Java进阶(五)Java I/O模型从BIO到NIO和Reactor模式
Java I/O模型
同步 vs. 异步
同步I/O 每个请求必须逐个地被处理,一个请求的处理会导致整个流程的暂时等待,这些事件无法并发地执行。用户线程发起I/O请求后需要等待或者轮询内核I/O操作完成后才能继续执行。
异步I/O 多个请求可以并发地执行,一个请求或者任务的执行不会导致整个流程的暂时等待。用户线程发起I/O请求后仍然继续执行,当内核I/O操作完成后会通知用户线程,或者调用用户线程注册的回调函数。
阻塞 vs. 非阻塞
阻塞 某个请求发出后,由于该请求操作需要的条件不满足,请求操作一直阻塞,不会返回,直到条件满足。
非阻塞 请求发出后,若该请求需要的条件不满足,则立即返回一个标志信息告知条件不满足,而不会一直等待。一般需要通过循环判断请求条件是否满足来获取请求结果。
需要注意的是,阻塞并不等价于同步,而非阻塞并非等价于异步。事实上这两组概念描述的是I/O模型中的两个不同维度。
同步和异步着重点在于多个任务执行过程中,后发起的任务是否必须等先发起的任务完成之后再进行。而不管先发起的任务请求是阻塞等待完成,还是立即返回通过循环等待请求成功。
而阻塞和非阻塞重点在于请求的方法是否立即返回(或者说是否在条件不满足时被阻塞)。
Unix下五种I/O模型
Unix 下共有五种 I/O 模型:
- 阻塞 I/O
- 非阻塞 I/O
- I/O 多路复用(select和poll)
- 信号驱动 I/O(SIGIO)
- 异步 I/O(Posix.1的aio_系列函数)
阻塞I/O
如上文所述,阻塞I/O下请求无法立即完成则保持阻塞。阻塞I/O分为如下两个阶段。
- 阶段1:等待数据就绪。网络 I/O 的情况就是等待远端数据陆续抵达;磁盘I/O的情况就是等待磁盘数据从磁盘上读取到内核态内存中。
- 阶段2:数据拷贝。出于系统安全,用户态的程序没有权限直接读取内核态内存,因此内核负责把内核态内存中的数据拷贝一份到用户态内存中。
非阻塞I/O
非阻塞I/O请求包含如下三个阶段
- socket设置为 NONBLOCK(非阻塞)就是告诉内核,当所请求的I/O操作无法完成时,不要将线程睡眠,而是返回一个错误码(EWOULDBLOCK) ,这样请求就不会阻塞。
- I/O操作函数将不断的测试数据是否已经准备好,如果没有准备好,继续测试,直到数据准备好为止。整个I/O 请求的过程中,虽然用户线程每次发起I/O请求后可以立即返回,但是为了等到数据,仍需要不断地轮询、重复请求,消耗了大量的 CPU 的资源。
- 数据准备好了,从内核拷贝到用户空间。
一般很少直接使用这种模型,而是在其他I/O模型中使用非阻塞I/O 这一特性。这种方式对单个I/O 请求意义不大,但给I/O多路复用提供了条件。
I/O多路复用(异步阻塞 I/O)
I/O多路复用会用到select或者poll函数,这两个函数也会使线程阻塞,但是和阻塞I/O所不同的是,这两个函数可以同时阻塞多个I/O操作。而且可以同时对多个读操作,多个写操作的I/O函数进行检测,直到有数据可读或可写时,才真正调用I/O操作函数。
从流程上来看,使用select函数进行I/O请求和同步阻塞模型没有太大的区别,甚至还多了添加监视Channel,以及调用select函数的额外操作,增加了额外工作。但是,使用 select以后最大的优势是用户可以在一个线程内同时处理多个Channel的I/O请求。用户可以注册多个Channel,然后不断地调用select读取被激活的Channel,即可达到在同一个线程内同时处理多个I/O请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
调用select/poll该方法由一个用户态线程负责轮询多个Channel,直到某个阶段1的数据就绪,再通知实际的用户线程执行阶段2的拷贝。 通过一个专职的用户态线程执行非阻塞I/O轮询,模拟实现了阶段一的异步化。
信号驱动I/O(SIGIO)
首先我们允许socket进行信号驱动I/O,并安装一个信号处理函数,线程继续运行并不阻塞。当数据准备好时,线程会收到一个SIGIO 信号,可以在信号处理函数中调用I/O操作函数处理数据。
异步I/O
调用aio_read 函数,告诉内核描述字,缓冲区指针,缓冲区大小,文件偏移以及通知的方式,然后立即返回。当内核将数据拷贝到缓冲区后,再通知应用程序。所以异步I/O模式下,阶段1和阶段2全部由内核完成,完成不需要用户线程的参与。
几种I/O模型对比
