大数据之路week06--day07(Hadoop生态圈的介绍)
Hadoop 基本概念
一、Hadoop出现的前提环境
随着数据量的增大带来了以下的问题
(1)如何存储大量的数据?
(2)怎么处理这些数据?
(3)怎样的高效的分析这些数据?
(4)在数据增长的情况下如何构建一个解决方案?
在大数据领域提出了两个概念
(1)分布式文件系统 用于存储大量的数据
(2)分布式计算框架MapReduce高效的分析数据
以上的两个概念组成一个名词 Hadoop
二、Hadoop的起源
谷歌发布了三篇论文 : GFS 分布式存储系统 , MapReduce 分布式计算框架 , BigTable
Hadoop Google
HDFS GFS
MapReduce MapReduce
Hbase BigTable
三、Hadoop与其他的分布式系统比较
(1)Hadoop集群的数据首先先进行分布式的存储
(2)Hadoop集群上通过HDFS分布式文件系统,会把存储的数据复制多份,保证了数据的安全性
(3)提供了一个简单的易用的分布式计算框架
(4)Hadoop扩展容易
四、Hadoop中的版本
Hadoop存在版本的区别:
Hadoop1x版本中核心组件就是为 HDFS ,MapReduce
Hadop2x 版本依然存在HDFS,MapReduce,新增加了一个YARN
五、YARN介绍
(1)云操作系统,理解为资源管理器,管理集群中的资源在增加了YARN操作系统之后,MapReduce任务就可以跑在YARN平台上,通过YARN平台进行MapReduce任务的管理,资源的分配
(2)例如 也可以通过YARN平台运行Spark任务,包括可以读取HDFS上的数据文件
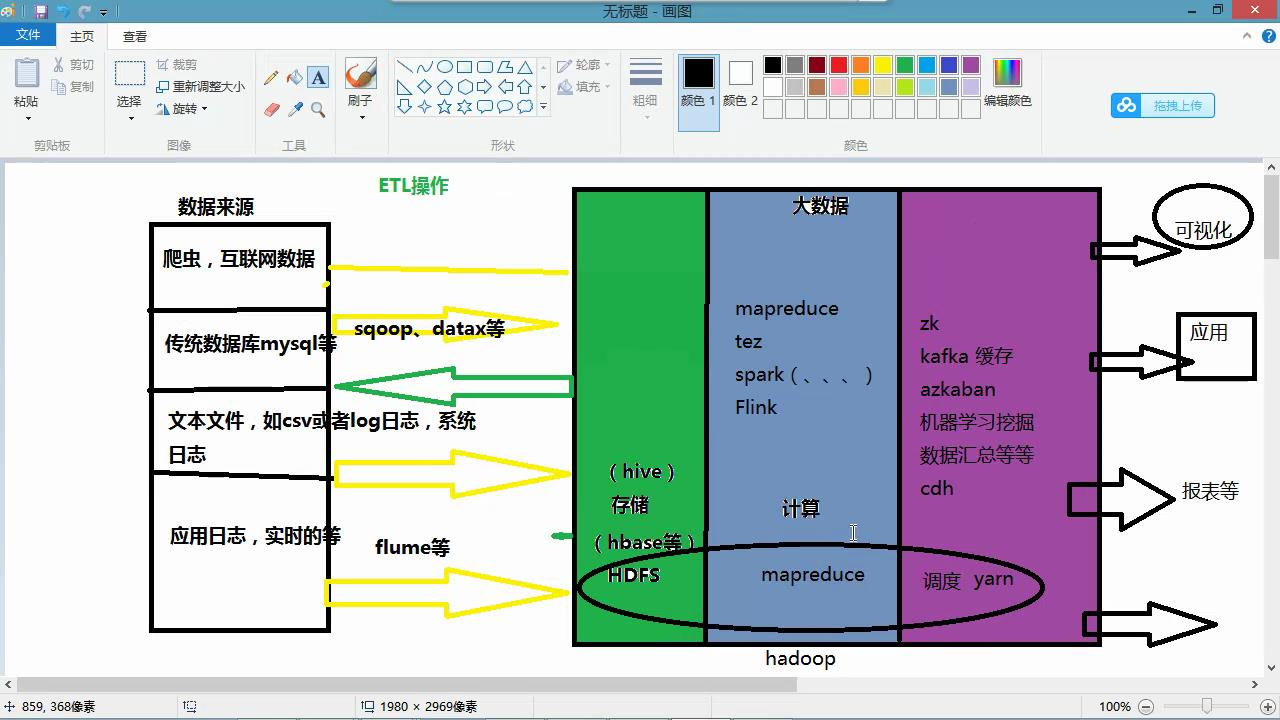
六、Hadoop生态圈的介绍
数据的来源,在企业中一般数据来源分为两种,第一种是企业内部的数据
例如:业务数据(保存在关系型数据库中),应用的服务器日志(日志文件),结构化数据
第二种是外部渠道获得:用户的行为记录(可以作为推荐系统的实现),通过搜索关键字,消费记录,爬虫技术,非结构化数据
