云计算openstack共享组件(2)——Memcache 缓存系统
一、缓存系统
在大型海量并发访问网站及openstack等集群中,对于关系型数据库,尤其是大型关系型数据库,如果对其进行每秒上万次的并发访问,并且每次访问都在一个有上亿条记录的数据表中查询某条记录时,其效率会非常低,对数据库而言,这也是无法承受的。
缓冲系统的使用可以很好的解决大型并发数据访问所带来的效率低下和数据库压力等问题,缓存系统将经常使用的活跃数据存储在内存中避免了访问重复数据时,数据库查询所带来的频繁磁盘i/o和大型关系表查询时的时间开销,因此缓存系统几乎是大型网站的必备功能模块。
缓存系统可以认为是基于内存的数据库,相对于后端大型生产数据库而言基于内存的缓存数据库能够提供快速的数据访问操作,从而提高客户端的数据请求访问反馈,并降低后端数据库的访问压力。
二、Memcached概念
Memcached 是一个开源的、高性能的分布式内存对象缓存系统。通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高网站访问速度,加速动态WEB应用、减轻数据库负载。
Memcached是一种内存缓存,把经常需要存取的对象或数据缓存在内存中,内存中,缓存的这些数据通过API的方式被存取,数据经过利用HASH之后被存放到位于内存上的HASH表内,HASH表中的数据以key-value的形式存放,由于Memcached没有实现访问认证及安全管理控制,因此在面向internet的系统架构中,Memcached服务器通常位于用户的安全区域。
当Memcached服务器节点的物理内存剩余空间不足,Memcached将使用最近最少使用算法(LRU,LastRecentlyUsed)对最近不活跃的数据进行清理,从而整理出新的内存空间存放需要存储的数据。
Memcached在解决大规模集群数据缓存的诸多难题上有具有非常明显的优势并且还易于进行二次开发,因此越来越多的用户将其作为集群缓存系统,此外,Memcached开放式的API,使得大多数的程序语言都能使用Memcached,如javac、C/C++C#,Perl、python、PHP、Ruby 各种流行的编程语言。
由于Memcached的诸多优势,其已经成为众多开源项目的首选集群缓存系统。如openstacksd的keystone身份认证项目。就会利用Memcached来缓存租户的Token等身份信息,从而在用户登陆验证时无需查询存储在MySQL后端数据库中的用户信息,这在数据库高负荷运行下的大型openstack集群中能够极大地提高用户的身份验证过程,在如web管理界面Horizon和对象存储Swift项目也都会利用Memcached来缓存数据以提高客户端的访问请求响应速率。
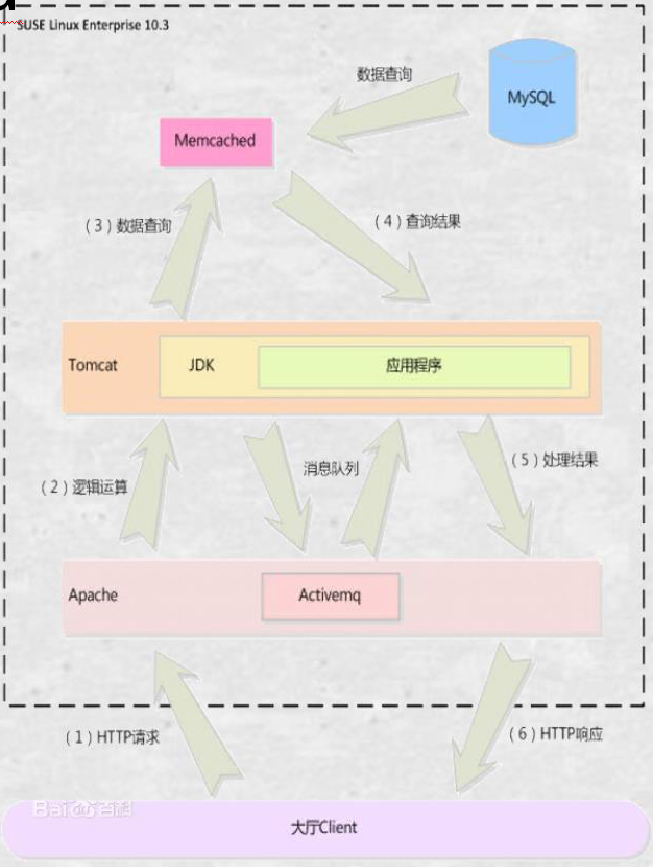
三、Memcached缓存流程
1. 检查客户端请求的数据是否在 Memcache 中,如果存在,直接将请求的数据返回,不在对数据进行任何操作。
2. 如果请求的数据不在 Memcache 中,就去数据库查询,把从数据库中获取的数据返回给客户端,同时把数据缓存一份 Memcache 中
3. 每次更新数据库的同时更新 Memcache 中的数据库。确保数据信息一致性。
4. 当分配给 Memcache 内存空间用完后,会使用LRU(least Recently Used ,最近最少使用 ) 策略加到其失效策略,失效的数据首先被替换掉,然后在替换掉最近未使用的数据。
四、Memcached功能特点
1. 协议简单
其使用基于文本行的协议,能直接通过 telnet 在Memcached 服务器上存取数据
2. 基于 libevent 的事件处理
