第三篇:Python基本数据类型
在了解基本数据类型的时候,我们需要了解基本数据类型有哪些?数字int、布尔值bool、字符串str、列表list、元组tuple、字典dict等,其中包括他们的基本用法和其常用的方法,这里会一一列举出来,以便参考。然后我们还需要了解一些运算符,因为这些基本数据类型常常会用于一些运算等等。
一、运算符
运算通常可以根据最终获得的值不同,可以分两类,即结果为具体的值,结果为bool值,那么哪些结果为具体的值-->算数运算、赋值运算,哪些结果又为bool值?--->比较运算、逻辑运算和成员运算。
1、算术运算
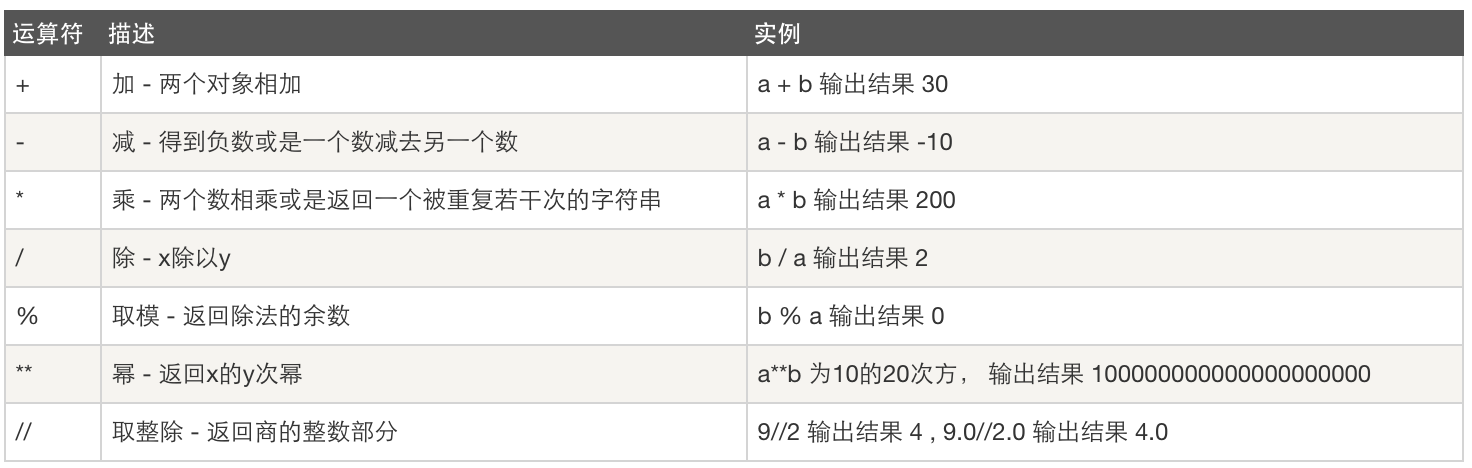
2、赋值运算

3、比较运算
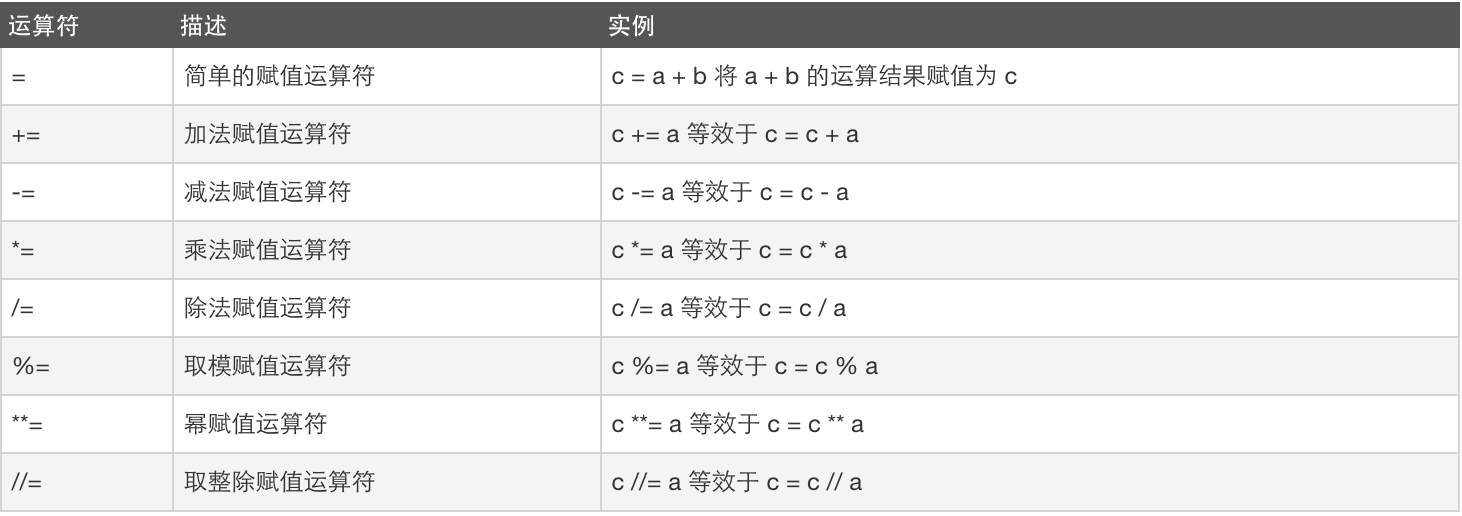
4、逻辑运算

5、成员运算

二、基本数据类型
1、数字 ---> int类
当然对于数字,Python的数字类型有int整型、long长整型、float浮点数、complex复数、以及布尔值(0和1),这里只针对int整型进行介绍学习。
在Python2中,整数的大小是有限制的,即当数字超过一定的范围不再是int类型,而是long长整型,而在Python3中,无论整数的大小长度为多少,统称为整型int。
其主要方法有以下两种:
int -->将字符串数据类型转为int类型, 注:字符串内的内容必须是数字
- 1 #!/usr/bin/env python
- 2 # -*- coding:utf-8 -*-
- 3
- 4 s = ''
- 5 i = int( s )
- 6 print( i)
bit_length() -->将数字转换为二进制,并且返回最少位二进制的位数
- #!/user/bin/env python
- #-*- coding:utf-8 -*-
- i =123
- print( i.bit_length() )
- #输出结果为:
- >>>5
2、布尔值 --->bool类
对于布尔值,只有两种结果即True和False,其分别对应与二进制中的0和1。而对于真即True的值太多了,我们只需要了解假即Flase的值有哪些---》None、空(即 [ ]/( ) /" "/{ })、0;
- #以下结果为假,即None、‘’、[]、()、{}以及 0
- >>> bool(None)
- False
- >>> bool('')
- False
- >>> bool([])
- False
- >>> bool(0)
- False
- >>> bool(())
- False
- >>> bool({})
- False
3、字符串 --->str类
关于字符串是Python中最常用的数据类型,其用途也很多,我们可以使用单引号 ‘’或者双引号“”来创建字符串。
字符串是不可修改的。所有关于字符我们可以从 索引、切片、长度、遍历、删除、分割、清除空白、大小写转换、判断以什么开头等方面对字符串进行介绍。
创建字符串
- #!/usr/bin/env python
- # -*- coding:utf-8 -*-
- #字符串的形式:使用‘’或者“”来创建字符串
- name ='little_five'
- print(name)
切片
- #获取切片,复数代表倒数第几个,从0开始
- >>> name ="little-five"
- >>> name[1]