数据要进行清洗 hive sqoop flume hbase hdfs mapreduce zookeeper
七、Hadoop的使用案例
现在使用Hadoop进行数据分析的公司越来越多,主要包括以下几种:
(1)为银行和信用卡公司进行欺诈性的检测
(2)社交媒体市场的分析
(3)电商网站的购物模式分析,用户行为分析
(4)城市的发展交通的模式识别
八、Hadoop的企业级应用主要包括四个层次
(1)存储层(HDFS Hbase)
(2)数据处理层 (Hive MapReduce)
(3)实时访问层(Spark Flink)
九、Hadoop中的组件信息
Hadoop中核心组件HDFS,YARN ,MapReduce
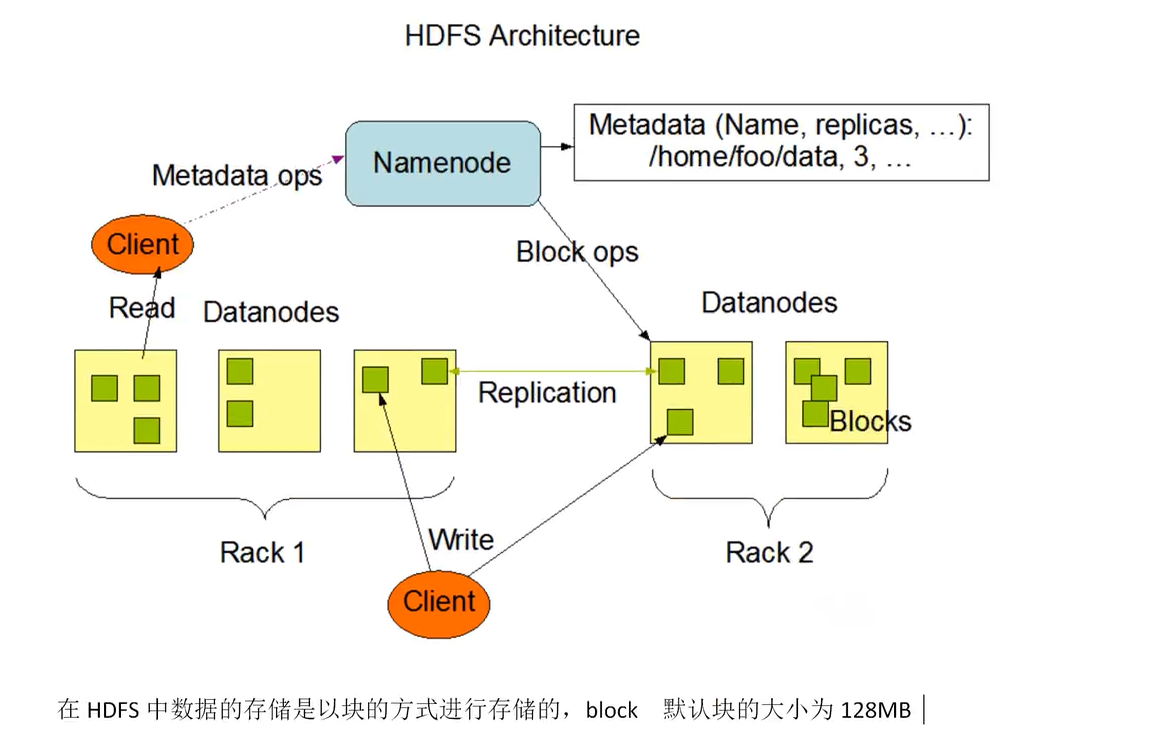
(1)HDFS架构
分布式存储系统,分布式的架构上存在 主/从 的架构关系在HDFS文件系统上存在主节点,以及从节点
主节点:namenode 负责管理HDFS集群文件中的元数据(文件的名称,文件的位置,文件的副本)
从节点:datanode负责存储真正的数据
(2)YARN架构
分布式的架构,分为主从架构
主节点 resourceManager负责管理集群中的所有资源(cpu,内存,磁盘,网络I/O)
从节点 nodeManager负责管理集群中每一台服务器的资源

(3)MapReduce 架构 核心思想 分而治之
Map端和Reduce端进行数据分析
数据在Map阶段进行分开处理,处理完成之后,再交给reduce进行统计,在Map和Reduce中间的阶段通过shuffle来进行连接。
大数据之路week06--day07(Hadoop生态圈的介绍)的更多相关文章
- 大数据之路week07--day03(Hadoop深入理解,JAVA代码编写WordCount程序,以及扩展升级)
什么是MapReduce 你想数出一摞牌中有多少张黑桃.直观方式是一张一张检查并且数出有多少张是黑桃. MapReduce方法则是: 1.给在座的所有玩家中分配这摞牌 2.让每个玩家数自己手中的牌有几 ...
