Pandas与Matplotlib结合进行可视化
前面所介绍的都是以表格的形式中展现数据, 下面将介绍Pandas与Matplotlib配合绘制出折线图, 散点图, 饼图, 柱形图, 直方图等五大基本图形.
Matplotlib是python中的一个2D图形库, 它能以各种硬拷贝的格式和跨平台的交互式环境生成高质量的图形, 比如说柱状图, 功率谱, 条形图, 误差图, 散点图等. 其中, matplotlib.pyplot 提供了一个类似matlab的绘图框架, 使用该框架前, 必须先导入它.
19. 折线图
折线图: 数据随着时间的变化情况描点连线而形成的图形, 通常被用于显示在相等时间间隔下数据的趋势. 下面将采用两种方式进行绘制折线图, 一种是pandas中plot()方法, 该方法用来绘制图形, 然后在matplotlib中的绘图框架中展示; 另一种则是直接利用matplotlib中绘图框架的plot()方法.
19.1 采用pandas中的plot()方法绘制折线图
在pandas中绘制折线图的函数是plot(x=None, y=None, kind='line', figsize = None, legend=True, style=None, color = "b", alpha = None):
第一个: x轴的数据
第二个: y轴的数据
第三个: kind表示图形种类, 默认为折线图
第四个: figsize表示图像大小的元组
第五个: legend=True表示使用图例, 否则不使用, 默认为True.
第六个: style表示线条样式
第七个: color表示线条颜色, 默认为蓝色
第八个: alpha表示透明度, 介于0~1之间.
plot()函数更多参数请查看官方文档:http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.plot.html?highlight=plot#pandas.DataFrame.plot
数据来源: https://assets.datacamp.com/production/course_1639/datasets/percent-bachelors-degrees-women-usa.csv

1 import pandas as pd
2 import matplotlib.pyplot as plt
3 #第一步读取数据: 使用read_csv()函数读取csv文件中的数据
4 df = pd.read_csv(r"D:\Data\percent-bachelors-degrees-women-usa.csv")
5 #第二步利用pandas的plot方法绘制折线图
6 df.plot(x = "Year", y = "Agriculture")
7 #第三步: 通过plt的show()方法展示所绘制图形
8 plt.show()
在执行上述代码过程了报错ImportError: matplotlib is required for plotting, 若遇到请点击参考办法
最终显示效果:

