源码解析C#中PriorityQueue(优先级队列)的实现
前言
前段时间看到有大佬对.net 6.0新出的PriorityQueue(优先级队列)数据结构做了解析,但是没有源码分析,所以本着探究源码的心态,看了看并分享出来。它不像普通队列先进先出(FIFO),而是根据优先级出队。
ps:读者多注意代码的注释。
D叉树的认识(d-ary heap)
首先我们在表示一个堆(大顶堆或小顶堆)的时候,实际上是通过一个一维数组来维护一个二叉树(d=2,d表示每个父节点最多有几个子节点),首先看下图的二叉树,数字代表索引:
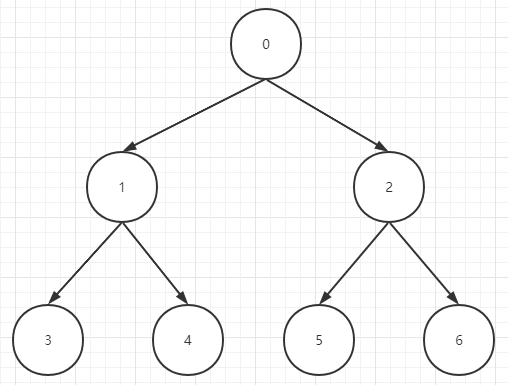
- 任意一个节点的父节点的索引为:(index - 1) / d
- 任意一个节点的左子节点的索引为:(index * d) + 1
- 任意一个节点的右子节点的索引为:(index * d) + 2
- 它的时间复杂度为O(logndn)
通过以上公式,我们就可以轻松通过一个数组来表达一个堆,只需保证能拿到正确的索引即可进行快速的插入和删除。
源码解析
构造初始化
关于这部分主要介绍关键的字段和方法,比较器的初始化以及堆的初始化,请看如下代码:
public class PriorityQueue<TElement, TPriority>
{
/// <summary>
/// 保存所有节点的一维数组且每一项是个元组
/// </summary>
private (TElement Element, TPriority Priority)[] _nodes;
/// <summary>
/// 优先级比较器,这里用的泛型,比较器可以自己实现
/// </summary>
private readonly IComparer<TPriority>? _comparer;
/// <summary>
/// 当前堆的大小
/// </summary>
private int _size;
/// <summary>
/// 版本号
/// </summary>
private int _version;
/// <summary>
/// 代表父节点最多有4个子节点,也就是d=4(d=4时好像效率最高)
/// </summary>
private const int Arity = 4;
/// <summary>
/// 使用位运算符,表示左移2或右移2(效率更高),即相当于除以4,
/// </summary>
private const int Log2Arity = 2;
/// <summary>
/// 构造函数初始化堆和比较器
/// </summary>
public PriorityQueue()
{
_nodes = Array.Empty<(TElement, TPriority)>();
_comparer = InitializeComparer(null);
}
/// <summary>
/// 重载构造函数,来定义比较器否则使用默认的比较器
/// </param>
public PriorityQueue(IComparer<TPriority>? comparer)
{
_nodes = Array.Empty<(TElement, TPriority)>();
_comparer = InitializeComparer(comparer);
}
private static IComparer<TPriority>? InitializeComparer(IComparer<TPriority>? comparer)
{
//如果是值类型,如果是默认比较器则返回null
if (typeof(TPriority).IsValueType)
{
if (comparer == Comparer<TPriority>.Default)
{
return null;
}
return comparer;
}
//否则就使用自定义的比较器
else
{
return comparer ?? Comparer<TPriority>.Default;
}
}
/// <summary>
/// 获取索引的父节点
/// </summary>
private int GetParentIndex(int index) => (index - 1) >> Log2Arity;
/// <summary>
/// 获取索引的左子节点
/// </summary>
private int GetFirstChildIndex(int index) => (index << Log2Arity) + 1;
}
单元总结:
- 实际所有元素使用一维数组来维护这个堆。
- 调用方可以自定义比较器,但是类型得一致。 如果没有比较器,则使用默认的比较器。
- 默认一个父节点最多有4个子节点,D=4时效率好像是最好的。
- 获取父节点索引位置和子节点索引位置使用位运算符,效率更高。
入队操作
入队操作操作相对简单,主要是做扩容和插入处理,请看如下代码:
public void Enqueue(TElement element, TPriority priority)
{
//拿到最大位置的索引,然后再将数组长度+1
int currentSize = _size++;
_version++;
//如果长度相等,说明已经到达最大位置,数组需要扩容了才能容下更多的元素
if (_nodes.Length == currentSize)
{
//扩容,参数是代表数组最小容量
Grow(currentSize + 1);
}
if (_comparer == null)
{
MoveUpDefaultComparer((element, priority), currentSize);
}
else
{
MoveUpCustomComparer((element, priority), currentSize);
}
}
private void Grow(int minCapacity)
{
//增长倍数
const int GrowFactor = 2;
//每次扩容的最小值
const int MinimumGrow = 4;
//每次扩容都2倍扩容
int newcapacity = GrowFactor * _nodes.Length;
//数组不能大于最大长度
if ((uint)newcapacity > Array.MaxLength) newcapacity = Array.MaxLength;
//使用他们两个的最大值
newcapacity = Math.Max(newcapacity, _nodes.Length + MinimumGrow);
//如果比参数小,则使用参数的最小值
if (newcapacity < minCapacity) newcapacity = minCapacity;
