论文阅读 | ERNIE: Enhanced Representation through Knowledge Integration
摘要
知识加强的语义表示模型。
knowledge masking strategies : entity-level masking / phrase-level masking 实体级别 和 短语级别
SOTA:5个中文NLP任务 NLI 语义相似性 命名实体识别 情感分析 QA
知识推理能力!
预训练模型: Cove Elmo GPT BERT XLNet
模型未考虑句子之前的知识。
ERNIE 在训练过程中学习实体和短语的先验知识。
ERNIE隐式地学习了关于知识和更长的语义依赖的信息,如实体之间的关系、实体的属性和事件的类型,以指导词嵌入学习。
这样可以使模型具有更好的泛化和适应性。
贡献如下:(1)我们引入了一种新的语言模型的学习过程,它掩盖了短语和实体等单元,以便从这些单元中隐式地学习句法和语义信息。(2) ERNIE在各种汉语自然语言处理任务上显著优于现有的方法。(3)我们发布了ERNIE和预培训模型的代码,可以在https://github.com/paddlepaddle/lark /tree/develop/ERNIE中找到。
相关工作
ULMFit (Howard and Ruder, 2018)提出了一种有效的转移学习方法,可以应用于NLP中的任何任务。ELMo (Peters et al., 2018)从不同的维度概括了传统的词嵌入研究。他们建议从语言模型中提取上下文相关的特性。GPT (Radford et al., 2018)通过调整变Transformer增强了上下文敏感的嵌入。
BERT (Devlin et al., 2018)使用两种不同的语言建模前训练任务。随机地在句子中隐藏一定比例的单词,并学会预测这些隐藏的单词。还学会了预测两个句子是否相邻。这个任务试图模拟两个句子之间的关系,这是传统语言模型所不能捕捉到的。因此,这种特殊的训练前方案帮助BERT在各种关键的NLP数据集(如GLUE (Wang et al., 2018)和SQUAD (Rajpurkar et al., 2016)等方面大大超过最先进的技术。
MT-DNN (Liu et al., 2019)将预训练学习和多任务学习相结合,以提高GLUE中多个不同任务的性能(Wang et al., 2018)。GPT-2 (Radford et al., 2019)将任务信息添加到预训练过程中,并将其模型调整为零射击任务。XLM (Lample和Conneau, 2019)将语言嵌入到训练前的过程中,从而在跨语言任务中获得更好的结果。
