Apache Spark Jobs 性能调优
当你开始编写 Apache Spark 代码或者浏览公开的 API 的时候,你会遇到各种各样术语,比如transformation,action,RDD(resilient distributed dataset) 等等。 了解到这些是编写 Spark 代码的基础。 同样,当你任务开始失败或者你需要透过web界面去了解自己的应用为何如此费时的时候,你需要去了解一些新的名词: job, stage, task。对于这些新术语的理解有助于编写良好 Spark 代码。这里的良好主要指更快的 Spark 程序。对于 Spark 底层的执行模型的了解对于写出效率更高的 Spark 程序非常有帮助。
Spark 是如何执行程序的
一个 Spark 应用包括一个 driver 进程和若干个分布在集群的各个节点上的 executor 进程。
driver 主要负责调度一些高层次的任务流(flow of work)。exectuor 负责执行这些任务,这些任务以 task 的形式存在, 同时存储用户设置需要caching的数据。 task 和所有的 executor 的生命周期为整个程序的运行过程(如果使用了dynamic resource allocation 时可能不是这样的)。如何调度这些进程是通过集群管理应用完成的(比如YARN,Mesos,Spark Standalone),但是任何一个 Spark 程序都会包含一个 driver 和多个 executor 进程。
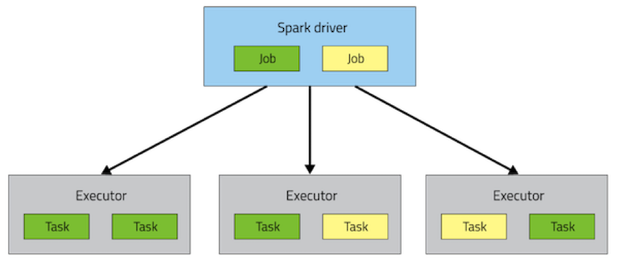
在执行层次结构的最上方是一系列 Job。调用一个Spark内部的 action 会产生一个 Spark job 来完成它。 为了确定这些job实际的内容,Spark 检查 RDD 的DAG再计算出执行 plan 。这个 plan 以最远端的 RDD 为起点(最远端指的是对外没有依赖的 RDD 或者 数据已经缓存下来的 RDD),产生结果 RDD 的 action 为结束 。
执行的 plan 由一系列 stage 组成,stage 是 job 的 transformation 的组合,stage 对应于一系列 task, task 指的对于不同的数据集执行的相同代码。每个 stage 包含不需要 shuffle 数据的 transformation 的序列。
什么决定数据是否需要 shuffle ?RDD 包含固定数目的 partition, 每个 partiton 包含若干的 record。对于那些通过narrow tansformation(比如 map 和 filter)返回的 RDD,一个 partition 中的 record 只需要从父 RDD 对应的partition 中的 record 计算得到。每个对象只依赖于父 RDD 的一个对象。有些操作(比如 coalesce)可能导致一个 task处理多个输入 partition ,但是这种 transformation 仍然被认为是 narrow 的,因为用于计算的多个输入 record 始终是来自有限个数的 partition。
然而 Spark 也支持需要 wide 依赖的 transformation,比如 groupByKey,reduceByKey。在这种依赖中,计算得到一个 partition 中的数据需要从父 RDD 中的多个 partition 中读取数据。所有拥有相同 key 的元组最终会被聚合到同一个partition 中,被同一个 stage 处理。为了完成这种操作, Spark需要对数据进行 shuffle,意味着数据需要在集群内传递,最终生成由新的 partition 集合组成的新的 stage。
举例,以下的代码中,只有一个 action 以及 从一个文本串下来的一系列 RDD, 这些代码就只有一个 stage,因为没有哪个操作需要从不同的 partition 里面读取数据。
- sc.textFile("someFile.txt").
- map(mapFunc).
- flatMap(flatMapFunc).
- filter(filterFunc).
