python搞搞大数据之hbase——初探
使用python链接mysql读入一个表并把它再写到hbase 里去(九头蛇万岁)
先声明一下需要用的库:
俩!!:
happybase (写这个的老哥真的happy)
pymysql
建议使用anaconda进行相应版本匹配安装,在装happybase的时候,conda默认的channel是找不到这个库的你需要使用 conda-forge 镜像参考如下网站:
https://anaconda.org/conda-forge/happybase
pymysql就不用说了,毕竟mysql业界广泛使用,这个平台都好找
安装好了之后打开你的pycharm把基本purepython项目创建好,解释器指定到anaconda3下面的python.exe上面
然后开始玩耍:
Step1:
请打算开你的大数据环境启动hadoop、zookeeper、hbase(简直后台内存爆掉)
Step2:
开始编写自己的脚本,建议表级别操作和数据级别操作分别写脚本,这样会好控制一些。
这里我简单写了四个脚本
test.py,mysql.py,delete.py,scan.py
(test开始没规划,实际就是创表脚本)
test.py
1 #!/usr/bin/python
2 # coding:utf-8
3 import happybase
4
5 connection = happybase.Connection('localhost', 9090)
6
7 connection.create_table(
8 'short',
9 {
10 'base':dict(),
11 'region':dict(),
12 'infos':dict()
13 }
14 )
这里面很简单的操作,你要用hbase,你就要链接它,happybase.Connection(主机名, 端口号)参数就这么简单,对应好就ok
这里创建表的方法写法和hbase的操作感觉相当的像,hbase的table用起来确实就像是字典嵌套字典,太过于真实
这里我的表名为short,表有三个列族base、region、infos,这个是根据数据自己设计出来的。数据是个csv:如下,请先存为csv文件,导入你的mysql做准备(如果你要实验这个例子)
customer_id,first_name,last_name,email,gender,address,country,language,job,credit_type,credit_no
1,Spencer,Raffeorty,sraffeorty0@dropbox.com,Male,9274 Lyons Court,China,Khmer,Safety Technician III,jcb,3589373385487669
2,Cherye,Poynor,cpoynor1@51.la,Female,1377 Anzinger Avenue,China,Czech,Research Nurse,instapayment,6376594861844533
3,Natasha,Abendroth,nabendroth2@scribd.com,Female,2913 Evergreen Lane,China,Yiddish,Budget/Accounting Analyst IV,visa,4041591905616356
4,Huntley,Seally,hseally3@prlog.org,Male,694 Del Sol Lane,China,Albanian,Environmental Specialist,laser,677118310740263477
5,Druci,Coad,dcoad4@weibo.com,Female,16 Debs Way,China,Hebrew,Teacher,jcb,3537287259845047
6,Sayer,Brizell,sbrizell5@opensource.org,Male,71 Banding Terrace,China,Maltese,Accountant IV,americanexpress,379709885387687
7,Becca,Brawley,bbrawley6@sitemeter.com,Female,7 Doe Crossing Junction,China,Czech,Payment Adjustment Coordinator,jcb,3545377719922245
8,Michele,Bastable,mbastable7@sun.com,Female,98 Clyde Gallagher Pass,China,Malayalam,Tax Accountant,jcb,3588131787131504
9,Marla,Brotherhood,mbrotherhood8@illinois.edu,Female,4538 Fair Oaks Trail,China,Dari,Design Engineer,china-unionpay,5602233845197745479
10,Lionello,Gogarty,lgogarty9@histats.com,Male,800 Sage Alley,China,Danish,Clinical Specialist,diners-club-carte-blanche,30290846607043
