java解析xml字符串方法
一,用DOM4J 针对无重复标签的xml字符串格式,如下:
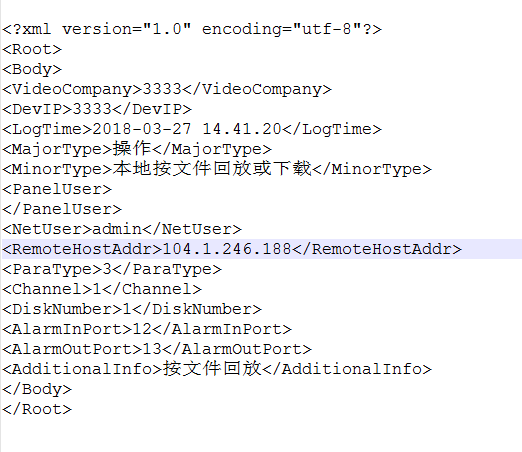
针对此种情况可用DOM4J解析法,引入 dom4j的相关jar包代码如下:
Document document=DocumentHelper.parseText(xmlStr);//xmlStr为上图格式的字符串
Node VideoCompany=document.selectSingleNode("//VideoCompany");//获取节点对象,注意引号内的“//”必须加 ,否则报错
Node DevIP=document.selectSingleNode("//DevIP");
//根据节点对象获取相应信息
String videoCompany=VideoCompany.getText();
String devIp=DevIP.getText();
System.out.println(devIp) //此时输出结果极为字符串:3333
二,用DOM 针对有重复标签的xml字符串格式,如下:
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book id="001">
<title>Harry Potter</title>
<author>J K. Rowling</author>
</book>
<book id="002">
<title>Learning XML</title>
<author>Erik T. Ray</author>
</book>
</books>
DOM 解析 XML
Java 中的 DOM 接口简介: JDK 中的 DOM API 遵循 W3C DOM 规范,其中 org.w3c.dom 包提供了 Document、DocumentType、Node、NodeList、Element 等接口, 这些接口均是访问 DOM 文档所必须的。我们可以利用这些接口创建、遍历、修改 DOM 文档。
javax.xml.parsers 包中的 DoumentBuilder 和 DocumentBuilderFactory 用于解析 XML 文档生成对应的 DOM Document 对象。
javax.xml.transform.dom 和 javax.xml.transform.stream 包中 DOMSource 类和 StreamSource 类,用于将更新后的 DOM 文档写入 XML 文件。
下面给出一个运用 DOM 解析 XML 的例子:
import java.io.File;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException; public class DOMParser {
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
//Load and parse XML file into DOM
public Document parse(String filePath) {
Document document = null;
try {
//DOM parser instance
DocumentBuilder builder = builderFactory.newDocumentBuilder();
//parse an XML file into a DOM tree
document = builder.parse(new File(filePath));
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return document;
} public static void main(String[] args) {
DOMParser parser = new DOMParser();
Document document = parser.parse("books.xml");
//get root element
Element rootElement = document.getDocumentElement(); //traverse child elements
NodeList nodes = rootElement.getChildNodes();
for (int i=0; i < nodes.getLength(); i++)
{
Node node = nodes.item(i);
if (node.getNodeType() == Node.ELEMENT_NODE) {
Element child = (Element) node;
//process child element
}
} NodeList nodeList = rootElement.getElementsByTagName("book");
if(nodeList != null)
{
for (int i = 0 ; i < nodeList.getLength(); i++)
{
Element element = (Element)nodeList.item(i);
String id = element.getAttribute("id");
}
}
}
}
在上面的例子中,DOMParser 的 Parse() 方法负责解析 XML 文件并生成对应的 DOM Document 对象。其中 DocumentBuilderFactory 用于生成 DOM 文档解析器以便解析 XML 文档。 在获取了 XML 文件对应的 Document 对象之后,我们可以调用一系列的 API 方便的对文档对象模型中的元素进行访问和处理。 需要注意的是调用 Element 对象的 getChildNodes() 方法时将返回其下所有的子节点,其中包括空白节点,因此需要在处理子 Element 之前对节点类型加以判断。
可以看出 DOM 解析 XML 易于开发,只需要通过解析器建立起 XML 对应的 DOM 树型结构后便可以方便的使用 API 对节点进行访问和处理,支持节点的删除和修改等。 但是 DOM 解析 XML 文件时会将整个 XML 文件的内容解析成树型结构存放在内存中,因此不适合用 DOM 解析很大的 XML 文件。
三.SAX 解析 例二中XML
与 DOM 建立树形结构的方式不同,SAX 采用事件模型来解析 XML 文档,是解析 XML 文档的一种更快速、更轻量的方法。 利用 SAX 可以对 XML 文档进行有选择的解析和访问,而不必像 DOM 那样加载整个文档,因此它对内存的要求较低。 但 SAX 对 XML 文档的解析为一次性读取,不创建任何文档对象,很难同时访问文档中的多处数据。
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.DefaultHandler;
import org.xml.sax.helpers.XMLReaderFactory; public class SAXParser { class BookHandler extends DefaultHandler {
private List<String> nameList;
private boolean title = false; public List<String> getNameList() {
return nameList;
}
// Called at start of an XML document
@Override
public void startDocument() throws SAXException {
System.out.println("Start parsing document...");
nameList = new ArrayList<String>();
}
// Called at end of an XML document
@Override
public void endDocument() throws SAXException {
System.out.println("End");
} /**
* Start processing of an element.