- 'i'
- >>> name[0:-2] #从第一个到倒数第二个,不包含倒数第二个
- 'little-fi'
索引--> index()、find()
- #!/usr/bin/env python
- # -*- coding:utf-8 -*-
- # 修正版
- name = "little_five"
- #index-->获取索引,语法->str.index(str, beg=0 end=len(string)),第二个参数指定起始索引beg,第三个参数结束索引end,指在起始索引到结束索引之前获取子串的索引
- print(name.index("l",2,8)) #在索引区间2-8之前查找‘l’,找到是第二个‘l’,其索引为4
- #find -->其作用与index相似
- print(name.find("l",2)) #结果也为 4
index()与find()的不同之处在于:若索引的该字符或者序列不在字符串内,对于index--》ValueError: substring not found,而对于find -->返回 -1。
- #!/usr/bin/env python
- # -*- coding:utf-8 -*-
- name = "little_five"
- print(name.index("q",2))
- #index--》输出为:
- >>>Traceback (most recent call last):
- File "C:/Users/28352/PycharmProjects/learning/Day13/test.py", line 5, in <module>
- print(name.index("q",2))
- ValueError: substring not found
- print(name.find("q",2))
- #find--》输出为:
- >>> -1
长度 -->len()
- name = "little_five"
- #获取字符串的长度
- print(len(name))
- #输出为:
- >>> 11
注:len()方法-->同样可以用于其他数据类型,例如查看列表、元组以及字典中元素的多少。
删除 --> del
- #删除字符串,也是删除变量
- >>> name ="little-five"
- >>> del name
- >>> name
- Traceback (most recent call last):
- File "<stdin>", line 1, in <module>
- NameError: name 'name' is not defined
判断字符串内容 --> isalnum()、isalpha()、isdigit()
- #判断是否全为数字
- >>> a =""
- >>> a.isdigit()
- True
- >>> b ="a123"
- >>> b.isdigit()
- False
- #判断是否全为字母
- >>> d ="alx--e"
- >>> d.isalpha()
- False
- >>> c ="alex"
- >>> c.isalpha()
- True
- #判断是否全为数字或者字母
- >>> e ="abc123"
- >>> e.isalnum()
- True
大小写转换 --> capitalize()、lower()、upper()、title()、casefold()
