经典卷积神经网络——AlexNet
一.网络结构
AlexNet由5层卷积层和3层全连接层组成。
论文中是把网络放在两个GPU上进行,为了方便我们仅考虑一个GPU的情况。
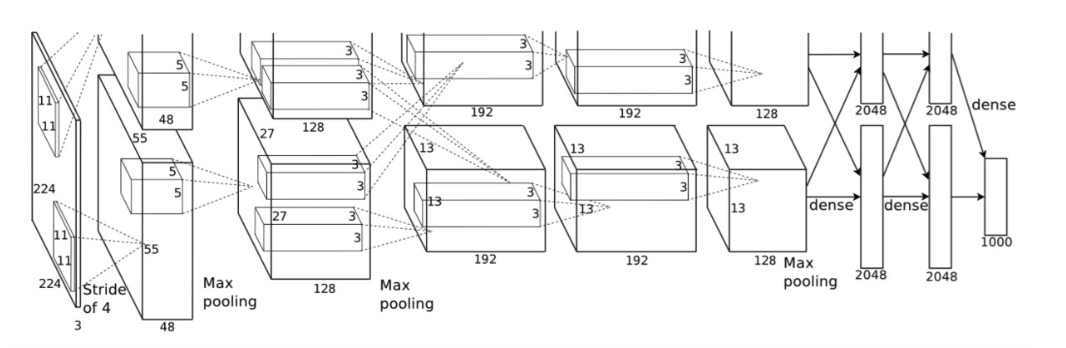
上图中的输入是224×224224×224,不过经过计算(224−11)/4=54.75(224−11)/4=54.75并不是论文中的55×5555×55,而使用227×227227×227作为输入,
卷积层C1:处理流程为:卷积、ReLU、LRN、池化、
卷积:输入为227x227x3,使用96个11x11x3的卷积核,步长为4x4,得到FeatureMap为55x55x96
池化:3x3最大池化,步长为2,得到27x27x96的FeatureMap
卷积层C2: 处理流程为:卷积、ReLU、LRN、池化
卷积:输入为27x27x96,使用256个5x5x96的卷积核(padding = 2),步长为1x1,得到FeatureMap为27*27*256
池化:3x3最大池化,步长为2,得到13x13x26的FeatureMap
卷积层C3: 处理流程为:卷积、ReLU
卷积: 输入为13x13x256,使用384个3x3x256的卷积核(padding = 1),,步长为1x1,得到13x13x384的FeatureMap
卷积层C4: 处理流程为: 卷积、ReLU
卷积:输入为13x13x384,使用256个3x3x384的卷积核(padding = 1),,步长为1x1,得到13x13x256的FeatureMap
卷积层C5:处理流程为:卷积、ReLU、池化
卷积:输入为13x13x256,使用256个3x3x256的卷积核,步长为1x1(padding = 1),,得到13x13x256的FeatureMap
池化:3x3的最大池化,步长为2,得到6x6x256的FeatureMap
全连接层FC6: 处理流程为:全连接、ReLU、Dropout
全连接;输入为6x6x256,使用4096个6x6x256的卷积核,得到1x1x4096
全连接层FC7: 处理流程为:全连接、ReLU、Dropout
全连接:输入1x1x4096,使用4096个1x1x4096的卷积核,得到1x1x4096
输出层:第七层4096个数据与第八层1000个神经元进行全连接,输出1000个float值
二.,模型特点
1.ReLU Nonlinearity
标准L-P神经元的输出一般使用tanh或者sigmoid函数作为激活函数,这些饱和的非线性函数计算机梯度的时候要比非饱和函数max(0,x)慢得多,把非饱和线性函数成为Rectified Linear Units(ReLUs)
2.在两个GPU上训练
使用的GPU为GTX 580,内存只有3GB,使用一个GPU可能会限制训练网络的大小规模,因此使用两个GPU。
并行方案为把一半的神经元放在一个GPU上,GPU的交流仅在一些层上。比如第三层的将第二层的所有输出作为输入,但是第四层将第三层只属于同个GPU的输出作为输入。
3.Local Response Normalization
引入LRN,是为了模仿生物上,被激活的神经元抑制相邻神经元,即侧抑制,归一化的目的就是抑制,LRN借鉴侧抑制实现局部抑制。
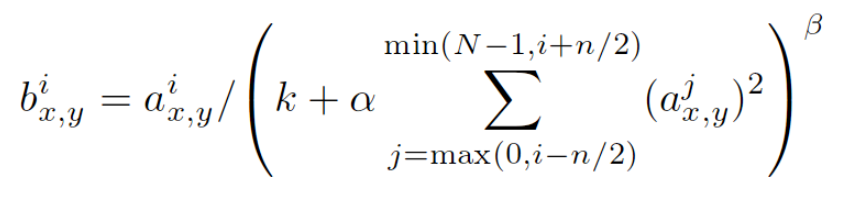
其中bix,y为归一化后的值,i表示通道的位置,x,y代表像素更新的位置
aix,y为输入值,是激活函数ReLU的输入值
k,alpja,beta,n/2为自定义系数,一般设置k=2,n=5,alpha=1Xe-4,beta=0.75。
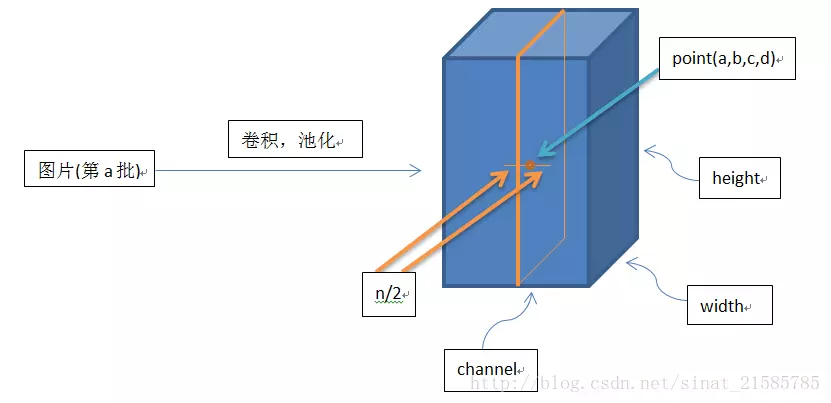
∑叠加方向是沿着通道方向,也就是一个点同方向的前面n/2个通道和后n/2个通道的点的平方和(n+1个点)

但是其他较晚产生的卷积神经网络模型基本不含LRN层,因为LRN的效果不明显,但是会增加2倍的前馈、反馈时间。
同时,LRN对激活函数的选择也有些要求,LRN对于ReLU这种不存在上限边界的激活函数比较有用,因为LRN层的原理就是从多个卷积核响应中选择值比较大的那一个,但是不适合sigmod或tanh这种由上下固定边界的的激活函数,因为这种边界本身就抑制了较大的输入值。
3.4Overlapping pooling
重叠池化有助于减少过拟合。
设池化的大小为zxz,步长为s,如果s<z,即每次池化都会和相邻池化有一部分重叠,称为重叠池化
三.减少过拟合操作
1数据增强
模型随机从256x256大小的原始图像中截取224x224大小的区域,同时还得到图片进行水平翻转后的镜像,相当于数据扩充了2048倍(2^(5+5+2))
测试时,模型会先截取一张图片的四个角加中间位置,并进行左右翻转,这样会获得10张图片,将10张图片作为预测的输入并对得到的10个预测结果求平均值,就是这样图片的预测结果。
2.dropout
在训练过程中,对全连接的神经元按照一定的概率将其暂时从网络中丢弃,暂时是指在此次训练中,被丢弃的神经元不进行前馈和BP了。
对于随机梯度下降来说,由于是随机丢弃,故每一个batch都是在训练一个不同的网络,这样就可以综合多个网络的训练结果。
经典卷积神经网络——AlexNet的更多相关文章
