【机器学习】Iris Data Set(鸢尾属植物数据集)
注:数据是机器学习模型的原材料,当下机器学习的热潮离不开大数据的支撑。在机器学习领域,有大量的公开数据集可以使用,从几百个样本到几十万个样本的数据集都有。有些数据集被用来教学,有些被当做机器学习模型性能测试的标准(例如ImageNet图片数据集以及相关的图像分类比赛)。这些高质量的公开数据集为我们学习和研究机器学习算法提供了极大的便利,类似于模式生物对于生物学实验的价值。
Iris数据集概况
Iris Data Set(鸢尾属植物数据集)是我现在接触到的历史最悠久的数据集,它首次出现在著名的英国统计学家和生物学家Ronald Fisher 1936年的论文《The use of multiple measurements in taxonomic problems》中,被用来介绍线性判别式分析。在这个数据集中,包括了三类不同的鸢尾属植物:Iris Setosa,Iris Versicolour,Iris Virginica。每类收集了50个样本,因此这个数据集一共包含了150个样本。
特征
该数据集测量了所有150个样本的4个特征,分别是:
- sepal length(花萼长度)
- sepal width(花萼宽度)
- petal length(花瓣长度)
- petal width(花瓣宽度)
以上四个特征的单位都是厘米(cm)。
通常使用$m$表示样本量的大小,$n$表示每个样本所具有的特征数。因此在该数据集中,$m = 150, n = 4$
数据集的获取
该数据集被广泛用于分类算法的示例中,很多机器学习相关的数据都对这个数据集进行了介绍,因此可以获得的途径应该也会很多。
下面是该数据集存放的原始位置,该位置好像已经无法下载了,但是收集了使用该数据集的论文列表可供参考:
https://archive.ics.uci.edu/ml/datasets/Iris/
另一个比较方便的获取方式是,直接利用Python中的机器学习包scikit-learn直接导入该数据集,可参考Iris Plants Database,下面是具体的操作:
from sklearn.datasets import load_iris
data = load_iris()
print(dir(data)) # 查看data所具有的属性或方法
print(data.DESCR) # 查看数据集的简介 import pandas as pd
#直接读到pandas的数据框中
pd.DataFrame(data=data.data, columns=data.feature_names)
下面是第3行和第4行的输出:
['DESCR', 'data', 'feature_names', 'target', 'target_names'] Iris Plants Database
==================== Notes
-----
Data Set Characteristics:
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
:Summary Statistics: ============== ==== ==== ======= ===== ====================
Min Max Mean SD Class Correlation
============== ==== ==== ======= ===== ====================
sepal length: 4.3 7.9 5.84 0.83 0.7826
sepal width: 2.0 4.4 3.05 0.43 -0.4194
petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)
petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)
============== ==== ==== ======= ===== ==================== :Missing Attribute Values: None
:Class Distribution: 33.3% for each of 3 classes.
:Creator: R.A. Fisher
:Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov)
:Date: July, 1988 This is a copy of UCI ML iris datasets.
http://archive.ics.uci.edu/ml/datasets/Iris The famous Iris database, first used by Sir R.A Fisher This is perhaps the best known database to be found in the
pattern recognition literature. Fisher's paper is a classic in the field and
is referenced frequently to this day. (See Duda & Hart, for example.) The
data set contains 3 classes of 50 instances each, where each class refers to a
type of iris plant. One class is linearly separable from the other 2; the
latter are NOT linearly separable from each other. References
----------
...
