「性能提升」扩展 Spring Cache 支持多级缓存
为什么多级缓存
缓存的引入是现在大部分系统所必须考虑的
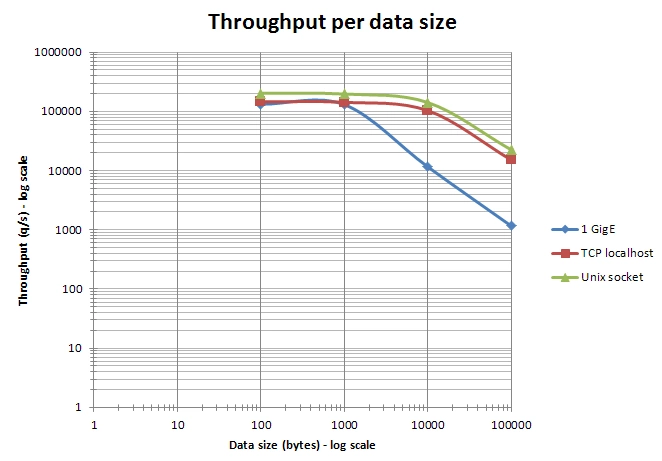
- redis 作为常用中间件,虽然我们一般业务系统(毕竟业务量有限)不会遇到如下图 在随着 data-size 的增大和数据结构的复杂的造成性能下降,但网络 IO 消耗会成为整个调用链路中不可忽视的部分。尤其在 微服务架构中,一次调用往往会涉及多次调用 例如pig oauth2.0 的 client 认证
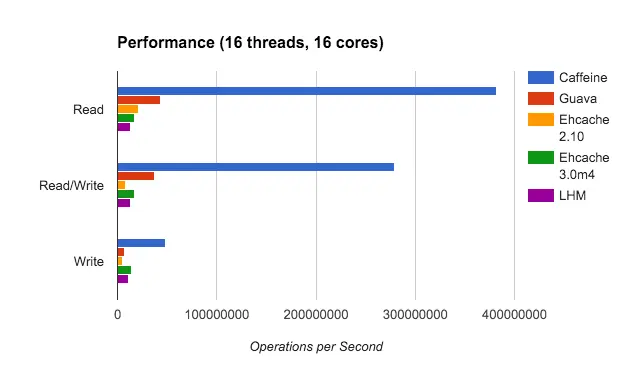
- Caffeine 来自未来的本地内存缓存,性能比如常见的内存缓存实现性能高出不少详细对比。
综合所述:我们需要构建 L1 Caffeine JVM 级别缓存 , L2 Redis 缓存。
设计难点
目前大部分应用缓存都是基于 Spring Cache 实现,基于注解(annotation)的缓存(cache)技术,存在的问题如下:
- Spring Cache 仅支持 单一的缓存来源,即:只能选择 Redis 实现或者 Caffeine 实现,并不能同时使用。
- 数据一致性:各层缓存之间的数据一致性问题,如应用层缓存和分布式缓存之前的数据一致性问题。
- 缓存过期:Spring Cache 不支持主动的过期策略
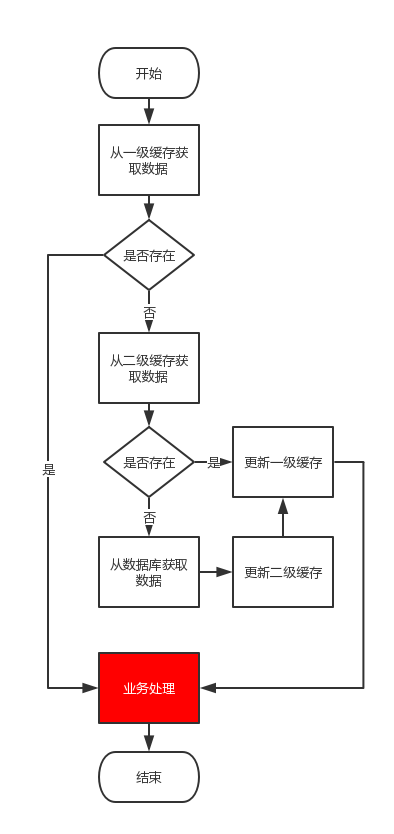
业务流程
如何使用
- 引入依赖
<dependency>
<groupId>com.pig4cloud.plugin</groupId>
<artifactId>multilevel-cache-spring-boot-starter</artifactId>
<version>0.0.1</version>
</dependency>
- 开启缓存支持
@EnableCaching
public class App {
public static void main(String[] args) {
SpringApplication.run(App.class, args);
}
}
- 目标接口声明 Spring Cache 注解
@Cacheable(value = "get",key = "#key")
@GetMapping("/get")
public String get(String key){
return "success";
}
性能比较
为保证性能 redis 在 127.0.0.1 环路安装
- OS: macOS Mojave
- CPU: 2.3 GHz Intel Core i5
- RAM: 8 GB 2133 MHz LPDDR3
- JVM: corretto_11.jdk
| Benchmark | Mode | Cnt | Score | Units |
|---|---|---|---|---|
| 多级实现 | thrpt | 2 | 2716.074 | ops/s |
| 默认 redis | thrpt | 2 | 1373.476 | ops/s |
代码原理
- 自定义 CacheManager 多级缓存实现
public class RedisCaffeineCacheManager implements CacheManager {
@Override
public Cache getCache(String name) {
Cache cache = cacheMap.get(name);
if (cache != null) {
return cache;
}
cache = new RedisCaffeineCache(name, stringKeyRedisTemplate, caffeineCache(), cacheConfigProperties);
Cache oldCache = cacheMap.putIfAbsent(name, cache);
log.debug("create cache instance, the cache name is : {}", name);
return oldCache == null ? cache : oldCache;
}
}
- 多级读取、过期策略实现
public class RedisCaffeineCache extends AbstractValueAdaptingCache {
protected Object lookup(Object key) {
Object cacheKey = getKey(key);
// 1. 先调用 caffeine 查询是否存在指定的值
