python学习之面向对象
目录
- __main__,__name__
- __module__,__class__
- __init__
- __del__
- __repr__,__str__
- __mro__
- __call__
- __new__
- __doc__
- __hasattr__,__getattr__,__setattr__
- __import__
- __dir__ ,__all__
- __enter__,__exit__
- 其他函数
Object Oriented Programming,简称oop,面向对象是种程序设计思想,我们之前学的是面向过程,虽然我们可以不用面向对象也可以完成某些小功能,复杂功能通过面向对象可以简单的解决,简化代码量,达到事半功倍的效果,把你写好的模块封装到一个类中
类
形象来说是一个模板或者模型,如果我们想要造车,需要通过设计图,汽车模型
对象,实例
根据模板造出来的车
实例化(根据模型制造汽车的过程)
初始化一个类,造了一个对象。把一个类变成一个具体的对象的过程,叫做实例化
- #经典类
- class Shop_car:#class:定义类后面接名称名称 汽车店,汽车的类,在创建类时通用首字母大写
- color = 'red'#汽车的属性,类里面的变量
- size = ''
- sign = 'BWM'
- money = 300000
- def fuc(self):#功能,方法:类中的函数
- print('滴滴滴上路')
- #新式类
- class shop(object):#与经典类一样,只有在python2中有区别,但推荐这种写法
#class shop: 或者 class shop(): 或者 class shop(object): 在python3.x中这三者都一样哈~- pass
- xiaoming = shop_car()#小明去汽车店买车,实例化
- print(xiaoming.color)#打印红色
- xiaoming.fuc()#类.一个方法就是调用这个方法,打印滴滴滴上路
扩展-type()
- #所有的类本身也是对象,它们是由type创建的
type有两种用法 其一可以获取当前对象是由哪一个类创建的
class A:pass
obj = A()
print(type(obj))- #1
- class Foo1(object):
- pass
- obj1 = Foo1()
- #
- obj2 = type('Foo2',(object,),{})
- #上述两者一样,要记住类是由type()也可以创建类
- #一切皆对象,我们可以创建一个new_type其继承type,对其扩展
- class new_type(type):
- pass
- obj3 = new_type('Foo3',(object,),{})
- class Mytype(type):#重写type方法 => metaclass
- def __init__(self,*args,**kwargs):
- print('jjj')
- pass
- #metaclass可以在指定声明要使用的type,从而重写的type方法
class Raom(object,metaclass=Mytype): def sda(self): print("sdsa") #我们知道类由type创建,而Mytype继承type,指定上面的Mytype,给Raom类指定类由Mytype创建
pass
- # class NewType(Mytype('Basetype',(object(,),{})) 这样写也意味着 继承关系 NewType > Mytype >Basetype > object
# pass
执行顺序
python解释器读代码执行顺序如下
- class Mytype(type):
- def __init__(self,*args,**kwargs):
- print('')
- super(Mytype,self).__init__(*args,**kwargs)
- def __call__(self, *args, **kwargs):
- print('')
- obj = self.__new__(self,*args, **kwargs)
- self.__init__(obj)
- class Test(object,metaclass=Mytype):
- def __init__(self):
- print('')
- pass
- def __new__(cls, *args, **kwargs):
- print('')
- return super().__new__(cls,*args, **kwargs)
- obj = Test()
#打印
#0
#1
#3
#2
内建函数↓↓↓
什么是内建函数,也称内置函数,就是python自己语言本身的特有的函数,其他语言没有
程序入口 __main__和__name__
a文件
def xxx():
print('aa')
if __name__ == '__main__':
xxx() #当我们调用xxx方法时,在当前文件下可以直接调用xxx方法,也就是方便自测使用
---------------------------------------------------------------------------------------------------------------------------
b文件
import a #导入a文件
a.xxx() #在其他文件执行时,在if __name == '__main__'中的方法和属性不会被b文件执行
#__name__在自己文件执行打印出的结果就是__main__,而在其他文件中调用,其打印结果为文件的文件名,所以如果name和main相等会执行其下的代码
- __module__实例1.py
- class test1(object):
- def __init__(self):
- print('test1')
__module__实例2.py
- from __module__实例1 import test1
- print(test1.__module__)#__module__实例1
- obj1 = test1()
- print(obj1.__module__)#__module__实例1
- print(obj1.__class__)#<class '__module__实例1.test1'>
- class test2(object):
- def __init__(self):
- print('test2')
- print(test2.__module__)#__main__
