centos7安装Scala、Spark(伪分布式)
centos7安装spark(伪分布式)
spark是由scala语言开发的,首先需要安装scala.
Scala安装
下载scala-2.11.8,(与spark版本要对应)
命令:wget https://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgz
解压到文件夹并配置环境变量
vim /etc/profile
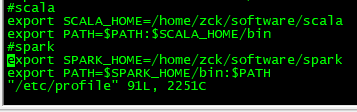
#scala
export SCALA_HOME=/home/zck/software/scala
export PATH=$PATH:$SCALA_HOME/bin
使配置文件生效

测试:scala -version

配置伪分布式spark;
解压到文件夹并配置环境变量
vim /etc/profile
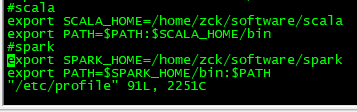
末尾添加以下内容
#spark
export SPARK_HOME=/home/zck/software/spark
export PATH=$SPARK_HOME/bin:$PATH测试
修改配置文件spark/conf/spark-env.sh
加入内容
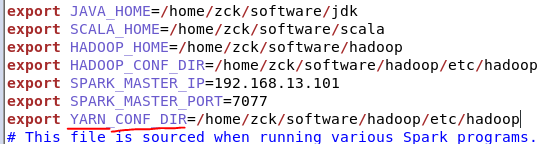
export JAVA_HOME=/home/zck/software/jdk
export SCALA_HOME=/home/zck/software/scala
export HADOOP_HOME=/home/zck/software/hadoop
export HADOOP_CONF_DIR=/home/zck/software/hadoop/etc/hadoop
export SPARK_MASTER_IP=192.168.13.101
export SPARK_MASTER_PORT=7077
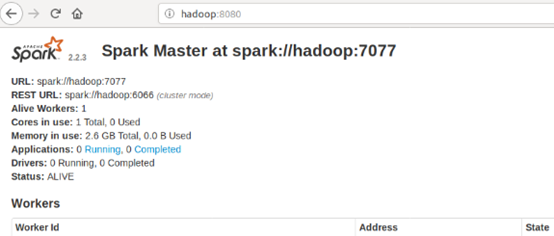
启动spark服务
进入spark文件夹,sbin/start-all.sh

然后再去浏览器看看
Spark yarn模式配置
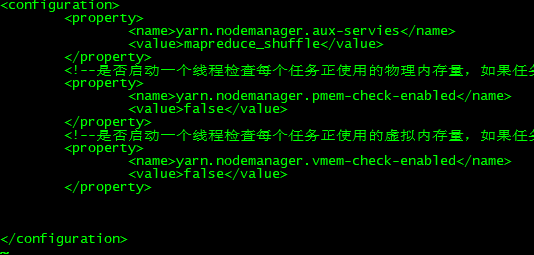
1、修改hadoop配置文件yarn-site.xml,添加如下内容:
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
2、修改spark-env.sh,添加如下配置:
export YARN_CONF_DIR=/opt/module/hadoop-2.7.2/etc/hadoop
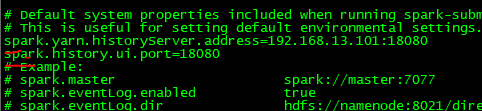
3、日志配置
修改配置文件spark-defaults.conf
添加如下内容:
spark.yarn.historyServer.address=hadoop102:18080
spark.history.ui.port=18080
4、重启spark历史服务
sbin/stop-history-server.sh
sbin/start-history-server.sh

