celery:强大的定时任务模块
什么是celery
还是一个老生常谈的话题,假设用户注册,首先注册信息入库,然后要调用验证码服务接口,然后根据手机号发送验证码,最后再返回响应给浏览器。但显然调用接口、发送验证码之后成功再给浏览器响应,这肯定是不友好的。于是我们把耗时的任务放在队列当中,直接返回响应给浏览器。同时服务器从队列里面获取任务,所以一般需要输入短信验证码的时候,一点击就显示发送成功了,其实没有,而是正在调用服务,所以一般是大概8秒后,手机才会收到。响应和给手机发送验证码这两步操作是同时进行的,并不是说先把验证码发送成功,然后才在页面上显示发送成功。
有人肯定会说,这特喵的不就是消息队列吗?是的,但是celery本身并不是消息队列,它只是对消息队列的各种操作进行了封装,我们可以使用它快速地进行消息(准确的说是任务)队列的使用和管理。至于消息队列本身,我们可以使用主流的消息队列,或者说具备存储、获取等功能的都可以。比如redis、rabbitmq、数据库等等,官方推荐rabbitmq。
celery架构
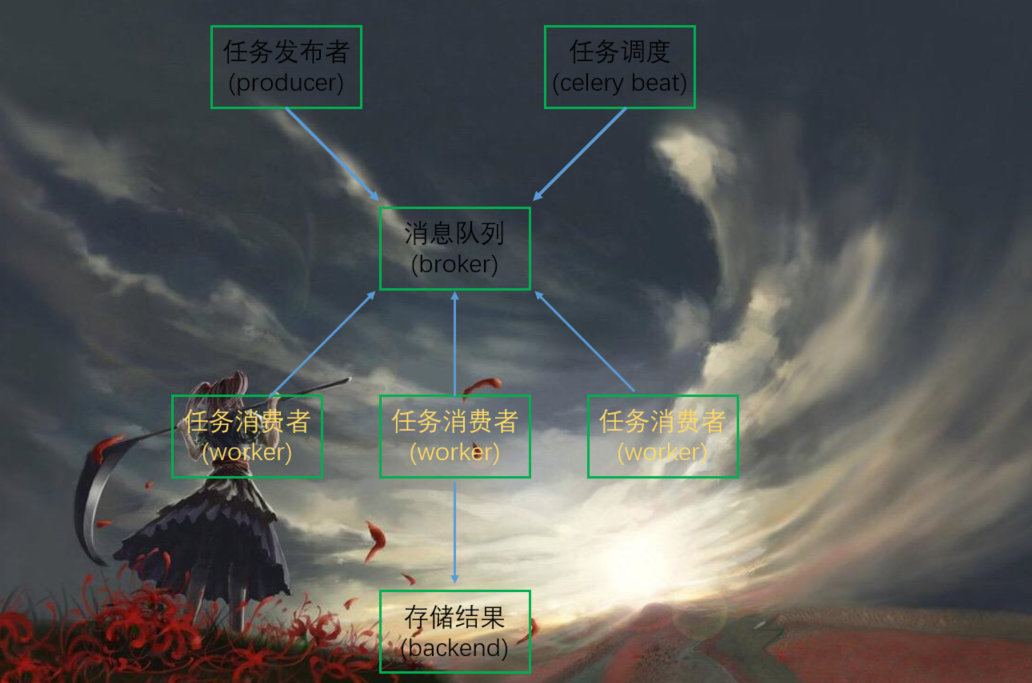
producer:任务生产者,调用celery api、函数、或者装饰器,产生任务的都是生产者celery beat:任务调度器,beat进程会读取配置文件的内容,周期性地将配置文件中到期需要执行的任务发送给消息队列broker:一般是消息队列,但是具有存储功能的数据库也是可以的。这一部分是celery所不提供的,是需要依赖第三方的,比如redis、rabbitmq等等。会接受生产者生产的消息,存进队列,再顺序发给消费者worker:执行task(任务)的消费者,可以同时运行多个消费者,并行消费。并且backend:用于在任务结束之后保存状态信息和结果,以便查询,一般是数据库
基本使用
首先定义一个task.py
from celery import Celery
"""
这个Celery也可以叫做App,
因为源码中定义了App = Celery
"""
# 指定一个name,以及broker、backend的地址,这里我们都使用redis
app = Celery("satori",
broker="redis://47.94.174.89:6379/1",
backend="redis://47.94.174.89:6379/2")
# 通过app.task对一个函数进行装饰,可以创建一个任务
@app.task
def task(name,age):
print("准备执行任务啦~~~~")
return f"name is {name}, age is {age}"
创建一个worker,等待任务。celery -A task worker -l info -P eventlet,里面的task是我们的py文件名,-l info表示日志等级,-P eventlet表示事件驱动使用eventlet,这个需要在windows平台设置,但在linux平台不需要
另外celery -A task worker -l info -P eventlet这种启动方式不符合规范,但是也能启动,真正的启动方式应该是celery worker -A task -l info -P eventlet,要把worker写在前面。
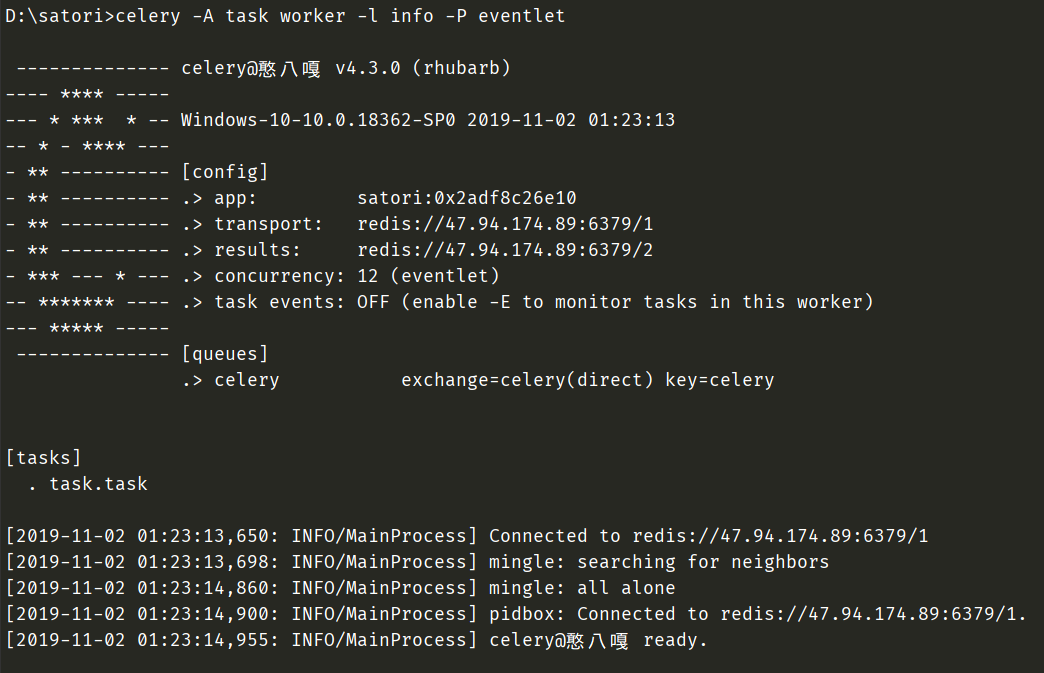
此时已经创建了一个worker,开启监听模式,准备往队列里面取任务,但是此时队列里面还没有任务,那么我们是不是要往队列里面添加任务呢?