11,Camile,Ringer,cringera@army.mil,Female,5060 Fairfield Alley,China,Punjabi,Junior Executive,china-unionpay,5602213490649878
12,Gillan,Banbridge,gbanbridgeb@wikipedia.org,Female,91030 Havey Point,China,Kurdish,Chemical Engineer,jcb,3555948058752802
13,Guinna,Damsell,gdamsellc@spiegel.de,Female,869 Ohio Park,China,Fijian,Analyst Programmer,jcb,3532009465228502
14,Octavia,McDugal,omcdugald@rambler.ru,Female,413 Forster Center,China,English,Desktop Support Technician,maestro,502017593120304035
15,Anjanette,Penk,apenke@lulu.com,Female,8154 Schiller Road,China,Swedish,VP Sales,jcb,3548039055836788
16,Maura,Teesdale,mteesdalef@globo.com,Female,9568 Quincy Alley,China,Dutch,Dental Hygienist,jcb,3582894252458217
导入mysql之后:
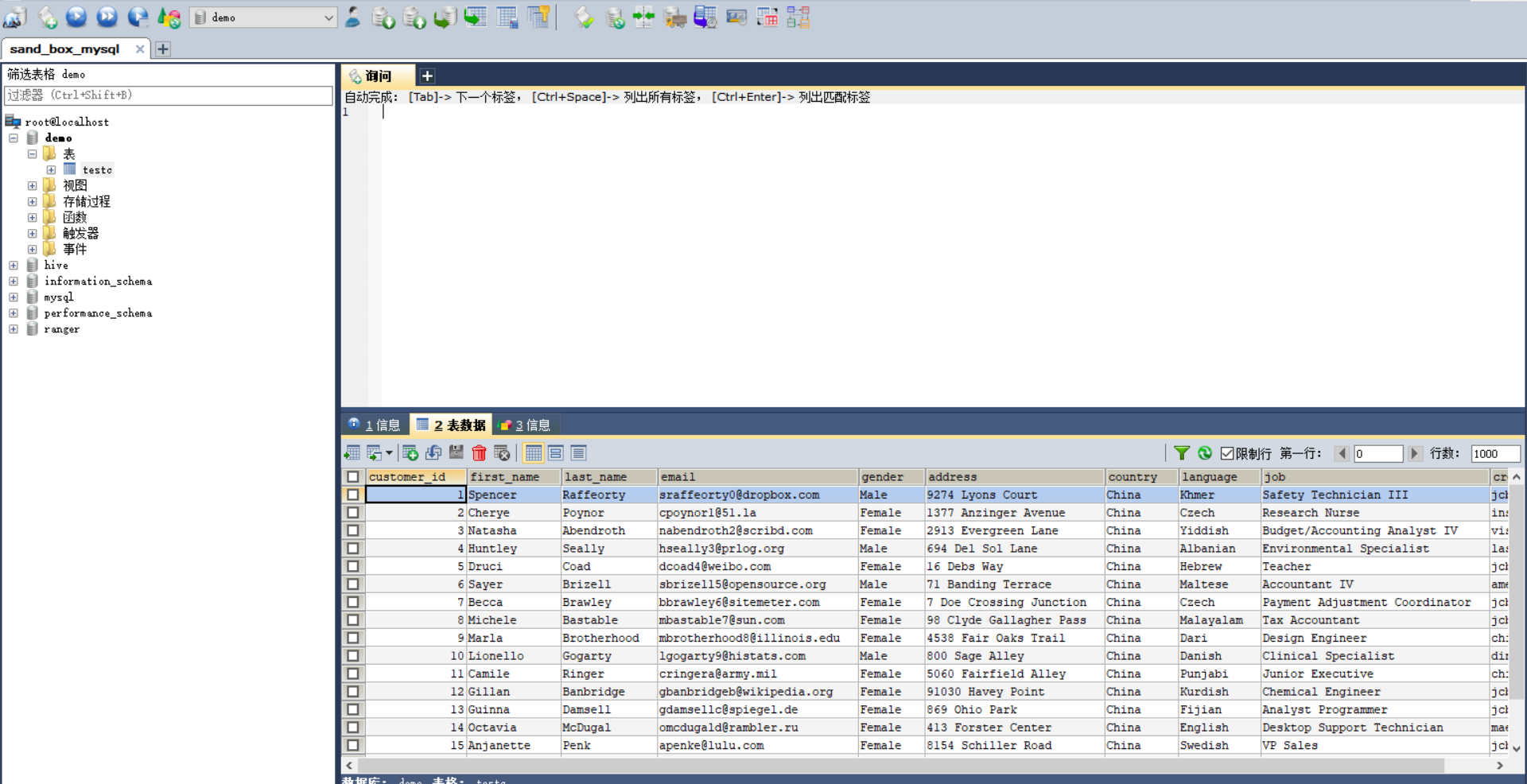
我是将它导在了数据库demo下面。
接下来,你就可以去玩蛇了
是不是感觉顺序混乱???混乱就对了
现在要干的事情是链接数据库读取数据,再将其插入到hbase中,mysql查表select,hbase插入put,知识点咚咚咚
mysql.py
#!/usr/bin/python
# coding:utf-8
import pymysql
import happybase class testc:
def __init__(self, customer_id, first_name, last_name, email, gender, address, country, language, job, credit_type,
credit_no):
self._key = customer_id
self._first_name = first_name
self._last_name = last_name
self._email = email
self._gender = gender
self._address = address
self._country = country
self._language = language
self._job = job
self._credit_type = credit_type
self._credit_no = credit_no def get(self):
return list((self._key, self._first_name, self._last_name,
self._email, self._gender, self._address,
self._country, self._language, self._job,
self._credit_type, self._credit_no)
) def __str__(self):
return '%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s' % (self._key,
self._first_name,
self._last_name,
self._email,
self._gender,
self._address,
self._country,
self._language,
self._job,
self._credit_type,
self._credit_no
) connection = happybase.Connection('localhost', 9090) db = pymysql.connect(host='127.0.0.1', port=3307, user='root', password='hadoop', database='demo')
cursor = db.cursor() sql = 'select * from testc'
cursor.execute(sql)
data = cursor.fetchall()
data = list(data)
datalist = []
for i in range(0, len(data)):
datalist.append(testc(data[i][0], data[i][1], data[i][2],
data[i][3], data[i][4], data[i][5],
data[i][6], data[i][7], data[i][8],
data[i][9], data[i][10]
))
print(datalist[i])
# 到这里mysql中的表数据已经被读取并存储与datalist中,接下来将它转存在hbase中去
table = connection.table('short')