- count()
跟上面的代码不同,下面一段代码需要统计总共出现超过1000次的单词:
- val tokenized = sc.textFile(args(0)).flatMap(_.split(' '))
- val wordCounts = tokenized.map((_, 1)).reduceByKey(_ + _)
- val filtered = wordCounts.filter(_._2 >= 1000)
- val charCounts = filtered.flatMap(_._1.toCharArray).map((_, 1)).
- reduceByKey(_ + _)
- charCounts.collect()
这段代码可以分成三个 stage。recudeByKey 操作是各 stage 之间的分界,因为计算 recudeByKey 的输出需要按照可以重新分配 partition。
这里还有一个更加复杂的 transfromation 图,包含一个有多路依赖的 join transformation。

粉红色的框框展示了运行时使用的 stage 图。
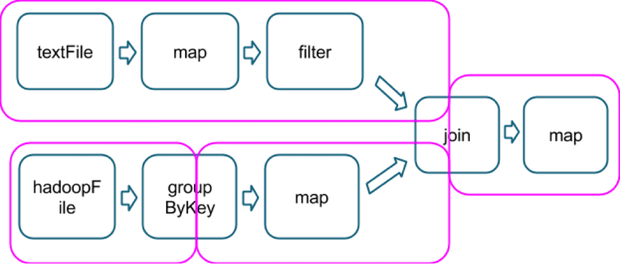
运行到每个 stage 的边界时,数据在父 stage 中按照 task 写到磁盘上,而在子 stage 中通过网络按照 task 去读取数据。这些操作会导致很重的网络以及磁盘的I/O,所以 stage 的边界是非常占资源的,在编写 Spark 程序的时候需要尽量避免的。父 stage 中 partition 个数与子 stage 的 partition 个数可能不同,所以那些产生 stage 边界的 transformation 常常需要接受一个 numPartition 的参数来觉得子 stage 中的数据将被切分为多少个 partition。
正如在调试 MapReduce 是选择 reducor 的个数是一项非常重要的参数,调整在 stage 边届时的 partition 个数经常可以很大程度上影响程序的执行效率。我们会在后面的章节中讨论如何调整这些值。
选择正确的 Operator
当需要使用 Spark 完成某项功能时,程序员需要从不同的 action 和 transformation 中选择不同的方案以获得相同的结果。但是不同的方案,最后执行的效率可能有云泥之别。回避常见的陷阱选择正确的方案可以使得最后的表现有巨大的不同。一些规则和深入的理解可以帮助你做出更好的选择。
在最新的 Spark5097 文档中开始稳定 SchemaRDD(也就是 Spark 1.3 开始支持的DataFrame),这将为使用 Spark 核心API的程序员打开 Spark的 Catalyst optimizer,允许 Spark 在使用 Operator 时做出更加高级的选择。当 SchemaRDD稳定之后,某些决定将不需要用户去考虑了。
选择 Operator 方案的主要目标是减少 shuffle 的次数以及被 shuffle 的文件的大小。因为 shuffle 是最耗资源的操作,所以有 shuffle 的数据都需要写到磁盘并且通过网络传递。repartition,join,cogroup,以及任何 *By 或者 *ByKey 的transformation 都需要 shuffle 数据。不是所有这些 Operator 都是平等的,但是有些常见的性能陷阱是需要注意的。
- 当进行联合的规约操作时,避免使用 groupByKey。举个例子,rdd.groupByKey().mapValues(_ .sum) 与 rdd.reduceByKey(_ + _) 执行的结果是一样的,但是前者需要把全部的数据通过网络传递一遍,而后者只需要根据每个key 局部的 partition 累积结果,在 shuffle 的之后把局部的累积值相加后得到结果。
- 当输入和输入的类型不一致时,避免使用 reduceByKey。举个例子,我们需要实现为每一个key查找所有不相同的 string。一个方法是利用 map 把每个元素的转换成一个 Set,再使用 reduceByKey 将这些 Set 合并起来
- rdd.map(kv => (kv._1, new Set[String]() + kv._2))
- .reduceByKey(_ ++ _)
这段代码生成了无数的非必须的对象,因为每个需要为每个 record 新建一个 Set。这里使用 aggregateByKey 更加适合,因为这个操作是在 map 阶段做聚合。
- val zero = new collection.mutable.Set[String]()
- rdd.aggregateByKey(zero)(
- (set, v) => set += v,
- (set1, set2) => set1 ++= set2)
- 避免 flatMap-join-groupBy 的模式。当有两个已经按照key分组的数据集,你希望将两个数据集合并,并且保持分组,这种情况可以使用 cogroup。这样可以避免对group进行打包解包的开销。
什么时候不发生 Shuffle
当然了解在哪些 transformation 上不会发生 shuffle 也是非常重要的。当前一个 transformation 已经用相同的patitioner 把数据分 patition 了,Spark知道如何避免 shuffle。参考一下代码:
- rdd1 = someRdd.reduceByKey(...)