* @param namespaceURI Namespace URI
* @param localName The local name, without prefix
* @param qName The qualified name, with prefix
* @param atts The attributes of the element
*/
@Override
public void startElement(String uri, String localName, String qName,
Attributes atts) throws SAXException {
// Using qualified name because we are not using xmlns prefixes here.
if (qName.equals("title")) {
title = true;
}
} @Override
public void endElement(String namespaceURI, String localName, String qName)
throws SAXException {
// End of processing current element
if (title) {
title = false;
}
} @Override
public void characters(char[] ch, int start, int length) {
// Processing character data inside an element
if (title) {
String bookTitle = new String(ch, start, length);
System.out.println("Book title: " + bookTitle);
nameList.add(bookTitle);
}
} } public static void main(String[] args) throws SAXException, IOException {
XMLReader parser = XMLReaderFactory.createXMLReader();
BookHandler bookHandler = (new SAXParser()).new BookHandler();
parser.setContentHandler(bookHandler);
parser.parse("books.xml");
System.out.println(bookHandler.getNameList());
}
}
SAX 解析器接口和事件处理器接口定义在 org.xml.sax 包中。主要的接口包括 ContentHandler、DTDHandler、EntityResolver 及 ErrorHandler。 其中 ContentHandler 是主要的处理器接口,用于处理基本的文档解析事件;DTDHandler 和 EntityResolver 接口用于处理与 DTD 验证和实体解析相关的事件; ErrorHandler 是基本的错误处理接口。DefaultHandler 类实现了上述四个事件处理接口。上面的例子中 BookHandler 继承了 DefaultHandler 类, 并覆盖了其中的五个回调方法 startDocument()、endDocument()、startElement()、endElement() 及 characters() 以加入自己的事件处理逻辑
四、XML解析总结
JDOM 和 DOM 在性能测试时表现不佳,在测试 10M 文档时内存溢出。在小文档情况下还值得考虑使用 DOM 和 JDOM。虽然 JDOM 的开发者已经说明他们期望在正式发行版前专注性能问题,但是从性能观点来看,它确实没有值得推荐之处。另外,DOM
仍是一个非常好的选择。DOM 实现广泛应用于多种编程语言。它还是许多其它与 XML 相关的标准的基础,因为它正式获得 W3C 推荐(与基于非标准的 Java 模型相对),所以在某些类型的项目中可能也需要它(如在 JavaScript 中使用 DOM)。
SAX表现较好,这要依赖于它特定的解析方式。一个 SAX 检测即将到来的XML流,但并没有载入到内存(当然当XML流被读入时,会有部分文档暂时隐藏在内存中)。
DOM4J,目前许多开源项目中大量采用 DOM4J,例如大名鼎鼎的 Hibernate 也用 DOM4J 来读取 XML 配置文件。如果不考虑可移植性,那就推荐采用DOM4J。
java解析xml字符串方法的更多相关文章
- 最简单的JAVA解析XML字符串方法
引入 dom4j 包<dependency> <groupId>dom4j</groupId> <artifactId>dom4j</artifa ...
- java解析xml字符串(用dom4j)
package com.smsServer.Dhst; import java.util.HashMap; import java.util.Iterator; import java.util.Ma ...