对异构非监督数据进行预处理的语义编码器可以提高传输学习性能。Universal sentence encoder (Cer等,2018)采用了来自Wikipedia、web news、web QA页面和讨论论坛的异构训练数据。句子编码器(Yang et al., 2018)基于从Reddit对话中提取的查询-响应对数据的响应预测。XLM (Lample和Conneau, 2019)将并行语料库引入BERT, 与掩码语言模型任务联合训练。通过对Transformer模型进行异构数据预处理,使XLM在监督/非监督MT任务和分类任务上获得了较好的性能提升。
方法
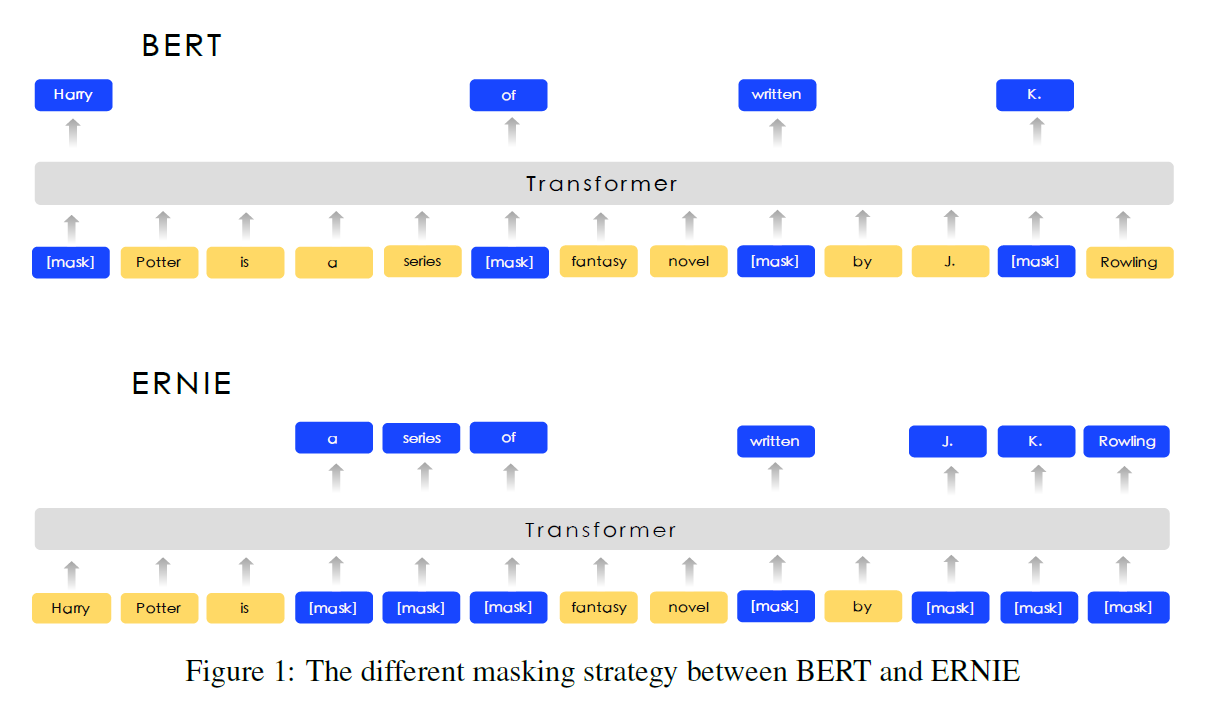
Transformer Encode
ERNIE使用多层Transformer(Vaswani et al., 2017)作为基础编码器,就像以前的预编译模型,如GPT, BERT和XLM。Transformer可以通过selfattention捕获句子中每个标记的上下文信息,并生成上下文嵌入序列。
对于中文语料库,我们在CJK Unicode范围内的每个字符周围添加空格,并使用单词(Wu et al., 2016)来标记中文句子。对于给定的令牌,其输入表示是通过将相应的令牌、段和位置嵌入token segment postion embedding相加来构造的。每个序列的第一个标记是特殊的分类嵌入([CLS])。
Knowledge Integration
我们使用先验知识来增强我们预先训练的语言模型。提出了一种多阶段的知识掩蔽策略,将短语和实体层次的知识融合到语言表达中,而不是直接增加知识的嵌入。图2描述了一种伪装的不同掩蔽水平。

Phrase-Level Masking: 对于英语,我们使用词汇分析和分块工具来获取句子中短语的边界,并使用一些语言相关的分割工具来获取其他语言(如汉语)中的单词/短语信息。
经过三阶段的学习,得到了由丰富的语义信息增强的词表示形式。
实验
为了便于比较,ERNIE被选择具有与BERT-base相同的模型大小。ERNIE使用12个编码器层,768个隐藏单位和12个注意力头。
异构语料库预训练