# execute.py
from task import task
# 将里面的任务导入进来
"""
注意,你不能这样去执行
task("憨八嘎", 18)
这样执行是没有意义的,这样就直接在本地执行了
我们的目的是将任务发送给队列,然后让监听队列的worker从队列里面取任务,然后执行
因此我们需要调用delay方法
"""
# delay里面传的参数,会原封不动的传递给task
# 此时任务就被发送到队列,也就是我们这里的redis里面去了
task.delay("憨八嘎", 18)
此时直接执行这个脚本,然后我们再来看看worker
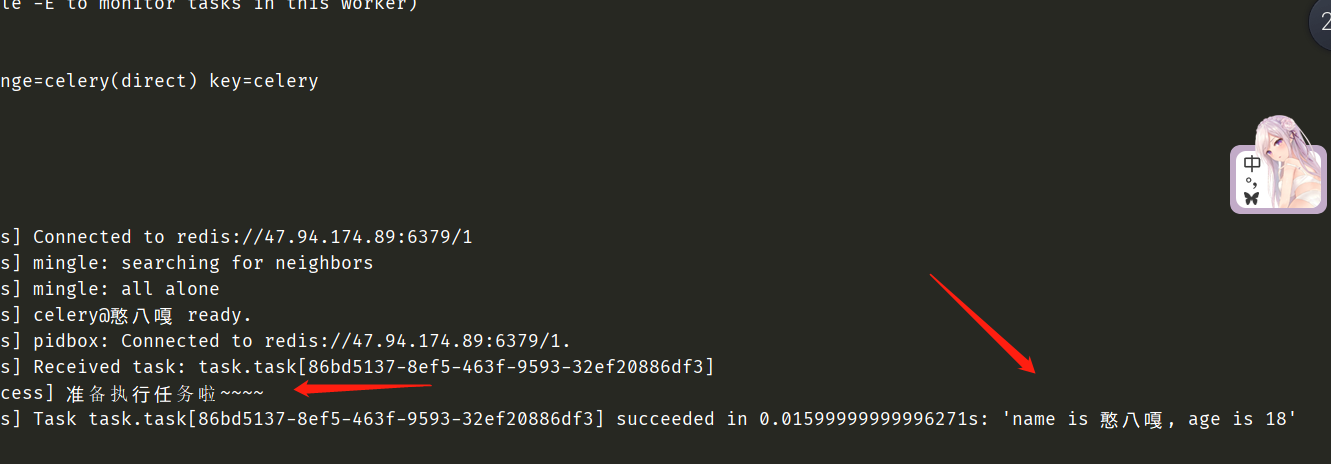
我们可以看到此时任务已经被worker取出并且消费了。并且我想说的是,当我们在执行task.delay()这个方法是不会阻塞的,会立即返回。我们可以验证一下。
from celery import Celery
app = Celery("satori",
broker="redis://47.94.174.89:6379/1",
backend="redis://47.94.174.89:6379/2")
@app.task
def task(name,age):
# 这里我们睡3秒
print("睡觉")
import time
time.sleep(3)
print("~~~~~~准备执行任务啦~~~~")
return f"name is {name}, age is {age}"
"""
注意:我们使用当前这个task.py来创建worker,任务必须在这里面创建好。
或者说你在其他地方创建,然后导入进入来也可以
总之celery -A task worker -l info -P eventlet创建worker的时候,要让worker知道有哪些任务
不然你先启动,后续再使用app.task装饰函数、创建任务、调用delay方法添加任务进队列的时候,会抛出一个KeyError
strategy = strategies[type_]
KeyError: 'satori.xxx'
"""
这里我们需要重新启动,然后执行execute.py
from task import task
import time
start = time.perf_counter()
task.delay("hanser", 18)
end = time.perf_counter()
print(end - start) # 0.2382841
可以看到基本瞬间就返回了,当前所花费的时间是用来发送任务到redis里面的。

from task import task
# 我们赋一个值吧
t1 = task.delay("hanser", 18)
print(type(t1)) # <class 'celery.result.AsyncResult'>
print(t1.id) # d781ff0c-48cc-4bfa-a5ac-2cfb3858cc69
print(t1.get()) # name is hanser, age is 18
"""
此时的t1是一个<class 'celery.result.AsyncResult'>实例对象,但是打印的时候会调用__str__方法打印出id
t1.id就是获取id,当我们添加一个任务的时候,会返回一个id。
如果我们不适用celery,直接连接队列、往队列里面添加任务,是不会返回id的。
那这个id有什么用呢?我们可以根据id去backend里面查找任务的执行状态和结果
至于t1.get()方法就是返回值了
"""
# 因此我们这里是需要配置backend的,如果我们在Celery中没有配置backend,那么t1.get()会报错。
根据id去查询结果
我们之前说,delay之后会返回一串<class 'celery.result.AsyncResult'>实例对象,可以根据这个实例对象下的id方法拿到id,然后去查找结果,那么要如何查找呢?
from task import task, app
from celery.result import AsyncResult
t1 = task.delay("hanser", 18)
# 传入id和app,可以去查询状态和结果
async_result = AsyncResult(id=t1.id, app=app)
while True:
import time
if async_result.successful():
print(async_result.get()) # 调用get方法拿到返回值
break
elif async_result.failed():
print("执行失败")
elif async_result.status == "PENDING":
print("任务正在被执行")
elif async_result.status == "RETRY":
print("任务异常正在重试")
elif async_result.status == "STARTED":
print("任务开始被执行")
time.sleep(1)
"""
任务正在被执行
任务正在被执行
任务正在被执行
name is hanser, age is 18
"""
当然这个AsyncResult还有很多其他方法
ready():查看任务状态,返回布尔值。任务执行完成返回True,否则为Falsewait():和下面的get一样result:任务执行结果get():获取任务执行结果,但是可以设置一个timeout,等待时间state:任务的状态,有三种:PENDING, START, SUCCESSstatus:和state一样successful():任务成功返回Truetrackback:如果任务抛出了一个异常,可以获取原始的回溯信息id、task_id:获取任务id
from task import task, app
from celery.result import AsyncResult
import time
t1 = task.delay("hanser", 18)
async_result = AsyncResult(id=t1.id, app=app)
print(async_result.task_id) # 677932cf-7169-4e62-87e0-bd62f469af72
print(async_result.id) # 677932cf-7169-4e62-87e0-bd62f469af72
print(async_result.ready()) # False
print(async_result.status) # PENDING
time.sleep(3)
print(async_result.task_id) # 677932cf-7169-4e62-87e0-bd62f469af72
print(async_result.id) # 677932cf-7169-4e62-87e0-bd62f469af72
print(async_result.ready()) # True
print(async_result.status) # SUCCESS
消息的序列化
既然是把数据存到消息队列里面,肯定是需要进行序列化,那么都支持哪些序列化的方式呢?
binary:二进制序列化方式,python的pickle默认的序列化方法json:支持多种语言,可解决扩语言的问题,但好像不支持自定义类XML:标签语言msgpack:二进制的类json序列化,但比json更小、更快yaml:表达能力更强、支持的类型更多,但是在python下性能不如json
根据情况,选择合适的类型。如果不是跨语言的话,直接选择binary即可,默认是json
celery的配置
celery的配置不同,所表现出来的性能也不同,比如序列化的方式、连接队列的方式,单线程、多线程、多进程等等。那么celery都有那些配置呢?
