ASP.NET Core Web API下事件驱动型架构的实现(四):CQRS架构中聚合与聚合根的实现
在前面两篇文章中,我详细介绍了基本事件系统的实现,包括事件派发和订阅、通过事件处理器执行上下文来解决对象生命周期问题,以及一个基于RabbitMQ的事件总线的实现。接下来对于事件驱动型架构的讨论,就需要结合一个实际的架构案例来进行分析。在领域驱动设计的讨论范畴,CQRS架构本身就是事件驱动的,因此,我打算首先介绍一下CQRS架构下相关部分的实现,然后再继续讨论事件驱动型架构实现的具体问题。
当然,CQRS架构本身的实现也是根据实际情况的不同,需要具体问题具体分析的,不仅如此,CQRS架构的实现也是非常复杂的,绝不是一套文章一套案例能够解释清楚并涵盖全部的。所以,我不会把大部分篇幅放在CQRS架构实现的细节上,而是会着重介绍与我们的主题相关的内容,并对无关的内容进行弱化。或许,在这个系列文章结束的时候,我们会得到一个完整的、能够运行的CQRS架构系统,不过,这套系统极有可能仅供技术研讨和学习使用,无法直接用于生产环境。
基于这样的前提,我们今天首先看一下CQRS架构中聚合与聚合根的实现,或许你会觉得目前讨论的内容与你本打算关心的事件驱动架构没什么关系,而事实是,CQRS架构中聚合与聚合根的实现是完全面向事件驱动的,而这部分内容也会为我们之后的讨论做下铺垫。不仅如此,我还会在本文讨论一些基于.NET/C#的软件架构设计的思考与实践(请注意文章中我添加了Note字样并且字体加粗的句子),因此,我还是会推荐你继续读完这篇文章。
CQRS架构知识回顾
早在2010年,我针对CQRS架构总结过一篇文章,题目是:《EntityFramework之领域驱动设计实践【扩展阅读】:CQRS体系结构模式》,当然,这篇文章跟Entity Framework本没啥关系,只是延续了领域驱动设计这一话题进行的扩展讨论罢了。这篇文章介绍了CQRS架构模式所产生的背景、结构,以及相关的一些概念,比如:最近非常流行的词语:“事件溯源”、解决事件溯源性能问题的“快照”、用于存取事件数据的“事件存储(Event Store)”,还有重新认识了什么叫做“对象的状态”,等等。此外,在后续的博文中,我也经常对CQRS架构中的实现细节做些探讨,有兴趣的读者可以翻看我过去的博客文章。总体上讲,CQRS架构基本符合下图所描述的结构:
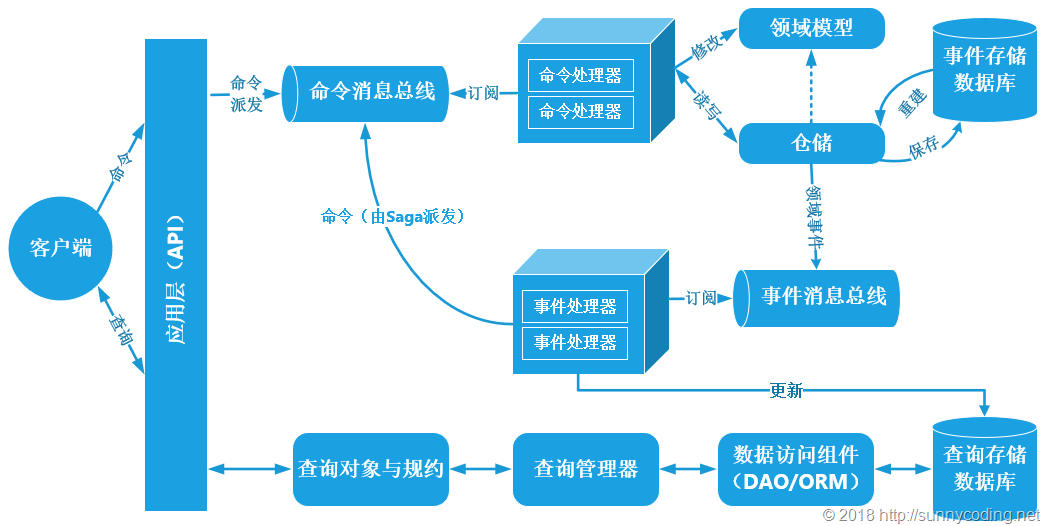
看上去是不是特别复杂?没错,特别复杂,而且每个部分都可以使用不同的工具、框架,以不同的形式进行实现。整个架构甚至可以是语言、平台异构的,还可以跟外部系统进行整合,实现大数据分析、呈现等等,玩法可谓之五花八门,这些统统都不在我们的讨论范围之内。我们今天打算讨论的,就是上图右上部分“领域模型”框框里的主题:CQRS架构中的聚合与聚合根。