- obj2 = test2()
- print(obj2.__module__)#__main__
- print(obj2.__class__)#<class '__main__.test2'>
- #__module__ 当前操作的对象在哪个模块
- #__class__ 输出类
构造函数 __init__
构造方法也称为面向对象三大特性之一,类在实例化的时候做的某些初始化操作,代码会根据优先级先查看是否有构造函数,如果有的话先运行构造函数里面的方法和代码,并查看是否有参数等
- class Shop_car:#根据序号一步一步解析
color = 'red'
size = '1000'
sign = 'BWM'
money = 300000- def fuc(self):#4.谁调用self就是谁的内存地址,通过内存地址找到fuc方法,当要调用时可直接调用
print("%s滴滴滴上路"%self.name)
def __init__(self,name):#构造函数,其在实例化的时候自动执行,self默认值参数,它在类中不可去除,self相当与一个公共传参的对象 2.name传递的形参是'小明'- print(self.color)#通过self可以调用类中的属性和方法
- self.name = name#3.把'小明'传给self.name使其获取了内存地址
- print('这车被%s买走了'%name)
- xiaoming = Shop_car('小明')#xiaoming这个变量表示实例也叫对象,一切的一切都为对象,也可以理解self也就是xiaoming, 1.实例化,因为函数中有构造函数所以一定要传参,把实参小明传给构造函数中的name
- xiaoming.fuc()#5.xiaoming调用类中fuc方法,打印'滴滴滴上路'
self其实就是能够区分是谁来调用的一个参数,我们在写代码时,重复的函数都可以变成一个,调用时直接去公共的函数中调用,可以节省内存空间
析构函数 __del__
在实例被销毁的时候执行的函数,这其实和python的垃圾回收机制有关,根据算法:不用的类,方法,变量一旦他们之间的连接中断,其实就调用__del__函数将他们回收掉
- class A:
- def aaa(self):
- print("aqaaa")
- def __del__(self):#这类中引用析构函数,在程序运行完了以后,自动运行析构函数中的方法
- print("运行析构函数")def bbb(self):
- print("bbb")
- def __init__(self,name):
- self.name = name
- a = A('ssss')
- a.aaa()
- a.bbb()
- class B:
- def ccc(self):
- print("ccc")
- b = B()
- b.ccc()
- print("dddd")
-----------------------
运行结果
aqaaa
bbb
ccc
dddd
运行析构函
析构函数通常用于关闭数据库连接
repr函数,str函数 __repr__ __str__
- # def __str__()
- # 调用重写方法,可以重写对象的值
- class Dog:
- """定义一个狗类"""
- def __init__(self, new_name, new_age):
- """在创建完对象之后 会自动调用, 它完成对象的初始化的功能"""
- # self.name = "来福"
- # self.age = 20
- self.name = new_name
- self.age = new_age # 它是一个对象中的属性,在对象中存储,即只要这个对象还存在,那么这个变量就可以使用
- # num = 100 # 它是一个局部变量,当这个函数执行完之后,这个变量的空间就没有了,因此其他方法不能使用这个变量
- def __str__(self): # def __repr__(self):
- """返回一个对象的描述信息"""
- # print(num)
- return "名字是:%s , 年龄是:%d" % (self.name, self.age)
- def eat(self):
- print("%s在吃骨头...." % self.name)
- def drink(self):
- print("%s在喝雪碧..." % self.name)
- def introduce(self):
- # print("名字是:%s, 年龄是:%d" % (来福的名字, 来福的年龄))
- # print("名字是:%s, 年龄是:%d" % (tom.name, tom.age))
- print("名字是:%s, 年龄是:%d" % (self.name, self.age))
- tom = Cat("来福", 20)
- # 打印 名字是:来福 , 年龄是:20
- # __str__定义方法表示当实例化一个对象后可以输出这个类来重写一个对象的返回值,__str__方法是面向用户
- # 如果终端输入tom或者不加__str__打印的是属性和内存地址 <__main__.Dog object at 0x00000000035CD2E8>
- # __repr__定义方式和__str__差不多,唯一区别可以在终端中打印来福 , 年龄是:20,__repr方法是面向程序员
- # >>>tom = Cat("来福", 20)
- # >>>tom 输出来福 , 年龄是:20
当我们想所有环境下都统一显示的话,可以重构__repr__方法;当我们想在不同环境下支持不同的显示,例如终端用户显示使用__str__,而程序员在开发期间则使用底层的__repr__来显示,实际上__str__只是覆盖了__repr__以得到更友好的用户显示。
mro函数 __mro__
- # 类.mro()
- # mro方法可以查看类的其父类的层级关系
- class a:
- pass
- class b:
- pass
- class c(a, b):
- pass
- print(c.mro())
- # ----打印 [<class '__main__.c'>, <class '__main__.a'>, <class '__main__.b'>, <class 'object'>]
- # __mro__函数↓
- class x:
- def commint(self):
- print("jjjj")
- class y:
- def commint(self):
- print("Zszss")
- class z(x, y):
- pass
- zoo = z()
- zoo.commint() # 如果要调用先调用谁呢?
