分布式消息中间件之kafka设计思想及基本介绍(一)
Kafka初探
场景->需求->解决方案->应用->原理
我该如何去设计消息中间件--借鉴/完善
场景
跨进程通信(进程间生产消费模型)
需求
基本需求
实现消息的发送和接收。
NIO通信 (序列化/反序列化)--dubbo、avro、protobuf、zk(jute)
实现消息的存储(持久化/非持久化)
数据库存储、文件存储(磁盘:顺序读写、页缓存、持久化的时机(落盘策略)、零拷贝)、内存
是否支持跨语言(多语言生态)
消息的确认(确认机制)--在跨进程通信中 ->业务逻辑需求
是否支持集群
自己实现选举、第三方的实现(zk)
高级需求
是否支持有序(业务逻辑)
是否支持事务消息(业务逻辑)->最终一致性
是否支持高并发和大数据的存储
是否支持可靠性存储
是否支持多协议
是否收费
发展
pub/sub--金融领域--TIB(规则)
非个性化需求, 而是共性化需求
IBM websphere mq(商业)
JMS协议->Java api->AMQP(通用性)
kafka
起源:LinkedIn 活动流 运营数据 诞生之初就是为了解决大数据量的问题
简介
实现语言:scala
架构图


下载及安装
单节点安装:
sudo wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.3.0/kafka_2.11-2.3.0.tgz
注意點:
必须安装zk(启动时必须先启动zk),详情请参考
远程安装 必须修改一下两个属性
#本机ip
listeners=PLAINTEXT://‘本机ip’:9092
#zk地址
zookeeper.connect=localhost:2181启动命令
sh kafka-server-start.sh -daemon server.properties
集群安装:
多机器部署
下载安装同单机,主要修改配置文件server.properties文件配置
#zookeeper地址(三个节点相同)
zookeeper.connect=192.168.1.11:2181
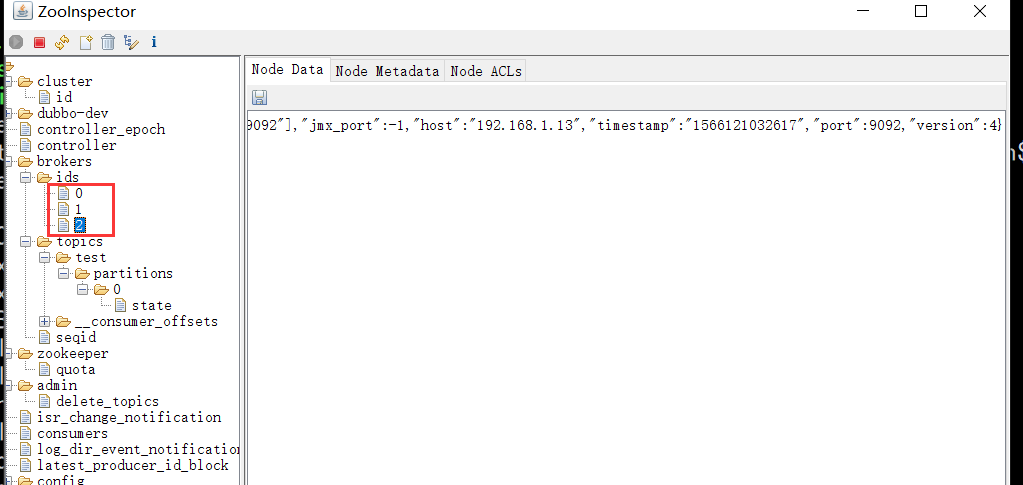
#broker.id(三个节点分别为0、1、2)
broker.id=1
##监听协议(三个节点配置各自的ip地址)
listeners=PLAINTEXT://192.168.1.12:9092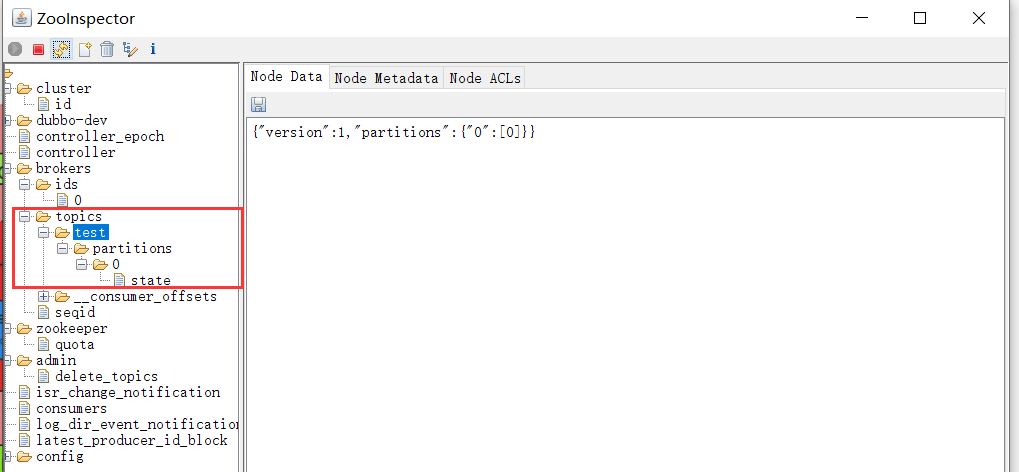