libevent 利用 C 开发的程序库,它将 BSD 系统的kqueue,Linux 系统的 epoll 等事件处理功能封装成为一个接口,确保即使服务器端的链接数。加也能发挥很好的性能。 Memcached 利用这个库进行异步事件处理。
3. 内置的内存管理方式
Memcached 有一套自己管理内存的方式,这套方式非常高效,所有的数据都保存在Memcached内置的内存中,当存入的数据占满空间时,使用 LRU 算法自动删除不使用的缓存,即重用过期的内存空间。Memecached 不考虑数据的容灾问题,一旦重启所有数据全部丢失。
4. 节点相互独立的分布式
各个 Memecached 服务器之间互不通信,都是独立的存取数据,不共享任何信息。通过对客户端的设计,让 Memcached 具有分布式,能支持海量缓存和大规模应用。
五、使用Memcached应该考虑的因素
1. Memcached服务单点故障
在Memcached集群系统中每个节点独立存取数据,彼此不存在数据同步镜像机制,如果一个Memcached节点故障或者重启,则该节点缓存在内存的数据全部会丢失,再次访问时数据再次缓存到该服务器
2. 存储空间限制
Memcache缓存系统的数据存储在内存中,必然会受到寻址空间大小的限制,32为系统可以缓存的数据为2G,64位系统缓存的数据可以是无限的,要看Memcached服务器物理内存足够大即可
3. 存储单元限制
Memcache缓存系统以 key-value 为单元进行数据存储,能够存储的数据key尺寸大小为250字节,能够存储的value尺寸大小为1MB,超过这个值不允许存储
4. 数据碎片
Memcache缓存系统的内存存储单元是按照Chunk来分配的,这意味着不可能,所有存储的value数据大小正好等于一个Chunk的大小,因此必然会造成内存碎片,而浪费存储空间
5. 利旧算法局限性
Memcache缓存系统的LRU算法,并不是针对全局空间的存储数据的,而是针对Slab的,Slab是Memcached中具有同样大小的多个Chunk集合
6.数据访问安全性
Memcache缓存系统的慢慢Memcached服务端并没有相应的安全认证机制通过,通过非加密的telnet连接即可对Memcached服务器端的数据进行各种操作
云计算openstack共享组件(2)——Memcache 缓存系统的更多相关文章
- 云计算openstack共享组件——Memcache 缓存系统
一.缓存系统 静态web页面: 1.工作流程: 在静态Web程序中,客户端使用Web浏览器(IE.FireFox等)经过网络(Network)连接到服务器上,使用HTTP协议发起一个请求(Reques ...
- 云计算openstack共享组件——Memcache 缓存系统(4)
一.缓存系统 一.静态web页面: 1.在静态Web程序中,客户端使用Web浏览器(IE.FireFox等)经过网络(Network)连接到服务器上,使用HTTP协议发起一个请求(Request),告 ...
- 云计算OpenStack共享组件---Memcache缓存系统(3)
一.缓存系统 1.静态web页面: (1)在静态Web程序中,客户端使用Web浏览器(IE.FireFox等)经过网络(Network)连接到服务器上,使用HTTP协议发起一个请求(Request), ...
- 云计算openstack共享组件(3)——消息队列rabbitmq
队列(MQ)概念: MQ 全称为 Message Queue, 消息队列( MQ ) 是一种应用程序对应用程序的通信方法.应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链 ...