for data_ in datalist:
row = data_.get()
table.put(
bytes('{}'.format(row[0]),encoding='ascii'),
{
b'base:first_name': bytes('{}'.format(row[1]), encoding='ascii'),
b'base:last_name': bytes('{}'.format(row[2]), encoding='ascii'),
b'base:email': bytes('{}'.format(row[3]), encoding='ascii'),
b'base:gender': bytes('{}'.format(row[4]), encoding='ascii'),
b'region:address': bytes('{}'.format(row[5]), encoding='ascii'),
b'region:country': bytes('{}'.format(row[6]), encoding='ascii'),
b'infos:language': bytes('{}'.format(row[7]), encoding='ascii'),
b'infos:job': bytes('{}'.format(row[8]), encoding='ascii'),
b'infos:credit_type': bytes('{}'.format(row[9]), encoding='ascii'),
b'infos:credit_no': bytes('{}'.format(row[10]), encoding='ascii')
}
) db.close()
大概流程思路是查出来的数据用特定格式做好,然后再写入,这里我做了个类(本质上没有必要),读者在实验的时候可以考录直接使用一个list去接收
连接mysql就需要你使用pymysql库
db = pymysql.connect(host='127.0.0.1', port=3307, user='root', password='hadoop', database='demo')
其中的参数怕是意思很清楚了,这里不进行过多赘述。
这里有个叫做游标对象的东西 cursor = db.cursor() 可以认为他是个代理,使用它来执行sql语句并展示。
cursor有三个方法,fetchall、fetchone、fetchmany。嚼一嚼英语就知道意思是取全部、一行和多行,多行自然你要设定参数
找合适的容器接收你得到的数据,把数据按一定规格处理好之后,准备导入到hvase中。末尾的for循环就是导入代码,这里全部使用了bytes()是因为hbase只支持二进制,所以转换为了ascii码编码,否则你会在接下来的scan中看到不想要的utf-8字符。
导好了之后,我们使用scan来看一下,hbase中scan是用来看全表的,那么这里table对象就会同样有这个方法,人家老哥很厉害啊。
scan.py
#!/usr/bin/python
# coding:utf-8 import happybase connection = happybase.Connection('localhost', 9090)
table = connection.table('short') for key, data in table.scan():
print(str(key),data)
这个篇幅很小,因为表级操作。

这里是我查到的结果
这个小小的实验基本就完成了,中间遇到坑的时候可能会重复删表和建表,这里再提供一个
delete.py
#!/usr/bin/python
# coding:utf-8
import happybase connection = happybase.Connection('localhost', 9090)
connection.disable_table('short')
connection.delete_table('short')
嗯好的,我只能帮你到这了,还要去学习哦,如果大佬有更好的数据导入是字符编码的处理方式,跪求告知,知识就是力量!谢过大佬。
hail hydra
python搞搞大数据之hbase——初探的更多相关文章
- Python/Numpy大数据编程经验
Python/Numpy大数据编程经验 1.边处理边保存数据,不要处理完了一次性保存.不然程序跑了几小时甚至几天后挂了,就啥也没有了.即使部分结果不能实用,也可以分析程序流程的问题或者数据的特点. ...
- 大数据之HBase
大数据之HBase数据插入优化之多线程并行插入实测案例 一.引言: 上篇文章提起关于HBase插入性能优化设计到的五个参数,从参数配置的角度给大家提供了一个性能测试环境的实验代码.根据网友的反馈,基于 ...
- 黑马基础阶段测试题:创建一个存储字符串的集合list,向list中添加以下字符串:”C++”、”Java”、” Python”、”大数据与云计算”。遍历集合,将长度小于5的字符串从集合中删除,删除成功后,打印集合中的所有元素
package com.swift; import java.util.ArrayList; import java.util.List; import java.util.ListIterator; ...