//重新分配内存,设置大小,因为数组的保存在内存中是连续的
Array.Resize(ref _nodes, newcapacity);
}
private void MoveUpDefaultComparer((TElement Element, TPriority Priority) node, int nodeIndex)
{
//nodes保存副本
(TElement Element, TPriority Priority)[] nodes = _nodes;
//这里入队操作是从空闲索引第一个位置开始插入
while (nodeIndex > 0)
{
//找父节点索引位置
int parentIndex = GetParentIndex(nodeIndex);
(TElement Element, TPriority Priority) parent = nodes[parentIndex];
//插入节点和父节点比较,如果小于0(默认比较器情况下构建的小顶堆),则交换位置
if (Comparer<TPriority>.Default.Compare(node.Priority, parent.Priority) < 0)
{
nodes[nodeIndex] = parent;
nodeIndex = parentIndex;
}
//算是性能优化吧,不必检查所有节点,当发现大于时,就直接退出就可以了
else
{
break;
}
}
//将插入节点放到它应该的位置
nodes[nodeIndex] = node;
}
单元总结:
- 首先记录当前元素最大的索引位置,根据适当的情况来扩容。
- 扩容正常情况下是以2倍的增长速度扩容。
- 插入数据时,从最后一个节点的父节点向上还是找,比较元素的Priority,交换位置,默认情况下是构建小顶堆。
出队操作
出队操作简单来说就是将根元素返回并移除(也就是数组的第一个元素),然后根据比较器将最小或最大的元素放到堆顶,请看如下代码:
public TElement Dequeue()
{
if (_size == 0)
{
throw new InvalidOperationException(SR.InvalidOperation_EmptyQueue);
}
//将堆顶元素返回
TElement element = _nodes[0].Element;
//然后调整堆
RemoveRootNode();
return element;
}
private void RemoveRootNode()
{
//记录最后一个元素的索引位置,并且将堆的大小-1
int lastNodeIndex = --_size;
_version++;
if (lastNodeIndex > 0)
{
//堆的大小已经被减1,所以将最后一个元素作为副本,开始从堆顶重新整理堆
(TElement Element, TPriority Priority) lastNode = _nodes[lastNodeIndex];
if (_comparer == null)
{
MoveDownDefaultComparer(lastNode, 0);
}
else
{
MoveDownCustomComparer(lastNode, 0);
}
}
if (RuntimeHelpers.IsReferenceOrContainsReferences<(TElement, TPriority)>())
{
//将最后一个位置的元素设置为默认值
_nodes[lastNodeIndex] = default;
}
}
private void MoveDownDefaultComparer((TElement Element, TPriority Priority) node, int nodeIndex)
{
(TElement Element, TPriority Priority)[] nodes = _nodes;
//堆的实际大小
int size = _size;
int i;
//当左子节点的索引小于堆的实际大小时
while ((i = GetFirstChildIndex(nodeIndex)) < size)
{
//左子节点元素
(TElement Element, TPriority Priority) minChild = nodes[i];
//当前左子节点的索引
int minChildIndex = i;
//这里即找到所有同一个父节点的相邻子节点,但是要判断是否超出了总的大小
int childIndexUpperBound = Math.Min(i + Arity, size);
//按照索引区间顺序查找,并根据比较器找到最小的子元素位置
while (++i < childIndexUpperBound)
{
(TElement Element, TPriority Priority) nextChild = nodes[i];
if (Comparer<TPriority>.Default.Compare(nextChild.Priority, minChild.Priority) < 0)
{
minChild = nextChild;
minChildIndex = i;
}
}
//如果最后一个节点的元素,比这个最小的元素还小,那么直接放到父节点即可
if (Comparer<TPriority>.Default.Compare(node.Priority, minChild.Priority) <= 0)
{
break;
}
//将最小的子元素赋值给父节点
nodes[nodeIndex] = minChild;
nodeIndex = minChildIndex;
}
//将最后一个节点放到空闲出来的索引位置
nodes[nodeIndex] = node;
}
单元总结:
- 返回根节点元素,然后移除根节点元素,调整堆。
- 从根节点开始,依次查找对应父节点的所有子节点,放到堆顶,也就是数组索引0的位置,然后如果树还有层数,继续循环查找。
- 将最后一个元素放到堆适当的位置,然后再将最后一个位置的元素置为默认值。
总结
通过源码的解读,除了了解类的设计之外,更对对优先级队列数据结构的实现有了更加深刻和清晰的认识。
这里也只是粘贴出主要的代码,需要看详细代码的请点击这里,笔者可能有一些解读错误的地方,欢迎评论指正。
源码解析C#中PriorityQueue(优先级队列)的实现的更多相关文章
- 源码解析.Net中IConfiguration配置的实现
前言 关于IConfituration的使用,我觉得大部分人都已经比较熟悉了,如果不熟悉的可以看这里.因为本篇不准备讲IConfiguration都是怎么使用的,但是在源码部分的解读,网上资源相对少一 ...