- print(z.__mro__)
- # __mro__方法是隐藏的特殊属性,返回基于当前类后面的所有继承关系,内置有大量算法,我们不需要理解那么多,只要知道这个类有两个父类,且要调用的那个方法两个父类都有,越靠前的优先级越高,使用mro按照z(x,y),排序方式是按z类先调用的是顺序x类,所以返回x在y的前面
call函数 我们可以理解成它就是所有调用的老祖宗(只要有括号就被理解为执行了call函数)
- class a:
- def bfg(self):
- print("asdsa")
- def __call__(self):
- print("nihao")
- c = a()
- c.bfg()
- c()#打印nihao 对象直接调用就是直接调的__call__方法,所以的对象是通过底层的call方法调用的,或者对象加两括号,如:
- class Call:
- def __init__(self,name):
- self.name=name
- def __call__(self):
- print("__call__执行打印",self.name)
- Call('rainbol_n1')()
- c = Call('rainbol_n2')#对象加两括号执行
- c()#对象加括号执行
- #或者c = Call('rainbol_n2')()
- #----------打印
- #__call__执行打印 rainbol_n1
- #__call__执行打印 rainbol_n2
- #综上结论:call内建函数在直接调用类或者运行对象会被运行,说白了call方法会调用__new__再调用__init__
new函数 __new__
- class A(object):
- def __init__(self, *args, **kwargs):
- print("init A")
- def __new__(cls, *args, **kwargs):
- print("new A %s" % cls)
- # return super(A, cls).__new__(cls, *args, **kwargs)
- return object.__new__(cls, *args, **kwargs)
- p = A()
- #------------打印
- new A <class '__main__.A'>
- init A
首先是new函数的格式
1.继承自object的新式类才有__new__ (在python3中已经无所谓了)
2.__new__至少要有一个参数cls,代表当前类,此参数在实例化时由Python解释器自动识别
3.__new__必须要有返回值,返回实例化出来的实例,这点在自己实现__new__时要特别注意,可以return父类(通过super(当前类名, cls))__new__出来的实例,或者直接是object的__new__出来的实例
4.__init__有一个参数self,就是这个__new__返回的实例,__init__在__new__的基础上可以完成一些其它初始化的动作,__init__不需要返回值
5.如果__new__创建的是当前类的实例,会自动调用__init__函数,通过return语句里面调用的__new__函数的第一个参数是cls来保证是当前类实例,如果是其他类的类名,;那么实际创建返回的就是其他类的实例,其实就不会调用当前类的__init__函数,也不会调用其他类的__init__函数。
总结:从上案例可以看到打印顺序是先调用了new后是init,要了解如果我们不重写new函数,其实我们调用的就是object中的new函数,而init函数也是调的new函数,只要了解,一般不建议使用new函数,关于new函数作用是调用底层的方法并修改也就是自定义函数,达到某些特定的用法.
单例模式 __new__实例拓展
- #通常模式与单例模式:通常的模式是我们平常打开一个文件夹,可以打开多个
- # 单例模式:比如英雄联盟,我们只能打开一个客户端,再次打开一个会提示程序已经运行了,因为在它程序设计上就是基于单例模式(有些游戏支持双开,就是对其进行修改)
- class Test1(object):#普通模式下每个实例的内存地址是不一样的
- __instance = None
- p = Test1()
- print(p)
- p = Test1()
- print(p)
- #打印
- # <__main__.Test1 object at 0x000000000226C198>
- # <__main__.Test1 object at 0x000000000226C208>
- class Test2(object):#单例模式 可以通过很多方式实现,此方法常用
- __instance = None
- def __new__(cls, *args, **kwargs):
- if cls.__instance:
- return cls.__instance
- cls.__instance = super().__new__(cls)
- return cls.__instance
- p = Test2()
- print(p)
- p = Test2()
- print(p)
- #打印
- #<__main__.Test object at 0x00000000023DA7B8>
- #<__main__.Test object at 0x00000000023DA7B8>
- class Singleton(object):
- _instance = None
- def __new__(cls, *args, **kwargs):
- if not cls._instance:
- cls._instance = object.__new__(cls)
- return cls._instance
doc函数 __doc__
- # use __doc__ 属性
- class MyClass:
- 'string.'
- def printSay():
- 'print say welcome to you.'
- print('say welcome to you.')
- print(MyClass.__doc__)
- print(MyClass.printSay.__doc__)
#打印
string.
print say welcome to you.
attr函数 __hasattr__,__setattr__,__getattr__
- class Test(object):
- def __setattr__(self, k,v):
- print(k, v)
- def f(self):
- print('')
- a = Test()#实例化
- a.b =123 #返回b 123
- a.f #没有任何结果
- a.f =1 #返回f 1
- Test().g =123 #返回g 123
- setattr的触发条件是当前对象(.)xx时候就会执行setattr
setattr递归问题
- class Test2(object):
- def __init__(self,k,v):
- self.x = {k, v}
- def __setattr__(self,k,v):
- print(k,v)#x {'123456', 'rainbol'}
- self.x = 'bbb'#注意:在__setattr__方法中里面调用对象.xxx就会出现递归报错RecursionError: maximum recursion depth exceeded
- def __getattr__(self, item):
- print('get',item)
- obj2 = Test2('rainbol','')
- # 了解了setattr的触发机制,所以为了防止实例化时出现进入setattr的方法,一般实例化以下方式
- class Test3(object):
- def __init__(self,k,v):
- #调用父类object的setattr,传入对应参数实现
- object.__setattr__(self,'x',{k,v})
- #self.x = {k, v}
- def __setattr__(self,k,v):
- print(k,v)
- self.x = 'bbb'
- def __getattr__(self, item):
- print('get',item)
- obj3 = Test3('rainbol','')
__getattribute__方法
- # __getattribute__
- class A:
- def __init__(self):
- print('')
- self.a1 = 1
- def __getattr__(self, item):