说到聚合与聚合根,了解过领域驱动设计(DDD)的读者肯定对这两个概念非常熟悉。通常情况下,具有相同生命周期,组合起来能够共同表述一种领域概念的一组模型对象,就可以组成一个聚合。在每个聚合中,衔接各个领域模型对象,并向外提供统一访问聚合的对象,就是聚合根。聚合中的所有对象,离开聚合根,就不能完整地表述一个领域概念。比如:收货地址无法离开客户,订单详情无法离开订单,库存无法离开货品等等。所以从定义上来看,一个聚合大概就是这样:
- 聚合中的对象可以是实体,也可以是值对象
- 聚合中所有对象具有相同的生命周期
- 外界通过聚合根访问整个聚合,聚合根通过导航属性(Navigation Properties)进而访问聚合中的其它实体和值对象
- 通过以上两点,可以得出:工厂和仓储必须针对聚合根进行操作
- 聚合根是一个实体
- 聚合中的对象是有状态的,通常会通过C#的属性(Properties)将状态曝露给外界
好吧,对这些概念比较熟悉的读者来说,我在此算是多啰嗦了几句。接下来,让我们结合CQRS架构中命令处理器对领域模型的更改过程来看看,除了以上这些常规特征之外,聚合与聚合根还有哪些特殊之处。当命令处理器接到操作命令时,便开始对领域模型进行更改,步骤如下:
- 首先,命令处理器通过仓储,获取具有指定ID值的聚合(聚合的ID值就是聚合根的ID值)
- 然后,仓储访问事件存储数据库,根据需要获取的聚合根的类型,以及ID值,获取所有关联的领域事件
- 其次,仓储构造聚合对象实例,并依照一定的顺序,逐一将领域事件重新应用在新构建的聚合上
- 每当有一个领域事件被应用在聚合上时,聚合本身的内联事件处理器会捕获这个领域事件,并根据领域事件中的数据,设置聚合中对象的状态
- 当所有的领域事件全部应用在聚合上时,聚合的状态就是曾经被保存时的状态
- 然后,仓储将已经恢复了状态的聚合返回给命令处理器,命令处理器调用聚合上的方法,对聚合进行更改
- 在调用方法的时候,方法本身会产生一个领域事件,这个领域事件会立刻被聚合本身的内联事件处理器捕获,并进行处理。在处理的过程中,会更新聚合中对象的状态,同时,这个领域事件还会被缓存在聚合中
- 命令处理器在完成对聚合的更改之后,便会调用仓储,将更改后的模型保存下来
- 接着,仓储从聚合中获得所有缓存的未曾保存的领域事件,并将所有这些领域事件逐个保存到事件存储数据库。在成功完成保存之后,会清空聚合中的事件缓存
- 最后,仓储将所有的这些领域事件逐个地派发到事件消息总线