除异步I/O外,其它四种模型的阶段2基本相同,都是从内核态拷贝数据到用户态。区别在于阶段1不同。前四种都属于同步I/O。
Java中四种I/O模型
上一章所述Unix中的五种I/O模型,除信号驱动I/O外,Java对其它四种I/O模型都有所支持。其中Java最早提供的blocking I/O即是阻塞I/O,而NIO即是非阻塞I/O,同时通过NIO实现的Reactor模式即是I/O复用模型的实现,通过AIO实现的Proactor模式即是异步I/O模型的实现。
从IO到NIO
面向流 vs. 面向缓冲
Java IO是面向流的,每次从流(InputStream/OutputStream)中读一个或多个字节,直到读取完所有字节,它们没有被缓存在任何地方。另外,它不能前后移动流中的数据,如需前后移动处理,需要先将其缓存至一个缓冲区。
Java NIO面向缓冲,数据会被读取到一个缓冲区,需要时可以在缓冲区中前后移动处理,这增加了处理过程的灵活性。但与此同时在处理缓冲区前需要检查该缓冲区中是否包含有所需要处理的数据,并需要确保更多数据读入缓冲区时,不会覆盖缓冲区内尚未处理的数据。
阻塞 vs. 非阻塞
Java IO的各种流是阻塞的。当某个线程调用read()或write()方法时,该线程被阻塞,直到有数据被读取到或者数据完全写入。阻塞期间该线程无法处理任何其它事情。
Java NIO为非阻塞模式。读写请求并不会阻塞当前线程,在数据可读/写前当前线程可以继续做其它事情,所以一个单独的线程可以管理多个输入和输出通道。
选择器(Selector)
Java NIO的选择器允许一个单独的线程同时监视多个通道,可以注册多个通道到同一个选择器上,然后使用一个单独的线程来“选择”已经就绪的通道。这种“选择”机制为一个单独线程管理多个通道提供了可能。
零拷贝
Java NIO中提供的FileChannel拥有transferTo和transferFrom两个方法,可直接把FileChannel中的数据拷贝到另外一个Channel,或者直接把另外一个Channel中的数据拷贝到FileChannel。该接口常被用于高效的网络/文件者数据传输和大文件拷贝。在操作系统支持的情况下,通过该方法传输数据并不需要将源数据从内核态拷贝到用户态,再从用户态拷贝到目标通道的内核态,同时也避免了两次用户态和内核态间的上下文切换,也即使用了“零拷贝”,所以其性能一般高于Java IO中提供的方法。
使用FileChannel的零拷贝将本地文件内容传输到网络的示例代码如下所示。
public class NIOClient {
public static void main(String[] args) throws IOException, InterruptedException {
SocketChannel socketChannel = SocketChannel.open();
InetSocketAddress address = new InetSocketAddress(1234);
socketChannel.connect(address);
RandomAccessFile file = new RandomAccessFile(
NIOClient.class.getClassLoader().getResource("test.txt").getFile(), "rw");
FileChannel channel = file.getChannel();
channel.transferTo(0, channel.size(), socketChannel);
channel.close();
file.close();
socketChannel.close();
}
}
阻塞I/O下的服务器实现
单线程逐个处理所有请求
使用阻塞I/O的服务器,一般使用循环,逐个接受连接请求并读取数据,然后处理下一个请求。
public class IOServer {
private static final Logger LOGGER = LoggerFactory.getLogger(IOServer.class);
public static void main(String[] args) {
ServerSocket serverSocket = null;
try {
serverSocket = new ServerSocket();
serverSocket.bind(new InetSocketAddress(2345));