- print('')
- return 2
- def __getattribute__(self, item):
- print('')
- if item == 'c1':
- raise AttributeError
- return 3
- def d1(self):
- print('')
- return 4
- if __name__ == '__main__':
- t = A() # 实例化a1 = 1 打印11
- print(t.a1) # 实际要打印1可是当前__getattribute__的存在,走__getattribute__方法,打印33,并赋值给a1,打印3
- print(t.b1) # 当前不存在b1属性,直接会走__getattribute__,打印33,并赋值给b1,打印2
- print(
- t.c1) # 当前不存在c1属性,直接会走__getattribute__,打印33,经过item=='c'符合要求走raise错误,在__getattribute__中定义错误AttributeError会走__getattr__方法,如果没有走定义该方法会返回AttributeError错误,此时打印22,并支付给c2,打印2
- print(t.d1()) # TypeError: 'int' object is not callable,说明方法也会走__getattribute__
- # 也就是说只要你定义了__getattribute__,什么属性/方法后都通过该方法获取,最后返回的结果无论定义的属性是否存在,都返回__getattribute__方法的结果
- # 优先级:__getattribute__ > __getattr__ > __dict__
__get__方法
- # __get__
- class A(object):
- def __get__(self, instance, owner):
- print(instance, owner)#instance:实际拥有者的实例,没有返回None owner:实际所属的类
- return ''
- class B(object):
- a = A()
- if __name__ == '__main__':
- t = B()#实例化
- print(t.a)
- print(B.a)
- #a是一个类的属性,只要t.a活着B.a就会执行A的__get__方法,如果把a = A()放在__init__中就不会执行__get__了
- #所以只要有__get__的方法只能是类属性的时候生效,其他情况下不生效
import函数 __import__
- #当我们了解了文件导入的功能,__import__其实就很简单了
- #1. 函数功能用于动态的导入模块,主要用于反射或者延迟加载模块。
- #2. __import__(module)相当于import module
- #直接导入文件
- __import__('templates.a')#直接导入templates目录下a文件
- #添加上层目录的文件
- top = os.path.dirname(os.path.abspath(__file__))
- sys.path.append(top)
- sys.path.append('../')#添加环境变量
- __import__('top.test')#之后和直接导入一致,导入文件
- #了解了__import__的导入文件,还可以导入模块
- #通过字符串赋值的方式导入,并使用该方法
- #案例1
- res = 'time'
- res = __import__(res)
- res.sleep(500)
- #案例2
- flask = __import__('flask')
- app = flask.Flask(__name__)
- @app.route('/',methods=['POST','GET'])
- def helloworld():
- return 'ok'
- app.run()
- #案例3
- res = __import__ ('os.path')#也可以通过这种方式
- res.mkdir('file_text')
- class MyItem:
- def __init__ (self, username, password):
- self.username = username
- self.password = password
- item = MyItem('rainbol', '')
- item.myapp = ['你好123']
- print(item.__dir__()) # 返回所有属性(包括方法)组成列表,可以看到返回了我们刚刚定义的myapp
- #'name', 'price', 'myapp', '__module__', '__init__', 'info', '__dict__', '__weakref__', '__doc__', '__repr__', '__hash__', '__str__', '__getattribute__', '__setattr__', '__delattr__', '__lt__', '__le__', '__eq__', '__ne__', '__gt__', '__ge__', '__new__', '__reduce_ex__', '__reduce__', '__subclasshook__', '__init_subclass__', '__format__', '__sizeof__', '__dir__', '__class__']
#或者如下方式也可以- print(dir(item)) # 返回所有属性(包括方法)排序之后的列表
- #['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'info', 'myapp', 'name', 'price']
我们知道dir()可以返回一些类,变量,模块,甚至是内建属性的函数名称,那我们也可以修改它的返回
- import time
- __all__ = ["this_time","res"] #__all__,如果显式声明了 __all__, import * 就只会导入 __all__ 列出的成员,也就说如果存在的方法没有写入__all__中,此时导入该方法就会报错,如果 __all__ 定义有误,列出的成员不存在,还会明确地抛出异常,而不是默认忽略。
# __all__的作用就是你定义了特别多的方法,你只想要别人导入指定的方法(非硬性),其他可以参考https://blog.csdn.net/hang916/article/details/79474821- this_time = time.time()
- class MyItem02:
- def __init__ (self, username, password):
- self.username = username
- self.password = password
- def mypass (self):
- self.tString = self.username + self.password
- def __dir__(self):
- return __all__ #让__dir__返回__all__内容
- res = MyItem02('rainbol',123456)
- print(dir(res))#['res', 'this_time'] dir(对象)说白了就是返回当前对象的所有数据的key
- print(dir(sys.modules[__name__])) # 使用__name__获取当前module对象,然后使用对象获得dir
- #我们知道with有着自动关闭的功能,就像打开文件一样,类也是一样,但要有两个内建函数的帮助
- with open('xxx','r') as f:
- f.read()
- class MysqlConnect(object):
- def open(self):
- pass
- def fetchone(self):
- pass
- def fetchall(self):
- pass
- def close(self):
- pass
- def __enter__(self):
- self.open()
- return self
- def __exit__(self, exc_type, exc_val, exc_tb):
- self.close()
- #通常情况下
- obj = MysqlConnect()
- obj.open()
- obj.fetchall()
- obj.close()
- #使用with
- with MysqlConnect() as f:#当出现with时自动调用类中的__enter__方法.
