth 或者 vi etc/pam.d/password ...
- 通过JDK动态代理实现 Spring AOP
1.新建一个目标类 接口:public interface IUserService //切面编程 public void addUser(); public void updateUser( ); ...
- API:获取当前用户的公网IP
在vue项目根目录下" public " 文件夹中的index.html,也就是根节点所在的文件引入JS,vue项目中静态文件需要在这里引入,用 script 标签规避跨域 < ...
- Nginx:常用基本命令与异常处理
Nginx日志 - ./nginx-1.6.0-ems/logs/nginx.pid Nginx启动时应该使用cmd等命令行工具启动,双击启动同样会产生进程但会造成异常,判断条件是 ./nginx-1 ...
- 如何高效掌控K8s资源变化?K8s Informer实现机制浅析
作者 王成,腾讯云研发工程师,Kubernetes contributor,从事数据库产品容器化.资源管控等工作,关注 Kubernetes.Go.云原生领域. 概述 进入 K8s 的世界,会发现有很 ...
- golang中的左值VS右值
对应关系 左值 可寻址 右值 不可寻址 可寻址:可以通过&取地址符,获取内存地址; 可寻址,也就是分配了内存; 不可寻址:根本没有分配内存; 常量const 常量通常只支持数字/字符串/布尔, ...
- HCNP Routing&Switching之IS-IS路由聚合和认证
前文我们了解了IS-IS路由渗透和开销相关话题,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/15302382.html:今天我们来聊一聊IS-IS路由聚合和认 ...
- HDFS基本命令
1.创建目录 hadoop dfs -mkdir /data hadoop dfs -mkdir -p /data/data1 创建多级目录 2.查看文件 hadoop dfs -ls / 3.上 ...
- 测试开发【提测平台】分享10-Element UI抽屉和表单校验&增改接口合并实现应用管理
微信搜索[大奇测试开],关注这个坚持分享测试开发干货的家伙. 开篇说个小讨论,一个群里聊天聊到关于更新篇章的长度,是小篇幅多次,还是每次按照一个小完整的功能,我个人的是按照后种来的,主要的思考就是希望 ...