- #!/usr/bin/env python
- # -*- coding:utf-8 -*-
- #大小写的互相转换
- >>> name ="little_five"
- #首字母大写-->capitalize
- >>> name.capitalize()
- 'Little_five'
- #转为标题-->title
- >>> info ="my name is little_five"
- >>> info.title()
- 'My Name Is Little_Five'
- #全部转为小写-->lower
- >>> name ="LITTLE_FIVE"
- >>> name.lower()
- 'little_five'
- #全部转为大写-->upper
- >>> name = "little_five"
- >>> name.upper()
- 'LITTLE_FIVE'
- #大小写转换-->swapcase
- >>> name ="lIttle_fIve"
- >>> name.swapcase()
- 'LiTTLE_FiVE'
判断以什么开头结尾 --> startswith()、endswith()
- #判断以什么开头、结尾
- >>> name ="little-five"
- #判断以什么结尾
- >>> name.endswith("e")
- True
- #判断以什么开头
- >>> name.startswith("li")
- True
扩展-->expandtabs()
- #expandtabs -->返回字符串中的 tab 符号('\t')转为空格后生成的新字符串。通常可用于表格格式的输出
- info ="name\tage\temail\nlittlefive\t22\t994263539@qq.com\njames\t33\t66622334@qq.com"
- print(info.expandtabs(10))
- #输出为:
- name age email
- little-five 22 994263539@qq.com
- james 33 66622334@qq.com
格式化输出-->format()、format_map()
- #格式化输出-->format、format_map
- #forma方法
- #方式一
- >>> info ="my name is {name},I'am {age} years old."
- >>> info.format(name="little-five",age=22)
- "my name is little-five,I'am 22 years old."
- #方式二
- >>> info ="my name is {0},I'am {1} years old."
- >>> info.format("little-five",22)
- "my name is little-five,I'am 22 years old."
- #方式三
- >>> info ="my name is {name},I'am {age} years old."
- >>> info.format(**{"name":"little-five","age":22})
- "my name is little-five,I'am 22 years old."