CELERY_DEFAULT_QUEUE:队列地址BROKER_URL: 代理人的地址CELERY_RESULT_BACKEND:结果存储地址CELERY_TASK_SERIALIZER:任务序列化方式CELERY_RESULT_SERIALIZER:任务执行结果序列化方式CELERY_TASK_RESULT_EXPIRES:任务过期时间CELERY_ACCEPT_CONTENT:指定任务接受的内容序列化类型(序列化),一个列表;
那么下面我们通过配置文件的方式启动
config.py
BROKER_URL = "redis://47.94.174.89:6379/1"
CELERY_RESULT_BACKEND = 'redis://47.94.174.89:6379/12'
# CELERY_TASK_SERIALIZER = 'binary'
# CELERY_RESULT_SERIALIZER = 'binary'
CELERY_TASK_RESULT_EXPIRES = 60 * 60 * 24 # 任务过期时间
# CELERY_ACCEPT_CONTENT = ["msgpack, binary, jspn"] # 里面是一个列表,传入接受的类型
app.py
# -*- coding:utf-8 -*-
# @Author: WanMingZhu
# @Date: 2019/11/2
from celery import Celery
import config
app = Celery(__name__)
# 导入config,调用config_from_object加载
app.config_from_object(config)
"""
是的,我们这里的文件名之前叫task.py实际上不准确,应该叫做app.py
至于为什么,我们看到这不跟flask一个模样吗?
"""
@app.task
def add(a, b):
print("计算加法")
return a + b
@app.task
def sub(a, b):
print("计算减法")
return a - b
task.py
from app import add, sub
add.delay(10, 20)
sub.delay(10, 20)
重新启动,由于我们的文件名已经改成了app,所以之前的task也要改成app,celery -A app worker -l info -P eventlet
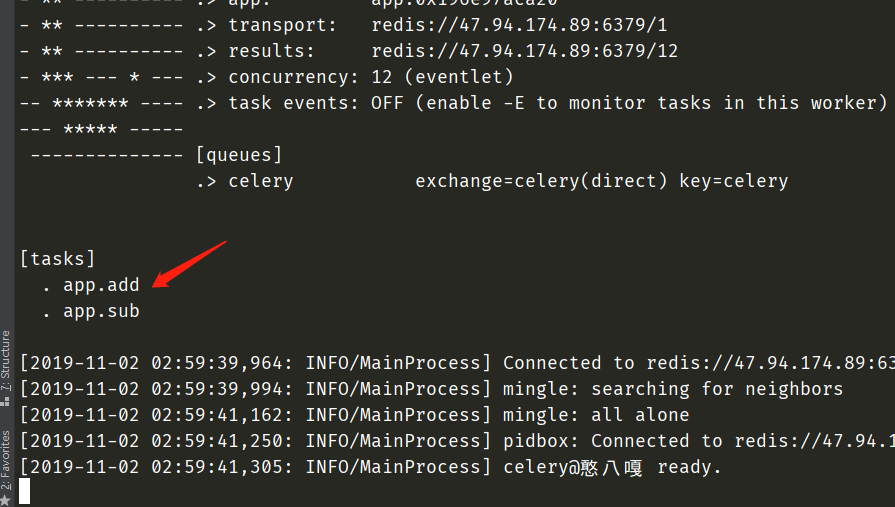
worker监听哪些任务,都已经输出在控制台了。就是说,创建worker的时候,要知道有哪些任务。下面执行task.py
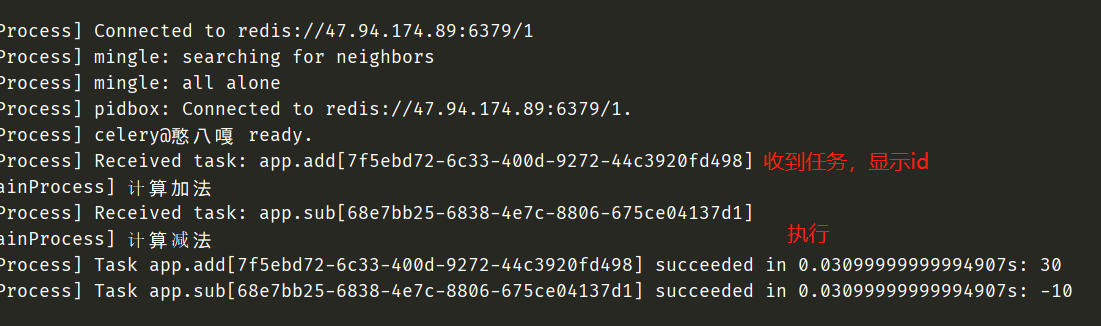
因此我们可以看到,可以同时执行多个任务。
celery.task
我们之前使用app.task对一个函数进行装饰,可以将其变为异步任务。其实这个app.task里面是可以传参的,支持哪些参数呢?