} catch (IOException ex) {
LOGGER.error("Listen failed", ex);
return;
}
try{
while(true) {
Socket socket = serverSocket.accept();
InputStream inputstream = socket.getInputStream();
LOGGER.info("Received message {}", IOUtils.toString(new InputStreamReader(inputstream)));
}
} catch(IOException ex) {
try {
serverSocket.close();
} catch (IOException e) {
}
LOGGER.error("Read message failed", ex);
}
}
}
为每个请求创建一个线程
上例使用单线程逐个处理所有请求,同一时间只能处理一个请求,等待I/O的过程浪费大量CPU资源,同时无法充分使用多CPU的优势。下面是使用多线程对阻塞I/O模型的改进。一个连接建立成功后,创建一个单独的线程处理其I/O操作。
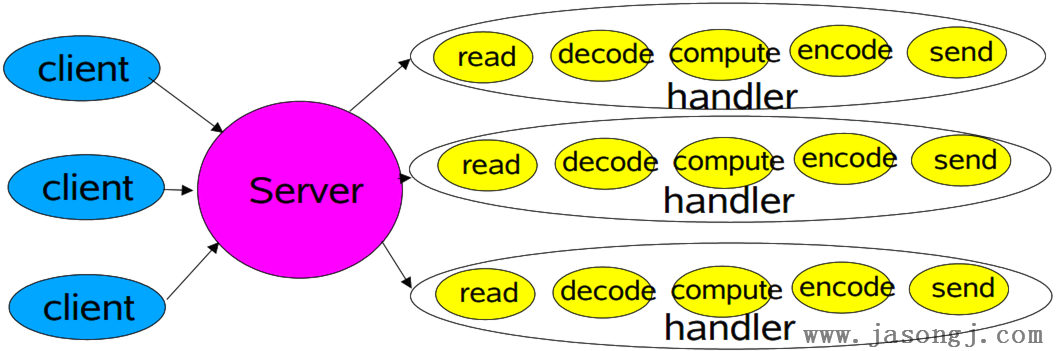
public class IOServerMultiThread {
private static final Logger LOGGER = LoggerFactory.getLogger(IOServerMultiThread.class);
public static void main(String[] args) {
ServerSocket serverSocket = null;
try {
serverSocket = new ServerSocket();
serverSocket.bind(new InetSocketAddress(2345));
} catch (IOException ex) {
LOGGER.error("Listen failed", ex);
return;
}
try{
while(true) {
Socket socket = serverSocket.accept();
new Thread( () -> {
try{
InputStream inputstream = socket.getInputStream();
LOGGER.info("Received message {}", IOUtils.toString(new InputStreamReader(inputstream)));
} catch (IOException ex) {
LOGGER.error("Read message failed", ex);
}
}).start();
}
} catch(IOException ex) {
try {
serverSocket.close();
} catch (IOException e) {
}
LOGGER.error("Accept connection failed", ex);
}
}
}
使用线程池处理请求
为了防止连接请求过多,导致服务器创建的线程数过多,造成过多线程上下文切换的开销。可以通过线程池来限制创建的线程数,如下所示。
public class IOServerThreadPool {
private static final Logger LOGGER = LoggerFactory.getLogger(IOServerThreadPool.class);
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
ServerSocket serverSocket = null;
try {
serverSocket = new ServerSocket();
serverSocket.bind(new InetSocketAddress(2345));
} catch (IOException ex) {
LOGGER.error("Listen failed", ex);
return;
}
try{
while(true) {
Socket socket = serverSocket.accept();
executorService.submit(() -> {
try{
InputStream inputstream = socket.getInputStream();