ERNIE采用异构语料库进行预处理。接下来(Cer等,2018),我们绘制了混合语料库汉语维基百科、百度百科、百度新闻和百度贴吧。句子的数量有21M, 51M, 47M, 54M。百度百科全书包含了用正式语言编写的百科全书文章,这是语言建模的强大基础。百度新闻提供关于电影名、演员名、足球队名等的最新信息。百度贴吧是一个类似于reddit的开放讨论论坛,在这里每个帖子都可以被看作是一个对话帖。我们的DLM任务中使用了贴吧语料库,下一节将对此进行讨论。
我们对汉字进行繁简转换,对英文字母进行大小写转换。我们的模型使用17964个unicode字符的共享词汇表。
DLM
对话数据对于语义表示非常重要,因为相同回复的对应查询语义通常是相似的。ERNIE在DLM(对话语言模型)任务上建模查询-响应对话结构。如图3所示,我们的方法引入了嵌入对话的方法来识别对话中的角色,不同于通用的句子编码器(Cer等,2018)。ERNIE的对话嵌入与在BERT中嵌入令牌类型的作用相同,只是ERNIE也可以表示多轮对话(如QRQ, QRR, QQR,其中Q和R分别代表查询和响应)。就像BERT中的MLM一样,mask应用于加强模型来预测基于查询和响应条件下的单词缺失。更重要的是,我们通过用随机选择的句子替换查询或响应来生成虚假样本。该模型旨在判断多回合对话是真实的还是虚假的。
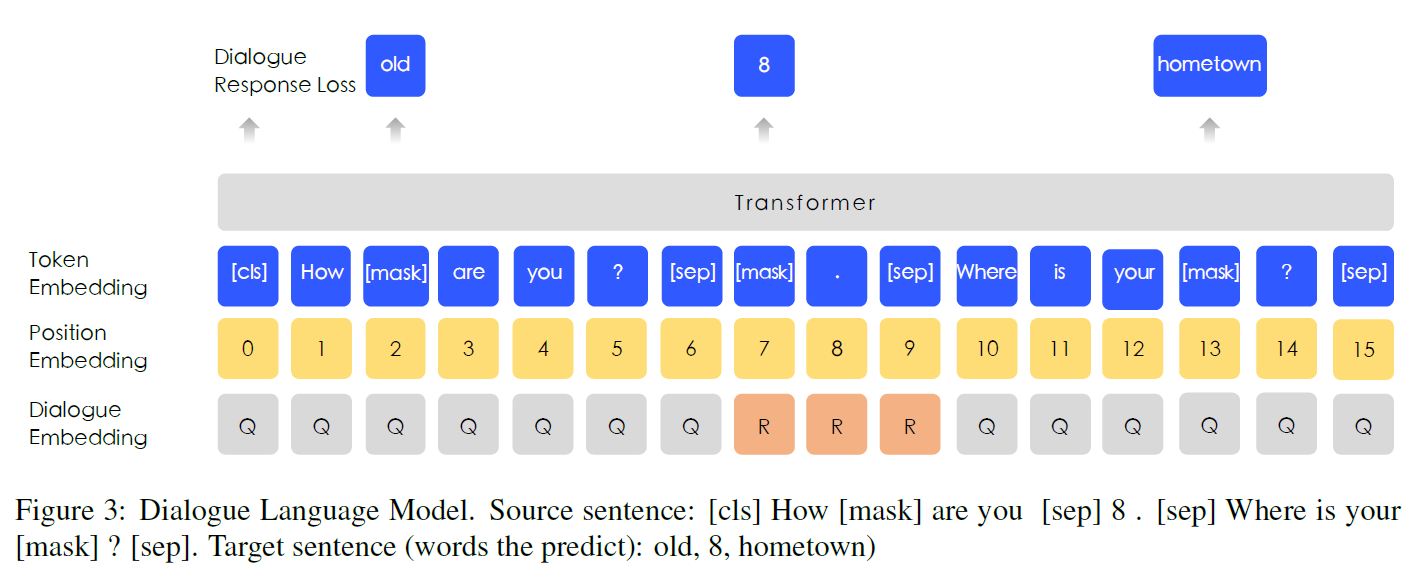
DLM任务帮助ERNIE学习对话中的im的关系,这也提高了模型学习语义表达的能力。DLM任务的模型体系结构与MLM任务的模型体系结构相兼容,从而与MLM任务交替进行再训练。
中文NLP任务实验
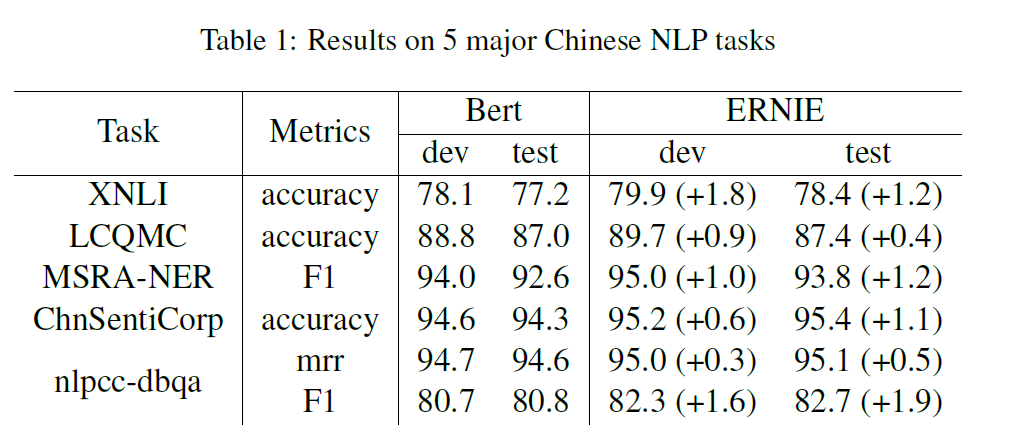
ERNIE被应用于5个中文NLP任务,包括自然语言推理、语义相似、命名实体识别、情感分析和问题回答。
NLU
跨语言自然语言推理(XNLI)语料库(Liu et al., 2019)是一个多语种语料库的众包集合。这些对子句附有注释,并被翻译成包括中文在内的14种语言。这些标签包含矛盾、中立和内涵。我们遵循BERT(Devlin et al., 2018)中的中文实验。
语义相似度
大型汉语问题匹配语料库(立法会mc) (Liu et al., 2018)旨在识别两个句子是否具有相同的意图。数据集中的每一对句子都与一个二进制标签相关联,该标签指示这两个句子是否具有相同的意图,并且可以将该任务形式化为预测一个二进制标签。
命名实体识别
MSRA-NER数据集是为命名实体识别而设计的,由Microsoft Research Asia发布。实体包含几种类型,包括人名、地名、组织名等等。这个任务可以看作是一个序列标记任务。