接下来在事件消息总线和事件处理器中将会发生的事情,我们今后还会讨论,这里就不多说了。从这个过程,我们不难得出:
- CQRS的聚合中,更改对象状态必须通过领域事件,也就是说,不能向外界曝露直接访问对象状态的接口,更通俗地说,表示对象状态的属性(Property)不能有设置器(Setter)
- CQRS聚合的聚合根中,会有一套内联的领域事件处理机制,用来捕获并处理聚合中产生的领域事件
- CQRS聚合的聚合根会有一个保存未提交领域事件的本地缓存,对该缓存的访问应该是线程安全的
- CQRS的聚合需要能够向仓储提供必要的接口,比如清除事件缓存的方法等
- 此外,CQRS聚合是有版本号的,版本号通常是一个64位整型,表述历史上发生在聚合上的领域事件一共有多少个。当然,这个值在我们目前的讨论中并非能够真正用得上,但是,在仓储重建聚合需要依赖快照时,这个版本号就非常重要了。我会在后续文章中介绍
听起来是不是非常复杂?确实如此。那我们就先从领域事件入手,逐步实现CQRS中的聚合与聚合根。
领域事件
领域事件,顾名思义,就是从领域模型中产生的事件消息。概念上很简单,比如,客户登录网站,就会由客户登录实体产生一个事件派发出去,例如CustomerLoggedOnEvent,表示客户登录这件事已经发生了。虽然在DDD的实践中,领域事件更多地在CQRS架构中被讨论,其实即便是非事件驱动型架构,也可以通过领域模型来发布消息,达到系统解耦的目的。
延续之前的设计,我们的领域事件继承了IEvent接口,并增加了三个属性/方法,此外,为了编程方便,我们实现了领域事件的抽象类,UML类图如下:
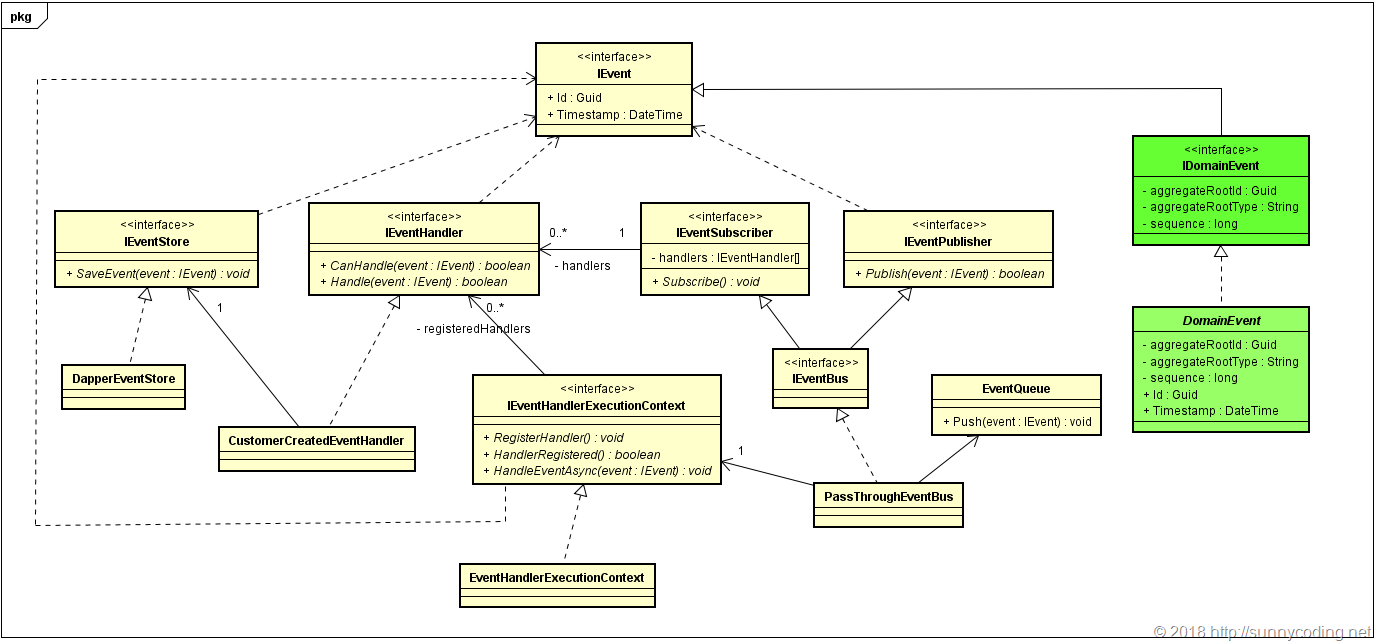
图中的绿色部分就是在之前我们的事件模型上新加的接口和类,用以表述领域事件的概念。其中:
- aggregateRootId:发生该领域事件的聚合的聚合根的ID值
- aggregateRootType:发生该领域事件的聚合的聚合根的类型
- sequence:该领域事件的序列号
好了,如果说我们将发生在某聚合上的领域事件保存到关系型数据库,那么,当需要获得该聚合的所有领域事件时,只需要下面一句SQL就行了:
SELECT * FROM [Events] WHERE [AggregateRootId]=aggregateRootId AND [AggregateRootType]=aggregateRootType ORDER BY [Sequence] ASC
这就是最简单的事件存储数据库的实现了。不过,我们暂时不介绍这些内容。
事实上,与标准的事件(IEvent接口)相比,除了上面三个主要的属性之外,领域事件还可以包含更多的属性和方法,这就要看具体的需求和设计了。不过目前为止,我们定义这三个属性已经够用了,不要把问题搞得太复杂。