name:可以显示地指定任务的名字serializer:指定序列化的方法bind:一个布尔值,如果为True,那么在delay调用的时候,会把装饰之后产生的task实例传递给函数的第一个参数
# app.py
from celery import Celery
import config
app = Celery(__name__)
app.config_from_object(config)
@app.task(name="憨八嘎", bind=True)
# 可以看到,如果bind=True,那么装饰的方法里面至少要有一个参数
def hanser(self, name, age):
print(f"self.request = {self.request}")
print(f"id = {self.request.id}")
print(f"name = {self.request.name}")
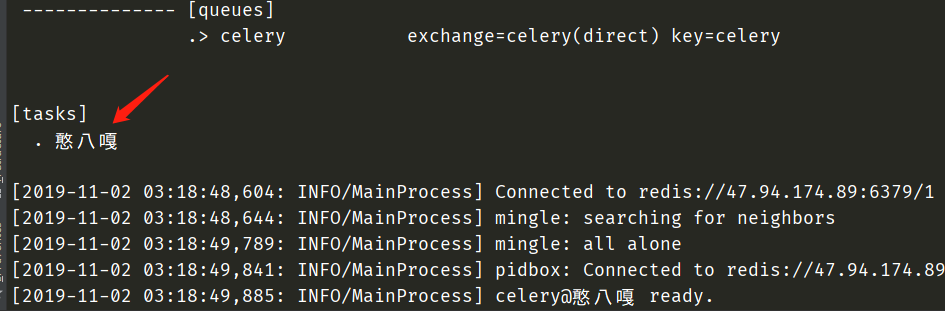
重写Task
我们创建任务的时候,使用app.task作为装饰器,通过装饰函数来创建一个任务。这就跟多线程一样,我们除了启动一个函数,还可以启动类。这对于celery也是一样的,我们可以自定义一个类、继承父类,重写关键的方法即可。下面我们来看看
from celery import Celery
from celery import Task
import config
app = Celery(__name__)
app.config_from_object(config)
class MyTask(Task):
"""自定义一个类,继承自celery.Task"""
"""
exc:失败时的错误的类型;
task_id:任务的id;
args:任务函数的参数;
kwargs:参数;
einfo:失败时的异常详细信息;
retval:任务成功执行的返回值;
"""
def on_failure(self, exc, task_id, args, kwargs, einfo):
"""任务失败时执行"""
def on_success(self, retval, task_id, args, kwargs):
"""任务成功时执行"""
print("任务执行成功")
def on_retry(self, exc, task_id, args, kwargs, einfo):
"""任务重试时执行"""
# 在使用app.task的时候,指定base即可
@app.task(name="憨八嘎", base=MyTask)
def add():
print("加法计算")
return 10 + 20
from app import add
add.delay()
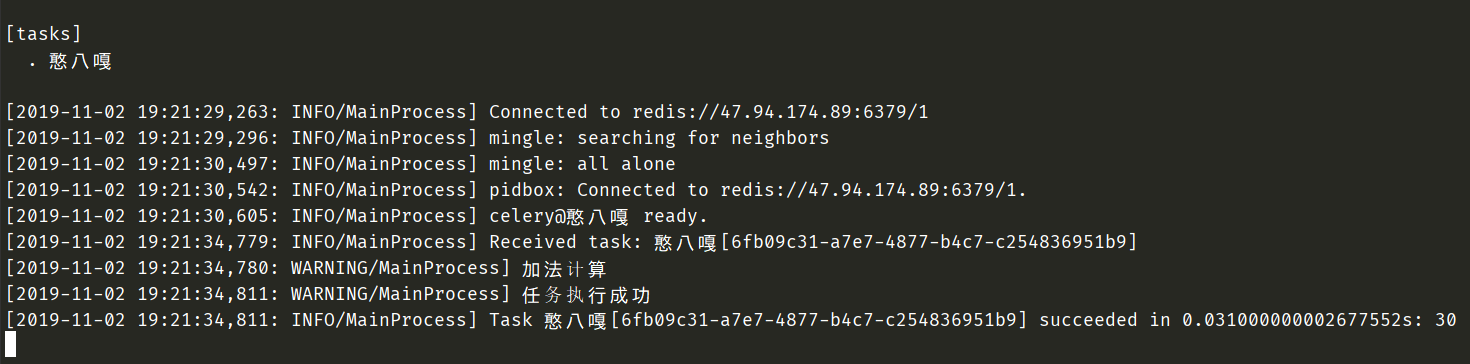
可以看到回调任务被触发了
调用任务时可以指定的参数
我们之前创建一个任务是通过app.task装饰器装饰一个函数,调用任务是通过调用任务的delay方法,将任务放到队列里面让worker调用,但是我们向里面加入哪些参数呢?下面的apply_async实际上和delay是一样,delay本质上调用了apply_sync,所以apply_async里面的参数和delay是一样的
apply_async
里面的参数非常多:
args:函数的位置参数kwargs:函数的关键字参数countdown: 倒计时,表示多少s后执行,参数为整型eta:任务的开始时间,datetime类型,如果指定了countdown,那么这个参数就不应该再指定expires:datetime或者整型,如果到规定时间、或者未来的多少秒之内,任务还没有发送到队列被worker执行,那么app.py里面指定的任务将被丢弃。shadow:重新指定任务名称,覆盖app.py创建任务时所指定的名字retry:任务失败之后是否重试,bool类型retry:重试所采用的策略,如果指定这个参数,那么retry必须要为True。参数类型是一个字典,里面参数如下max_retries : 最大重试次数, 默认为 3 次interval_start : 重试等待的时间间隔秒数, 默认为 0 , 表示直接重试不等待interval_step : 每次重试让重试间隔增加的秒数, 可以是数字或浮点数, 默认为 0.2interval_max : 重试间隔最大的秒数, 即 通过 interval_step 增大到多少秒之后, 就不在增加了, 可以是数字或者浮点数, 默认为 0.2
routing_key:自定义路由键,针对于rabbitmqqueue:指定发送到哪个队列,针对于rabbitmqexchange:指定发送到哪个交换机,针对于rabbitmqpriority:任务队列的优先级,0-9之间serializer:任务序列化方法;通常不设置compression:压缩方案,通常有zlib, bzip2headers:为任务添加额外的消息;link:任务成功执行后的回调方法;是一个signature对象;可以用作关联任务;link_error: 任务失败后的回调方法,是一个signature对象;
from app import add
add.apply_async(countdown=5)

我们发送任务永远都是不阻塞的,这里countdown=5,是指worker在接收到任务之后等待5s才执行,可以看到在21:45:13接收到的任务,但是21:45:18开始执行,说明确实等待了5s才执行。其它的参数,就不试了,太特么多了。当然有的参数也用不到,具体用哪个参数根据业务需求来。
如果只是使用countdown表示多少秒后执行的话,没什么问题,但是当使用eta参数,指定时间的时候执行,会有一个大坑
from app import add
import datetime
add.apply_async(eta=datetime.datetime.now() + datetime.timedelta(seconds=5))

我们发现任务就一直卡在这个地方了,同样是5s后执行,但是却一直停在这里。原因是,我们使用datetime的时候,必须指定为utc时间。
from app import add
import datetime
from pytz import timezone
add.apply_async(eta=datetime.datetime.now(tz=timezone("utc")) + datetime.timedelta(seconds=5))

可以看到此时是执行成功的。
生产环境中使用celery
我们说过,当我们使用app创建worker的时候,这个任务必须已经创建好,并且还要在app里面,因为这样的话,创建worker的时候,才知道有哪些任务。并不是说可以在任意时刻创建任务往队列里面发,然后让worker执行的。worker能执行的任务,是在app里面的任务,但是如果我有一百个任务呢?难道都要写在app里面吗?于是我们想到一个比较low的办法,就是我在其他地方创建任务,然后再导入到app里面不就可以了吗?我们来试一下
from app import app
@app.task
def add(a, b):
return f"a + b = {a + b}"
@app.task
def sub(a, b):
return f"a - b = {a - b}"
@app.task
def mul(a, b):
return f"a * b = {a * b}"
@app.task
def div(a, b):
return f"a // b = {a // b}"
我按照这种方式定义任务可以吗?显然是不可以的,倒不是说定义的方式错了。而是说,我们首先在task.py中,从app文件里面导入了app,但为了让任务都出现在app里面,那么我们还要在app.py文件中,从task里面导入这些任务,显然这样会引发循环导入问题。
# task.py
def task_add(a, b):
return f"a + b = {a + b}"
def task_sub(a, b):
return f"a - b = {a - b}"
def task_mul(a, b):
return f"a * b = {a * b}"
def task_div(a, b):
return f"a // b = {a // b}"
干脆就直接这样定义好了
from celery import Celery
import config
import task
app = Celery(__name__)
app.config_from_object(config)
for func in dir(task):
if func.startswith("task_"):
exec(f"{func} = app.task(task.{func})")
"""
如果python基础好的,肯定知道我这一步是在干什么。
首先遍历task的所有属性,我们只要名字以task_开头的,所以这种方式定义任务的时候,任务的名字要具备一致性
f"{func} = app.task(task.{func})",这是f-string,假设func是task_add
那么这行字符串就相当于是"add = app.task(task.task_add)"
那么再调用exec,等于说是把里面的字符串内容当成命令来执行
不是使用装饰器吗?装饰器的本质是什么呢?