- #format_map方法
- >>> info ="my name is {name},I'am {age} years old."
- >>> info.format_map({"name":"little-five","age":22})
- "my name is little-five,I'am 22 years old."
jion方法
- #join--> join(): 连接字符串数组。将字符串、元组、列表中的元素以指定的字符(分隔符)连接生成一个新的字符串
- #字符串
- >>> name ="littefive"
- >>> "-".join(name)
- 'l-i-t-t-e-f-i-v-e'
- #列表
- >>> info = ["xiaowu","say","hello","world"]
- >>> "--".join(info)
- 'xiaowu--say--hello--world'
分割 --> split()、partition()
- #分割,有两个方法-partition、split
- #partition -->只能将字符串分为三个部分,生成列表
- >>> name ="little-five"
- >>> name.partition("-")
- ('little', '-', 'five')
- #split-->分割字符串,并且可以指定分割几次,并且返回列表
- >>> name ="little-five-hello-world"
- >>> name.split("-")
- ['little', 'five', 'hello', 'world']
- >>> name.split("-",2) #指定分割几次
- ['little', 'five', 'hello-world']
- >>>
替代 -->replace
- #替代
- >>> name ="little-five"
- >>> name.replace("l","L")
- 'LittLe-five'
- #也可以指定参数,替换几个
- >>> name.replace("i","e",2)
- 'lettle-feve'
- 清除空白 --> strip()、lstrip()、rstrip()
- #去除空格
- >>> name =" little-five "
- #去除字符串左右两边的空格
- >>> name.strip()
- 'little-five'
- #去除字符串左边的空格
- >>> name.lstrip()
- 'little-five '
- #去除字符串右边的空格
- >>> name.rstrip()
- ' little-five'
替换 -->makestran 、translate
- #进行一一替换
- >>> a ="wszgr"
- >>> b="我是中国人"
- >>> v =str.maketrans(a,b) #创建对应关系,并且两个字符串长度要求一致
- >>> info ="I'm a Chinese people,wszgr"
- >>> info.translate(v)
- "I'm a Chine是e people,我是中国人"
4、列表 --->list类
列表是由一系列特定元素顺序排列的元素组成的,它的元素可以是任何数据类型即数字、字符串、列表、元组、字典、布尔值等等,同时其元素也是可修改的。
其形式为:
- names = ['little-five","James","Alex"]
- #或者
- names = list(['little-five","James","Alex"])
索引、切片
- #索引-->从0开始,而不是从一开始
- name =["xiaowu","little-five","James"]
- print(name[0:-1])
- #切片-->负数为倒数第几个,其为左闭右开,如不写,前面表示包含前面所有元素,后面则表示后面所有元素
- m1 =name[1:]
- print(m1)
- #输出为-->['little-five', 'James']
- m2 =name[:-1]
- print(m2)
- #输出为-->['xiaowu', 'little-five']
追加-->append()
- #追加元素-->append()
- name =["xiaowu","little-five","James"]
- name.append("alex")
- print(name)
- #输出为--》['xiaowu', 'little-five', 'James', 'alex']
拓展-->extend()
- #扩展--》其将字符串或者列表的元素添加到列表内
- #一、将其他列表元素添加至列表内
- name =["xiaowu","little-five","James"]
- name.extend(["alex","green"])
- print(name)
- #输出为-->['xiaowu', 'little-five', 'James', 'alex', 'green']
- #二、将字符串元素添加到列表内
- name =["xiaowu","little-five","James"]
- name.extend("hello")
- print(name)
- #输出为-->xiaowu', 'little-five', 'James', 'alex', 'green', 'h', 'e', 'l', 'l', 'o']
- #三、将字典元素添加至列表内,注:字典的key。
- name =["xiaowu","little-five","James"]
- name.extend({"hello":"world"})