有了领域事件的基本模型,我们开始设计CQRS下的聚合。
聚合的设计与实现
由于外界访问聚合都是通过聚合根来实现的,因此,针对聚合的操作都会被委托给聚合根来处理。比如,当用户地址发生变化时,服务层会调用Customer.ChangeAddress方法,这个方法就会产生一个领域事件,并通过内联的事件处理机制更改聚合中Address值对象中的状态。于是,从技术角度,聚合的设计也就是聚合根的实现。
接口与类之间的关系
首先需要设计的是与聚合相关的概念所表述的接口、类及其之间的关系。结合领域驱动设计中的概念,我们得到下面的设计:
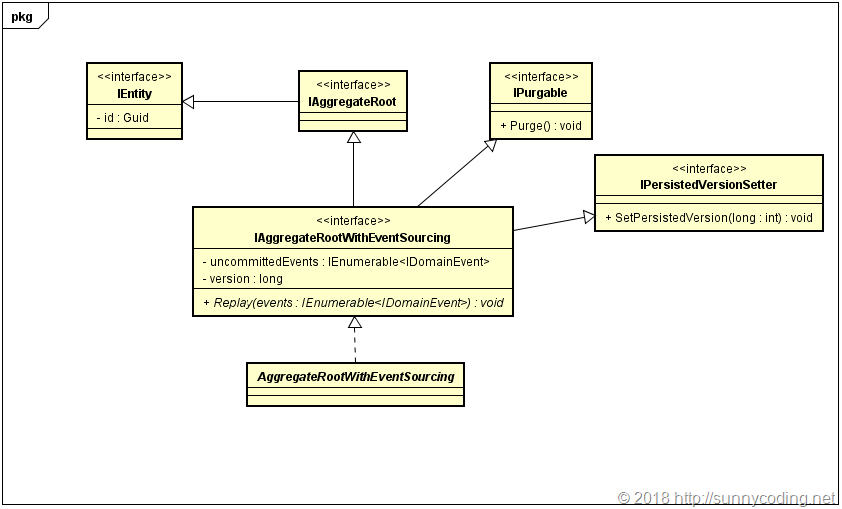
其中,实体(IEntity)、聚合根(IAggregateRoot)都是大家耳熟能详的领域驱动设计的概念。由于实体都是通过Id进行唯一标识,所以,IEntity会有一个id的属性,为了简单起见,我们使用Guid作为它的类型。聚合根(IAggregateRoot)继承于IEntity接口,有趣的是,在我们目前的场景中,IAggregateRoot并不包含任何成员,它仅仅是一个空接口,在整个框架代码中,它仅作为泛型的类型约束。Note:这种做法其实也是非常常见的一种框架设计模式。具有事件溯源能力的聚合根(IAggregateRootWithEventSourcing)又继承于IAggregateRoot接口,并且有如下三个成员:
- uncommittedEvents:用于缓存发生在当前聚合中的领域事件
- version:表示当前聚合的版本号
- Replay:将指定的一系列领域事件“应用”到当前的聚合上,也就是所谓的事件回放
此外,你还发现我们还有两个神奇的接口:IPurgable和IPersistedVersionSetter。这两个接口的职责是:
- IPurgable表示,实现了该接口的类型具有某种清空操作,比如清空某个队列,或者将对象状态恢复到初始状态。让IAggregateRootWithEventSourcing继承于该接口是因为,当仓储完成了聚合中领域事件的保存和派发之后,需要清空聚合中缓存的事件,以保证在今后,发生在同一时间点的同样的事件不会被再次保存和派发
- IPersistedVersionSetter接口允许调用者对聚合的“保存版本号”进行设置。这个版本号表示了在事件存储中,属于当前聚合的所有事件的个数。试想,如果一个聚合的“保存版本号”为4(即在事件存储中有4个事件是属于该聚合的),那么,如果再有2个事件发生在这个聚合中,于是,该聚合的版本就是4+2=6.
