ElasticSearch——冷热(hot&warm)架构部署
背景
最近在做订单数据存储到ElasticSearch,考虑到数据量比较大,采用冷热架构来存储,每月建立一个新索引,数据先写入到热索引,通过工具将3个月后的索引自动迁移到冷节点上。
ElasticSearch版本:6.2.4
冷热架构
官方叫法:热暖架构——“Hot-Warm” Architecture。
通俗解读:热节点存放用户最关心的热数据;温节点或者冷节点存放用户不太关心或者关心优先级低的冷数据或者暖数据。

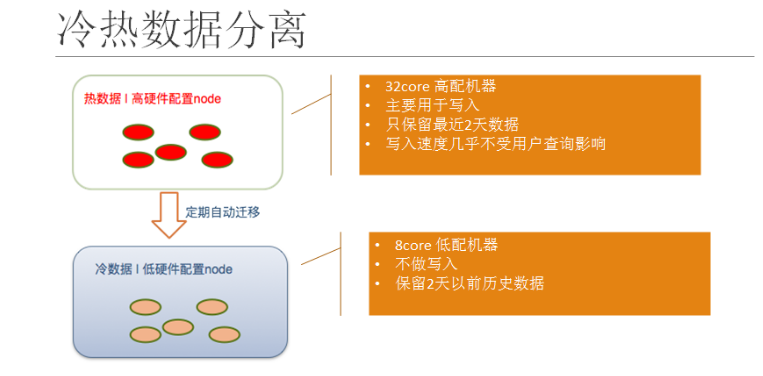
1.1 官方解读冷热架构
为了保证Elasticsearch的读写性能,官方建议磁盘使用SSD固态硬盘。然而Elasticsearch要解决的是海量数据的存储和检索问题,海量的数据就意味需要大量的存储空间,如果都使用SSD固态硬盘成本将成为一个很大的问题,这也是制约许多企业和个人使用Elasticsearch的因素之一。为了解决这个问题,Elasticsearch冷热分离架构应运而生。
冷热架构是一项十分强大的功能,能够让您将 Elasticsearch 部署划分为“热”数据节点和“冷”数据节点。
- 热数据节点处理所有新输入的数据,并且存储速度也较快,以便确保快速地采集和检索数据。
- 冷节点的存储密度则较大,如需在较长保留期限内保留日志数据,不失为一种具有成本效益的方法。
将这两种类型的数据节点结合到一起后,您便能够有效地处理输入数据,并将其用于查询,同时还能在节省成本的前提下在较长时间内保留数据。此架构对日志用例来说尤其大有帮助,因为在日志用例中,人们的大部分精力都会专注于近期的日志(例如最近两周),而较早的日志(由于合规性或者其他原因仍需要保留)则可以接受较慢的查询时间。
1.2 典型应用场景
一句话:在成本有限的前提下,让客户关注的实时数据和历史数据硬件隔离,最大化解决客户反应的响应时间慢的问题。业务场景描述:
每日增量6TB日志数据,高峰时段写入及查询频率都较高,集群压力较大,查询ES时,常出现查询缓慢问题。
- ES集群的索引写入及查询速度主要依赖于磁盘的IO速度,冷热数据分离的关键为使用SSD磁盘存储热数据,提升查询效率。
- 若全部使用SSD,成本过高,且存放冷数据较为浪费,因而使用普通SATA磁盘与SSD磁盘混搭,可做到资源充分利用,性能大幅提升的目标。
实现原理
借助 Elasticsearch的分片分配策略,确切的说是:
- 第一:集群节点层面支持规划节点类型,这是划分热暖节点的前提。
具体方式是在elasticsearch.yml文件中增加以下配置:
node.attr.{attribute}: {value}
其中attribute为用户自定义的任意标签名,value为该节点对应的该标签的值,例如对于冷热分离,可以使用如下设置
node.attr.temperature: hot //热节点
node.attr.temperature: cold //冷节点
- 第二:索引层面支持将数据路由到给定节点,这为数据写入冷、热节点做了保障。
具体方式是在创建模板或索引时指定属性:
index.routing.allocation.include.{attribute} //表示索引可以分配在包含多个值中其中一个的节点上。
index.routing.allocation.require.{attribute} //表示索引要分配在包含索引指定值的节点上(通常一般设置一个值)。
index.routing.allocation.exclude.{attribute} //表示索引只能分配在不包含所有指定值的节点上。
实现方案
1.1 集群设计:
| 节点名称 | 服务器类型 | 存储数据 |
| es-master1 | 4C 16G 1T SATA | 元数据 |
| es-master2 | ||
| es-master3 | ||
| es-hot1 | 16C 64G 1T SSD | Hot |
| es-hot2 | ||
| es-hot3 | ||
| es-cold1 | 8C 32G 5T SATA | Cold |
| es-cold2 |
2.1 配置Master节点
Master1节点配置(其他节点配置类似)
[root@es-master1 ~]# cd /etc/elasticsearch/
[root@es-master1 elasticsearch]# vim elasticsearch.yml
cluster.name: linuxplus
node.name: es-master1.linuxplus.com
node.attr.rack: r6
node.master: true
node.data: false
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
discovery.zen.ping.unicast.hosts: ["es-master1.linuxplus.com:9300","es-master2.linuxplus.com:9300","es-master3.linuxplus.com:9300","es-hot1.linuxplus.com:9300","es-hot2.linuxplus.com:9300","es-hot3.linuxplus.com:9300","es-stale1.linuxplus.com:9300","es-stale2.linuxplus.com:9300"]
discovery.zen.minimum_master_nodes:
bootstrap.system_call_filter: false
2.2 配置Hot节点
Hot1节点配置(其他节点配置类似)
[root@es-hot1 elasticsearch]# vim elasticsearch.yml
cluster.name: linuxplus