- 云计算openstack共享组件——消息队列rabbitmq(3)
一.MQ 全称为 Message Queue, 消息队列( MQ ) 是一种应用程序对应用程序的通信方法.应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们. 消息传 ...
- 云计算OpenStack共享组件---信息队列rabbitmq(2)
一.MQ 全称为 Message Queue, 消息队列( MQ ) 是一种应用程序对应用程序的通信方法.应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们. 消息传 ...
- 云计算openstack共享组件(1)——时间同步服务ntp
一.标准时间讲解 地球分为东西十二个区域,共计 24 个时区 格林威治作为全球标准时间即 (GMT 时间 ),东时区以格林威治时区进行加,而西时区则为减. 地球的轨道并非正圆,在加上自转速度逐年递减, ...
- 云计算openstack共享组件——时间同步服务ntp(2)
一.标准时间讲解 地球分为东西十二个区域,共计 24 个时区 格林威治作为全球标准时间即 (GMT 时间 ),东时区以格林威治时区进行加,而西时区则为减. 地球的轨道并非正圆,在加上自转速度逐年递减, ...
- openstack共享组件——Memcache 缓存系统(4)
云计算openstack共享组件——Memcache 缓存系统(4) 一.缓存系统 一.静态web页面: 1.在静态Web程序中,客户端使用Web浏览器(IE.FireFox等)经过网络(Netw ...
随机推荐
- Spring Cloud Eureka 你还在让它裸奔吗??
前些天栈长在微信公众号Java技术栈分享了 Spring Cloud Eureka 最新版 实现注册中心的实战教程:Spring Cloud Eureka 注册中心集群搭建,Greenwich 最新版 ...
- python接口自动化(九)--python中字典和json的区别(详解)
简介 这篇文章的由来是由于上一篇发送post请求的接口时候,参数传字典(dict)和json的缘故,因为python中,json和dict非常类似,都是key-value的形式,为啥还要这么传参,在群 ...
- UmengAppDemo【友盟统计SDK集成以及多渠道打包配置,基于V7.5.3版本】
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 前言 这里只是记录下集成友盟统计SDK以及简单配置多渠道打包的步骤.所以1.该Demo不能运行:2.配置多渠道打包只是一种简单的写法,具体 ...
- jdk切换小工具
今天无意之中看到一个小工具,就是可以自由切换jdk版本!以前每次切换jdk还要去找环境变量找半天,emmm.... 现在我们只需要双击一个xxx.bat的一个批处理文件,就可以自由切换jdk版本,很方 ...
- 玩转Spring Cloud之熔断降级(Hystrix)与监控
本文内容导航目录: 前言:解释熔断降级一.搭建服务消费者项目,并集成 Hystrix环境 1.1.在POM XML中添加Hystrix依赖(spring-cloud-starter-netflix-h ...
- 【转】IIS上的反向代理
http://blog.csdn.net/yuanguozhengjust/article/details/23576033 一直说在IIS上做反向代理,由于沉迷在nginx一行指令完事的美好情景当中 ...
- shiro缓存管理
一. 概述 Shiro作为一个开源的权限框架,其组件化的设计思想使得开发者可以根据具体业务场景灵活地实现权限管理方案,权限粒度的控制非常方便.首先,我们来看看Shiro框架的架构图:从上图我们可以很清 ...
- asp.net Core HttpClient 出现Cannot access a disposed object. Object name: 'SocketsHttpHandler' 的问题。
ASP.NET Core 部署在Centos 中 偶尔出现 One or more errors occurred. (Cannot access a disposed object.Object n ...
- 持续集成之 Spring Boot 实战篇
本文作者: CODING 用户 - 何健 这次实战篇,我们借助「CODING 持续集成」,实现一个简单的 Spring Boot 项目从编码到最后部署的完整过程.本教程还有 B 站视频版,帮助读者更好 ...
- oppo7.0系统手机(亲测有效)激活Xposed框架的流程
对于喜欢钻研手机的朋友而言,很多时候会使用到xposed框架及种类繁多功能极强的模块,对于5.0以下的系统版本,只要手机能获得root权限,安装和激活xposed框架是异常简单的,但随着系统版本的升级 ...