Note:为什么不将这两个接口中的方法直接放在IAggregateRootWithEventSourcing中呢?是因为单一职责原则。聚合本身不应该存在所谓之“清空缓存”或者“设置保存版本号”这样的概念,这样的概念对于技术人员来说比较容易理解,可是如果将这些技术细节加入领域模型中,就会污染领域模型,造成领域专家无法理解领域模型,这是违背面向对象分析与设计的单一职责原则的,也违背了领域驱动设计的原则。那么,即使把这些方法通过额外的接口独立出去,实现了IAggregateRootWithEventSourcing接口的类型,不还是要实现这两个接口中的方法吗?这样,聚合的访问者不还是可以访问这两个额外的方法吗?的确如此,这些接口是需要被实现的,但是我们可以使用C#中接口的显式实现,这样的话,如果不将IAggregateRootWithEventSourcing强制转换成IPurgable或者IPersistedVersionSetter的话,是无法直接通过聚合根对象本身来访问这些方法的,这起到了非常好的保护作用。接口的显式实现在软件系统的框架设计中也是常用手段。
抽象类AggregateRootWithEventSourcing的实现
在上面的类图中,IAggregateRootWithEventSourcing最终由AggregateRootWithEventSourcing抽象类实现。不要抱怨类的名字太长,它有助于我们理解这一类型在我们的领域模型中的角色和功能。下面的代码列出了该抽象类的主要部分的实现:
public abstract class AggregateRootWithEventSourcing : IAggregateRootWithEventSourcing
{
private readonly Lazy<Dictionary<string, MethodInfo>> registeredHandlers;
private readonly Queue<IDomainEvent> uncommittedEvents = new Queue<IDomainEvent>();
private Guid id;
private long persistedVersion = 0;
private object sync = new object(); protected AggregateRootWithEventSourcing()
: this(Guid.NewGuid())
{ } protected AggregateRootWithEventSourcing(Guid id)
{
registeredHandlers = new Lazy<Dictionary<string, MethodInfo>>(() =>
{
var registry = new Dictionary<string, MethodInfo>();
var methodInfoList = from mi in this.GetType().GetMethods(BindingFlags.Public | BindingFlags.NonPublic | BindingFlags.Instance)
let returnType = mi.ReturnType
let parameters = mi.GetParameters()
where mi.IsDefined(typeof(HandlesInlineAttribute), false) &&
returnType == typeof(void) &&
parameters.Length == 1 &&
typeof(IDomainEvent).IsAssignableFrom(parameters[0].ParameterType)
select new { EventName = parameters[0].ParameterType.FullName, MethodInfo = mi }; foreach (var methodInfo in methodInfoList)
{
registry.Add(methodInfo.EventName, methodInfo.MethodInfo);
} return registry;
}); Raise(new AggregateCreatedEvent(id));
} public Guid Id => id; long IPersistedVersionSetter.PersistedVersion { set => Interlocked.Exchange(ref this.persistedVersion, value); } public IEnumerable<IDomainEvent> UncommittedEvents => uncommittedEvents; public long Version => this.uncommittedEvents.Count + this.persistedVersion; void IPurgable.Purge()
{
lock (sync)
{
uncommittedEvents.Clear();
}
} public void Replay(IEnumerable<IDomainEvent> events)
{
((IPurgable)this).Purge();
events.OrderBy(e => e.Timestamp)
.ToList()
.ForEach(e =>
{
HandleEvent(e);
Interlocked.Increment(ref this.persistedVersion);
});
} [HandlesInline]
protected void OnAggregateCreated(AggregateCreatedEvent @event)
{
this.id = @event.NewId;
} protected void Raise<TDomainEvent>(TDomainEvent domainEvent)
where TDomainEvent : IDomainEvent
{
lock (sync)
{
// 首先处理事件数据。
this.HandleEvent(domainEvent);
// 然后设置事件的元数据,包括当前事件所对应的聚合根类型以及
// 聚合的ID值。