- 源码解析.Net中Host主机的构建过程
前言 本篇文章着重讲一下在.Net中Host主机的构建过程,依旧延续之前文章的思路,着重讲解其源码,如果有不知道有哪些用法的同学可以点击这里,废话不多说,咱们直接进入正题 Host构建过程 下图是我自 ...
- Spark 源码解析 : DAGScheduler中的DAG划分与提交
一.Spark 运行架构 Spark 运行架构如下图: 各个RDD之间存在着依赖关系,这些依赖关系形成有向无环图DAG,DAGScheduler对这些依赖关系形成的DAG,进行Stage划分,划分的规 ...
- 源码解析.Net中DependencyInjection的实现
前言 笔者的这篇文章和上篇文章思路一样,不注重依赖注入的使用方法,更加注重源码的实现,我尽量的表达清楚内容,让读者能够真正的学到东西.如果有不太清楚依赖注入是什么或怎么在.Net项目中使用的话,请点击 ...
- 源码解析.Net中Middleware的实现
前言 本篇继续之前的思路,不注重用法,如果还不知道有哪些用法的小伙伴,可以点击这里,微软文档说的很详细,在阅读本篇文章前,还是希望你对中间件有大致的了解,这样你读起来可能更加能够意会到意思.废话不多说 ...
- multiprocessing 源码解析 更新中......
一.参考链接 1.源码包下载·链接: https://pypi.org/search/?q=multiprocessing+ 2.源码包 链接:https://pan.baidu.com/s/1j ...
- java中PriorityQueue优先级队列使用方法
优先级队列是不同于先进先出队列的另一种队列.每次从队列中取出的是具有最高优先权的元素. PriorityQueue是从JDK1.5开始提供的新的数据结构接口. 如果不提供Comparator的话,优先 ...
- 源码解析Android中View的measure量算过程
Android中的Veiw从内存中到呈现在UI界面上需要依次经历三个阶段:量算 -> 布局 -> 绘图,关于View的量算.布局.绘图的总体机制可参见博文< Android中View ...
- 《转》JAVA中PriorityQueue优先级队列使用方法
该文章转自:http://blog.csdn.net/hiphopmattshi/article/details/7334487 优先级队列是不同于先进先出队列的另一种队列.每次从队列中取出的是具有最 ...
随机推荐
- 零基础学习java------day18------properties集合,多线程(线程和进程,多线程的实现,线程中的方法,线程的声明周期,线程安全问题,wait/notify.notifyAll,死锁,线程池),
1.Properties集合 1.1 概述: Properties类表示了一个持久的属性集.Properties可保存在流中或从流中加载.属性列表中每个键及其对应值都是一个字符串 一个属性列表可包含另 ...
- 内存管理——new delete expression
C++申请释放内存的方法与详情表 调用情况 1.new expression new表达式在申请内存过程中都发生了什么? 编译器将new这个分解为下面的主要3步代码,①首先调用operator new ...
- Lock锁的使用
在Java多线程中,可以使用synchronized关键字实现线程之间的同步互斥,在jdk1.5后新增的ReentrantLock类同样可达到此效果,且在使用上比synchronized更加灵活. 观 ...
- winxp 关闭445端口
关闭445端口的方法方法很多,但是我比较推荐以下这种方法: 修改注册表,添加一个键值 Hive: HKEY_LOCAL_MACHINE Key: System\Controlset\Services\ ...
- Linux单机安装Zookeeper
一.官网 https://zookeeper.apache.org/ 二.简介 Apache ZooKeeper致力于开发和维护开源服务器,实现高度可靠的分布式协调. ZooKeeper是一种集中式服 ...
- 【Linux】【Services】【KVM】安装与简单配置
1. 环境: 1.1. OS: Red Hat Enterprise Linux Server release 7.4 (Maipo) 1.2. Kernel: 3.10.0-693.el7.x86_ ...
- 【Linux】【Services】【Package】编译安装
程序包编译安装: testapp-VERSION-release.src.rpm --> 安装后,使用rpmbuild命令制作成二进制格式的rpm包,而后再安装: ...
- linux系统下命令的学习
本博客是本人工作时做的笔记 ps aux |grep ^profile |grep A190200024 ^ 表示行首匹配 linux查看文件大小: 具体可查看:https://www.cnblogs ...
- 【Spark】【RDD】从内存(集合)创建RDD
val list = List(1,2,3) var rdd = sc.parallelize(list) rdd.partitions.size 通过调用SparkContext的paralleli ...
- Taro 微信小程序 上传文件到minio
小程序前端上传文件不建议直接引用minio的js npm包,一来是这个包本身较大,会影响小程序的体积,二来是ak sk需要放到前端存储,不够安全,因此建议通过请求后端拿到签名数据后上传. 由于小程序的 ...