LOGGER.info("Received message {}", IOUtils.toString(new InputStreamReader(inputstream)));
} catch (IOException ex) {
LOGGER.error("Read message failed", ex);
}
});
}
} catch(IOException ex) {
try {
serverSocket.close();
} catch (IOException e) {
}
LOGGER.error("Accept connection failed", ex);
}
}
}
Reactor模式
精典Reactor模式
精典的Reactor模式示意图如下所示。
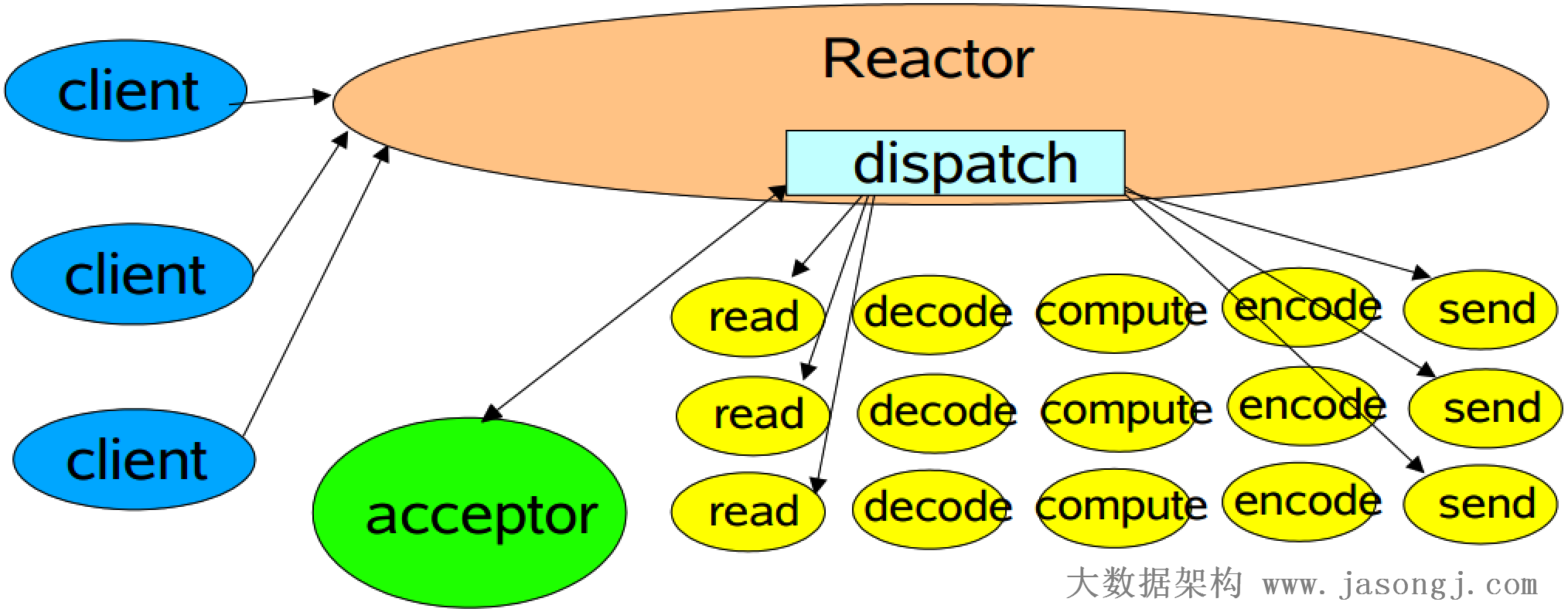
在Reactor模式中,包含如下角色
- Reactor 将I/O事件发派给对应的Handler
- Acceptor 处理客户端连接请求
- Handlers 执行非阻塞读/写
最简单的Reactor模式实现代码如下所示。
public class NIOServer {
private static final Logger LOGGER = LoggerFactory.getLogger(NIOServer.class);
public static void main(String[] args) throws IOException {
Selector selector = Selector.open();
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.configureBlocking(false);
serverSocketChannel.bind(new InetSocketAddress(1234));
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
while (selector.select() > 0) {
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> iterator = keys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
if (key.isAcceptable()) {
ServerSocketChannel acceptServerSocketChannel = (ServerSocketChannel) key.channel();
SocketChannel socketChannel = acceptServerSocketChannel.accept();
socketChannel.configureBlocking(false);
LOGGER.info("Accept request from {}", socketChannel.getRemoteAddress());
socketChannel.register(selector, SelectionKey.OP_READ);
} else if (key.isReadable()) {
SocketChannel socketChannel = (SocketChannel) key.channel();
ByteBuffer buffer = ByteBuffer.allocate(1024);
int count = socketChannel.read(buffer);
if (count <= 0) {
socketChannel.close();
key.cancel();
LOGGER.info("Received invalide data, close the connection");
continue;
}
LOGGER.info("Received message {}", new String(buffer.array()));
}
keys.remove(key);
}
}
}
}
为了方便阅读,上示代码将Reactor模式中的所有角色放在了一个类中。
从上示代码中可以看到,多个Channel可以注册到同一个Selector对象上,实现了一个线程同时监控多个请求状态(Channel)。同时注册时需要指定它所关注的事件,例如上示代码中socketServerChannel对象只注册了OP_ACCEPT事件,而socketChannel对象只注册了OP_READ事件。