- TensorFlow实战之实现AlexNet经典卷积神经网络
本文根据最近学习TensorFlow书籍网络文章的情况,特将一些学习心得做了总结,详情如下.如有不当之处,请各位大拿多多指点,在此谢过. 一.AlexNet模型及其基本原理阐述 1.关于AlexNet ...
- 经典卷积神经网络(LeNet、AlexNet、VGG、GoogleNet、ResNet)的实现(MXNet版本)
卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现. 其中 文章 详解卷 ...
- 五大经典卷积神经网络介绍:LeNet / AlexNet / GoogLeNet / VGGNet/ ResNet
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习.深度学习的知识! LeNet / AlexNet / GoogLeNet / VGG ...
- 经典卷积神经网络算法(2):AlexNet
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 经典卷积神经网络的学习(一)—— AlexNet
AlexNet 为卷积神经网络和深度学习正名,以绝对优势拿下 ILSVRC 2012 年冠军,引起了学术界的极大关注,掀起了深度学习研究的热潮. AlexNet 在 ILSVRC 数据集上达到 16. ...
- 经典卷积神经网络算法(5):ResNet
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 经典卷积神经网络的学习(二)—— VGGNet
1. 简介 VGGNet 是牛津大学计算机视觉组(Visual Geometry Group)和 Google DeepMind 公司的研究员一起研发的深度卷积神经网络,其主要探索了卷积神经网络的深度 ...
- 经典卷积神经网络算法(1):LeNet-5
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 经典卷积神经网络算法(3):VGG
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
随机推荐
- Disconnected from the target VM, address: '127.0.0.1:56577', transport: 'socket'
Disconnected from the target VM, address: '127.0.0.1:56577', transport: 'socket' Disconnected from t ...
- LINQ to Entities不识别C#语法报错
错误:报错不识别string.Join…… var QueryWithStandard=from a in listA join b in listB on a.ID equals b.AID int ...
- 后代元素 span:first-child{...}
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...
- 纯 css 控制隔行变色
使用::nth-child 选择器 tr:nth-child(odd) { background-color: #ccc; } tr:nth-child(even) { background-colo ...
- 【题解】游荡的奶牛-C++
题目题目描述奶牛们在被划分成N行M列(2 <= N <= 100; 2 <= M <= 100)的草地上游走, 试图找到整块草地中最美味的牧草.Farmer John在某个时刻 ...
- 004——转载C#禁止改变窗体大小
原文链接:http://www.cnblogs.com/shaozhuyong/p/5545005.html 1.先把MaximizeBox和MinimumBox设置为false,这时你发现最大最小化 ...
- python 迭代工具
names = ['anne', 'beth', 'george', 'damon'] ages = [, , , ] for name,age in zip(names,ages): #print( ...
- 推荐 | Vue 入门&进阶路线
今儿跟大家聊聊 Vue . 不得不承认, Vue 越来越受欢迎了.对比 Angular 和 React,虽然三者都是非常优秀的前端框架,但从 GitHub 趋势看,Vue 已经排在第一位,达到了13万 ...
- prometheus简单监控Linux,mysql,nginx
prometheus安装 下载安装 #官网下载 解压即可使用 https://prometheus.io/download/ #docker 方式安装 sudo docker run -n prome ...
- 关于安卓端 点击button时出现橙色边框
一开始我以为是安卓的原因,后来经过测试发现不是,出现这个情况应该button的outline属性生效了,但是我已经写了outline 为none,后来发现,需要写上:foucs{ outline:0 ...