- rdd2 = someOtherRdd.reduceByKey(...)
- rdd3 = rdd1.join(rdd2)
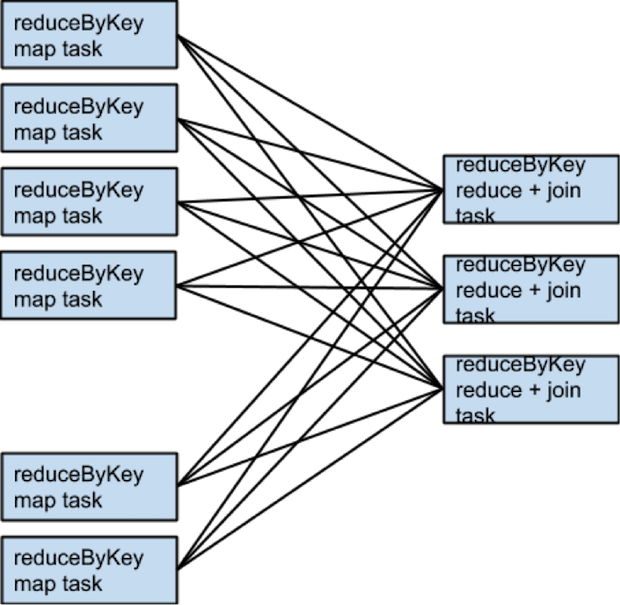
因为没有 partitioner 传递给 reduceByKey,所以系统使用默认的 partitioner,所以 rdd1 和 rdd2 都会使用 hash 进行分 partition。代码中的两个 reduceByKey 会发生两次 shuffle 。如果 RDD 包含相同个数的 partition, join 的时候将不会发生额外的 shuffle。因为这里的 RDD 使用相同的 hash 方式进行 partition,所以全部 RDD 中同一个 partition 中的 key的集合都是相同的。因此,rdd3中一个 partiton 的输出只依赖rdd2和rdd1的同一个对应的 partition,所以第三次shuffle 是不必要的。
举个例子说,当 someRdd 有4个 partition, someOtherRdd 有两个 partition,两个 reduceByKey 都使用3个partiton,所有的 task 会按照如下的方式执行:
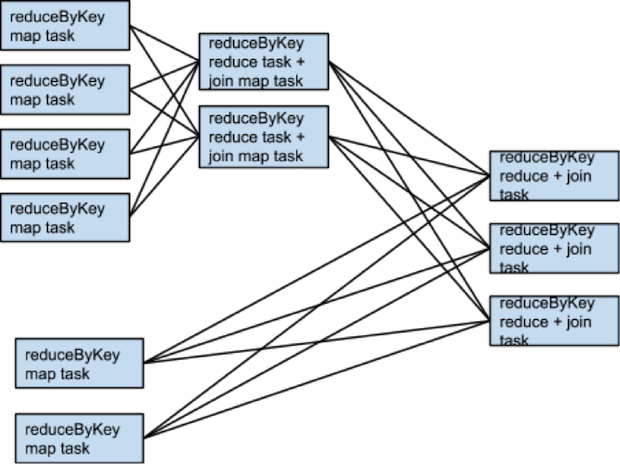
如果 rdd1 和 rdd2 在 reduceByKey 时使用不同的 partitioner 或者使用相同的 partitioner 但是 partition 的个数不同的情况,那么只有一个 RDD (partiton 数更少的那个)需要重新 shuffle。
相同的 tansformation,相同的输入,不同的 partition 个数:
当两个数据集需要 join 的时候,避免 shuffle 的一个方法是使用 broadcast variables。如果一个数据集小到能够塞进一个executor 的内存中,那么它就可以在 driver 中写入到一个 hash table中,然后 broadcast 到所有的 executor 中。然后map transformation 可以引用这个 hash table 作查询。
什么情况下 Shuffle 越多越好
尽可能减少 shuffle 的准则也有例外的场合。如果额外的 shuffle 能够增加并发那么这也能够提高性能。比如当你的数据保存在几个没有切分过的大文件中时,那么使用 InputFormat 产生分 partition 可能会导致每个 partiton 中聚集了大量的record,如果 partition 不够,导致没有启动足够的并发。在这种情况下,我们需要在数据载入之后使用 repartiton (会导致shuffle)提高 partiton 的个数,这样能够充分使用集群的CPU。
另外一种例外情况是在使用 recude 或者 aggregate action 聚集数据到 driver 时,如果数据把很多 partititon 个数的数据,单进程执行的 driver merge 所有 partition 的输出时很容易成为计算的瓶颈。为了缓解 driver 的计算压力,可以使用reduceByKey 或者 aggregateByKey 执行分布式的 aggregate 操作把数据分布到更少的 partition 上。每个 partition中的数据并行的进行 merge,再把 merge 的结果发个 driver 以进行最后一轮 aggregation。查看 treeReduce 和treeAggregate 查看如何这么使用的例子。
这个技巧在已经按照 Key 聚集的数据集上格外有效,比如当一个应用是需要统计一个语料库中每个单词出现的次数,并且把结果输出到一个map中。一个实现的方式是使用 aggregation,在每个 partition 中本地计算一个 map,然后在 driver中把各个 partition 中计算的 map merge 起来。另一种方式是通过 aggregateByKey 把 merge 的操作分布到各个partiton 中计算,然后在简单地通过 collectAsMap 把结果输出到 driver 中。