@app.task
def add():
...
等价于 add = app.task(add)
所以这样任务是不是就创建好了呢?,我们来看一下
"""
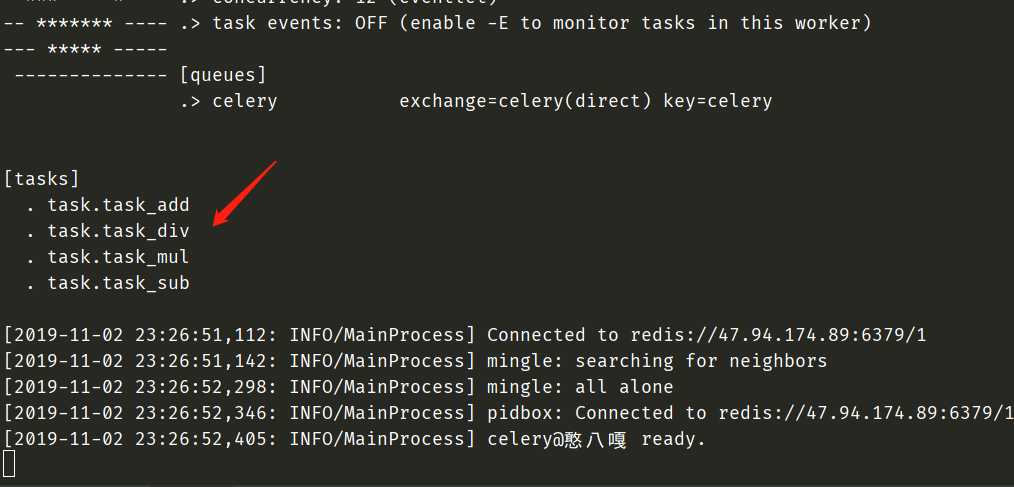
显然任务是创建成功了的。那么我们再新开一个py文件,将任务送到队列里面去让worker执行。
from task import *
task_add(20, 10)
task_sub(20, 10)
task_mul(20, 10)
task_div(20, 10)

但是这样显然不够好,先不说可维护性不好。如果我有很多任务呢?这样做显然是不友好的,于是celery提供了一个更好的办法。
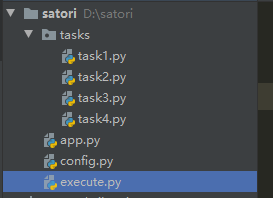
当前我的项目如下,app和config不用说,tasks是一个目录,里面存放所有的任务。execute则是负责把任务送到队列里面去
tasks.task1
from app import app
@app.task
def task1():
return "task1"
tasks.task2
from app import app
@app.task
def task2():
return "task2"
tasks.task3
from app import app
@app.task
def task3():
return "task3"
tasks.task4
from app import app
@app.task
def task4():
return "task4"
我们直接在task里面导入了app,如果直接导入肯定是找不到的,所以我们要在config里面设置环境变量
config
from pathlib import Path
import sys
sys.path.append(str(Path(__file__).parent))
BROKER_URL = "redis://127.0.0.1:6378/1"
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6378/2'
app
from celery import Celery
import config
# 我们只需要在include里面指定包名.模块名即可,就可以把里面的内容全部导进来
# 可以看到是支持多个文件的,显然这样就更方便了
app = Celery(__name__, include=["tasks.task1", "tasks.task2", "tasks.task3", "tasks.task4"])
app.config_from_object(config)
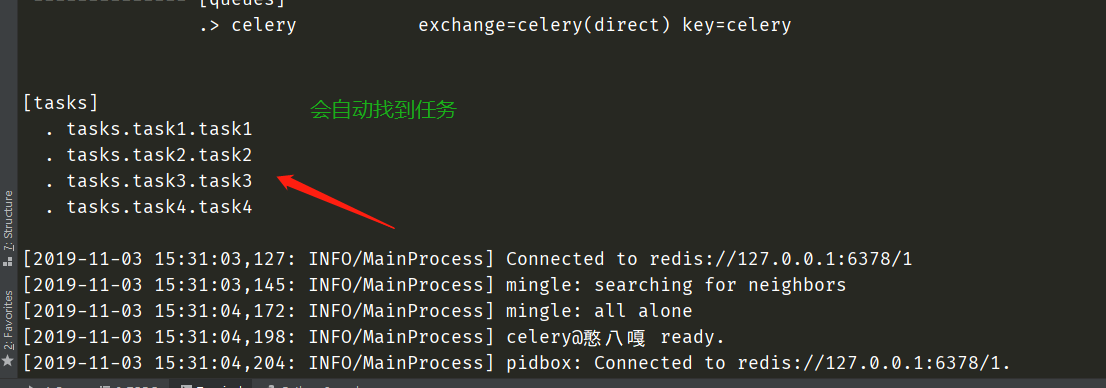
execute
from tasks.task1 import task1
from tasks.task2 import task2
from tasks.task3 import task3
from tasks.task4 import task4
task1.delay()
task2.delay()
task3.delay()
task4.delay()

任务已经全部执行完毕了,这样是不是很方便呢。
自定义任务流
signature对象
from tasks.task1 import task1
from tasks.task2 import task2
from tasks.task3 import task3
from tasks.task4 import task4
# 可以调用signature方法,变成一个signature对象
t1 = task1.signature()
res = t1.delay()
print(res.get()) # task1
# 这个和res = task1.delay()功能是一样的,但是为什么要有这一个东西,后面就知道了
group
将任务按照一个组来执行,将返回值作为一个组来返回
from tasks.task1 import task1
from tasks.task2 import task2
from tasks.task3 import task3
from tasks.task4 import task4
from celery import group
# 将多个signature对象作为一个列表传进去
gp = group(task1.signature(), task2.signature(), task3.signature(), task4.signature())
# 执行组任务,返回一个<class 'celery.result.GroupResult'>对象
res = gp()
print(res.id) # 6f9739a9-4325-4912-8bef-88c221018ea8
print(res.get()) # ['task1', 'task2', 'task3', 'task4']
"""
可以看到整个组是有唯一的id的。
另外signature也可以写成,subtask或者s,在源码里面这几个是等价的,净搞这么多花里胡哨的。
"""
chain
将多个任务像链子一样串起来,第一个任务的输出会作为第二个任务的输入,会传递给下一个任务的第一个参数
@app.task
def task1():
l = []
return l
@app.task
# task1的返回值会传递给这里的task1_return
def task2(task1_return, value):
task1_return.append(value)
return task1_return
@app.task
def task3(task2_return, num):
return [i + num for i in task2_return]
@app.task
def task4(task4_return):
return sum(task4_return)
from tasks.task1 import task1
from tasks.task2 import task2
from tasks.task3 import task3
from tasks.task4 import task4
from celery import group, chain
# 将多个signature对象作为一个列表传进去
my_chain = chain(task1.s() | task2.s(123) | task3.s(5) | task4.s())
# 整个过程等价于[123+5]
# 执行任务链
res = my_chain()
# 获取最终返回值
print(res.get()) # 128
使用定时任务
既然是定时任务,那么就意味着worker要后台启动,否则一旦远程连接断开,就停掉了。因此celery是支持我们是可以后台启动的,并且可以启动多个,我们注意到此时没有 -P eventlet,这是因为我们不在windows下启动,原因是windows下不支持这种启动方式`
celery multi start -A app w1 -l info
celery multi start -A app w2 -l info
celery multi start -A app w3 -l info
...