情感分析
ChnSentiCorp (Song-bo)是一个旨在判断句子感情的数据集。它包括酒店、书籍和电子计算机等多个领域的评论。这个任务的目的是判断句子是肯定的还是否定的。
检索问题回答
(http: //tcci.ccf.org.cn/conference/ 2016/dldoc/evagline2.pdf) nlpccdbqa数据集的目标是选择对应问题的答案。该数据集的评价方法包括MRR (Voorhees, 2001)和F1评分。
实验结果
消融学习
知识掩蔽效应策略
为了验证知识掩蔽策略的有效性,我们从整个系统中抽取了10%的训练数据作为样本。结果见表2. 可以看出,在基本字级掩码的基础上增加短语级掩码可以提高模型的性能。在此基础上,我们加入了实体级的掩蔽策略,进一步提高了模型的性能。此外。结果还表明,当训练前数据集的大小增加10倍时,XNLI测试集的性能提高了0.8%。

DLM
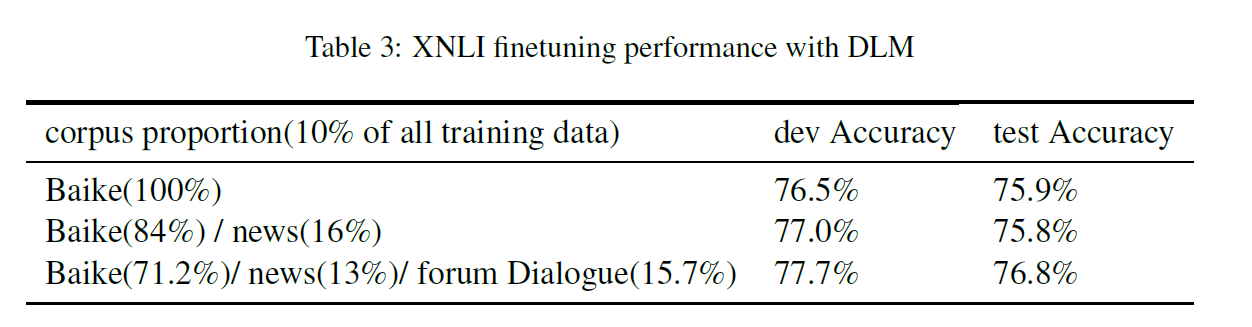
消融研究也在DLM任务中进行。我们使用了10%的不同比例的训练语料库来说明DLM任务在XNLI开发集上的贡献。我们在这些数据集上对ERNIE进行了从零开始的预训练,并报告了5次随机重新启动微调后XNLI任务的平均结果。具体的实验设置和开发集结果如表3所示,可以看出在这个DLM任务中,在开发/测试准确性方面实现了0.7%/1.0%的改进。
完形填空
为了验证ERNIE的知识学习能力,我们使用了几个完形填空测试样本(Taylor, 1953)来检验模型。在实验中,名称实体从段落中删除,模型需要推断它是什么。图4。在案例1中,BERT试图复制上下文中出现的名字,而ERNIE记住了文中提到的关于关系的知识。在案例2和案例5中,BERT可以根据上下文成功地学习模式,因此可以正确地预测指定的实体类型,但是不能用正确的实体填充这个位置。相反,ERNIE可以用正确的实体填充这些位置。在案例3、案例4、案例6中,BERT用几个与句子相关的字符填补了空缺,但是很难预测语义概念。ERNIE预测正确的实体,但情况4除外。虽然ERNIE在Case 4中预测了错误的实体,但它可以正确地预测语义类型,并将一个澳大利亚城市的实体填入槽中。综上所述,这些案例表明ERNIE在基于上下文的知识推理方面表现得更好。

结论
在本文中,我们提出了一种将知识整合到训练前语言模型中的新方法。对5个中文处理任务的实验结果表明,我们的方法优于BERT。我们还证实了对异构数据的知识集成和预处理都能使模型获得更好的语言表示。