二次排序
还有一个重要的技能是了解接口 repartitionAndSortWithinPartitions transformation。这是一个听起来很晦涩的transformation,但是却能涵盖各种奇怪情况下的排序,这个 transformation 把排序推迟到 shuffle 操作中,这使大量的数据有效的输出,排序操作可以和其他操作合并。
举例说,Apache Hive on Spark 在join的实现中,使用了这个 transformation 。而且这个操作在 secondary sort 模式中扮演着至关重要的角色。secondary sort 模式是指用户期望数据按照 key 分组,并且希望按照特定的顺序遍历 value。使用 repartitionAndSortWithinPartitions 再加上一部分用户的额外的工作可以实现 secondary sort。
调试资源分配
Spark 的用户邮件邮件列表中经常会出现 “我有一个500个节点的集群,为什么但是我的应用一次只有两个 task 在执行”,鉴于 Spark 控制资源使用的参数的数量,这些问题不应该出现。但是在本章中,你将学会压榨出你集群的每一分资源。推荐的配置将根据不同的集群管理系统( YARN、Mesos、Spark Standalone)而有所不同,我们将主要集中在YARN 上,因为这个 Cloudera 推荐的方式。
我们先看一下在 YARN 上运行 Spark 的一些背景。查看之前的博文:点击这里查看
Spark(以及YARN) 需要关心的两项主要的资源是 CPU 和 内存, 磁盘 和 IO 当然也影响着 Spark 的性能,但是不管是 Spark 还是 Yarn 目前都没法对他们做实时有效的管理。
在一个 Spark 应用中,每个 Spark executor 拥有固定个数的 core 以及固定大小的堆大小。core 的个数可以在执行 spark-submit 或者 pyspark 或者 spark-shell 时,通过参数 --executor-cores 指定,或者在 spark-defaults.conf 配置文件或者 SparkConf 对象中设置 spark.executor.cores 参数。同样地,堆的大小可以通过 --executor-memory 参数或者 spark.executor.memory 配置项。core 配置项控制一个 executor 中task的并发数。 --executor-cores 5 意味着每个executor 中最多同时可以有5个 task 运行。memory 参数影响 Spark 可以缓存的数据的大小,也就是在 groupaggregate 以及 join 操作时 shuffle 的数据结构的最大值。
--num-executors 命令行参数或者spark.executor.instances 配置项控制需要的 executor 个数。从 CDH 5.4/Spark 1.3 开始,你可以避免使用这个参数,只要你通过设置 spark.dynamicAllocation.enabled 参数打开 动态分配 。动态分配可以使的 Spark 的应用在有后续积压的在等待的 task 时请求 executor,并且在空闲时释放这些 executor。
同时 Spark 需求的资源如何跟 YARN 中可用的资源配合也是需要着重考虑的,YARN 相关的参数有:
- yarn.nodemanager.resource.memory-mb 控制在每个节点上 container 能够使用的最大内存;
- yarn.nodemanager.resource.cpu-vcores 控制在每个节点上 container 能够使用的最大core个数;
请求5个 core 会生成向 YARN 要5个虚拟core的请求。从 YARN 请求内存相对比较复杂因为以下的一些原因:
- --executor-memory/spark.executor.memory 控制 executor 的堆的大小,但是 JVM 本身也会占用一定的堆空间,比如内部的 String 或者直接 byte buffer,executor memory 的 spark.yarn.executor.memoryOverhead 属性决定向 YARN 请求的每个 executor 的内存大小,默认值为max(384, 0.7 * spark.executor.memory);
- YARN 可能会比请求的内存高一点,YARN 的 yarn.scheduler.minimum-allocation-mb 和 yarn.scheduler.increment-allocation-mb 属性控制请求的最小值和增加量。
下面展示的是 Spark on YARN 内存结构:
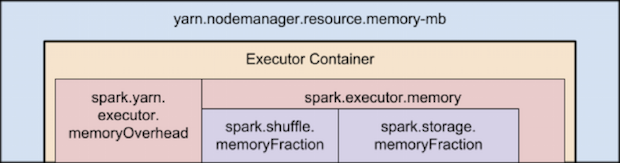
如果这些还不够决定Spark executor 个数,还有一些概念还需要考虑的:
- 应用的master,是一个非 executor 的容器,它拥有特殊的从 YARN 请求资源的能力,它自己本身所占的资源也需要被计算在内。在 yarn-client 模式下,它默认请求 1024MB 和 1个core。在 yarn-cluster 模式中,应用的 master 运行 driver,所以使用参数 --driver-memory 和 --driver-cores 配置它的资源常常很有用。
- 在 executor 执行的时候配置过大的 memory 经常会导致过长的GC延时,64G是推荐的一个 executor 内存大小的上限。
- 我们注意到 HDFS client 在大量并发线程是时性能问题。大概的估计是每个 executor 中最多5个并行的 task 就可以占满的写入带宽。
- 在运行微型 executor 时(比如只有一个core而且只有够执行一个task的内存)扔掉在一个JVM上同时运行多个task的好处。比如 broadcast 变量需要为每个 executor 复制一遍,这么多小executor会导致更多的数据拷贝。
为了让以上的这些更加具体一点,这里有一个实际使用过的配置的例子,可以完全用满整个集群的资源。假设一个集群有6个节点有NodeManager在上面运行,每个节点有16个core以及64GB的内存。那么 NodeManager的容量:yarn.nodemanager.resource.memory-mb 和 yarn.nodemanager.resource.cpu-vcores 可以设为 63 * 1024 = 64512 (MB) 和 15。我们避免使用 100% 的 YARN container 资源因为还要为 OS 和 hadoop 的 Daemon 留一部分资源。在上面的场景中,我们预留了1个core和1G的内存给这些进程。Cloudera Manager 会自动计算并且配置。
所以看起来我们最先想到的配置会是这样的:--num-executors 6 --executor-cores 15 --executor-memory 63G。但是这个配置可能无法达到我们的需求,因为:
- 63GB+ 的 executor memory 塞不进只有 63GB 容量的 NodeManager;
- 应用的 master 也需要占用一个core,意味着在某个节点上,没有15个core给 executor 使用;
- 15个core会影响 HDFS IO的吞吐量。
配置成 --num-executors 17 --executor-cores 5 --executor-memory 19G 可能会效果更好,因为:
- 这个配置会在每个节点上生成3个 executor,除了应用的master运行的机器,这台机器上只会运行2个 executor
- --executor-memory 被分成3份(63G/每个节点3个executor)=21。 21 * (1 - 0.07) ~ 19。
调试并发
我们知道 Spark 是一套数据并行处理的引擎。但是 Spark 并不是神奇得能够将所有计算并行化,它没办法从所有的并行化方案中找出最优的那个。每个 Spark stage 中包含若干个 task,每个 task 串行地处理数据。在调试 Spark 的job时,task的个数可能是决定程序性能的最重要的参数。