node.name: es-hot1.linuxplus.com # 提示:自行修改其他节点的名称
node.attr.rack: r1
node.master: false
node.data: true
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 10.10.10.24 # 提示:自行修改其他节点的IP
discovery.zen.ping.unicast.hosts: ["es-master1.linuxplus.com:9300","es-master2.linuxplus.com:9300","es-master3.linuxplus.com:9300"]
discovery.zen.minimum_master_nodes:
bootstrap.system_call_filter: false
node.attr.hotwarm_type: hot # 标识为热数据节点
[root@es-hot1 elasticsearch]# /etc/init.d/elasticsearch start
2.3 配置Cold节点
Cold1节点配置(其他节点配置类似)
[root@es-stale1 elasticsearch]# vim elasticsearch.yml
cluster.name: linuxplus
node.name: es-stale1.linuxplus.com # 提示:自行修改其他节点的名称
node.attr.rack: r1
node.master: false
node.data: true
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 10.10.10.27 # 提示:自行修改其他节点的IP
discovery.zen.ping.unicast.hosts: ["es-master1.linuxplus.com:9300","es-master2.linuxplus.com:9300","es-master3.linuxplus.com:9300"]
discovery.zen.minimum_master_nodes:
bootstrap.system_call_filter: false
node.attr.hotwarm_type: cold # 标识为冷数据节点
[root@es-stale1 elasticsearch]# /etc/init.d/elasticsearch start
3.1 数据写入
- 方案一:通过模板指定冷热数据节点
PUT _template/order_template
{
"index_patterns": "order_*",
"settings": {
"index.routing.allocation.require.hotwarm_type": "hot", # 指定默认为热数据节点
"index.number_of_replicas": "0"
}
}
注:以【order_】开头索引命名的,都将其数据放到hot节点上
- 方案二:通过索引指定冷热数据节点
PUT /order_2019-
{
"settings": {
"index.routing.allocation.require.hotwarm_type": "hot", # 指定为热数据节点
"number_of_replicas":
}
}
- 热节点效果图:分别创建2个索引,包含3个分片1个副本

4.1 数据迁移至冷节点
- 方案一:手工修改索引路由为:cold
ES看到有新的标记就会将这个索引自动迁移到冷数据节点中
#在kibana里操作: PUT /order_stpprdinf_2019-/_settings
{
"settings": {
"index.routing.allocation.require.hotwarm_type": "cold" # 指定数据存放到冷数据节点
}
}
- 方案二:通过shell脚本定期迁移数据
#!/bin/bash hot数据(保留7天)迁移到cold
Time=$(date -d "1 week ago" +"%Y.%m.%d")
Hostname=$(hostname)
arr=("order_stpprdinf" "order_stppayinf")
for var in ${arr[@]}
do
curl -H "Content-Type: application/json" -XPUT http://$Hostname:9200/$var_$Time/_settings?pretty -d'
{
"settings": {
"index.routing.allocation.require.hotwarm_type": "cold" # 指定数据存放到冷数据节点
}
}'
done
- 方案三:通过curator定期迁移数据
步骤1:创建config.yml,填写Elasticsearch集群配置信息。
# Rmember, leave a key empty if there is no value. None will be a string,
# not a Python "NoneType"
client:
hosts: ["10.0.101.100", "10.0.101.101", "10.0.101.102"]
port:
url_prefix:
use_ssl: False
certificate:
client_cert:
client_key:
ssl_no_validate: False
http_auth:
timeout:
master_only: False logging:
loglevel: INFO
logfile: /opt/elasticsearch-curator/logs/run.log
logformat: default
blacklist: ['elasticsearch', 'urllib3']