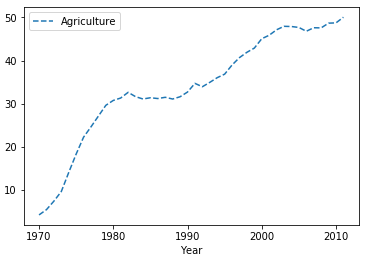
如果想将实线变为虚线呢, 可修改style参数为"--":
1 import pandas as pd
2 import matplotlib.pyplot as plt
3 df = pd.read_csv(r"D:\Data\percent-bachelors-degrees-women-usa.csv")
4 #添加指定的style参数
5 df.plot(x = "Year", y = "Agriculture", style = "--")
6 plt.show()
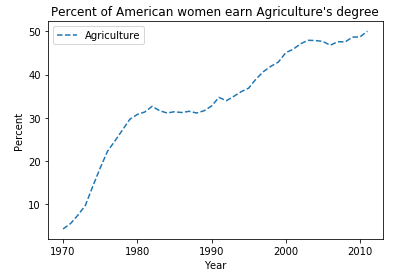
添加坐标轴标签以及标题:
1 import pandas as pd
2 import matplotlib.pyplot as plt
3 df = pd.read_csv(r"D:\Data\percent-bachelors-degrees-women-usa.csv")
4 df.plot(x = "Year", y = "Agriculture", style = "--")
5 #添加横坐标轴标签
6 plt.xlabel("Year")
7 #添加纵坐标轴标签
8 plt.ylabel("Percent")
9 #添加标题
10 plt.title("Percent of American women earn Agriculture's degree")
11 plt.show()
19.2 采用matplotlib.pyplot的plot()方法绘制折线图
matplotlib.pyplot.plot(x, y, style, color, linewidth)函数的参数分别表示: x轴数据, y轴数据, style线条样式, color线条颜色, linewidth线宽.
1 import pandas as pd
2 import matplotlib.pyplot as plt
3 #第一步: 读取数据
4 df = pd.read_csv(r"D:\Data\percent-bachelors-degrees-women-usa.csv")
5 #第二步: 将所需数据赋值给对应的变量
6 df_year, df_Agriculture = df["Year"], df["Agriculture"]
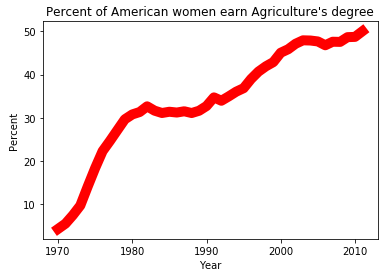
7 #第三步: 用matplotlib中绘图框架的plot()方法绘制红色的折线图
8 plt.plot(df_year, df_Agriculture,"-", color = "r",linewidth = 10)
9 #添加横坐标轴标签
10 plt.xlabel("Year")
11 #添加纵坐标轴标签
12 plt.ylabel("Percent")
13 #添加标题
14 plt.title("Percent of American women earn Agriculture's degree")
15 plt.show()
显示效果:
20. 散点图
散点图: 用两组数据构成多个坐标点, 考察坐标点的分布, 判断两变量之间是否存在某种关联或总结坐标点的分布模式. 各点的值由点在坐标中的位置表示, 用不同的标记方式表示各点所代表的不同类别.
20.1 采用pandas中的plot()方法绘制散点图
只需将plot()函数中的kind参数的值改为"scatter"即可.
数据来源: http://archive.ics.uci.edu/ml/machine-learning-databases/iris/
1 import pandas as pd
2 import matplotlib.pyplot as plt
3 #读取数据
4 df = pd.read_csv(r"D:\Data\Iris.csv")
5 #原始数据中没有给出字段名, 在这里指定
6 df.columns = ['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid','species']
7 #指定x轴与y轴数据并绘制散点图
8 df.plot(x = "sepal_len", y = "sepal_wid", kind = "scatter" )
9 #添加横坐标轴标签
10 plt.xlabel("sepal length")
11 #添加纵坐标轴标签
12 plt.ylabel("sepal width")
13 #添加标题
14 plt.title("Iris sepal length and width analysis")
15 plt.show()

20.2 采用matplotlib.pyplot的plot()方法绘制散点图
1 import pandas as pd
2 import matplotlib.pyplot as plt
3 df = pd.read_csv(r"D:\Data\Iris.csv")
4 df.columns = ['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid','species']
5 #用绘图框架的plot()方法绘图, 样式为".", 颜色为红色
6 plt.plot(df["sepal_len"], df["sepal_wid"],".", color = "r")
7 plt.xlabel("sepal length")
8 plt.ylabel("sepal width")
9 plt.title("Iris sepal length and width analysis")
10 plt.show()

21. 饼图
饼图: 将一个圆形划分为多个扇形的统计图, 它通常被用来显示各个组成部分所占比例.
由于在绘制饼状图先要对数据进行分类汇总, 先查看数据的总体信息
1 import pandas as pd
2 df = pd.read_csv(r"D:\Data\Iris.csv")
3 df.columns = ['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid','species']
4 #查看数据总体信息
5 df.describe()
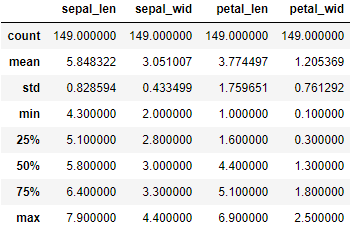
可以看出每一列都是149个数据, 那么接下来对species列进行分类汇总
1 import pandas as pd
2 df = pd.read_csv(r"D:\Data\Iris.csv")
3 df.columns = ['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid','species']
4 #对species列进行分类并对sepal_len列进行计数
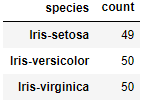
5 df_gbsp = df.groupby("species")["sepal_len"].agg(["count"])
6 df_gbsp
21.1 采用pandas中的plot()方法绘制饼状图
1 import pandas as pd
2 import matplotlib.pyplot as plt
3 df = pd.read_csv(r"D:\Data\Iris.csv")
4 df.columns = ['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid','species']
5 #对species列进行分类并对sepal_len列进行计数
6 df_gbsp = df.groupby("species")["sepal_len"].agg(["count"])
7 #绘制图形样式为饼图, 百分比保留两位小数, 字体大小为20, 图片大小为6x6, subplots为True表示将数据每列绘制为一个子图,legend为True表示隐藏图例
8 df_gbsp.plot(kind = "pie", autopct='%.2f%%', fontsize=20, figsize=(6, 6), subplots = True, legend = False)
9 plt.show()