domainEvent.AggregateRootId = this.id;
domainEvent.AggregateRootType = this.GetType().AssemblyQualifiedName;
domainEvent.Sequence = this.Version + 1;
// 最后将事件缓存在“未提交事件”列表中。
this.uncommittedEvents.Enqueue(domainEvent);
}
} private void HandleEvent<TDomainEvent>(TDomainEvent domainEvent)
where TDomainEvent : IDomainEvent
{
var key = domainEvent.GetType().FullName;
if (registeredHandlers.Value.ContainsKey(key))
{
registeredHandlers.Value[key].Invoke(this, new object[] { domainEvent });
}
}
}
上面的代码不算复杂,它根据上面的分析和描述,实现了IAggregateRootWithEventSourcing接口,篇幅原因,就不多做解释了,不过有几点还是可以鉴赏一下的:
- 使用Lazy类型来保证领域事件处理器的容器在整个聚合生命周期中只初始化一次
- 通过lock语句和Interlocked.Exchange来保证类型的线程安全和数值的原子操作
- 聚合根被构造的时候,会找到当前类型中所有标记了HandlesInlineAttribute特性,并具有一定特征的函数,将它们作为领域事件的内联处理器,注册到容器中
- 每当聚合中的某个业务操作(方法)需要更改聚合中的状态时,就调用Raise方法来产生领域事件,由对应的内联处理器捕获领域事件,并在处理器方法中设置聚合的状态
- Replay方法会遍历所有给点的领域事件,调用HandleEvent方法,实现事件回放
现在,我们已经实现了CQRS架构下的聚合与聚合根,虽然实际上这个结构有可能比我们的实现更为复杂,但是目前的这个设计已经能够满足我们进一步研究讨论的需求了。下面,我们再更进一步,看看CQRS中仓储应该如何实现。
仓储实现初探
为什么说是“初探”?因为我们目前打算实现的仓储暂时不包含事件派发的逻辑,这部分内容我会在后续文章中讲解。首先看看,仓储的接口是什么样的。在CQRS架构中,仓储只具备两种操作:
- 保存聚合
- 根据聚合ID(也就是聚合根的ID)值,获取聚合对象
你或许会问,那根据某个条件查询满足该条件的所有聚合对象呢?注意,这是CQRS架构中查询部分的职责,不属于我们的讨论范围。
通常,仓储的接口定义如下:
public interface IRepository
{
Task SaveAsync<TAggregateRoot>(TAggregateRoot aggregateRoot)
where TAggregateRoot : class, IAggregateRootWithEventSourcing; Task<TAggregateRoot> GetByIdAsync<TAggregateRoot>(Guid id)
where TAggregateRoot : class, IAggregateRootWithEventSourcing;
}
与之前领域事件的设计类似,我们为仓储定义一个抽象类,所有仓储的实现都应该基于这个抽象类:
public abstract class Repository : IRepository
{
protected Repository()
{ } public async Task<TAggregateRoot> GetByIdAsync<TAggregateRoot>(Guid id)
where TAggregateRoot : class, IAggregateRootWithEventSourcing
{
var domainEvents = await LoadDomainEventsAsync(typeof(TAggregateRoot), id);
var aggregateRoot = ActivateAggregateRoot<TAggregateRoot>();
aggregateRoot.Replay(domainEvents);
return aggregateRoot;
} public async Task SaveAsync<TAggregateRoot>(TAggregateRoot aggregateRoot)
where TAggregateRoot : class, IAggregateRootWithEventSourcing
{
var domainEvents = aggregateRoot.UncommittedEvents;
await this.PersistDomainEventsAsync(domainEvents);
aggregateRoot.PersistedVersion = aggregateRoot.Version;
aggregateRoot.Purge();
} protected abstract Task<IEnumerable<IDomainEvent>> LoadDomainEventsAsync(Type aggregateRootType, Guid id); protected abstract Task PersistDomainEventsAsync(IEnumerable<IDomainEvent> domainEvents); private TAggregateRoot ActivateAggregateRoot<TAggregateRoot>()
where TAggregateRoot : class, IAggregateRootWithEventSourcing
{
var constructors = from ctor in typeof(TAggregateRoot).GetTypeInfo().GetConstructors()
let parameters = ctor.GetParameters()
where parameters.Length == 0 ||
(parameters.Length == 1 && parameters[0].ParameterType == typeof(Guid))