数据的可视化展示
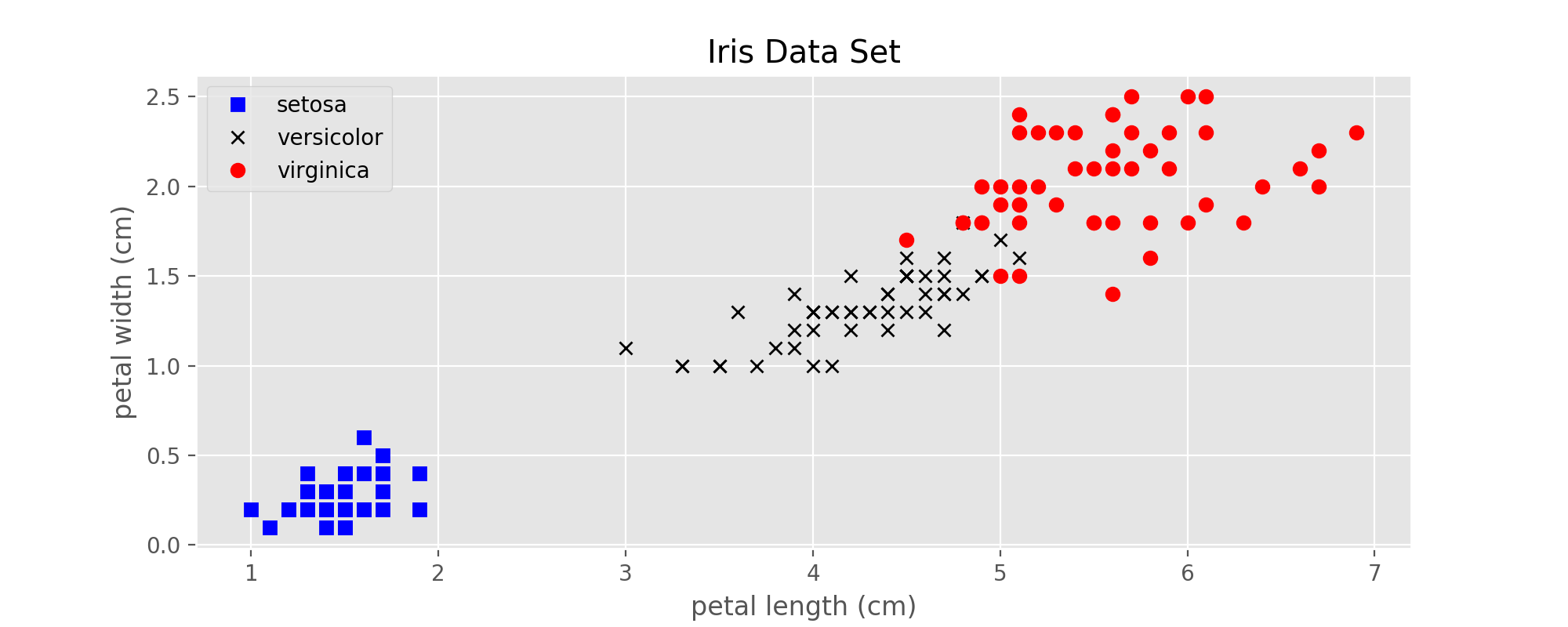
将数据用图像的形式展示出来,可以对该数据集有一个直观的整体印象。下面利用该数据集4个特征中的后两个,即花瓣的长度和宽度,来展示所有的样本点。
import matplotlib.pyplot as plt
plt.style.use('ggplot') X = data.data # 只包括样本的特征,150x4
y = data.target # 样本的类型,[0, 1, 2]
features = data.feature_names # 4个特征的名称
targets = data.target_names # 3类鸢尾花的名称,跟y中的3个数字对应 plt.figure(figsize=(10, 4))
plt.plot(X[:, 2][y==0], X[:, 3][y==0], 'bs', label=targets[0])
plt.plot(X[:, 2][y==1], X[:, 3][y==1], 'kx', label=targets[1])
plt.plot(X[:, 2][y==2], X[:, 3][y==2], 'ro', label=targets[2])
plt.xlabel(features[2])
plt.ylabel(features[3])
plt.title('Iris Data Set')
plt.legend()
plt.savefig('Iris Data Set.png', dpi=200)
plt.show()
利用上面的代码画出来的图如下:
Reference
https://en.wikipedia.org/wiki/Iris_flower_data_set
https://archive.ics.uci.edu/ml/datasets/Iris/
https://matplotlib.org/users/style_sheets.html
http://scikit-learn.org/stable/datasets/index.html#iris-plants-database
【机器学习】Iris Data Set(鸢尾属植物数据集)的更多相关文章
- 【机器学习】Iris Data Set(鸢尾花数据集)
[机器学习]Iris Data Set(鸢尾花数据集) 注:数据是机器学习模型的原材料,当下机器学习的热潮离不开大数据的支撑.在机器学习领域,有大量的公开数据集可以使用,从几百个样本到几十万个样本的数 ...
- 鸢尾花数据集-iris.data
iris.data 5.1,3.5,1.4,0.2,Iris-setosa 4.9,3.0,1.4,0.2,Iris-setosa 4.7,3.2,1.3,0.2,Iris-setosa 4.6,3. ...
- 什么是机器学习的特征工程?【数据集特征抽取(字典,文本TF-Idf)、特征预处理(标准化,归一化)、特征降维(低方差,相关系数,PCA)】
2.特征工程 2.1 数据集 2.1.1 可用数据集 Kaggle网址:https://www.kaggle.com/datasets UCI数据集网址: http://archive.ics.uci ...