21.2 采用matplotlib.pyplot的pie()方法绘制饼状图
pie(x, explode = None, labels = None, colors=None, autopct=None)的参数分别表示:
第一个: x表示要绘图的序列
第二个: explode要突出显示的组成部分
第三个: labels各组成部分的标签
第四个: colors各组成部分的颜色
第五个: autopct数值显示格式
1 import pandas as pd
2 import matplotlib.pyplot as plt
3 df = pd.read_csv(r"D:\Data\Iris.csv")
4 df.columns = ['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid','species']
5 df["species"] = df["species"].apply(lambda x: x.replace("Iris-",""))
6 df_gbsp = df.groupby("species",as_index = False)["sepal_len"].agg({"counts": "count"})
7 #对counts列的数据绘制饼状图.
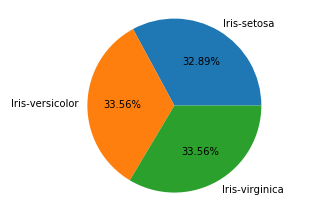
8 plt.pie(df_gbsp["counts"],labels = df_gbsp["species"], autopct = "%.2f%%" )
9 plt.show()
22. 柱形图
柱形图: 又称为长条图, 是一种以长方形的长度为变量的统计图. 柱形图常用来比较两个或以上的数据不同时间或者不同条件).
22.1 采用pandas的plot()方法绘制柱形图
1 import pandas as pd
2 import matplotlib.pyplot as plt
3 df = pd.read_csv(r"D:\Data\Iris.csv")
4 df.columns = ['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid','species']
5 df["species"] = df["species"].apply(lambda x: x.replace("Iris-",""))
6 #对species分组求均值
7 df_gbsp = df.groupby("species", as_index = False).mean()
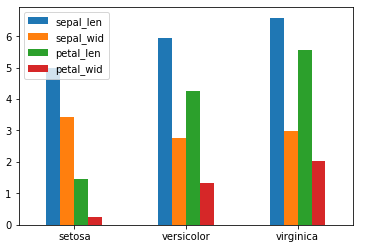
8 #绘制柱形图
9 df_gbsp.plot(kind = "bar")
10 #修改横坐标轴刻度值
11 plt.xticks(df_gbsp.index,df_gbsp["species"],rotation=360)
12 plt.show()
当然也可以绘制横向柱形图
1 import pandas as pd
2 import matplotlib.pyplot as plt
3 df = pd.read_csv(r"D:\Data\Iris.csv")
4 df.columns = ['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid','species']
5 df["species"] = df["species"].apply(lambda x: x.replace("Iris-",""))
6 df_gbsp = df.groupby("species", as_index = False).mean()
7 #将bar改为barh即可绘制横向柱形图
8 df_gbsp.plot(kind = "barh")
9 plt.yticks(df_gbsp.index,df_gbsp["species"],rotation=360)
10 plt.show()