- print(name)
注:扩展extend与追加append的区别:-->前者为添加将元素作为一个整体添加,后者为将数据类型的元素分解添加至列表内。例:
- #extend-->扩展
- name =["xiaowu","little-five","James"]
- name.extend(["hello","world"])
- print(name)
- 输出为-->['xiaowu', 'little-five', 'James', 'hello', 'world']
- #append -->追加
- name.append(["hello","world"])
- print(name)
- 输出为 -->['xiaowu', 'little-five', 'James', ['hello', 'world']]
insert() -->插入
- #insert()插入-->可以指定插入列表的某个位置,前面提到过列表是有序的
- name =["xiaowu","little-five","James"]
- name.insert(1,"alex") #索引从0开始,即第二个
- print(name)
pop() -->取出
- #pop()--取出,可将取出的值作为字符串赋予另外一个变量
- name =["xiaowu","little-five","James"]
- special_name =name.pop(1)
- print(name)
- print(special_name,type(special_name))
- #输出为:['xiaowu', 'James']
- # little-five <class 'str'>
remove()-->移除、del -->删除
- #remove -->移除,其参数为列表的值的名称
- name =["xiaowu","little-five","James"]
- name.remove("xiaowu")
- print(name)
- #其输出为:['little-five', 'James']
- #del -->删除
- name =["xiaowu","little-five","James"]
- #name.remove("xiaowu")
- del name[1]
- print(name)
- #其输出为:['xiaowu', 'James']
sorted()-->排序,默认正序,加入reverse =True,则表示倒序
- #正序
- num =[11,55,88,66,35,42]
- print(sorted(num)) -->数字排序
- name =["xiaowu","little-five","James"]
- print(sorted(name)) -->字符串排序
- #输出为:[11, 35, 42, 55, 66, 88]
- # ['James', 'little-five', 'xiaowu']
- #倒序
- num =[11,55,88,66,35,42]
- print(sorted(num,reverse=True))
- #输出为:[88, 66, 55, 42, 35, 11]
5、元组 --->tuple类
元组即为不可修改的列表。其于特性跟list相似。其使用圆括号而不是方括号来标识。
- #元组
- name = ("little-five","xiaowu")
- print(name[0])
6、字典 --->dict类
字典为一系列的键-值对,每个键值对用逗号隔开,每个键都与一个值相对应,可以通过使用键来访问对应的值。无序的。
键的定义必须是不可变的,即可以是数字、字符串也可以是元组,还有布尔值等。
而值的定义可以是任意数据类型。
- #字典的定义
- info ={
- 1:"hello world", #键为数字
- ("hello world"):1, #键为元组
- False:{
- "name":"James"
- },
- "age":22
- }
遍历 -->items、keys、values
- info ={
- "name":"little-five",
- "age":22,
- "email":"99426353*@qq,com"
- }
- #键
- for key in info:
- print(key)
- print(info.keys())
- #输出为:dict_keys(['name', 'age', 'email'])
- #键值对
- print(info.items())
- #输出为-->dict_items([('name', 'little-five'), ('age', 22), ('email', '99426353*@qq,com')])
- #值
- print(info.values())
- #输出为:dict_values(['little-five', 22, '99426353*@qq,com'])
7、集合 -->set类
关于集合set的定义:在我看来集合就像一个篮子,你可以往里面存东西也可往里面取东西,但是这些东西又是无序的,你很难指定单独去取某一样东西;同时它又可以通过一定的方法筛选去获得你需要的那部分东西。故集合可以 创建、增、删、关系运算。
集合的特性:
1、去重
2、无序
3、每个元素必须为不可变类型即(hashable类型,可作为字典的key)。
创建:set、frozenset
- #、创建,将会自动去重,其元素为不可变数据类型,即数字、字符串、元组
- test01 ={"zhangsan","lisi","wangwu","lisi",,("hello","world",),True}
- #或者