那么这个数字是由什么决定的呢?在之前的博文中介绍了 Spark 如何将 RDD 转换成一组 stage。task 的个数与 stage 中上一个 RDD 的 partition 个数相同。而一个 RDD 的 partition 个数与被它依赖的 RDD 的 partition 个数相同,除了以下的情况: coalesce transformation 可以创建一个具有更少 partition 个数的 RDD,union transformation 产出的 RDD的 partition 个数是它父 RDD 的 partition 个数之和, cartesian 返回的 RDD 的 partition 个数是它们的积。
如果一个 RDD 没有父 RDD 呢? 由 textFile 或者 hadoopFile 生成的 RDD 的 partition 个数由它们底层使用的 MapReduce InputFormat 决定的。一般情况下,每读到的一个 HDFS block 会生成一个 partition。通过 parallelize 接口生成的 RDD 的 partition 个数由用户指定,如果用户没有指定则由参数 spark.default.parallelism 决定。
要想知道 partition 的个数,可以通过接口 rdd.partitions().size() 获得。
这里最需要关心的问题在于 task 的个数太小。如果运行时 task 的个数比实际可用的 slot 还少,那么程序解没法使用到所有的 CPU 资源。
过少的 task 个数可能会导致在一些聚集操作时, 每个 task 的内存压力会很大。任何 join,cogroup,*ByKey 操作都会在内存生成一个 hash-map或者 buffer 用于分组或者排序。join, cogroup ,groupByKey 会在 shuffle 时在 fetching 端使用这些数据结构, reduceByKey ,aggregateByKey 会在 shuffle 时在两端都会使用这些数据结构。
当需要进行这个聚集操作的 record 不能完全轻易塞进内存中时,一些问题会暴露出来。首先,在内存 hold 大量这些数据结构的 record 会增加 GC的压力,可能会导致流程停顿下来。其次,如果数据不能完全载入内存,Spark 会将这些数据写到磁盘,这会引起磁盘 IO和排序。在 Cloudera 的用户中,这可能是导致 Spark Job 慢的首要原因。
那么如何增加你的 partition 的个数呢?如果你的问题 stage 是从 Hadoop 读取数据,你可以做以下的选项:
- 使用 repartition 选项,会引发 shuffle;
- 配置 InputFormat 用户将文件分得更小;
- 写入 HDFS 文件时使用更小的block。
如果问题 stage 从其他 stage 中获得输入,引发 stage 边界的操作会接受一个 numPartitions 的参数,比如
- val rdd2 = rdd1.reduceByKey(_ + _, numPartitions = X)
X 应该取什么值?最直接的方法就是做实验。不停的将 partition 的个数从上次实验的 partition 个数乘以1.5,直到性能不再提升为止。
同时也有一些原则用于计算 X,但是也不是非常的有效是因为有些参数是很难计算的。这里写到不是因为它们很实用,而是可以帮助理解。这里主要的目标是启动足够的 task 可以使得每个 task 接受的数据能够都塞进它所分配到的内存中。
每个 task 可用的内存通过这个公式计算:spark.executor.memory * spark.shuffle.memoryFraction * spark.shuffle.safetyFraction)/spark.executor.cores 。 memoryFraction 和 safetyFractio 默认值分别 0.2 和 0.8.