Spark几种模式对比
|
模式 |
Spark安装机器数 |
需启动的进程 |
所属者 |
|
Local |
1 |
无 |
Spark |
|
Standalone |
3 |
Master及Worker |
Spark |
|
Yarn |
1 |
Yarn及HDFS |
Hadoop |
centos7安装Scala、Spark(伪分布式)的更多相关文章
- ZooKeeper:win7上安装单机及伪分布式安装
zookeeper是一个为分布式应用所设计的分布式的.开源的调度服务,它主要用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用,协调及其管理的难度,提高性能的分布式服务. 本章的目的:如何 ...
- Hadoop的HDFS和MapReduce的安装(三台伪分布式集群)
一.创建虚拟机 1.从网上下载一个Centos6.X的镜像(http://vault.centos.org/) 2.安装一台虚拟机配置如下:cpu1个.内存1G.磁盘分配20G(看个人配置和需求,本人 ...
- 大数据:Hadoop(JDK安装、HDFS伪分布式环境搭建、HDFS 的shell操作)
所有的内容都来源与 Hadoop 官方文档 一.Hadoop 伪分布式安装步骤 1)JDK安装 解压:tar -zxvf jdk-7u79-linux-x64.tar.gz -C ~/app 添加到系 ...
- Hadoop安装教程_伪分布式
文章更新于:2020-04-09 注1:hadoop 的安装及单机配置参见:Hadoop安装教程_单机(含Java.ssh安装配置) 注2:hadoop 的完全分布式配置参见:Hadoop安装教程_分 ...
- Mac环境下安装配置Hadoop伪分布式
伪分布式需要修改5个配置文件(hadoop2.x的配置文件$HADOOP_HOME/etc/hadoop) 第一个:hadoop-env.sh #vim hadoop-env.sh #第25行,由于新 ...
- 第5章 选举模式和ZooKeeper的集群安装 5-2 单机伪分布式安装zookeeper集群
先搭建伪分布式集群,再去搭建真分布式集群.有些的人的电脑内存.性能比较低,所以在搭建真实的一个分布式环境的话,可能会相对来说比较卡,所以两种都会做一下,首先会在单机上搭建一个集群.单机上的集群主要就是 ...
- Spark学习之路 (五)Spark伪分布式安装
一.JDK的安装 JDK使用root用户安装 1.1 上传安装包并解压 [root@hadoop1 soft]# tar -zxvf jdk-8u73-linux-x64.tar.gz -C /usr ...
- Spark学习之路 (五)Spark伪分布式安装[转]
JDK的安装 JDK使用root用户安装 上传安装包并解压 [root@hadoop1 soft]# tar -zxvf jdk-8u73-linux-x64.tar.gz -C /usr/local ...
- spark伪分布式安装
一,在官网下载对应的版本http://spark.apache.org/downloads.html 二在linux中解压下来的spark包 三:配置环境变量 (1)在/etc/profi ...
随机推荐
- DX12 开debuggerlayer
https://social.technet.microsoft.com/Forums/azure/en-US/ef10f8eb-fee0-4cde-bb01-52d1db2ea347/win10-1 ...
- 牛客国庆集训派对Day6 && CCPC-WannaFly-Camp #1 F. kingdom(DP)
题目链接:https://www.nowcoder.com/acm/contest/206/F 题意:一棵 n 个点的树,根为 1,重儿子到父亲的费用为 0,其余为 1,问所有点到 1 的最大总费用是 ...
- Codeforces Round #346 (Div. 2) A题 [一道让我生气的思维题·]
A. Round House Vasya lives in a round building, whose entrances are numbered sequentially by integer ...
- 【java设计模式】-06原型模式
原型模式简述 定义: 使用原型实例指定待创建对象的类型,并且通过复制这个原型来创建新的对象 ,也就是通过复制现有对象实例产生新的对象,也就是所谓的"克隆" 实现方式: 1.实现Cl ...
- python操作s3 -- boto2.x
以下是python操作s3常用方法: boto s3手册:http://boto.readthedocs.org/en/latest/ref/s3.html boto s3快速入门:http://bo ...
- echart itemStyle属性设置
itemStyle // itemStyle 设置饼状图扇形区域样式 itemStyle: { // emphasis:英文意思是 强调;着重; ...
- Centos7卸载nginx及php、php-fpm方法
Centos7卸载nginx及php.php-fpm方法 2016年12月01日 18:17:22 阅读数:20824 本文环境:Centos7.yum方式安装的nginx和php.php-fpm 之 ...
- PHP遍历目录下的文件夹和文件 以及遍历文件下内容
1.遍历目录下的文件夹和文件: public function bianli1($dir) { $files = array(); if($head = opendir($dir)) { while( ...
- [java]取当前平台默认字符集,取字符串长度
public class TimestampLength { public static void main(String[] args) { System.out.println(java.nio. ...
- ZT:在mybatis的Mapping文件写入表名 出现异常ORA-00903: 表名无效 的解决
简而言之,把#{tablename}换成${tablename}就能解决问题. 版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:htt ...