- f.fetchall()
- #当类不用了时会自动执行__exit__方法
#当出现这种情况一般是做离线测试
- #实例
- class Test(object):
- def __enter__(self):
- self.r = open('xxx.txt','w',encoding='utf-8')
- return self.r
- def __exit__(self, exc_type, exc_val, exc_tb):
- self.r.close()
- with Test() as f:
- f.write('')
__dict__
- class Foo(object):
- def __init__(self, name, age1):
- self.name = name
- self.age1 = age1
- v1 = Foo('rainbol', 17)
- print(v1.__dict__) # {'name': 'rainbol', 'age1': 17}会把对象中找到所有变量并将其转化为字典形式
__setitem__,__getitem__,__delitem__
- # class Func(object):
- # pass
- # r = Func()
- # r['xx'] = 1#TypeError: 'Func' object does not support item assignment
- # 使用一个对象[key] = value会执行__setitem__,当前类没有定义所以就报错了
- class Func1(object):
- def __setitem__(self, key, value): # 支持赋值
- print('__setitem__被执行了')
- def __getitem__(self, item): # 支持取值
- print('__getitem__被执行了')
- def __delitem__(self, key): # 支持删除值
- print('__delitem__被执行了')
- res = Func1()
- res['xx'] = 1 # __setitem__被执行了
- res['xx'] # __getitem__被执行了
- del res['xx'] # __delitem__被执行了
__slots__
- class Rain1(object):
- pass
- a1 = Rain1()
- a1.x = 'rainbol'
- print(a1.x)
- class Rain2(object):
- __slots__ = 'xx'
- a1 = Rain2()
- a1.x = 'rainbol'
- print(a1.x) #AttributeError: 'Rain1' object has no attribute 'x'
- #__slots__是一个类变量,变量可以是元祖字典列表或者迭代对象,也可以是字符串
- #__slot__的作用:我们可以看到实例中al.x报错了,因为使用了__slots__之后使得__dict__不生效,再因为a1.x使用了__setattr__方式,内部再调用__dict__方法,所以不能用了
- #当你定义了__slots__之后,由它定义中的类生成的实例不再具有__dict__属性,它就会为实例使用一个很小的固定大小数组来构建实例,而不是为每个实例都定义一个,比如↓
- class Rain3(object):
- __slots__ = 'xx'
- def fuc(self):
- pass
- a = Rain3()
- b = Rain3()
- c = Rain3()
- #假如你创造了很多实例,这些实例都在运行都没有销毁,我们知道创建__dict__字典会消耗大量内存,在__slots__中列出的属性名在内部被映射到这个数组的指定小标上
- #优点:当一个类有少量类方法,但有大量实例时,节省内存空间
- #通过实例只能创建叫xx的属性,起到限制作用,当然也可以设置多个类属性 __slots__ = ['name','age','password']
- #缺点:大部分内置方法都用到__dict__,所有慎用
特殊函数 以上一些函数比较常用,我这个重点举例,下面是一些方法,所有的符号都有自己定义的方法如:1+2 这个加号就调用了__add__方法,==>a.__add__(b) 所以其实所有的特殊字符也都是方法
类的基础方法

行为方式以及迭代

计算属性
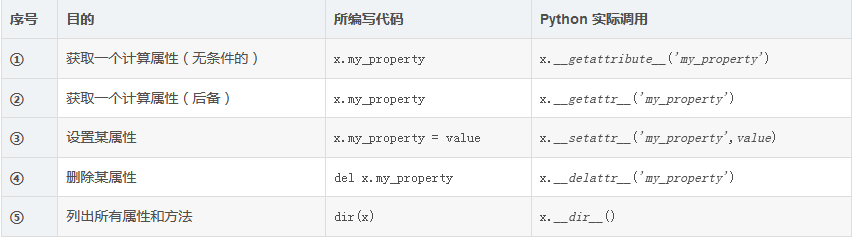
函数类似的类

序列类似的类

字典类似的类
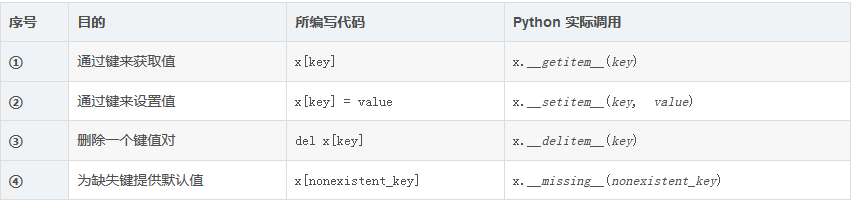
比较的类
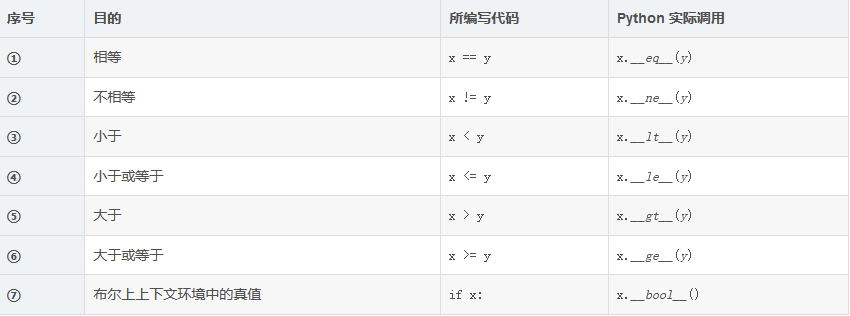
可序列化的类
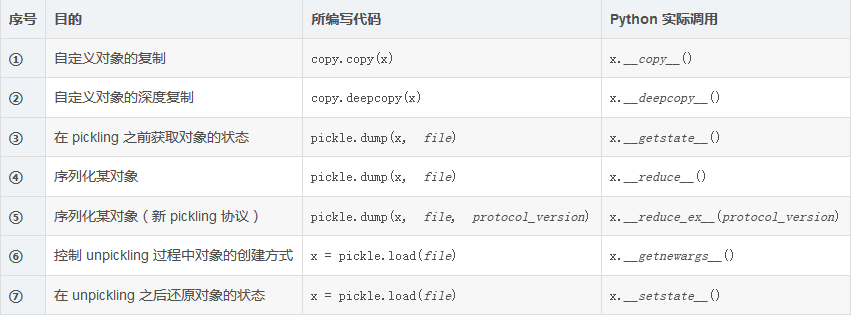
with语块中的类

底层操作

特殊属性
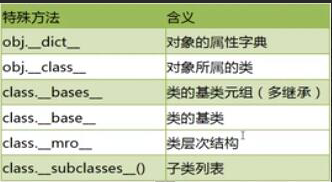