在未来,我们将把其他类型的知识集成到语义表示模型中,例如使用语法分析或来自其他任务的弱监督信号。此外,我们还将在其他语言中验证这个想法。
论文阅读 | ERNIE: Enhanced Representation through Knowledge Integration的更多相关文章
- 论文阅读 Dynamic Graph Representation Learning Via Self-Attention Networks
4 Dynamic Graph Representation Learning Via Self-Attention Networks link:https://arxiv.org/abs/1812. ...
- [论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks
[论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks 本文结构 解决问题 主要贡献 算法 ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- Nature/Science 论文阅读笔记
Nature/Science 论文阅读笔记 Unsupervised word embeddings capture latent knowledge from materials science l ...
- [论文阅读]阿里DIN深度兴趣网络之总体解读
[论文阅读]阿里DIN深度兴趣网络之总体解读 目录 [论文阅读]阿里DIN深度兴趣网络之总体解读 0x00 摘要 0x01 论文概要 1.1 概括 1.2 文章信息 1.3 核心观点 1.4 名词解释 ...
- BERT 论文阅读笔记
BERT 论文阅读 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 由 @快刀切草莓君 ...
- [论文阅读笔记] node2vec Scalable Feature Learning for Networks
[论文阅读笔记] node2vec:Scalable Feature Learning for Networks 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 由于DeepWal ...
- [论文阅读笔记] Are Meta-Paths Necessary, Revisiting Heterogeneous Graph Embeddings
[论文阅读笔记] Are Meta-Paths Necessary? Revisiting Heterogeneous Graph Embeddings 本文结构 解决问题 主要贡献 算法原理 参考文 ...
- [论文阅读笔记] Structural Deep Network Embedding
[论文阅读笔记] Structural Deep Network Embedding 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 现有的表示学习方法大多采用浅层模型,这可能不能 ...
随机推荐
- retrying failed action with response code: 403 错误解决
[2019-06-10T06:52:51,610][INFO ][logstash.outputs.elasticsearch] retrying failed action with respons ...
- 6、DockerFile解析:三步走、保留字指令
1.dockerfiel是什么 1.是什么 Dockerfile是用来构建Docker镜像的构建文件,是由一系列命令和参数构成的脚本. 2.构建三步骤 编写Dockerfile文件 docker bu ...
- [Javascript] Correctly Type-Checking Numbers
There are two ways to correctly type checks number: console.log(typeof 99.66); // number console.log ...
- 【Android-SwipeRefreshLayout控件】下拉刷新
Android自带API ,V4包下面的下拉刷新控件 android.support.v4.widget.SwipeRefreshLayout SwipeRefreshLayout只能包含一个控件 布 ...
- laravel各种请求类
curl请求类 composer require php-curl-class/php-curl-class
- Java进阶知识13 Hibernate查询语言(HQL),本文以hibernate注解版为例讲解
1.简单概述 1.1. 1) SQL:面向的是数据库 select * from tableName;2) HQL查询(Hibernate Query language): hibernate 提供的 ...
- 【原创】洛谷 LUOGU P3366 【模板】最小生成树
P3366 [模板]最小生成树 题目描述 如题,给出一个无向图,求出最小生成树,如果该图不连通,则输出orz 输入输出格式 输入格式: 第一行包含两个整数N.M,表示该图共有N个结点和M条无向边.(N ...
- 实例分析jdom和dom4j的使用和区别 (转)
实例分析jdom和dom4j的使用和区别 对于xml的解析和生成,我们在实际应用中用的比较多的是JDOM和DOM4J,下面通过例子来分析两者的区别(在这里我就不详细讲解怎么具体解析xml,如果对于 ...
- OUC_Summer Training_ DIV2_#13 723afternoon
A - Shaass and Oskols Time Limit:2000MS Memory Limit:262144KB 64bit IO Format:%I64d & %I ...
- Nginx之共享内存与slab机制
1. 共享内存 在 Nginx 里,一块完整的共享内存以结构体 ngx_shm_zone_t 来封装,如下: typedef struct ngx_shm_zone_s ngx_shm_zone_t; ...