select new { ConstructorInfo = ctor, ParameterCount = parameters.Length }; if (constructors.Count() > 0)
{
TAggregateRoot aggregateRoot;
var constructorDefinition = constructors.First();
if (constructorDefinition.ParameterCount == 0)
{
aggregateRoot = (TAggregateRoot)constructorDefinition.ConstructorInfo.Invoke(null);
}
else
{
aggregateRoot = (TAggregateRoot)constructorDefinition.ConstructorInfo.Invoke(new object[] { Guid.NewGuid() });
} // 将AggregateRoot下的所有事件清除。事实上,在AggregateRoot的构造函数中,已经产生了AggregateCreatedEvent。
aggregateRoot.Purge();
return aggregateRoot;
} return null;
}
}
代码也是非常简单、容易理解的:GetByIdAsync方法根据给定的聚合根类型以及ID值,从后台存储中读取所有属于该聚合的领域事件,并在聚合上进行回放,以便将聚合恢复到存储前的状态;SaveAsync方法则从聚合根上获得所有未被提交的领域事件,将这些事件保存到后台存储,然后设置聚合的“已保存版本”,最后清空未提交事件的缓存。剩下的就是如何实现LoadDomainEventsAsync以及PersistDomainEventsAsync两个方法了。而这两个方法,原本就应该是事件存储对象的职责范围了。
Note:你也许会问:如果某个聚合从开始到现在,已经发生了大量的领域事件了,那么这样一条条地将事件回放到聚合上,岂不是性能非常低下?没错,这个问题我们可以通过快照来解决。在后续文章中我会介绍。你还会问:日积月累,事件存储系统中的事件数量岂不是会越来越多吗?需要删除吗?答案是:不删!不过可以对数据进行归档,或者依赖一些第三方框架来处理这个问题,但是,从领域驱动设计的角度,领域事件代表着整个领域模型系统中发生过的所有事情,事情既然已经发生,就无法再被抹去,因此,删除事件存储系统中的事件是不合理的。那数据量越来越大怎么办?答案是:或许,存储硬件设备要比业务数据更便宜。
仓储的实现我们暂且探索到这一步,目前我们只需要有一个正确的聚合保存、读取(通过领域事件重塑)的逻辑就可以了,并不需要关心事件本身是如何被读取被保存的。接下来,我们在.NET Core的测试项目中,借助Moq框架,通过Mock一个假想的仓储,来验证整个系统从聚合、聚合根的实现到仓储设计的正确性。
使用Moq框架,通过单元测试验证聚合、聚合根以及仓储设计的正确性
Moq是一个很好的Mock框架,简单轻量,而且支持.NET Core,在单元测试的项目中使用Moq是一种很好的实践。Moq上手非常简单,只需要在单元测试项目上添加Moq的NuGet依赖包就可以开始着手编写测试用例了。为了测试我们的聚合根以及仓储对聚合根保存、读取的设计,首先我们定义一个简单的聚合:
public class Book : AggregateRootWithEventSourcing
{
public void ChangeTitle(string newTitle)
{
this.Raise(new BookTitleChangedEvent(newTitle));
} public string Title { get; private set; } [HandlesInline]
private void OnTitleChanged(BookTitleChangedEvent @event)
{
this.Title = @event.NewTitle;
} public override string ToString()
{
return Title;
}
}
Book类是一个聚合根,它继承AggregateRootWithEventSourcing抽象类,同时它有一个属性,Title,表示书的名称,而ChangeTitle方法(业务方法)会直接产生一个BookTitleChangedEvent领域事件,之后,OnTitleChanged成员函数会负责将领域事件中的NewTitle的值设置到Book聚合根的Title状态上,完成书本标题的更新。与之相关的BookTitleChangedEvent的定义如下:
public class BookTitleChangedEvent : DomainEvent
{
public BookTitleChangedEvent(string newTitle)
{
this.NewTitle = newTitle;
} public string NewTitle { get; set; } public override string ToString()
{
return $"{Sequence} - {NewTitle}";
}
}
首先,下面两个测试用例用于测试Book聚合本身产生领域事件的过程是否正确,如果正确,那么当Book本身本构造时,会产生一个AggregateCreatedEvent,如果更改书本的标题,则又会产生一个BookTitleChangedEvent,所以,第一个测试中,book的版本应该为1,而第二个则为2:
[Fact]
public void CreateBookTest()
{
// Arrange & Act
var book = new Book();
// Assert
Assert.NotEqual(Guid.Empty, book.Id);
Assert.Equal(1, book.Version);
} [Fact]
public void ChangeBookTitleEventTest()
{
// Arrange
var book = new Book();
// Act
book.ChangeTitle("Hit Refresh");
// Assert