没有重载 python中没有重载,在python中当出现了两个一模一样的方法python会自动调用最后一个有效的方法
封装
把一些功能的实现细节不对外暴露,类中对数据的赋值、内部调用对外部用户是透明的,这使类变成了一个胶囊或容器,里面包含着类的数据和方法
属性方法 @property
看着像变量的方法,装逼用
- class A:
- def __init__(self,name):
- self.name = name
- @property
- def proper(self):
- return self.name
- class B:
- def __init__(self,name):
- self.name = name
- def proper(self):
- return self.name
- aaa = A('小明')
- bbb = B('小红')
- print(aaa.proper)
- print(bbb.proper())其两者效果相同
注意:属性方法不能传参数,也就是不能@property def proper(self,a,b): pass 不能这样写, 回报错TypeError: proper() missing 1 required positional argument
继承
继承称为面向对象三大特性之二,子类继承了父类的属性和方法,父类中的东西都有
- class Father:
- def __init__(self,name):
- self.name = name
- def father(self):
- print('长相')
def super01(self,name):
print("%s工作"%name)
print("%s工作"%name)- class Son(Father):#子类继承父类用括号包裹父类,当然还可以多继承,class Son(Father1,Father2,Father3),注意:如果想要调用其众多父类中同一方法名,多继承调用取继承类最左边的类,也就是Father1;多继承的优先级是从Father1开始找,并再查找Father的父类直到其基类(如果是同一基类现在不会去基类找),直到Father3最后去基类找
- def son(self):
- print("身高180")
def father(self):
print("heath")# Son类继承了Father类,在Son类中这个方法和Father类中的方法名一样,又添加或者是更变了新功能,这个称为方法的重写
def super01(self):
super(Son,self).super01(name)# super方法表示主动会调用父类的super01方法,意思是执行原来有的功能,一般用于迭代,保留原来功能加入新功能,想要删除原来功能只有重写
#Father.super01(self,name)# 主动调用父类方法,但是这种方法实用
print("这个我新加的功能")- son = Son('继承')
- son.father()
- print(issubclass(Son,Father)) #判断Son是否是Father的子类或子子类或子子子...,返回布尔值,子类在前父类在后,注意其关系是子子孙孙与父的关系
- #注意:继承注重于self,也就是对象的传递,一层一层按照层级寻找,我们要能够看清self的传递关系,和继承的优先级
继承的执行先会去执行父类再到其本身
在项目中存在大量super,其他意思不能实际理解成super就是调用了该父类,应从项目初始调用开始,其类的父类才是实际要找的
print(子类.__base__)#查看该类被继承的父类
多继承
python3使用的多继承时使用的内部的c3算法计算,我们今天查看资料了解,查看继承关系可以通过:类.__mro__打印,当然super也是通过mro来衍生的
组合 和继承类似,打个比方来区别 继承就是:狗是动物,那狗就继承了动物,组合就是:手机有cpu,不能说手机是cpu,这就是组合
- class Animal:
- def active(self,name,form):
- print("名字叫%s的%s在叫"%(name,form))
- def fuc(self,form):
- print(form)
- class Pet:
- def __init__(self, name,form):
- self.name = name
- animal1 = Animal()#创建一个对象
- animal2 = Animal()#创建另一个对象
- laifu = Pet(animal1,animal2)#Pet类和animal类组合,所以对象之间的继承叫组合
- laifu.name.active("来福","狗")#名字叫来福的狗在叫
- laifu.name.active("皮特","猫")#名字叫皮特的猫在叫
- laifu.name.fuc('喵喵')
- #虽然也可以laifu.form.active("来福","狗")
- #要注意Pet构造函数中的参数有几个才能创建几个对象,不然会报错
多态
多态称为是面向对象三大特性之三,但是python不支持多态,需要一些代码量来完成,多态的意义就是通过一个方法来统一调用多个类中的方法.