...
停止的话就是
celery multi stop -A app w1 -l info
celery multi stop -A app w2 -l info
celery multi stop -A app w4 -l info
...
...
为了演示,就在windows下前台启动。我们之前在介绍celery架构的时候,提到过一个celery beat,这个是调度器,是自动将任务添加到队列里面去执行的。
tasks.task
from app import app
@app.task
def task1():
print("我是task1")
return "task1你好"
@app.task
def task2(name):
print(f"我是{name}")
return f"{name}你好"
@app.task
def task3():
print("我是task3")
return "task3你好"
@app.task
def task4(name):
print(f"我是{name}")
return f"{name}你好"
tasks.period_task
from celery.schedules import crontab
from app import app
from .task import task1, task2, task3, task4
@app.on_after_configure.connect
def 设置定时任务(sender, **kwargs):
# 第一个参数为schedule,可以是一个float,也可以是一个crontab
# crontab后面会说,第二个参数是任务,第三个参数是名字
sender.add_periodic_task(10.0, task1.s(), name="每10秒执行一次")
sender.add_periodic_task(15.0, task2.s("task2"), name="每15秒执行一次")
sender.add_periodic_task(20.0, task3.s(), name="每20秒执行一次")
sender.add_periodic_task(
crontab(hour=18, minute=5, day_of_week=0),
task4.s("task4"),
name="每个星期天的18:05运行一次"
)
config
from pathlib import Path
import sys
sys.path.append(str(Path(__file__).parent))
BROKER_URL = "redis://127.0.0.1:6378/1"
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6378/2'
# 之前说过,celery默认使用utc时间,其实我们是可以手动禁用的,然后手动指定时区
CELERY_ENABLE_UTC = False
CELERY_TIMEZONE = 'Asia/Shanghai'
app
from celery import Celery
import config
app = Celery(__name__, include=["tasks.task", "tasks.period_task"])
app.config_from_object(config)
下面就来启动任务
启动worker:celery worker -A app -l info -P eventlet,我们之前启动方式是celery -A app worker -l info -P eventlet,也是可以的,不过前者是最标准的写法
启动beat:celery beat -A tasks.period_task -l info,启动worker是celery worker,app就是我们的app.py文件名,当然在当前命令行的路径要能找得到app.py。启动beat则是celery beat,tasks.period_task就是我们的定时任务对应的py文件名,由于是在tasks目录里面,因此需要指定tasks.period_task
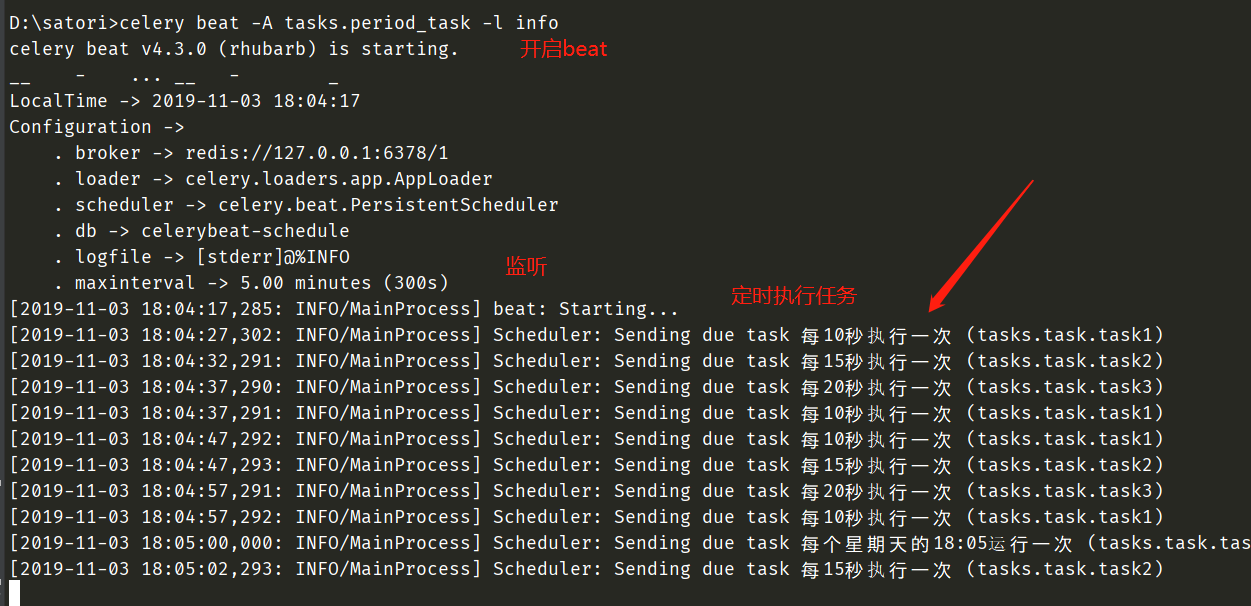
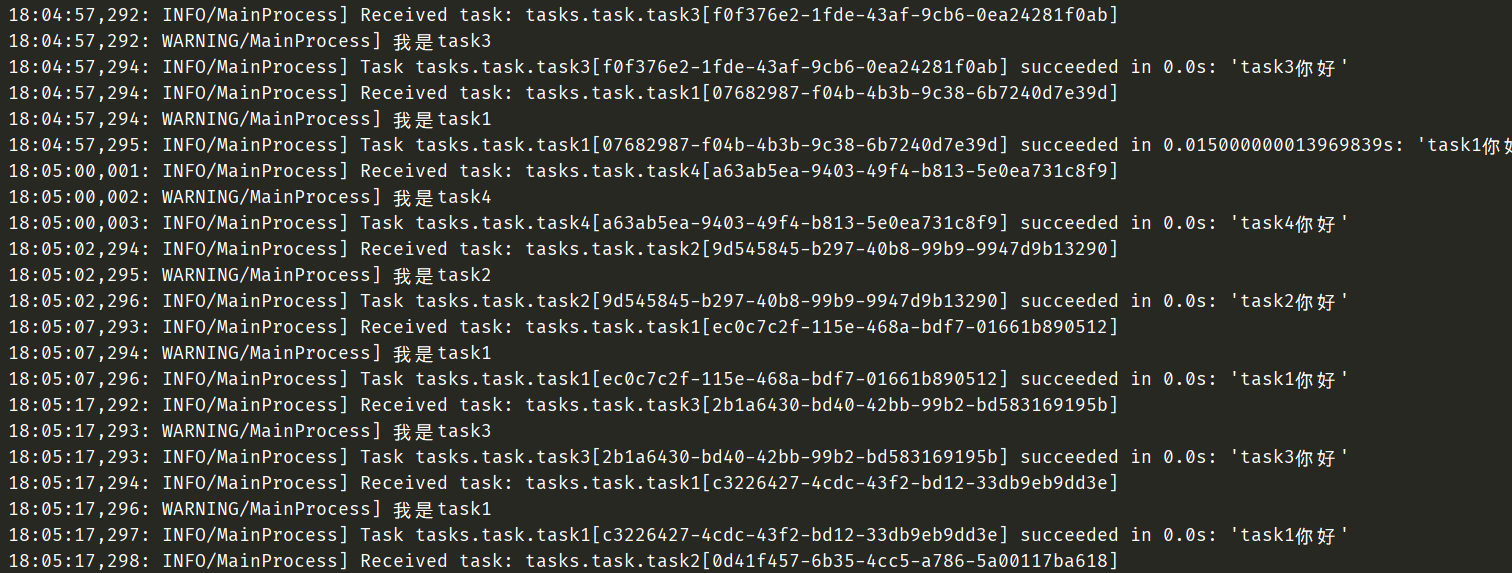
可以看到,此时定时任务就正常的启动了。另外我们刚才是通过设置函数、打上装饰器的方式实现的,我们还可以通过配置的方式实现
from celery.schedules import crontab
from app import app
from .task import task1, task2, task3, task4
# @app.on_after_configure.connect
# def aaa(sender, **kwargs):
# sender.add_periodic_task(10.0, task1.s(), name="每10秒执行一次")
# sender.add_periodic_task(15.0, task2.s("task2"), name="每15秒执行一次")
# sender.add_periodic_task(20.0, task3.s(), name="每20秒执行一次")
# sender.add_periodic_task(
# crontab(hour=18, minute=5, day_of_week=0),
# task4.s("task4"),
# name="每个星期天的18:05运行一次"
# )
app.conf.beat_schedule = {
"每10秒执行一次": {"task": "task1", "schedule": 10.0},
"每15秒执行一次": {"task": "task2", "schedule": 15.0, "args": ("task2", )}, # 参数通过args和kwargs指定
"每20秒执行一次": {"task": "task3", "schedule": 20.0},
"每个星期天的18:05运行一次": {"task": "task4",
"schedule": crontab(hour=18, minute=5, day_of_week=0),