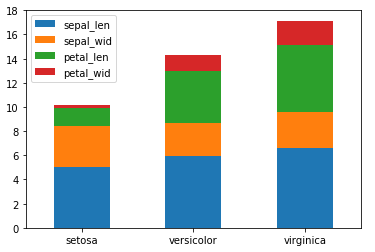
若想要将样式改为堆积柱形图:
#修改stacked参数为True即可
df_gbsp.plot(kind = "barh", stacked = True)
22.2 采用matplotlib.pyplot的bar()方法绘制柱形图
bar( x, height, width=0.8, color = None, label =None, bottom =None, tick_label = None)的参数分别表示:
第一个: x表示x轴的位置序列
第二个: height表示某个系列柱形图的高度
第三个: width表示某个系列柱形图的宽度
第四个: label表示图例
第五个: bottom表示底部为哪个系列, 常被用在堆积柱形图中
第六个: tick_label刻度标签
1 import pandas as pd
2 import matplotlib.pyplot as plt
3 df = pd.read_csv(r"D:\Data\Iris.csv")
4 df.columns = ['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid','species']
5 df["species"] = df["species"].apply(lambda x: x.replace("Iris-",""))
6 df_gbsp = df.groupby("species").mean()
7 #绘制"sepal_len"列柱形图
8 plt.bar(df_gbsp.index,df_gbsp["sepal_len"], width= 0.5 , color = "g")
9 plt.show()

绘制多组柱形图:
1 import numpy as np
2 import pandas as pd
3 import matplotlib.pyplot as plt
4 df = pd.read_csv(r"D:\Data\Iris.csv")
5 df.columns = ['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid','species']
6 df["species"] = df["species"].apply(lambda x: x.replace("Iris-",""))
7 df_gbsp = df.groupby("species").mean()
8 #计算有多少个列
9 len_spe = len(df_gbsp.count())
10 #计算有多少行, 并生成一个步进为1的数组
11 index = np.arange(len(df_gbsp.index))
12 #设置每组总宽度
13 total_width= 1.4
14 #求出每组每列宽度
15 width = total_width/len_spe
16 #对每个字段进行遍历
17 for i in range(len_spe):
18 #得出每个字段的名称
19 het = df_gbsp.columns[i]
20 #求出每个字段所包含的数组, 也就是对应的高度
21 y_values = df_gbsp[het]
22 #设置x轴标签
23 x_tables = index * 1.5 + i*width
24 #绘制柱形图
25 plt.bar(x_tables, y_values, width =width)
26 #通过zip接收(x_tables,y_values),返回一个可迭代对象, 每一个元素都是由(x_tables,y_values)组成的元组.
27 for x, y in zip(x_tables, y_values):
28 #通过text()方法设置数据标签, 位于柱形中心, 最顶部, 字体大小为10.5
29 plt.text(x, y ,'%.2f'% y ,ha='center', va='bottom', fontsize=10.5)
30 #设置x轴刻度标签位置
31 index1 = index * 1.5 + 1/2
32 #通过xticks设置x轴标签为df_gbsp的索引
33 plt.xticks(index1 , df_gbsp.index)
34 #添加图例
35 plt.legend(df_gbsp.columns)
36 plt.show()
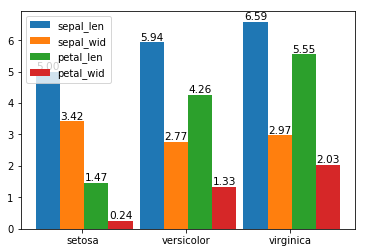
绘制堆积柱形图
1 import numpy as np
2 import pandas as pd
3 import matplotlib.pyplot as plt
4 df = pd.read_csv(r"D:\Data\Iris.csv")
5 df.columns = ['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid','species']
6 df["species"] = df["species"].apply(lambda x: x.replace("Iris-",""))
7 df_gbsp = df.groupby("species").mean()
8 len_spe = len(df_gbsp.count())
9 index = np.arange(len(df_gbsp.index))
10 total_width= 1
11 width = total_width/len_spe
12 ysum = 0
13 for i in range(len_spe):
14 het = df_gbsp.columns[i]
15 y_values = df_gbsp[het]
16 #将x轴标签改为index/2, 之后在设置bottom为ysum.
17 plt.bar(index/2, y_values, width =width, bottom = ysum)
18 ysum, ysum1= ysum+ y_values, ysum
19 #计算堆积后每个区域中心对应的高度
20 zsum = ysum1 + (ysum - ysum1)/2
21 for x, y , z in zip(index/2, y_values, zsum):
22 plt.text(x, z ,'%.2f'% y ,ha='center', va='center', fontsize=10.5)
23 plt.xticks(index/2 , df_gbsp.index)
24 plt.legend(df_gbsp.columns)
25 plt.show()