Object value = caffeineCache.getIfPresent(key);
if (value != null) {
log.debug("get cache from caffeine, the key is : {}", cacheKey);
return value;
}
// 2. 调用 redis 查询在指定的值
value = stringKeyRedisTemplate.opsForValue().get(cacheKey);
if (value != null) {
log.debug("get cache from redis and put in caffeine, the key is : {}", cacheKey);
caffeineCache.put(key, value);
}
return value;
}
}
- 过期策略,所有更新操作都基于 redis pub/sub 消息机制更新
public class RedisCaffeineCache extends AbstractValueAdaptingCache {
@Override
public void put(Object key, Object value) {
push(new CacheMessage(this.name, key));
}
@Override
public ValueWrapper putIfAbsent(Object key, Object value) {
push(new CacheMessage(this.name, key));
}
@Override
public void evict(Object key) {
push(new CacheMessage(this.name, key));
}
@Override
public void clear() {
push(new CacheMessage(this.name, null));
}
private void push(CacheMessage message) {
stringKeyRedisTemplate.convertAndSend(topic, message);
}
}
- MessageListener 删除指定 Caffeine 的指定值
public class CacheMessageListener implements MessageListener {
private final RedisTemplate<Object, Object> redisTemplate;
private final RedisCaffeineCacheManager redisCaffeineCacheManager;
@Override
public void onMessage(Message message, byte[] pattern) {
CacheMessage cacheMessage = (CacheMessage) redisTemplate.getValueSerializer().deserialize(message.getBody());
cacheMessage.getCacheName(), cacheMessage.getKey());
redisCaffeineCacheManager.clearLocal(cacheMessage.getCacheName(), cacheMessage.getKey());
}
}
源码地址
https://github.com/pig-mesh/multilevel-cache-spring-boot-starter
「性能提升」扩展 Spring Cache 支持多级缓存的更多相关文章
- 【开源项目系列】如何基于 Spring Cache 实现多级缓存(同时整合本地缓存 Ehcache 和分布式缓存 Redis)
一.缓存 当系统的并发量上来了,如果我们频繁地去访问数据库,那么会使数据库的压力不断增大,在高峰时甚至可以出现数据库崩溃的现象.所以一般我们会使用缓存来解决这个数据库并发访问问题,用户访问进来,会先从 ...
- 基于Spring Cache实现二级缓存(Caffeine+Redis)
一.聊聊什么是硬编码使用缓存? 在学习Spring Cache之前,笔者经常会硬编码的方式使用缓存. 我们来举个实际中的例子,为了提升用户信息的查询效率,我们对用户信息使用了缓存,示例代码如下: @A ...
- 【Spring】17、spring cache 与redis缓存整合
spring cache,基本能够满足一般应用对缓存的需求,但现实总是很复杂,当你的用户量上去或者性能跟不上,总需要进行扩展,这个时候你或许对其提供的内存缓存不满意了,因为其不支持高可用性,也不具备持 ...