- python3 load Iris.data数据集出现报错key words: b'Iris-setosa'
通过搜索原因,发现有可能是在对文件读取是编译出现了问题,并且Keyword中提示b'Iris-setosa',而我们的string转float函数中没有字母b,很奇怪.所以尝试将转换函数所有的stri ...
- 使用tensorflow.data.Dataset构造batch数据集(具体用法在下一篇博客介绍)
import tensorflow as tf import numpy as np def _parse_function(x): num_list = np.arange(10) return n ...
- 【机器学习】从SVM到SVR
注:最近在工作中,高频率的接触到了SVM模型,而且还有使用SVM模型做回归的情况,即SVR.另外考虑到自己从第一次知道这个模型到现在也差不多两年时间了,从最开始的腾云驾雾到现在有了一点直观的认识,花费 ...
- 【机器学习笔记】来吧!解析k-NN
序: 监督型学习与无监督学习,其最主要区别在于:已知的数据里面有没有标签(作为区别数据的内容). 监督学习大概是这个套路: 1.给定很多很多数据(假设2000个图片),并且给每个数据加上标签(与图片一 ...
- AI学习--机器学习概述
学习框架 01-人工智能概述 机器学习.人工智能与深度学习的关系 达特茅斯会议-人工智能的起点 机器学习是人工智能的一个实现途径深度学习是机器学习的一个方法发展而来(人工神经网络) 从图上可以看出,人 ...
- SVM-SVR
高频率的接触到了SVM模型,而且还有使用SVM模型做回归的情况,即SVR.另外考虑到自己从第一次知道这个模型到现在也差不多两年时间了,从最开始的腾云驾雾到现在有了一点直观的认识,花费了不少时间.因此在 ...
随机推荐
- Shell 读取用户输入
14.2 读取用户输入 14.2.1 变量 上一章我们谈到如何定义或取消变量,变量可被设置为当前shell的局部变量,或是环境变量.如果您的shell脚本不需要调用其他脚本,其中的变量通常设置为脚 ...
- STL --> find()和find_if()
find()和find_if() 一.find()函数 find(first, end, value); // 返回区间[first,end)中第一个值等于value的元素的位置.如果没有找到匹配元素 ...
- java排序算法(一):概述
java排序算法(一)概述 排序是程序开发中一种非常常见的操作,对一组任意的数据元素(活记录)经过排序操作后,就可以把它们变成一组按关键字排序的一组有序序列 对一个排序的算法来说,一般从下面三个方面来 ...
- 每天学习点jquery
一.jquery选择器 1.根据给定的ID匹配一个元素(如果选择器中包含特殊字符,可以用两个斜杠转义)id选择器 举例:html代码 <div id="notMe">& ...
- [bzoj3173]最长上升子序列_非旋转Treap
最长上升子序列 bzoj-3173 题目大意:有1-n,n个数,第i次操作是将i加入到原有序列中制定的位置,后查询当前序列中最长上升子序列长度. 注释:1<=n<=10,000,开始序列为 ...
- KVM之二:配置网络
1.安装KVM a.通过yum安装虚拟化的软件包 [root@kvm ~ ::]#yum install -y kvm virt-* libvirt bridge-utils qemu-img 说明: ...
- Jupyter Notebook的快捷键
Jupyter Notebook 有两种键盘输入模式. 编辑模式,允许你往单元中键入代码或文本,这时的单元框线是绿色的. 命令模式,键盘输入运行程序命令:这时的单元框线是蓝色. 命令模式 ...
- Hibernate学习笔记二
Hibernate持久化类的编写规则 Hibernate是持久层的ORM映射框架,专注于数据的持久化工作.所谓持久化,就是将内存中的数据永久存储到关系型数据库中. 持久化类 一个java类与数据库表建 ...
- breeze源码阅读心得
在阅读Spark ML源码的过程中,发现很多机器学习中的优化问题,都是直接调用breeze库解决的,因此拿来breeze源码想一探究竟.整体来看,breeze是一个用scala实现的基 ...
- 201621123060《JAVA程序设计》第二周学习总结
1.本周学习总结 本周学习了JAVA中的引用类.包装类(学习了一种语法:自动装箱)和数组(遍历数组的新方法foreach循环). 2. 书面作业 1.String-使用Eclipse关联jdk源代码 ...