"args": ("task4", )}
}
# 上面定义定时任务的方式,可以下面配置的方式替代。
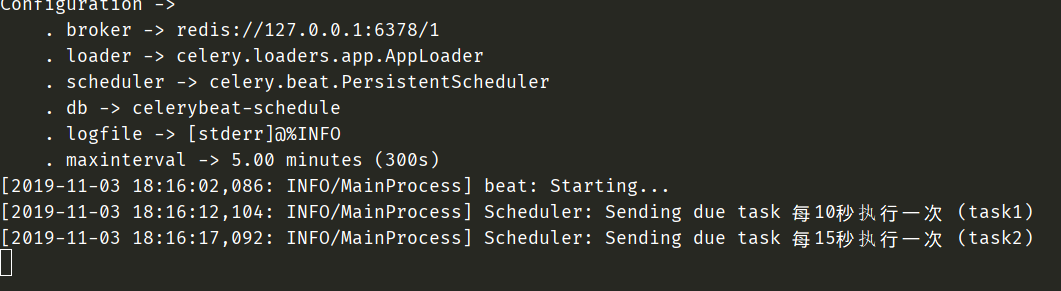
这种启动方式依旧是可以成功的。
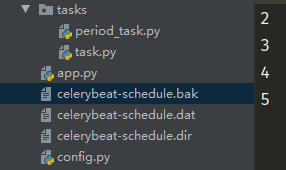
另外我们发现目录里面多了三个文件,这是存放有关定时任务信息的。
crontab参数
@python_2_unicode_compatible
class crontab(BaseSchedule):
def __init__(self, minute='*', hour='*', day_of_week='*',
day_of_month='*', month_of_year='*', **kwargs):
上面是crontab对应的初始化函数
minute:0-59,表示第几分钟触发,*表示每分钟触发一次hour:0-23,第几个小时触发,*表示每小时都会触发,比如:minute=2,hour=*,那么表示每小时的第二分钟触发一次day_of_week:一周的第几天,0-6,0是星期天,1-6分别是星期一到星期六,不习惯的话也可以用mon,tue,wed,thu,fri,sat,sun表示day_of_month:一个月的第几天month_of_year:当前年份的第几个月
通配符
*:所有,比如minute=*,表示每分钟触发*/a:所有可被a整除的时候触发a-b:a到b范围内触发a-b/c:范围a-b且能够被c整除的时候触发2,10,40:比如minute=2,10,40表示第2、10、40分钟的时候触发
通配符之间是可以自由组合的,比如'*/3,8-17'就表示能被3整除,且范围处于8-17的时候触发。
天色
是的,你没有看错,还可以根据天色来设置定时任务
from celery.schedules import solar
app.conf.beat_schedule = {
"日落": {"task": "task1",
"schedule": solar("sunset", -37.81753, 144.96715)
},
}
solor里面接收三个参数:
event
dawn_astronomical:天还未亮的时候,太阳在地平线下18度dawn_nautical:地平线有充足的阳光并且可以看清一些东西,太阳在地平线下12度dawn_civil:有充足的阳光并且可以看清东西、开始户外活动,太阳在地平线下6度sunrise:太阳的上边缘,出现在东方地平线上solar_noon:一天中太阳距离地平线最高的位置sunset:傍晚太阳的上边缘消失在西方地平线上dusk_civil:黄昏的尽头,还能看得见东西,太阳在地平线下6度dusk_nautical:已看不清东西,太阳在地平线下12度dusk_astronomical:天完全黑的时候,太阳在地平线下18度
lat:纬度
大于0:南纬小于0:北纬
lon:经度
大于0:东经小于0:西经
celery的常用配置
BROKER_URL:broker的url,在celery4.0之前叫做CELERY_BROKER_URL
BROKER_URL = 'redis://username:passwd@host:port/db'CELERY_RESULT_BACKEND:结果的接收地址
CELERY_RESULT_BACKEND = 'redis://username:passwd@host:port/db'CELERY_TASK_SERIALIZER :指定任务的序列化方式
CELERY_TASK_SERIALIZER = 'msgpack'CELERY_TASK_RESULT_EXPIRES :任务过期时间,任务在规定时间之前没有被执行,那么取消
CELERY_TASK_RESULT_EXPIRES = 60 * 20CELERY_ACCEPT_CONTENT :指定任务接收的序列化类型
CELERY_ACCEPT_CONTENT = ["msgpack"]CELERY_ACKS_LATE:任务发送完成后是否需要确认,对性能会有影响
CELERY_ACKS_LATE = TrueCELERY_MESSAGE_COMPRESSION :压缩方案选择,可以是zlib, bzip2,默认是发送没有压缩的数据
CELERY_MESSAGE_COMPRESSION = 'zlib'CELERYD_TASK_TIME_LIMIT:规定任务的完成时间
CELERYD_TASK_TIME_LIMIT = 5,5s内必须完成,否则执行该任务的worker会被杀死CELERYD_CONCURRENCY :celery worker的并发数,默认是服务器的内核数目,也是命令行-c参数指定的数目
CELERYD_CONCURRENCY = 8CELERYD_PREFETCH_MULTIPLIER :celery worker每次去队列领取任务的数量
CELERYD_PREFETCH_MULTIPLIER = 4CELERYD_MAX_TASKS_PER_CHILD :每个worker最多能执行多少个任务,超过之后就会死掉。默认是无限的
CELERYD_MAX_TASKS_PER_CHILD = 40CELERY_DEFAULT_QUEUE :设置默认的队列名称,如果一个消息不符合其他的队列就会放在默认队列里面,如果什么都不设置的话,数据都会发送到默认的队列中
CELERY_QUEUES :设置详细的队列
CELERY_QUEUES = {
"default": { # 这是上面指定的默认队列
"exchange": "default",
"exchange_type": "direct",
"routing_key": "default"
},
"topicqueue": { # 这是一个topic队列 凡是topictest开头的routing key都会被放到这个队列
"routing_key": "topic.#",
"exchange": "topic_exchange",
"exchange_type": "topic",
},
"task_eeg": { # 设置扇形交换机
"exchange": "tasks",
"exchange_type": "fanout",