- 大数据之路week06--day07(Hadoop常用命令)
一.前述 分享一篇hadoop的常用命令的总结,将常用的Hadoop命令总结如下. 二.具体 1.启动hadoop所有进程start-all.sh等价于start-dfs.sh + start-yar ...
- 大数据系列(5)——Hadoop集群MYSQL的安装
前言 有一段时间没写文章了,最近事情挺多的,现在咱们回归正题,经过前面四篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,相关的两款软件VSFTP和SecureCRT也已经正常安装了. ...
- 大数据系列(4)——Hadoop集群VSFTP和SecureCRT安装配置
前言 经过前三篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,当然,我相信安装的过程肯定遇到或多或少的问题,这些都需要自己解决,解决的过程就是学习的过程,本篇的来介绍几个Hadoop环 ...
- 大数据系列(3)——Hadoop集群完全分布式坏境搭建
前言 上一篇我们讲解了Hadoop单节点的安装,并且已经通过VMware安装了一台CentOS 6.8的Linux系统,咱们本篇的目标就是要配置一个真正的完全分布式的Hadoop集群,闲言少叙,进入本 ...
- 大数据系列(2)——Hadoop集群坏境CentOS安装
前言 前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题. 技术准备 VMwa ...
- Hadoop生态圈-hbase介绍-伪分布式安装
Hadoop生态圈-hbase介绍-伪分布式安装 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HBase简介 HBase是一个分布式的,持久的,强一致性的存储系统,具有近似最 ...
- CentOS6安装各种大数据软件 第一章:各个软件版本介绍
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- Hadoop生态圈-hbase介绍-完全分布式搭建
Hadoop生态圈-hbase介绍-完全分布式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
随机推荐
- java后台面试之计算机网络问题集锦
1.http和https的区别 2.对称加密和非对称加密 3.三次握手与四次挥手的流程 4.为什么TCP需要三次握手?两次不可以吗?为什么 5.为什么TCP挥手需要四次?三次不行吗? 6.TCP协议如 ...
- Java中的事务及使用
什么是事务? 事务(Transaction),一般是指要做的或所做的事情.在计算机术语中是指访问并可能更新数据库中各种数据项的一个程序执行单元(unit).事务通常由高级数据库操纵语言或编程语言(如S ...
- idea使用maven+Tomcat
1.创建maven项目,并使用webapp骨架,并修改pom.xml文件 <build> <finalName>myWebApp</finalName> <! ...
- CF197A Plate Game
题目描述 你有一个长方形的桌子,长度 a ,宽度 b ,以及无限多的半径 r的圆盘. 两位玩家玩以下游戏:他们轮流把圆盘放在桌子上,使得盘子之间不能互相重叠(但他们的边缘可以互相接触),任何盘子上的任 ...
- STM32之串口硬件连接图
笔记本USB转串口实物连接图: 电路连接图:
- 初始NLTK
NLTK官网:链接 Natural Language Toolkit NLTK corpora and lexical resources such as WordNet, along with a ...
- 最简容器动手小实践——FC坦克大战游戏容器化
FC 经典力作相信大家一点也不陌生.童年时期最频繁的操作莫过于跳关,在 果断跳到最后一关之后,一般都是以惨败告终,所以还是一关一关的过原始积累才能笑到最后.这款游戏的经典就在于双人配合,守家吃装备.也 ...
- [BZOJ3681]Arietta(可持久化线段树合并优化建图+网络流)
暴力建图显然就是S->i连1,i->j'连inf(i为第j个力度能弹出的音符),j'->T连T[j]. 由于是“某棵子树中权值在某区间内的所有点”都向某个力度连边,于是线段树优化建图 ...
- hdu 2586 欧拉序+rmq 求lca
题意:求树上任意两点的距离 先说下欧拉序 对这颗树来说 欧拉序为 ABDBEGBACFHFCA 那欧拉序有啥用 这里先说第一个作用 求lca 对于一个欧拉序列,我们要求的两个点在欧拉序中的第一个位置之 ...
- SVN_03绿色版
1.首先备份当前安装visualSVN文件的bin目录,万一出错还能反个水.一般默认安装路径是C:\Program Files(x86)VisualSVN\bin 2.然后运行ildasm,Windo ...