多态就是抽象化的一种体现,把一系列具体事物的共同点抽象出来, 再通过这个抽象的事物, 与不同的具体事物进行对话。
- class Human:
- def __init__(self, name):
- self.name = name
- class Man(Human): # Man继承Human的构造函数方法
- def cry(self):
- print("aaaax")
- class Wormen(Human): # Wormen继承Human的构造函数方法
- def cry(self):
- print("bbbbxx")
- def cry(obj): # 定义一个公共方法,来执行,Man和Wormen
- obj.cry()
- user1 = Wormen('小红') # 实例化四个人类
- user2 = Wormen('小黄')
- user3 = Man('小明')
- user4 = Man('小张')
- list = [user1, user2, user3, user4] # 将其放入一个list中
- for i in list: # 循环列表
- cry(i) # 运行cry方法依次执行来完成控制
私有方法,私有属性
所谓私有就是实例化之后别人不能够调用,在工作中,通常封装一些功能,其只能在类中互相调用,但到了这个类的外头就不能用了,私有就把变量名或者函数名前面加上"__"两个下划线
- class Tom_s_dog:#定义Tom的狗的方法
- dogname = 'dog'
- __dogname = 'rubi'#设置私有属性
- def __init__(self,name):
- self.name = name
- def __fuc(self):
- print("%s走了过来,%s:汪汪汪"%(self.name,self.dogname))
- print("Tom走了过来,%s:不叫了"%self.__dogname)
- def cry(self):
- self.__fuc()
- xiaoming = Tom_s_dog('小明')
- xiaoming.cry()#可以调用,因为cry没有设置为私有方法.成功调用__fuc中的私有方法
- xiaoming.__fuc()#报错不能调用
- xiaoming.__dogname#报错不能调用
print(xiaoming._Tom_s_dog__dogname) #强制获取私有字段
静态方法,类方法,类变量
- class Stu(object):
- country = 'china' # 类变量
- def __init__(self, name):
- self.name = name
- @staticmethod
- # 静态方法,和类本身没有什么关系了,就相当于在类里面定义了一个方法而已
# 静态方法用在哪儿:如果这个函数,没有与类变量,类方法,实例变量,实例方法,那可以把它定义成静态方法
# 类方法和实例方法可以随便调用静态方法,但是静态调用不了别人- def say():
- print('xxx')
- @classmethod
- # 类方法,不需要实例化一个对象,直接可以用类来使用类变量和其他类方法
# 在哪儿用到类方法:表示你这个类方法,没有使用到实例变量和没有调用实例方法,你就可以用类方法- def hello(cls):# cls就是Stu这个类,cls和Stu的内存地址是一样的,在下面可以直接Stu.hello()直接可以用
- print(cls.country)
- def hi(self):
- # 这个是实例方法
- print(self.name)
- t = Stu('name')
- Stu.hello()
- Stu.say()
- t.hi()
- t.say()
- t.hello()
-----------------打印结果
china
xxx
name
xxx
china
方法的动态性
- class A:
- def a(self):
- print("hhh")
- def b():
- print("QQQQ")
- AA = A()
- AA.a()#可以调用a方法
- #AA.b()不可以调用报错了,怎么加b进去呢?
- AA.B = b#此时把b赋值给AA对象的B,B是我新定义的值.相当与一个变量
- AA.B()#此时查看结果,"QQQQ",记住:所有的方法,函数,一切都是对象
- isinstance
- class Gandpa(object):
- pass
- class Father(Gandpa):
- pass
- class Son(Father):
- pass
- r = Son()
- print(isinstance(r,Son))#True
- print(isinstance(r,Father))#True
- print(isinstance(r,Gandpa))#True
- #可以看到isinstance是判断r对象是否是Son以及其祖先的实例(对象),返回布尔值
- if type(r) == Son:
- print('Son')
- if type(r) == Father:
- print('Father')
- if type(r) == Gandpa:
- print('Gandpa')
- #打印Son,可以看到使用type能更精确的判断r对象是否是其直接类的实例(对象)
-> 函数注释
- # ->也叫标记返回函数注释,只是便于阅读的一种注释
- class TagReturns(object):
- def __init__(self, username: str = '', password: str = '', number: str = int) -> None:
- self.username = username
- self.password = password
- self.number = number
- def error_instance(self) -> None:
- print(self.username + self.number)
- return self.username + self.number # 如果在pycharm中这段会标黄,因为它违反了PEP 484,->None表明预期为None,而是实际返回str类型
- # 应该如下格式编写,其按照PEP 484 - Type Hints编写格式,虽然没有强制规则,代码也不会报错
- def true_instance(self) -> str:
- print(self.username + self.number)
- return self.username + self.number
- def attrs(self) -> bool:
- return True
- def ottrs(self) -> callable:
- return self.attrs
- def bttrs(self) -> [12, 34, 56]: # 也可以指定一些值,可以便于阅读代码,其他并没有什么用
- print(self.true_instance.__annotations__) # {'return': <class 'bool'>}
- return {"ss": 11234}
- res = TagReturns('rainbol', '', 'number_008')
- print(res.bttrs.__annotations__) # {'return': [12, 34, 56]} 返回指定函数注释的一个字典
版权声明:本文原创发表于 博客园,作者为 RainBol本文欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则视为侵权。
python学习之面向对象的更多相关文章
- Python学习之==>面向对象编程(二)
一.类的特殊成员 我们在Python学习之==>面向对象编程(一)中已经介绍过了构造方法和析构方法,构造方法是在实例化时自动执行的方法,而析构方法是在实例被销毁的时候被执行,Python类成员中 ...