"binding_key": "tasks",
},
}
CELERY_ENABLE_UTC:celery默认是使用utc时间,我们需要禁用掉,不是用utc
CELERY_ENABLE_UTC = FalseCELERY_TIMEZONE:时区,既然禁用了utc时区,我们最好指定一个
CELERY_TIMEZONE = 'Asia/Shanghai'
celery:强大的定时任务模块的更多相关文章
- Django与Celery配合实现定时任务
一.前言 Celery是一个基于python开发的分布式任务队列,而做python WEB开发最为流行的框架莫属Django,但是Django的请求处理过程都是同步的无法实现异步任务,若要实现异步任务 ...
- Celery学习--- Celery操作之定时任务
celery支持定时任务,设定好任务的执行时间,celery就会定时自动帮你执行, 这个定时任务模块叫celery beat 文件定时执行任务 项目前提: 安装并启动Redis celery_Sche ...
- Django+Celery框架自动化定时任务开发
本章介绍使用DjCelery即Django+Celery框架开发定时任务功能,在Autotestplat平台上实现单一接口自动化测试脚本.业务场景接口自动化测试脚本.App自动化测试脚本.Web自动化 ...
- ansible定时任务模块和用户组模块使用
接上篇,还是一些基础模块的使用,这里主要介绍的是系统模块的使用. 下面例子都进行过相关的实践,从而可以直接进行使用相关的命令. 3.用户模块的使用 用户模块主要用来管理用户账号和用户的属性(对远程主机 ...
- 比ngx_http_substitutions_filter_module 更强大的替换模块sregex的replace-filter-nginx-module
之前写过nginx反代替换的教程(传送门),使用了ngx_http_substitutions_filter_module模块.不过这货只能替换同一行,具有局限性-_-# 现在一个更强大的替换模块来了 ...
- Go 的定时任务模块 Cron 使用
前言 新项目是Golang作为开发语言, 遇到了些新的坑, 也学到了新的知识, 收获颇丰 本章介绍在Go中使用Cron定时任务模块来实现逻辑 正文 在项目中, 我们往往需要定时执行一些逻辑, 举个例子 ...
- Celery 异步任务 , 定时任务 , 周期任务 的芹菜
1.什么是Celery?Celery 是芹菜Celery 是基于Python实现的模块, 用于执行异步定时周期任务的其结构的组成是由 1.用户任务 app 2.管道 broker 用于存储 ...
- Django搭配Celery进行异步/定时任务(一)初步搭建
以下需求场景很常见: 1. 用户点击页面按钮,请求后台进行一系列耗时非常高的操作,页面没有响应/一直Loading,用户体验非常不好. 2. 某些数据需要预先处理,每天凌晨的时候进行运算,大约半小时到 ...
- Celery - 异步任务 , 定时任务 , 周期任务
1.什么是Celery?Celery 是芹菜Celery 是基于Python实现的模块, 用于执行异步定时周期任务的其结构的组成是由 1.用户任务 app 2.管道 broker 用于存储 ...
随机推荐
- vue计算属性VS侦听属性
原文地址 Vue 提供了一种更通用的方式来观察和响应 Vue 实例上的数据变动:侦听属性.当你有一些数据需要随着其它数据变动而变动时,你很容易滥用 watch——特别是如果你之前使用过 Angular ...
- Linux(CentOS)下安装tesseract-ocr以及配置依赖leptonica
下载 wget https://github.com/tesseract-ocr/tesseract/archive/4.1.0.tar.gz wget http://www.leptonica.or ...
- C#作业系统提示和故障排除
使用Unity C#作业系统时,请确保遵守以下内容: 不要从作业访问静态数据 从作业访问静态数据会绕过所有安全系统.如果您访问错误的数据,您可能会以意想不到的方式崩溃Unity.例如,访问MonoBe ...
- mysql数据库设计字符类型及长度
1.数字类型 小数的我就不聊了,因为有小数点的一般都是用字符串保存.关于整数,有几种可以选TINYINT.SMALLINT.MEDIUMINT.INT和BIGINT,分别占1.2.4.8字节.如果无符 ...
- position: sticky 防坑指南
position: sticky 防坑指南:https://www.jianshu.com/p/e217905e8b87 今天在写小程序项目的时候碰到一个需求是要把轮播图下面的标签栏滑动到顶部后固定, ...
- PAT B1036 跟奥巴马一起编程 (15)
AC代码 #include <cstdio> using namespace std; int main(){ int n = 0, m = 0; char a; scanf(" ...
- php 合成图片,合成圆形图片
合成图片方法 <?php class Share { /* * 生成分享图片 * */ function cre_share_study_img(){ $auth = json_decode(b ...
- laravel框架之自帶登錄&註冊
//控制器層 <?php namespace App\Http\Controllers\admin; use App\Models\admin\Users; use Illuminate\Htt ...
- 在 jupyterlab 和 jupyter notebook 中集成conda虚拟环境
在jupyterlab中切换虚拟环境使用jupyter-conda包,参考链接:https://pypi.org/project/jupyter-conda/ Install Requirements ...
- less的引用及公共变量的抽离
一.什么是less? less是什么自然不用多言,乃一个css预编译器,可以扩展css语言,添加功能如如允许变量(variables),混合(mixins),函数(functions) 和许多其他的技 ...