bar()函数是用来绘制竖直柱形图, 而绘制横向柱形图用barh()函数即可, 两者用法相差不多
23. 直方图
直方图: 由一系列高度不等的长方形表示数据分布的情况, 宽度表示间隔, 高度表示在对应宽度下出现的频数.
23.1 采用pandas中的plot()方法绘制折线图
将plot()方法中的kind参数改为"hist"即可, 参考官方文档: http://pandas.pydata.org/pandas-docs/version/0.15.0/visualization.html#histograms
1 import numpy as np
2 import pandas as pd
3 import matplotlib.pyplot as plt
4 df = pd.read_csv(r"D:\Data\Iris.csv")
5 df.columns = ['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid','species']
6 df["species"] = df["species"].apply(lambda x: x.replace("Iris-",""))
7 df_gbsp = df["sepal_len"]
8 #绘制直方图
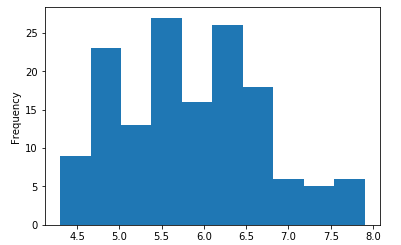
9 df_gbsp.plot(kind = "hist")
10 plt.show()
#可修改cumulative=True实现累加直方图, 以及通过bins参数修改分组数
df_gbsp.plot(kind = "hist", cumulative='True', bins = 20)

23.2 采用matplotlib.pyplot的hist()方法绘制折线图
1 import numpy as np
2 import pandas as pd
3 import matplotlib.pyplot as plt
4 df = pd.read_csv(r"D:\Data\Iris.csv")
5 df.columns = ['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid','species']
6 df["species"] = df["species"].apply(lambda x: x.replace("Iris-",""))
7 #hist()方法绘制直方图
8 plt.hist(df["sepal_wid"], bins =20, color = "k")
9 plt.show()

#修改为累加直方图, 透明度为0.7
plt.hist(df["sepal_wid"], bins =20, color = "K", cumulative=True, alpha = 0.7)