步骤2:创建action.yml
# Remember, leave a key empty if there is no value. None will be a string,
# not a Python "NoneType"
#
# Also remember that all examples have 'disable_action' set to True. If you
# want to use this action as a template, be sure to set this to False after
# copying it.
actions:
:
action: allocation # 这里执行操作类型为删除索引
description: >-
Apply shard allocation routing to 'require' 'tag=cold' for hot/cold node
setup for logstash- indices older than days, based on index_creation date.
options:
key: hotwarm_type # 这是es节点中定义的属性
value: cold # 这是要更新的值,变为冷节点
allocation_type: require # 这里alloction的类型
disable_action: false
filters:
- filtertype: pattern
kind: prefix # 这里是指匹配前缀为 “order_” 的索引,还可以支持正则匹配等,详见官方文档
value: order_
- filtertype: age # 这里匹配时间
source: name # 这里根据索引name来匹配,还可以根据字段等,详见官方文档
direction: older
timestring: "%Y-%m" # 用于匹配和提取索引或快照名称中的时间戳
unit: months # 这里定义的是months,还有days,weeks等,总时间为unit * unit_count
unit_count:
步骤3:运行curator
单次运行:
cd /opt/elasticsearch-curator
curator --config config.yml action.yml
cron定时任务运行:
crontab -e
#添加如下配置,每天0时运行一次
0 0 */1 * * curator --config /opt/elasticsearch-curator/config.yml /opt/elasticsearch-curator/action.yml

- 迁移冷节点效果图:

应用
因为按时间分了多个索引,查询的时候可以跨多个索引进行查询,打分、排序、分页和搜单个索引没什么区别。
/**
* 查询.
*
* @param indexName 索引名稱
* @param type 索引類型
* @param conditionMap 查询条件Map
* @param orderByMap 排序Map
* @param page 分页page
* @return 查询结果
*/
@Override
public List<Map<String, Object>> query(final String[] indexName, final String type,
final Map<String, Object> conditionMap, final Map<String, String> orderByMap,
final Page page) {
logger.info("查询elasticSearch数据......");
logger.info("indexName={}", Arrays.toString(indexName));
logger.info("conditionMap={}", conditionMap.toString());
logger.info("orderByMap={}", orderByMap.toString()); final long currentTimeMillis = System.currentTimeMillis();
RestHighLevelClient client = null;
List<Map<String, Object>> resultList = new ArrayList<>();
try {
// 1、创建连接
client = createConnect(); // 2、创建search请求
SearchRequest searchRequest = new SearchRequest(indexName);
searchRequest.types(type); 这里省略几百行代码................ }
参考:
铭毅天下:干货 | Elasticsearch 冷热集群架构实战
https://blog.51cto.com/stuart/2335120
https://cloud.tencent.com/developer/article/1544261
https://elasticsearch.cn/article/6127#tip3
ElasticSearch——冷热(hot&warm)架构部署的更多相关文章
- ElasticSearch实战系列十: ElasticSearch冷热分离架构
前言 本文主要介绍ElasticSearch冷热分离架构以及实现. 冷热分离架构介绍 冷热分离是目前ES非常火的一个架构,它充分的利用的集群机器的优劣来实现资源的调度分配.ES集群的索引写入及查询速度 ...
- EFK教程(3) - ElasticSearch冷热数据分离
基于ElasticSearch多实例架构,实现资源合理分配.冷热数据分离 作者:"发颠的小狼",欢迎转载与投稿 目录 ▪ 用途 ▪ 架构 ▪ 192.168.1.51 elasti ...