selector.select()是阻塞的,当有至少一个通道可用时该方法返回可用通道个数。同时该方法只捕获Channel注册时指定的所关注的事件。
多工作线程Reactor模式
经典Reactor模式中,尽管一个线程可同时监控多个请求(Channel),但是所有读/写请求以及对新连接请求的处理都在同一个线程中处理,无想充分利用多CPU的优势,同时读/写操作也会阻塞对新连接请求的处理。因此可以引入多线程,并行处理多个读/写操作,如下图所示。
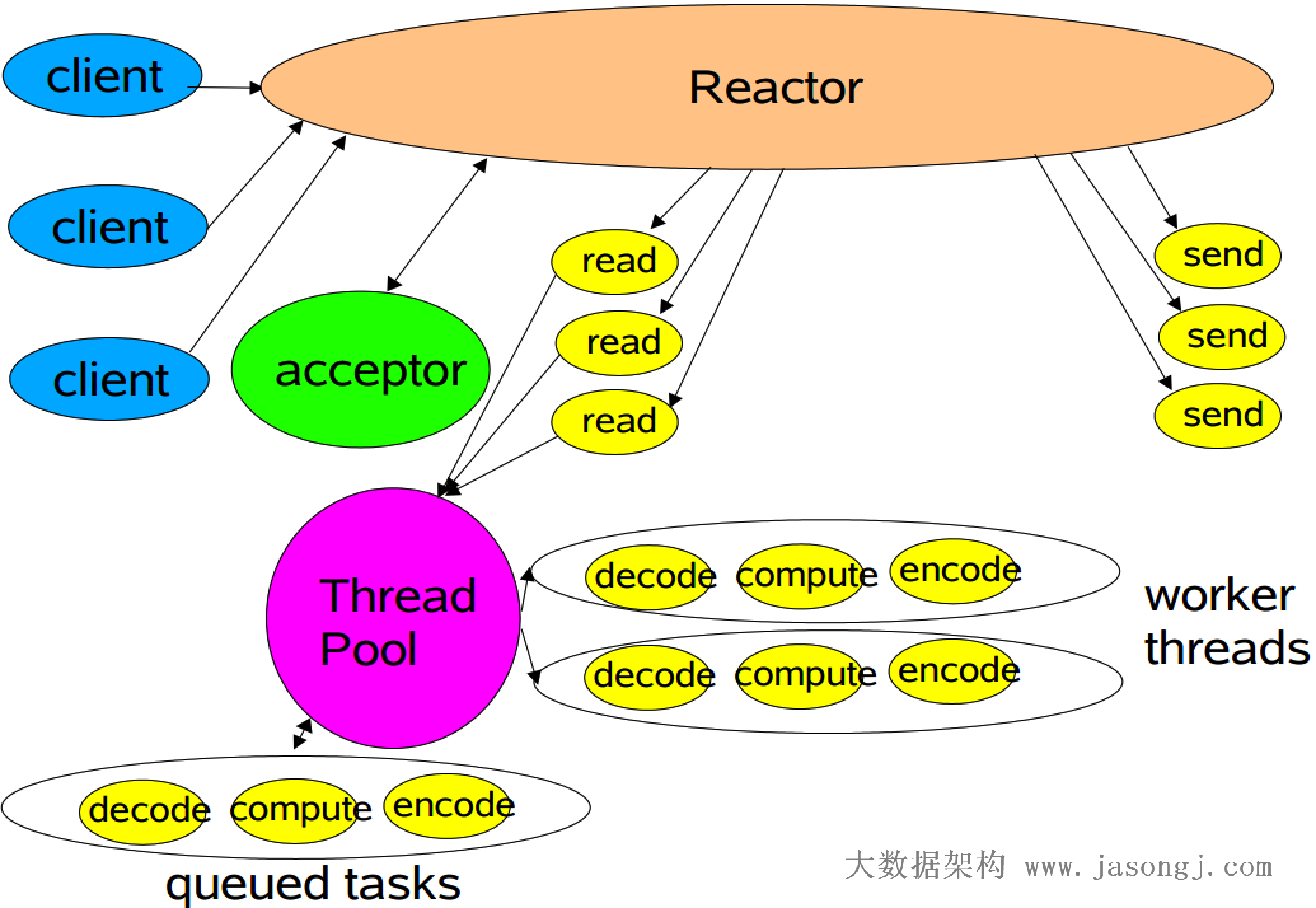
多线程Reactor模式示例代码如下所示。
public class NIOServer {
private static final Logger LOGGER = LoggerFactory.getLogger(NIOServer.class);
public static void main(String[] args) throws IOException {
Selector selector = Selector.open();
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.configureBlocking(false);
serverSocketChannel.bind(new InetSocketAddress(1234));
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
if(selector.selectNow() < 0) {
continue;
}
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> iterator = keys.iterator();
while(iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
if (key.isAcceptable()) {
ServerSocketChannel acceptServerSocketChannel = (ServerSocketChannel) key.channel();
SocketChannel socketChannel = acceptServerSocketChannel.accept();
socketChannel.configureBlocking(false);
LOGGER.info("Accept request from {}", socketChannel.getRemoteAddress());
SelectionKey readKey = socketChannel.register(selector, SelectionKey.OP_READ);
readKey.attach(new Processor());
} else if (key.isReadable()) {
Processor processor = (Processor) key.attachment();
processor.process(key);
}
}
}
}
}
从上示代码中可以看到,注册完SocketChannel的OP_READ事件后,可以对相应的SelectionKey attach一个对象(本例中attach了一个Processor对象,该对象处理读请求),并且在获取到可读事件后,可以取出该对象。
注:attach对象及取出该对象是NIO提供的一种操作,但该操作并非Reactor模式的必要操作,本文使用它,只是为了方便演示NIO的接口。
具体的读请求处理在如下所示的Processor类中。该类中设置了一个静态的线程池处理所有请求。而process方法并不直接处理I/O请求,而是把该I/O操作提交给上述线程池去处理,这样就充分利用了多线程的优势,同时将对新连接的处理和读/写操作的处理放在了不同的线程中,读/写操作不再阻塞对新连接请求的处理。
public class Processor {
private static final Logger LOGGER = LoggerFactory.getLogger(Processor.class);