- test02 =set({"zhangsan","lisi","wangwu","lisi",,("hello","world",),True})
- #、不可变集合的创建 -->frozenset()
- test =frozenset({"zhangsan","lisi","wangwu","lisi",,("hello","world",),True})
增: add、update
- #更新单个值 --->add
- names ={"zhangsan","lisi","wangwu"}
- names.add("james") #其参数必须为hashable类型
- print(names)
- #更新多个值 -->update
- names ={"zhangsan","lisi","wangwu"}
- names.update({"alex","james"})#其参数必须为集合
- print(names)
删除:pop、remove、discard
- #随机删除 -->pop
- names ={"zhangsan","lisi","wangwu","alex","james"}
- names.pop()
- print(names)
- #指定删除,若要删除的元素不存在,则报错 -->remove
- names ={"zhangsan","lisi","wangwu","alex","james"}
- names.remove("lisi")
- print(names)
- #指定删除,若要删除的元素不存在,无视该方法 -->discard
- names ={"zhangsan","lisi","wangwu","alex","james"}
- names.discard("hello")
- print(names)
关系运算:交集 & 、并集 | 、差集 - 、交差补集 ^ 、 issubset 、isupperset
比如有两个班英语班和数学班,我们需要统计这两个班中报名情况,例如既报名了英语班有报名数学班的同学名字等等,这时候我们就可以应用到集合的关系运算:
- english_c ={"ZhangSan","LiSi","James","Alex"}
- math_c ={"WangWu","LiuDeHua","James","Alex"}
- #1、交集--> in a and in b
- #统计既报了英语班又报了数学班的同学
- print(english_c & math_c)
- print(english_c.intersection(math_c))
- #输出为:{'Alex', 'James'}
- #2、并集--> in a or in b
- #统计报名了两个班的所有同学
- print(english_c | math_c)
- print(english_c.union(math_c))
- #输出为:{'James', 'ZhangSan', 'LiuDeHua', 'LiSi', 'Alex', 'WangWu'}
- #3、差集--> in a not in b
- #统计只报名英语班的同学
- print(english_c - math_c)
- print(english_c.difference(math_c))
- #输出为:{'LiSi', 'ZhangSan'}
- 4、交差补集
- #统计只报名一个班的同学
- print(english_c ^ math_c)
- #输出为:{'LiuDeHua', 'ZhangSan', 'WangWu', 'LiSi'}
判断两个集合的关系是否为子集、父集 --> issubset 、isupperset
- #5、issubset-->n 是否为 m 的子集
- # issuperset --> n 是否为 m 的父集
- n ={1,2,4,6,8,10}
- m ={2,4,6}
- l ={1,2,11}
- print(n >= m)
- #print(n.issuperset(m)) #n 是否为 m的父集
- #print(n.issuperset(l))
- print(m <=n)
- #print(m.issubset(n)) #m 是否为 n的子集
第三篇:Python基本数据类型的更多相关文章
- 【Python之路】第三篇--Python基本数据类型
运算符 1.算数运算: # 在py2的 取整除运算中 9//2 = 4.0 # 引入 from __future__ import division 9//2 = 4.5 # py3中不需要! 2.比 ...
- 【0728 | 预习】第三篇 Python基础
第三篇 Python基础预习 Part 1 变量 一.什么是变量? 二.为什么要有变量? 三.定义变量 四.变量的组成 五.变量名的命名规范 六.变量名的两种风格 Part 2 常量 Part 3 P ...
- Python开发【第三篇】基本数据类型
整型 int __author__ = 'Tang' # 将字符串转换为数字 a = " b = int(a) # 前面是0的数转换,默认base按照十进制 a = " b = i ...
- python学习【第三篇】基本数据类型
Number(数字) int(整型) 在32位机器上,整数的位数为32位,取值范围为-2**31-2**31-1,即-2147483648-2147483647 在64位系统上,整数的位数为64位,取 ...
- Python之路(第五篇) Python基本数据类型集合、格式化、函数
一.变量总结 1.1 变量定义 记录某种状态或者数值,并用某个名称代表这个数值或状态. 1.2 变量在内存中的表现形式 Python 中一切皆为对象,数字是对象,列表是对象,函数也是对象,任何东西都是 ...