- Elasticsearch的几种架构(ELK,EL,EF)性能对比测试报告
Elasticsearch的几种架构性能对比测试报告 1.前言 选定了Elasticsearch作为存储的数据库,但是还需要对Elasticsearch的基础架构做一定测试,所以,将研究测试报告输出如 ...
- PB级数据实时查询,滴滴Elasticsearch多集群架构实践
PB级数据实时查询,滴滴Elasticsearch多集群架构实践 mp.weixin.qq.com 点击上方"IT牧场",选择"设为星标"技术干货每日送达 点 ...
- Rafy 领域实体框架演示(3) - 快速使用 C/S 架构部署
本系列演示如何使用 Rafy 领域实体框架快速转换一个传统的三层应用程序,并展示转换完成后,Rafy 带来的新功能. <福利到!Rafy(原OEA)领域实体框架 2.22.2067 发布!> ...
- 【金】nginx+uwsgi+django+python 应用架构部署
网上有很多这种配置,但就是没一个靠普的,费了好大的力气才完成架构部署.顺便记录一下. 一.部署前的说明 先安装好 python,django,uwsgi,nginx软件后.后配置运行的软件是分先后的. ...
- LNMP架构部署
第1章 部署LNMP架构步骤 1.1 ①部署Linux系统(OK) 基本优化完成(ip地址设置 yum源更新 字符集设置) 安全优化完成(iptables关闭 selinux关闭 /tmp/ 1777 ...
- 首发福利!全球第一开源ERP Odoo系统架构部署指南 电子书分享
引言 Odoo,以前叫OpenERP,是比利时Odoo S.A.公司开发的一个企业应用软件套件,开源套件包括一个企业应用快速开发平台,以及几千个Odoo及第三方开发的企业应用模块.Odoo适用于各种规 ...
- [待完善]mycat分布式架构部署
mycat介绍:http://mycat.org.cn/ mycat分布式架构部署
随机推荐
- subline html5的快捷键
选择类 Ctrl+D 选中光标所占的文本,继续操作则会选中下一个相同的文本. Alt+F3 选中文本按下快捷键,即可一次性选择全部的相同文本进行同时编辑.举个栗子:快速选中并更改所有相同的变量名.函数 ...
- 【轉】mantis安裝
一.mantis简介 可以看出,mantis是一个基于php技术的,个人觉得这个系统还是很完善的. 安装mantis,需要安装一下软件: phpMyAdmin 下载地址https://w ...
- 实现strStr()函数
方法一:暴力解法 int strStr(string haystack, string needle) { if (needle.empty()) ; int M = haystack.size(); ...
- Postgresql 解决锁表
转载地址:https://blog.csdn.net/cicon/article/details/68068462##一.postgresql解决锁表--查询是否锁表了select oid from ...
- 2-set奶牛议会
Description 由于对Farmer John的领导感到极其不悦,奶牛们退出了农场,组建了奶牛议会.议会以“每头牛 都可以获得自己想要的”为原则,建立了下面的投票系统: M只到场的奶牛 (1 & ...
- luogu P2345 奶牛集会
二次联通门 : luogu P2345 奶牛集会 /* luogu P2345 奶牛集会 权值线段树 以坐标为下标, 坐标为值建立线段树 对奶牛按听力由小到大排序 对于要查的牛 每次第i次放入奶牛起作 ...
- shiro 配置注解后无权访问不进行页面跳转异常:org.apache.shiro.authz.UnauthorizedException: Subject does not have permission
该问题需要使用异常管理: <!-- 无权访问跳转的页面 --> <bean class="org.springframework.web.servlet.handler.S ...
- Scrapy不同的item指定不同的Pipeline
scrapy不同的item指定不同的Pipeline from items import AspiderItem, BspiderItem, CspiderItem class myspiderPip ...
- ICEM棱柱网格生成方向【转载】
转载自:http://blog.sina.com.cn/s/blog_8add9da60102v2hv.html 利用ICEM生成边界层网格(棱柱网格)时,发现生成的棱柱网格的方向不在流体域一侧,跑到 ...
- 2018-2019-2 网络对抗技术 20165202 Exp8 Web基础
博客目录 一.实践内容 Web前端HTML 能正常安装.启停Apache.理解HTML,理解表单,理解GET与POST方法,编写一个含有表单的HTML Web前端javascipt 理解JavaScr ...