- java解析xml字符串为实体(dom4j解析)
package com.smsServer.Dhst; import java.util.HashMap; import java.util.Iterator; import java.util.Ma ...
- java解析XML的方法
1.DOM 实现方法 xml文件 <?xml version="1.0" encoding="utf-8"?> <Accounts> & ...
- Java解析XML字符串,取出其中<aaaa><![CDATA[(XXX)]]></aaa>里面的XXX值,也可以使用xml解析的其他方式,这是最简单的字符串解析
直接贴一段业务代码,这段代码是解析请求返回的xml格式字符串,为了取出其中的值便于下一步的使用. @RequestMapping(value="/search",produces ...
- Java解析XML的四种方法详解 - 转载
XML现在已经成为一种通用的数据交换格式,平台的无关性使得很多场合都需要用到XML.本文将详细介绍用Java解析XML的四种方法 在做一般的XML数据交换过程中,我更乐意传递XML字符串,而不是格式化 ...
- java解析xml的三种方法
java解析XML的三种方法 1.SAX事件解析 package com.wzh.sax; import org.xml.sax.Attributes; import org.xml.sax.SAXE ...
- 【Java】详解Java解析XML的四种方法
XML现在已经成为一种通用的数据交换格式,平台的无关性使得很多场合都需要用到XML.本文将详细介绍用Java解析XML的四种方法. AD: XML现在已经成为一种通用的数据交换格式,它的平台无关性,语 ...
- 使用Java解析XML文件或XML字符串的例子
转: 使用Java解析XML文件或XML字符串的例子 2017年09月16日 11:36:18 inter_peng 阅读数:4561 标签: JavaXML-Parserdom4j 更多 个人分类: ...
随机推荐
- C语言中字符串常用函数--strcat,strcpy
strcpy 原型声明:extern char *strcpy(char* dest, const char *src); 头文件:#include <string.h> 功能:把从src ...
- Android图片加载库Fresco
在Android设备上面,快速高效的显示图片是极为重要的.过去的几年里,我们在如何高效的存储图像这方面遇到了很多问题.图片太大,但是手机的内存却很小.每一个像素的R.G.B和alpha通道总共要占用4 ...
- 简述Java内存泄露
翻译人员: 铁锚翻译时间: 2013年11月4日原文链接: The Introduction of Memory Leaks内存管理一直是Java 所鼓吹的强大优点.开发者只需要简单地创建对象,而Ja ...
- MPLSVPN 命令集
载请标明出处:http://blog.csdn.net/sk719887916,作者:skay 读懂下面配置命令需要有一定的TCP/IP,路由协议基础,现在直接上关键VPN命令. router ...
- C语言中的位运算和逻辑运算
这篇文章来自:http://blog.csdn.net/qp120291570/article/details/8708286 位运算 C语言中的位运算包括与(&),或(|),亦或(^),非( ...
- java垃圾回收机制,以及常用的回收算法
记得之前去平安面试的时候,面试官问到了垃圾回收,我当时也就是说说了垃圾回收的原理,但是具体有哪些实现策略,我当时是懵的. 概念: Java的垃圾回收机制是Java虚拟机提供的能力,用于在空闲时间以不定 ...
- android动画介绍--Animation 实现loading动画效果
Animation的使用方法并不难.这里简单的介绍一下使用方法. 先看效果图: 效果还是不错的吧. 下面来看看使用方法. 动画效果是通过Animation来实现的,一共有四种,分别为: AlphaAn ...
- OAF开发概念和案例总结(项目总结)
留看: 网上关于OAF学习的资料比较少,最近有些时间,整理了下自己在项目上的经验总结和同学们一下共享一下 和学友一起讨论一下OAF开发,还有两个比较复杂的系列正在整理中..... 一.OAF EO定义 ...
- 【生活随笔】Introspection of my life in 2014
2014年已过去两星期,有写年度总结的必要了.今天特意看了看去年1月5日写的2013年度总结,看看都有些什么变化.我发现每年作一次总结是很有必要的,无赖恰逢考试周,连元旦都不能好好过,更不用说写 ...
- 剑指offer面试题48: 最长不含重复字符的子字符串
Given a string, find the length of the longest substring without repeating characters.(请从子字符串中找出一个最长 ...