在内存中所有 shuffle 数据的大小很难确定。最可行的是找出一个 stage 运行的 Shuffle Spill(memory) 和 Shuffle Spill(Disk) 之间的比例。在用所有shuffle 写乘以这个比例。但是如果这个 stage 是 reduce 时,可能会有点复杂:
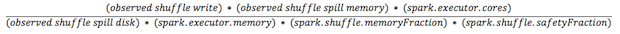
在往上增加一点因为大多数情况下 partition 的个数会比较多。
试试在,在有所疑虑的时候,使用更多的 task 数(也就是 partition 数)都会效果更好,这与 MapRecuce 中建议 task 数目选择尽量保守的建议相反。这个因为 MapReduce 在启动 task 时相比需要更大的代价。
压缩你的数据结构
Spark 的数据流由一组 record 构成。一个 record 有两种表达形式:一种是反序列化的 Java 对象另外一种是序列化的二进制形式。通常情况下,Spark 对内存中的 record 使用反序列化之后的形式,对要存到磁盘上或者需要通过网络传输的record 使用序列化之后的形式。也有计划在内存中存储序列化之后的 record。
spark.serializer 控制这两种形式之间的转换的方式。Kryo serializer,org.apache.spark.serializer.KryoSerializer 是推荐的选择。但不幸的是它不是默认的配置,因为 KryoSerializer 在早期的 Spark 版本中不稳定,而 Spark 不想打破版本的兼容性,所以没有把 KryoSerializer 作为默认配置,但是 KryoSerializer 应该在任何情况下都是第一的选择。
你的 record 在这两种形式切换的频率对于 Spark 应用的运行效率具有很大的影响。去检查一下到处传递数据的类型,看看能否挤出一点水分是非常值得一试的。
过多的反序列化之后的 record 可能会导致数据到处到磁盘上更加频繁,也使得能够 Cache 在内存中的 record 个数减少。点击这里查看如何压缩这些数据。
过多的序列化之后的 record 导致更多的 磁盘和网络 IO,同样的也会使得能够 Cache 在内存中的 record 个数减少,这里主要的解决方案是把所有的用户自定义的 class 都通过 SparkConf#registerKryoClasses 的API定义和传递的。
数据格式
任何时候你都可以决定你的数据如何保持在磁盘上,使用可扩展的二进制格式比如:Avro,Parquet,Thrift或者Protobuf,从中选择一种。当人们在谈论在Hadoop上使用Avro,Thrift或者Protobuf时,都是认为每个 record 保持成一个 Avro/Thrift/Protobuf 结构保存成 sequence file。而不是JSON。
每次当时试图使用JSON存储大量数据时,还是先放弃吧...
原文地址:
http://blog.cloudera.com/blog/2015/03/how-to-tune-your-apache-spark-jobs-part-1/
http://blog.cloudera.com/blog/2015/03/how-to-tune-your-apache-spark-jobs-part-2/
Apache Spark Jobs 性能调优的更多相关文章
- 【转载】Apache Spark Jobs 性能调优(二)
调试资源分配 Spark 的用户邮件邮件列表中经常会出现 "我有一个500个节点的集群,为什么但是我的应用一次只有两个 task 在执行",鉴于 Spark 控制资源使用的参数 ...
- 【转载】Apache Spark Jobs 性能调优(一)
当你开始编写 Apache Spark 代码或者浏览公开的 API 的时候,你会遇到各种各样术语,比如 transformation,action,RDD 等等. 了解到这些是编写 Spark 代码的 ...
- Spark的性能调优杂谈
下面这些关于Spark的性能调优项,有的是来自官方的,有的是来自别的的工程师,有的则是我自己总结的. 基本概念和原则 <1> 每一台host上面可以并行N个worker,每一个worke ...