private static final ExecutorService service = Executors.newFixedThreadPool(16);
public void process(SelectionKey selectionKey) {
service.submit(() -> {
ByteBuffer buffer = ByteBuffer.allocate(1024);
SocketChannel socketChannel = (SocketChannel) selectionKey.channel();
int count = socketChannel.read(buffer);
if (count < 0) {
socketChannel.close();
selectionKey.cancel();
LOGGER.info("{}\t Read ended", socketChannel);
return null;
} else if(count == 0) {
return null;
}
LOGGER.info("{}\t Read message {}", socketChannel, new String(buffer.array()));
return null;
});
}
}
多Reactor
Netty中使用的Reactor模式,引入了多Reactor,也即一个主Reactor负责监控所有的连接请求,多个子Reactor负责监控并处理读/写请求,减轻了主Reactor的压力,降低了主Reactor压力太大而造成的延迟。
并且每个子Reactor分别属于一个独立的线程,每个成功连接后的Channel的所有操作由同一个线程处理。这样保证了同一请求的所有状态和上下文在同一个线程中,避免了不必要的上下文切换,同时也方便了监控请求响应状态。
多Reactor模式示意图如下所示。
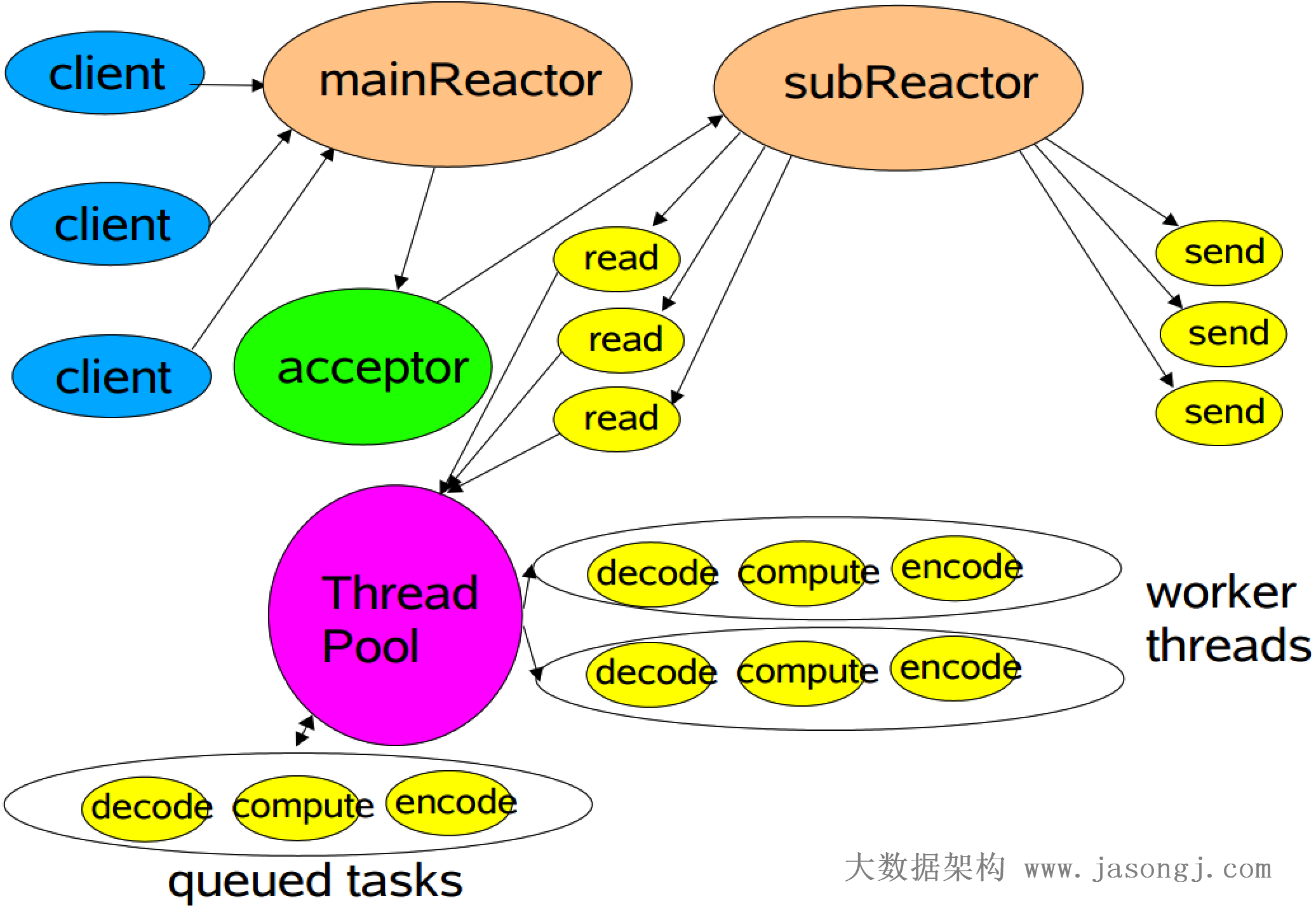
多Reactor示例代码如下所示。
public class NIOServer {
private static final Logger LOGGER = LoggerFactory.getLogger(NIOServer.class);
public static void main(String[] args) throws IOException {
Selector selector = Selector.open();
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.configureBlocking(false);
serverSocketChannel.bind(new InetSocketAddress(1234));
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
int coreNum = Runtime.getRuntime().availableProcessors();
Processor[] processors = new Processor[coreNum];
for (int i = 0; i < processors.length; i++) {
processors[i] = new Processor();
}
int index = 0;
while (selector.select() > 0) {
Set<SelectionKey> keys = selector.selectedKeys();
for (SelectionKey key : keys) {
keys.remove(key);
if (key.isAcceptable()) {
ServerSocketChannel acceptServerSocketChannel = (ServerSocketChannel) key.channel();
SocketChannel socketChannel = acceptServerSocketChannel.accept();
socketChannel.configureBlocking(false);
LOGGER.info("Accept request from {}", socketChannel.getRemoteAddress());
Processor processor = processors[(int) ((index++) / coreNum)];