- 第三篇 Python关于mysql的API--pymysql模块, mysql事务
python关于mysql的API--pymysql模块 pymysql是Python中操作MySQL的模块,其使用方法和py2的MySQLdb几乎相同. 模块安装 pip install pymys ...
- 第一篇 Python的数据类型
Python的标准数据类型有五种: (1)字符串 (2)数字(包括整数,浮点数,布尔,复数) (3)列表(list) (4)元组(tuple) (5)字典(dict) 注:使用type函数可以查看对象 ...
- 第七篇Python基本数据类型之数字&字符串&布尔值
数字 写在最前,必须要会的:int() 整型 Python3里无论数字多长都用int表示,Python2里有int和Long表示,Long表示长整型 有关数字的常用方法,方法调用后面都必须带括号() ...
- Python学习日记(三)——Python基本数据类型(运算符、int、str、tuple、dict、range)
运算符 1.算数运算 2.比较运算 3.赋值运算 4.逻辑运算 5.成员运算 基本数据类型 1.数字 int(整型) 在32位机器上,整数的位数为32位,取值范围为-2**31-2**31-1,即-2 ...
- 三、Python基本数据类型
一.基本算术运算(获取的结果是值) 1 a1=10 2 a2=20#初始赋值 3 a3=a1+a2 #结果30 4 a4=a2-a1 #结果10 5 a5=a1*a2 #结果200 6 a6=a2/a ...
随机推荐
- 海康威视实时预览回调PS流用EasyRTMP向RTMP服务器推流中视频数据处理的代码
在上一篇方案<EasyRTMP结合海康HCNetSDK获取海康摄像机H.264实时流并转化成为RTMP直播推流(附源码)>我们介绍了将海康安防摄像机进行互联网直播的整体方案流程,其中有一个 ...
- npm publish 一直报错 404
在封装 zswui react ui 组件库的时候,尝试了下 github的 packages 包设置,然后就给自己挖坑了. zswui 这是一个从零开始配置,实现组件开发测试的项目. 因为设置 ...
- Swift4.0复习特性、编译标志和检查API的可用性
1.Swift中的特性: @引出,后面紧跟特性名,圆括号带参数即可. @attribute(args) avaiable: 指明对象,函数,类型的可用性. @available(iOS 10.0, m ...
- kafka删除topic后再创建同名的topic报错(ERROR org.apache.kafka.common.errors.TopicExistsException)
[hadoop@datanode3 logs]$ kafka-topics.sh --delete --zookeeper datanode1:2181 --topic firstTopic firs ...
- Windows Server 2012 安装 .NET 3.5 解决办法
我遇到的每台Windows Server 2012都会遇到无法通过控制面板进行.net3.5安装的问题,在网上找了很多办法都不适合自己,最后研究出来一个办法就是 1.首先从镜像提取sxs文件放置到一个 ...
- 模型-视图-控制器的C++解释
模型-视图-控制器 (MVC) 并非一种技术,而是软件设计/工程的一个概念.MVC包含三个组成部分,如下图所示 模型 模型直接响应对数据的处理,比如数据库.模型不应依赖其它组成部分,即视图或控制器,换 ...
- QT qml TreeView展示数据结构于界面
Class QAbstractItemModel: 使用QML的TreeView类来展示树状的结构,对应的是QT的Model/View模型.这个model是一个数据模型,要为TreeView提供一个 ...
- PHP中文名加密
<?php function encryptName($name) { $encrypt_name = ''; //判断是否包含中文字符 if(preg_match("/[\x{4e0 ...
- LeetCode 21. 合并两个有序链表(Merge Two Sorted Lists)
21. 合并两个有序链表 21. Merge Two Sorted Lists 题目描述 将两个有序链表合并为一个新的有序链表并返回.新链表是通过拼接给定的两个链表的所有节点组成的. LeetCode ...
- Pytorch 网络结构可视化
安装 conda install graphvizconda install tensorwatch 载入库 import sysimport torchimport tensorwatch as t ...