- Python学习一(面向对象和函数式编程)
学习了一周的Python,虽然一本书还没看完但是也收获颇多,作为一个老码农竟然想起了曾经荒废好久的园子,写点东西当做是学习笔记吧 对Python的语法看的七七八八了,比较让我关注的还是他编程的思想,那 ...
- 从0开始的Python学习014面向对象编程
简介 到目前为止,我们的编程都是根据数据的函数和语句块来设计的,面向过程的编程.还有一种我们将数据和功能结合起来使用对象的形式,使用它里面的数据和方法这种方法叫做面向对象的编程. 类和对象是面向对象 ...
- python学习 day23 面向对象三大特性之继承
### 面向对象三大特性值继承#### 1.什么是继承 继承是一种关系,必须存在两个对象才可能产生这种关系,在现实生活中的继承,王思聪可以继承王健林的财产 被继承的成为父,继承的一方成为子 在程序中, ...
- Python学习-day6 面向对象概念
开始学习面向对象,可以说之前的学习和编程思路都是面向过程的,从上到下,一步一步走完. 如果说一个简单的需求,用面向过程实现起来相对容易,但是如果在日常生产,面向对象就可以发挥出他的优势了. 程序的可扩 ...
- Python学习之面向对象基础
python的面向对象和以前学的c++,Java都是一般,大同小异,面向对象基础先谈谈类的构造,编写,属性和方法的可见性等等 1.定义类,创建和使用对象 #定义类 class Student(obje ...
- Python学习--10 面向对象编程
面向对象编程--Object Oriented Programming,简称OOP,是一种程序设计思想.OOP把对象作为程序的基本单元,一个对象包含了数据和操作数据的函数. 本节对于面向对象的概念不做 ...
- python学习总结(面向对象进阶)
-------------------类属性和实例属性关系------------------- 1.类属性和实例属性关系 1.实例属性 实例对象独有的属性 2.类属性 ...
- python学习day19 面向对象(一)封装/多态/继承
面向对象 封装思想:将同一类的函数函数封装到同一个py文件中,方便调用 面向对象也有封装的作用,将同一类的函数封装到一个类中 多态(鸭子模型):多种类型/多种形态 #,什么事鸭子模型 对于一个函数,p ...
- python学习笔记----面向对象
面向对象 类:成员变量(属性) 方法(操作成员变量) 出一个场景:玩过游戏.主人公,进入了一个场景,有10个小怪物是一样的.有攻击力,血(100格).如果小怪物有多个数值需要管理,小怪物的血量.小怪物 ...
随机推荐
- Andrew Ng机器学习课程10补充
Andrew Ng机器学习课程10补充 VC dimension 讲到了如果通过最小化训练误差,使用一个具有d个参数的hypothesis class进行学习,为了学习好,一般需要参数d的线性关系个训 ...
- gcc 不同版本的安装
系统环境centos 6.5 使用root用户进行安装,此方法会将gcc安装至/usr/bin目录下 curl -Lks http://www.hop5.in/yum/el6/hop5.repo ...
- LeetCode 605. 种花问题(Can Place Flowers) 6
605. 种花问题 605. Can Place Flowers 题目描述 假设你有一个很长的花坛,一部分地块种植了花,另一部分却没有.可是,花卉不能种植在相邻的地块上,它们会争夺水源,两者都会死去. ...
- Ubuntu 软件卸载脚本(卸载软件 + 移除配置文件 + 移除依赖项)
#!/bin/bash function z-apt-uninstall() { if [ ! $1 ] then echo "z-apt-uninstall error: software ...
- 修改织梦DedeCMS投票漏洞
织梦/dedecms系统我们都知道是有很多漏洞的,我在调试投票功能的时候正好要用到投票功能,这不就出现了漏洞,下面我就给大家展示如何修复这个织梦投票漏洞 首先我们打开//dedevote.class. ...
- ALV报表——选择屏幕变量赋值
ABAP选择屏幕变量赋值 运行效果: 代码: *&---------------------------------------------------------------------* ...
- 微信公众号h5页面自定义分享
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content ...
- Markdown语法图文全面详解(转)
基本语法参考 转自:https://blog.csdn.net/u014061630/article/details/81359144 更改字体.颜色.大小,设置文字背景色,调整图片大小设置居中 ...
- truncate删除一个分区,测试全局索引是否失效
目的,有一个清理数据的需求,需要删除历史的一个分区所有记录信息,但是存在主键global索引,如何更好的维护. 如下测试流程一 提前创建好一个已时间created 字段作为分区键的范围分区表 SQL& ...
- hdu 2539 虽然是水题 wa了很多次 说明自己的基本功不扎实 需要打好基础先 少年
两点吧 1.gets使用的时候 确保上一次的回车符对其没有影响 getline也是如此 这样的细节.. 多注意啊!! 2.编写程序的时候 对一些极端的情况要多调试 比如此题当 n==1的时候.. ...