processor.addChannel(socketChannel);
}
}
}
}
}
如上代码所示,本文设置的子Reactor个数是当前机器可用核数的两倍(与Netty默认的子Reactor个数一致)。对于每个成功连接的SocketChannel,通过round robin的方式交给不同的子Reactor。
子Reactor对SocketChannel的处理如下所示。
public class Processor {
private static final Logger LOGGER = LoggerFactory.getLogger(Processor.class);
private static final ExecutorService service =
Executors.newFixedThreadPool(2 * Runtime.getRuntime().availableProcessors());
private Selector selector;
public Processor() throws IOException {
this.selector = SelectorProvider.provider().openSelector();
start();
}
public void addChannel(SocketChannel socketChannel) throws ClosedChannelException {
socketChannel.register(this.selector, SelectionKey.OP_READ);
}
public void start() {
service.submit(() -> {
while (true) {
if (selector.selectNow() <= 0) {
continue;
}
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> iterator = keys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
if (key.isReadable()) {
ByteBuffer buffer = ByteBuffer.allocate(1024);
SocketChannel socketChannel = (SocketChannel) key.channel();
int count = socketChannel.read(buffer);
if (count < 0) {
socketChannel.close();
key.cancel();
LOGGER.info("{}\t Read ended", socketChannel);
continue;
} else if (count == 0) {
LOGGER.info("{}\t Message size is 0", socketChannel);
continue;
} else {
LOGGER.info("{}\t Read message {}", socketChannel, new String(buffer.array()));
}
}
}
}
});
}
}
在Processor中,同样创建了一个静态的线程池,且线程池的大小为机器核数的两倍。每个Processor实例均包含一个Selector实例。同时每次获取Processor实例时均提交一个任务到该线程池,并且该任务正常情况下一直循环处理,不会停止。而提交给该Processor的SocketChannel通过在其Selector注册事件,加入到相应的任务中。由此实现了每个子Reactor包含一个Selector对象,并由一个独立的线程处理。
Java进阶系列
- Java进阶(一)Annotation(注解)
- Java进阶(二)当我们说线程安全时,到底在说什么
- Java进阶(三)多线程开发关键技术
- Java进阶(四)线程间通信方式对比
- Java进阶(五)NIO和Reactor模式进阶
Java进阶(五)Java I/O模型从BIO到NIO和Reactor模式的更多相关文章
- Java I/O模型从BIO到NIO和Reactor模式(转)
原创文章,转载请务必将下面这段话置于文章开头处(保留超链接).本文转发自技术世界,原文链接 http://www.jasongj.com/java/nio_reactor/ Java I/O模型 同步 ...