- 品味Spring Cache设计之美
最近负责教育类产品的架构工作,两位研发同学建议:"团队封装的Redis客户端可否适配Spring Cache,这样加缓存就会方便多了" . 于是边查阅文档边实战,收获颇丰,写这篇文 ...
- Spring 3.1新特性之三:Spring对声明式缓存的支持
一.概述: Spring 3.1 引入了激动人心的基于注释(annotation)的缓存(cache)技术,它本质上不是一个具体的缓存实现方案(例如EHCache 或者 OSCache),而是一个对缓 ...
- Spring Boot中的缓存支持(一)注解配置与EhCache使用
Spring Boot中的缓存支持(一)注解配置与EhCache使用 随着时间的积累,应用的使用用户不断增加,数据规模也越来越大,往往数据库查询操作会成为影响用户使用体验的瓶颈,此时使用缓存往往是解决 ...
- Spring Cache 带你飞(二)
接着上一篇讲了 Spring Cache 如何被 Spring Aop 代理加载对应的代码,以及何如注入相关界面逻辑. Spring Cache 带你飞(一) 本篇我们围绕两个要点展开: 一个数据是如 ...
- Spring Cache抽象详解
缓存简介 缓存,我的理解是:让数据更接近于使用者:工作机制是:先从缓存中读取数据,如果没有再从慢速设备上读取实际数据(数据也会存入缓存):缓存什么:那些经常读取且不经常修改的数据/那些昂贵(CPU/I ...
- 基于Redis的Spring cache 缓存介绍
目录 Cache API及默认提供的实现 demo 依赖包安装 定义实体类.服务类和相关配置文件 Cache注解 启用Cache注解 @CachePut @CacheEvict @Cacheable ...
随机推荐
- APC体育公司重视“女性经济 ”深度挖掘女性市场
据消费者追踪服务调查数据显示,从2020年1月到8月,a private company体育公司(公司编号:08703733)品牌下的女性运动服装的在线销售额较上一年增长了77%. 女性市场已然成为A ...
- sublime 使用过程中遇到的问题
1.当我把鼠标放置在下图所示的class上几秒钟后,sublime就会在全局查找当前的class字符,这时sublime就会出现卡顿或无响应 解决方法: 点击preferences下的settings ...
- 27_MySQL数字函数(重点)
/* SALES部门中工龄超过20年的,底薪增加10% SALES部门中工龄不满20年的,底薪增加5% ACCOUNTING部门,底薪增加300元 RESEARCH部门里低于部门平均底薪的,底薪增加2 ...
- Mybatis-06 动态Sql
Mybatis-06 动态Sql 多对一处理 多个学生,对应一个老师 对于学生这边而言,关联多个学生,关联一个老师 [多对一] 对于老师而言,集合,一个老师又很多学生 [一对多] 1.创建数据库 2. ...
- 渗透测试--Nmap主机识别
通过本篇博客可以学到:Nmap的安装和使用,列举远程机器服务端口,识别目标机器上的服务,指纹,发现局域网中存活主机,端口探测技巧,NSE脚本使用,使用特定网卡进行检测,对比扫描结果ndiff,可视化N ...
- ss_port_change - 一键修改ss配置与Centos7的Firewall策略脚本
ss_port_change 修改ss配置与Centos7的Firewall策略脚本 注意是否需要修改config路径与ss服务的名 脚本的敏感字用了*代替 项目地址 Github 脚本 #!/bin ...
- POJ-3281(最大流+EK算法)
Dining POJ-3281 这道题目其实也是网络流中求解最大流的一道模板题. 只要建模出来以后直接套用模板就行了.这里的建模还需要考虑题目的要求:一种食物只能给一只牛. 所以这里可以将牛拆成两个点 ...
- mysql内一些可以延时注入的查询语句
一.sleep() 配合其他函数进行使用将十分方便,如下所示: 拆分讲解: select substr(database(),1,1) ; 截取当前数据库的第一位,转换为ascii码值: se ...
- Hi3359AV100 NNIE开发(1)-RFCN demo LoadModel函数与参数解析
之后随笔将更多笔墨着重于NNIE开发系列,下文是关于Hi3359AV100 NNIE开发(1)-RFCN demo LoadModel函数与参数解析,通过对LoadModel函数的解析,能够很好理解. ...
- Go语言|类型转换和类型别名
类型转换 同类型之间的转换 Go语言中只有强制类型转换,没有隐式类型转换.该语法只能在两个类型之间支持相互转换的时候使用. import "fmt" func main() { v ...