- 【Python开发】Python 适合大数据量的处理吗?
Python 适合大数据量的处理吗? python 能处理数据库中百万行级的数据吗? 处理大规模数据时有那些常用的python库,他们有什么优缺点?适用范围如何? 需要澄清两点之后才可以比较全面的看这 ...
- 大数据开发--Hbase协处理器案例
大数据开发--Hbase协处理器案例 1. 需求描述 在社交网站,社交APP上会存储有大量的用户数据以及用户之间的关系数据,比如A用户的好友列表会展示出他所有的好友,现有一张Hbase表,存储就是当前 ...
- 大数据查询——HBase读写设计与实践
导语:本文介绍的项目主要解决 check 和 opinion2 张历史数据表(历史数据是指当业务发生过程中的完整中间流程和结果数据)的在线查询.原实现基于 Oracle 提供存储查询服务,随着数据量的 ...
- 为什么说Python 是大数据全栈式开发语言
欢迎大家访问我的个人网站<刘江的博客和教程>:www.liujiangblog.com 主要分享Python 及Django教程以及相关的博客 交流QQ群:453131687 原文链接 h ...
- 【大数据】Hbase如何批量删除指定数据
一.起因: Hbase是一个列式存储,nosql类型的数据库,类似mongodb. 目前似乎没有提供批量删除的方法,只有一个单行删除的命令:deleteall 'tablename', rowkey ...
- 大数据学习——Hbase
1. Hbase基础 1.1 hbase数据库介绍 1.简介 hbase是bigtable的开源java版本.是建立在hdfs之上,提供高可靠性.高性能.列存储.可伸缩.实时读写nosql的数据库系统 ...
随机推荐
- 定时器TIM,pwm
一.定时器 1. 定义 设置等待时间,到达后则执行指定操作的硬件. 2. STM32F407的定时器有以下特征 具有基本的定时功能,也有PWM输出(灯光控制.电机的转速).脉冲捕获功能( ...
- 51nod 1412
考虑到只与深度和点的个数有关$f[n][d]$ 表示 $n$ 个点,深度为 $d$ 的 $AVL$ 树有多少种 枚举左子树大小为 $i$, 进行转移并且深度为 $logn$ 级别 $f[n][d] = ...
- Codevs 1768 种树 3(差分约束)
1768 种树 3 时间限制: 2 s 空间限制: 256000 KB 题目等级 : 钻石 Diamond 题目描述 Description 为了绿化乡村,H村积极响应号召,开始种树了. H村里有n幢 ...
- _cdecl与_stdcall区别
_cdecl与_stdcall是最常用的的两种函数调用修饰,区别在于函数返回时,清理栈(恢复栈平衡)是caller做还是被调函数做. : _cdecl int add1(int a, int b) : ...
- 畅通工程续(HDU 1874)(简单最短路)
某省自从实行了很多年的畅通工程计划后,终于修建了很多路.不过路多了也不好,每次要从一个城镇到另一个城镇时,都有许多种道路方案可以选择,而某些方案要比另一些方案行走的距离要短很多.这让行人很困扰. 现在 ...
- scrapy框架之Pipeline管道类
Item Pipeline简介 Item管道的主要责任是负责处理有蜘蛛从网页中抽取的Item,他的主要任务是清洗.验证和存储数据.当页面被蜘蛛解析后,将被发送到Item管道,并经过几个特定的次序处理数 ...
- AcWing:244. 谜一样的牛(树状数组 + 二分)
有n头奶牛,已知它们的身高为 1~n 且各不相同,但不知道每头奶牛的具体身高. 现在这n头奶牛站成一列,已知第i头牛前面有AiAi头牛比它低,求每头奶牛的身高. 输入格式 第1行:输入整数n. 第2. ...
- GEOS库的编译
下载地址https://trac.osgeo.org/geos/ 选择最新的geos-3.6.2版本,下载 将geos-3.6.2放在VS2012文件夹下,本例是D:\VS2012 打开VS2012开 ...
- JAVA基础知识|抽象类与接口类
一.抽象类 抽象类:拥有抽象方法的类就是抽象类,抽象类要使用abstract声明 抽象方法:没有方法体的方法,必须要使用abstract修饰 为什么要使用抽象类,抽象方法? 举例来说,如果你定义了一个 ...
- OpenCL使用CL_MEM_USE_HOST_PTR存储器对象属性与存储器映射
随着OpenCL的普及,现在有越来越多的移动设备以及平板.超级本等都支持OpenCL异构计算.而这些设备与桌面计算机.服务器相比而言性能不是占主要因素的,反而能耗更受人关注.因此,这些移动设备上的GP ...