伪集群部署
在单节点创建文件目录进行设置。参考上述多机器部署。
基本操作

##创建topic--创建成功后可以在zk客户端看到此消息
sh kafka-topics.sh --create --zookeeper 192.168.1.11:2181 -replication-factor 1 --partitions 1 --topic test
##消费监听消息
sh kafka-console-consumer.sh --bootstrap-server 192.168.1.11:9092 --topic test --from-beginning
##生产消息
sh kafka-console-producer.sh --broker-list 192.168.1.11:9092 --topic test
消息中间件的应用场景
不同的业务领域,异步,解耦,削峰
注册新用户(用户中心)
->发送理财金/优惠券;为了增加复购->赠送一些优惠券(营销服务)
秒杀场景(流量大,商品少)
分布式消息中间件之kafka设计思想及基本介绍(一)的更多相关文章
- AI框架精要:设计思想
AI框架精要:设计思想 本文主要介绍飞桨paddle平台的底层设计思想,可以帮助用户理解飞桨paddle框架的运作过程,以便于在实际业务需求中,更好的完成模型代码编写与调试及飞桨paddle框架的二次 ...
- 分布式系列九: kafka
分布式系列九: kafka概念 官网上的介绍是kafka是apache的一种分布式流处理平台. 最初由Linkedin开发, 使用Scala编写. 具有高性能,高吞吐量的特定. 包含三个关键能力: 发 ...
- Kafka/Metaq设计思想学习笔记 转
转载自: http://my.oschina.net/geecoodeer/blog/194829 本文没有特意区分它们之间的区别,仅仅是列出其中笔者认为好的设计思想,供后续设计参考. 目前笔者并没有 ...
- Kafka详解四:Kafka的设计思想、理念
问题导读 1.Kafka的设计基本思想是什么?2.Kafka消息转运过程中是如何确保消息的可靠性的? 本节主要从整体角度介绍Kafka的设计思想,其中的每个理念都可以深入研究,以后我可能会发专题文章做 ...
- kafka具体解释四:Kafka的设计思想、理念
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/suifeng3051/article/details/37606001 本节主要从总体角度 ...
- 从一般分布式设计看HDFS设计思想与架构
要想深入学习HDFS就要先了解其设计思想和架构,这样才能继续深入使用HDFS或者深入研究源代码.懂得了"所以然"才能在实际使用中灵活运用.快速解决遇到的问题.下面这篇博文我们就先 ...
- Kafka 设计与原理详解
一.Kafka简介 本文综合了我之前写的kafka相关文章,可作为一个全面了解学习kafka的培训学习资料. 转载请注明出处 : 本文链接 1.1 背景历史 当今社会各种应用系统诸如商业.社交.搜索. ...
- kafka之二:Kafka 设计与原理详解
一.Kafka简介 本文综合了我之前写的kafka相关文章,可作为一个全面了解学习kafka的培训学习资料. 转载请注明出处 : 本文链接 1.1 背景历史 当今社会各种应用系统诸如商业.社交.搜索. ...
- [转载] 360分布式存储系统Bada的设计和应用
原文: http://mp.weixin.qq.com/s?__biz=MzAwMDU1MTE1OQ==&mid=208931479&idx=1&sn=1dc6ea4fa28a ...
随机推荐
- c++ STL之unordered_map
1.1 特性 关联性:通过key去检索value,而不是通过绝对地址(和顺序容器不同) 无序性:使用hash表存储,内部无序 Map : 每个值对应一个键值 键唯一性:不存在两个元素的键一样 动态内存 ...
- Android View重绘和更新: invalidate和requestLayout 总结的不错 赶紧复制。。哈哈
总述:View有两个很重要的方法:invalidate和requestLayout,常用于View重绘和更新. Invalidate:To farce a view to draw,call inva ...
- System.arraycopy() 数组复制方法
一.深度复制和浅度复制的区别 Java数组的复制操作可以分为深度复制和浅度复制,简单来说深度复制,可以将对象的值和对象的内容复制;浅复制是指对对象引用的复制. 二.System.arraycop ...
- koa2数据请求相关问题解决方案汇总
前端请求后端数据,难免会遇到如下几个问题: 1⃣️跨域 2⃣️post/get,其中post请求的方式又分为多种 3⃣️后端数据返回格式(上一篇已经有讨论过,这里不再赘述) 用koa2的话,如何解决这 ...
- 论UT阶段重要性
测试与开发这对立的命运啊 如果是对测试从业者心存鄙视的朋友啊,请关掉此页,带着偏见不好看的~ 人生就像一个旅途,每个人看到风景不一样,世界观.人生观.价值观也就不同.不要试着去改变别人,因为你的观点在 ...
- 【HANA系列】SAP HANA SQL IFNULL和NULLIF用法与区别
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[HANA系列]SAP HANA SQL IFN ...
- 论文阅读 | HotFlip: White-Box Adversarial Examples for Text Classification
[code] [pdf] 白盒 beam search 基于梯度 字符级
- idea spring+springmvc+mybatis环境配置整合详解
idea spring+springmvc+mybatis环境配置整合详解 1.配置整合前所需准备的环境: 1.1:jdk1.8 1.2:idea2017.1.5 1.3:Maven 3.5.2 2. ...
- [目标检测] 从 R-CNN 到 Faster R-CNN
R-CNN 创新点 经典的目标检测算法使用滑动窗法依次判断所有可能的区域,提取人工设定的特征(HOG,SIFT).本文则预先提取一系列较可能是物体的候选区域,之后仅在这些候选区域上用深度网络提取特征, ...
- [Comet OJ - Contest #4 D][39D 1584]求和_"数位dp"
求和 题目大意: 数据范围: 题解: 脑筋急转弯可还行..... 我们发现只需要最后枚举个位/xk/xk 因为前面的贡献都是确定的了. 故此我们最后暴力统计一下就好咯. 不知道为啥我组合数一直过不去, ...