- Spark的性能调优
下面这些关于Spark的性能调优项,有的是来自官方的,有的是来自别的的工程师,有的则是我自己总结的. Data Serialization,默认使用的是Java Serialization,这个程序员 ...
- Spark Streaming性能调优详解
Spark Streaming性能调优详解 Spark 2015-04-28 7:43:05 7896℃ 0评论 分享到微博 下载为PDF 2014 Spark亚太峰会会议资料下载.< ...
- Spark Streaming性能调优详解(转)
原文链接:Spark Streaming性能调优详解 Spark Streaming提供了高效便捷的流式处理模式,但是在有些场景下,使用默认的配置达不到最优,甚至无法实时处理来自外部的数据,这时候我们 ...
- Spark常规性能调优
1.1.1 常规性能调优一:最优资源配置 Spark性能调优的第一步,就是为任务分配更多的资源,在一定范围内,增加资源的分配与性能的提升是成正比的,实现了最优的资源配置后,在此基础上再考虑进行 ...
- Spark:性能调优
来自:http://blog.csdn.net/u012102306/article/details/51637366 资源参数调优 了解完了Spark作业运行的基本原理之后,对资源相关的参数就容易理 ...
- Spark 常规性能调优
1. 常规性能调优 一:最优资源配置 Spark性能调优的第一步,就是为任务分配更多的资源,在一定范围内,增加资源的分配与性能的提升是成正比的,实现了最优的资源配置后,在此基础上再考虑进行后面论述的性 ...
随机推荐
- 【HTML】 HTML基础知识 表单
html 表单 表单的标签是<form>,用于给网站的后台提交数据.提交的数据格式原本是什么样不太清楚,以python的flask框架来看,我从表单中得到的数据是一个字典(flask.re ...
- xml解析多个结点方法(C#)
解析多个结点的XML文件,格式如下: <?xml version="1.0" encoding="utf-8"?> <response> ...
- ConcurrentHashMap 源码分析
ConcurrentHashMap 源码分析 1. 前言 终于到这个类了,其实在前面很过很多次这个类,因为这个类代码量比较大,并且涉及到并发的问题,还有一点就是这个代码有些真的晦涩,不好懂.前前 ...
- Java基础学习笔记十二 类、抽象类、接口作为方法参数和返回值以及常用API
不同修饰符使用细节 常用来修饰类.方法.变量的修饰符 public 权限修饰符,公共访问, 类,方法,成员变量 protected 权限修饰符,受保护访问, 方法,成员变量 默认什么也不写 也是一种权 ...
- Beta项目复审
Beta项目复审 复审人:张宇光 所属团队:MyGod 团队成员:程环宇.王田路.张芷祎.张宇光.王婷婷 团队排名: SW_HW4-team团队 hyw-team团队 Java-Team团队 C++团 ...
- 201621123035 《Java程序设计》第1周学习总结
1.本周学习总结 本周学习内容:Java平台概论.认识JDK规范与操作.了解JVM.JRE与JDK.撰写Java原始码.path是什么 关键词:JVM.JRE.JDK 联系:JVM是Java虚拟机的缩 ...
- Scala 快速入门
 Scalable 编程语言 纯正的的面向对象语言 函数式编程语言 无缝的java互操作 scala之父 Martin Odersky 1. 函数式编程 函数式编程(functional progr ...
- JAVA_SE基础——24.面向对象的内存分析
黑马程序员入学blog ... 接着上一章的代码: //车类 class Car{ //事物的公共属性使用成员变量描述. String name; //名字的属性 String color; //颜色 ...
- 07_Python的控制判断循环语句1(if判断,for循环...)_Python编程之路
Python的数据类型在前几节我们都简单的一一介绍了,接下来我们就要讲到Python的控制判断循环语句 在现实编程中,我们往往要利用计算机帮我们做大量重复计算的工作,在这样的情况下,需要机器能对某个条 ...
- app测试中遇到问题总结
工作总结: 1 这两天由于工作,需要进行抓包,使用了Charles,fidder,发现一个坑点: charles没有抓到返回值的时候,默认是不在列表显示请求信息的,能不能设置,我就不知道了,但是可以在 ...