- Java进阶(五十三)屡试不爽之正则表达式
Java进阶(五十三)屡试不爽之正则表达式 在线测试网址: http://tool.oschina.net/regex/# 上面的在线测试网址,含有正则表达式的生成,非常实用.大家共勉之! 匹配中文: ...
- Java进阶(五十一)Could not create the view: An unexpected exception was thrown
Java进阶(五十一)Could not create the view: An unexpected exception was thrown 今天打开Myeclipse10的时候,发现server ...
- Java进阶(五十一)必须记住的Myeclipse快捷键
Java进阶(五十一)必须记住的Myeclipse快捷键 在调试程序的时候,我们经常需要注释一些代码,在用Myeclipse编程时,就可以用 Ctrl+/ 为选中的一段代码加上以 // 打头的注释:当 ...
- Java进阶(五十二)利用LOG4J生成服务日志
Java进阶(五十二)利用LOG4J生成服务日志 前言 由于论文写作需求,需要进行流程挖掘.前提是需要有真实的事件日志数据.真实的事件日志数据可以用来发现.监控和提升业务流程. 为了获得真实的事件日志 ...
- Java IO模型:BIO、NIO、AIO
Java IO模型:BIO.NIO.AIO 本来是打算直接学习网络框架Netty的,但是先补充了一下自己对Java 几种IO模型的学习和理解.分别是 BIO.NIO.AIO三种IO模型. IO模型的基 ...
- I/O模型之四:Java 浅析I/O模型(BIO、NIO、AIO、Reactor、Proactor)
目录: <I/O模型之一:Unix的五种I/O模型> <I/O模型之二:Linux IO模式及 select.poll.epoll详解> <I/O模型之三:两种高性能 I ...
- Java进阶知识点5:服务端高并发的基石 - NIO与Reactor模式以及AIO与Proactor模式
一.背景 要提升服务器的并发处理能力,通常有两大方向的思路. 1.系统架构层面.比如负载均衡.多级缓存.单元化部署等等. 2.单节点优化层面.比如修复代码级别的性能Bug.JVM参数调优.IO优化等等 ...
- 【Java IO流】浅谈io,bio,nio,aio
本文转载自:http://www.cnblogs.com/doit8791/p/4951591.html 1.同步异步.阻塞非阻塞概念 同步和异步是针对应用程序和内核的交互而言的. 阻塞 ...
随机推荐
- Linux下安装Java环境配置步骤详述
0.下载jdk8 登录网址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html选择对 ...
- Viewport---响应式 Web 设计----在路上(13)
什么是 Viewport? viewport 是用户网页的可视区域. viewport 翻译为中文可以叫做"视区". 手机浏览器是把页面放在一个虚拟的"窗口"( ...
- JDK安装源码src和doc
(1)src 打开JDK的安装目录如(C:\Program Files\Java\jdk1.8.0_91)有一个src.zip的压缩文件,这个压缩文件里就是源码. mkdir src copy src ...
- 了解Package Configurations
使用VS2010创建的SSIS Project有两种deployment model:project deployment 和 package deployment,默认是Project deploy ...
- OpenCASCADE Quaternion
OpenCASCADE Quaternion eryar@163.com Abstract. The quaternions are members of a noncommutative divis ...
- Qt with OpenCascade
Qt with OpenCascade 摘要Abstract:详细介绍了如何在Qt中使用OpenCascade. 关键字Key Words:Qt.OpenCascade 一.引言 Introducti ...
- MVC5 网站开发实践 1、建立项目
目录 MVC5 网站开发实践 概述 一.建立项目 1.建立团队项目 在办公室和家里使用不同的电脑,为了方便代码的共享将项目建立为团队项目. 如图打开vs2013→新建→团队项目(图1),会自动 ...
- Why Namespace? - 每天5分钟玩转 OpenStack(102)
上一节我们讨论了 Neutron 将虚拟 router 放置到 namespace 中实现了不同 subnet 之间的路由.今天探讨为什么要用 namespace 封装 router? 回顾一下前面的 ...
- Create Volume 操作(Part I) - 每天5分钟玩转 OpenStack(50)
前面已经学习了 Cinder 的架构和相关组件,从本节我们开始详细分析 Cinder 的各种操作,首先讨论 Cinder 如何创建 volume. Create 操作流程如下: 客户(可以是 Open ...
- 延时调用--deferred.js原码分析
有些时候,我们需要等待上一个操作完成之后,才能进行下一步的操作.比如Ajax实现自动提交表单操作的时候,程序需要等待,一旦有返回结果了,则继续进行一下步操作. 这时deferred.js这个库就产生了 ...