以上是对pandas的几个基本可视化视图的总结, 更多pandas可视化相关参考官方文档: http://pandas.pydata.org/pandas-docs/version/0.15.0/visualization.html
原文来自:https://www.cnblogs.com/star-zhao/p/9715307.html
Pandas与Matplotlib结合进行可视化的更多相关文章
- 动态可视化 数据可视化之魅D3,Processing,pandas数据分析,科学计算包Numpy,可视化包Matplotlib,Matlab语言可视化的工作,Matlab没有指针和引用是个大问题
动态可视化 数据可视化之魅D3,Processing,pandas数据分析,科学计算包Numpy,可视化包Matplotlib,Matlab语言可视化的工作,Matlab没有指针和引用是个大问题 D3 ...
- Pandas与Matplotlib基础
pandas是Python中开源的,高性能的用于数据分析的库.其中包含了很多可用的数据结构及功能,各种结构支持相互转换,并且支持读取.保存数据.结合matplotlib库,可以将数据已图表的形式可视化 ...
- 用Pandas获取商品期货价格并可视化
用Pandas获取商品期货价格并可视化 摘 要 1.用pandas从excel中读取数据: 2.用pandas进行数据清洗.整理: 3.用bokeh进行简单的可视化. 1.数据读取 本文主要是将获 ...
- day18-常用模块III (numpy、pandas、matplotlib)
目录 numpy模块 创建矩阵 获取矩阵的行列数 切割矩阵 矩阵元素替换 矩阵的合并 通过函数创建矩阵 矩阵的运算 矩阵的点乘与转置 矩阵的逆 矩阵的其他操作 numpy.random生成随机数 pa ...
- Pandas与Matplotlib
Pandas与Matplotlib基础 pandas是Python中开源的,高性能的用于数据分析的库.其中包含了很多可用的数据结构及功能,各种结构支持相互转换,并且支持读取.保存数据.结合matplo ...
- 使用 jupyter-notebook + python + matplotlib 进行数据可视化
上次用 python 脚本中定期查询数据库,监视订单变化,将时间与处理完成订单的数量进行输入写入日志,虽然省掉了人为定时查看数据库并记录的操作,但是数据不进行分析只是数据,要让数据活起来! 为了方便看 ...
- linux下安装numpy,pandas,scipy,matplotlib,scikit-learn
python在数据科学方面需要用到的库: a.Numpy:科学计算库.提供矩阵运算的库. b.Pandas:数据分析处理库 c.scipy:数值计算库.提供数值积分和常微分方程组求解算法.提供了一个非 ...
- 用Python的Pandas和Matplotlib绘制股票KDJ指标线
我最近出了一本书,<基于股票大数据分析的Python入门实战 视频教学版>,京东链接:https://item.jd.com/69241653952.html,在其中给出了MACD,KDJ ...
- matplotlib实现数据可视化
一篇matplotlib库的学习博文.matplotlib对于数据可视化非常重要,它完全封装了MatLab的所有API,在python的环境下和Python的语法一起使用更是相得益彰. 一.库的安装和 ...
随机推荐
- Selenium(六)对话框处理与登录测试
1.以百度为例,找到登录框,查看元素,可以看到这是一个div 操作登录框: 通过判断是否找到这个错误提示元素查看是否登录成功. 一个简单的登录脚本:
- [2019牛客多校第三场][G. Removing Stones]
题目链接:https://ac.nowcoder.com/acm/contest/883/G 题目大意:有\(n\)堆石头,每堆有\(a_i\)个,每次可以选其中两堆非零的石堆,各取走一个石子,当所有 ...
- python自动华 (三)
Python自动化 [第三篇]:Python基础-集合.文件操作.字符编码与转码.函数 1. 集合 1.1 特性 集合是一个无序的,不重复的数据组合,主要作用如下: 去重,把一 ...
- javaMail 详解
原文:http://www.matrix.org.cn/resource/article/44/44101_JavaMail.html 一.JavaMail API简介JavaMail API是读取. ...
- java+超大文件上传与下载
这里先说下spring mvc 遇到的坑,就是如果文件上传时,后端这样写public String file1(HttpServletRequest request),根据request拿到的东西是 ...
- [Luogu] 跑路
https://www.luogu.org/problemnew/show/P1613 Floyd判断是否一步到达 将一步到达的连变跑Floyd #include <iostream> # ...
- nginx 部署php
一:nginx安装: yum install nginx 安装完成即可,在/usr/sbin/目录下是nginx命令所在目录,在/etc/nginx/目录下是nginx所有的配置文件,用于配置ngin ...
- codeforces#101194H. Great Cells(数学)
题目链接: https://codeforces.com/gym/101194 题意: 在$n×m$的各自中填上$1$到$k$的数 定义Greate cell为严格大于同行和同列的格子 定义$A_g$ ...
- 域渗透-企业应用SAML签名攻击
在项目中遇到SAML企业应用 想留个后门时候一脸懵 随便的整理记录 记录项目中SAML渗透的知识点. 0x01 前置知识 SAML单点登陆 SAML(Security Assertion ...
- 2019PKUWC游记
有的时候,不是你不会 而是你,认为你不会 ——*Miracle* 本篇游记就简单写了 Day-inf 犹豫许久,还是选择了北大 不是因为喜欢——甚至恰好相反 而是,听说清华高手较多,约型单一, 于是我 ...