Assert.Equal("Hit Refresh", book.Title);
Assert.Equal(2, book.UncommittedEvents.Count());
Assert.Equal(2, book.Version);
}
接下来,测试仓储保存Book聚合的正确性,因为我们没有实现一个有效的仓储实例,因此,这里借助Moq帮我们动态生成。在下面的代码中,让Moq对仓储抽象类的PersisDomainEventsAsync受保护成员进行动态生成,指定当它被任何IEnumerable<IDomainEvent>作为参数调用时,都将这些事件保存到一个本地的List中,于是,最后只需要检查List中的领域事件是否符合我们的要求就可以了。代码如下:
[Fact]
public async Task PersistBookTest()
{
// Arrange
var domainEventsList = new List<IDomainEvent>();
var mockRepository = new Mock<Repository>(); mockRepository.Protected().Setup<Task>("PersistDomainEventsAsync",
ItExpr.IsAny<IEnumerable<IDomainEvent>>())
.Callback<IEnumerable<IDomainEvent>>(evnts => domainEventsList.AddRange(evnts))
.Returns(Task.CompletedTask); var book = new Book();
// Act
book.ChangeTitle("Hit Refresh");
await mockRepository.Object.SaveAsync(book); // Assert
Assert.Equal(2, domainEventsList.Count);
Assert.Empty(book.UncommittedEvents);
Assert.Equal(2, book.Version);
}
同理,我们还可以测试仓储读取聚合并恢复聚合状态的正确性,同样还是使用Moq对仓储的LoadDomainEventsAsync进行Mock:
[Fact]
public async Task RetrieveBookTest()
{
// Arrange
var fakeId = Guid.NewGuid();
var domainEventsList = new List<IDomainEvent>
{
new AggregateCreatedEvent(fakeId),
new BookTitleChangedEvent("Hit Refresh")
};
var mockRepository = new Mock<Repository>();
mockRepository.Protected().Setup<Task<IEnumerable<IDomainEvent>>>("LoadDomainEventsAsync",
ItExpr.IsAny<Type>(),
ItExpr.IsAny<Guid>())
.Returns(Task.FromResult(domainEventsList.AsEnumerable())); // Act
var book = await mockRepository.Object.GetByIdAsync<Book>(fakeId); // Assert
Assert.Equal(fakeId, book.Id);
Assert.Equal("Hit Refresh", book.Title);
Assert.Equal(2, book.Version);
Assert.Empty(book.UncommittedEvents);
}
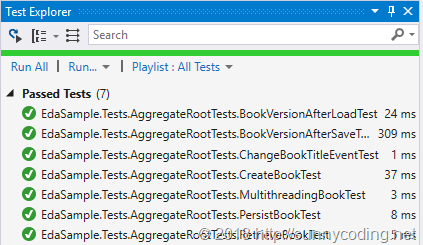
好了,其它的几个测试用例就不多做介绍了,使用Visual Studio运行一下测试然后查看结果就可以了:
总结
本文又是一篇长篇幅的文章,好吧,要介绍的东西太多,而且这些内容又不能单独割开成多个主题,所以也就很难控制篇幅了。文章主要介绍了基于CQRS架构的聚合以及聚合根的设计与实现,同时引出了仓储的部分实现,这些内容也是为今后进一步讨论事件驱动型架构做准备。本文介绍的内容对于一个真实的CQRS系统实现来说还是有一定差距的,但总体结构也大致如此。文中还提及了快照的概念,这部分内容我今后在介绍事件存储的实现部分还会详细讨论,下一章打算扩展一下仓储本身,了解一下仓储对领域事件的派发,以及事件处理器对领域事件的处理。
源代码的使用
本系列文章的源代码在https://github.com/daxnet/edasample这个Github Repo里,通过不同的release tag来区分针对不同章节的源代码。本文的源代码请参考chapter_4这个tag,如下:
ASP.NET Core Web API下事件驱动型架构的实现(四):CQRS架构中聚合与聚合根的实现的更多相关文章
- 重温.NET下Assembly的加载过程 ASP.NET Core Web API下事件驱动型架构的实现(三):基于RabbitMQ的事件总线
重温.NET下Assembly的加载过程 最近在工作中牵涉到了.NET下的一个古老的问题:Assembly的加载过程.虽然网上有很多文章介绍这部分内容,很多文章也是很久以前就已经出现了,但阅读之后 ...
- ASP.NET Core Web API下事件驱动型架构的实现(一):一个简单的实现
很长一段时间以来,我都在思考如何在ASP.NET Core的框架下,实现一套完整的事件驱动型架构.这个问题看上去有点大,其实主要目标是为了实现一个基于ASP.NET Core的微服务,它能够非常简单地 ...
- ASP.NET Core Web API下事件驱动型架构的实现(二):事件处理器中对象生命周期的管理
在上文中,我介绍了事件驱动型架构的一种简单的实现,并演示了一个完整的事件派发.订阅和处理的流程.这种实现太简单了,百十行代码就展示了一个基本工作原理.然而,要将这样的解决方案运用到实际生产环境,还有很 ...
- ASP.NET Core Web API下事件驱动型架构的实现(三):基于RabbitMQ的事件总线
在上文中,我们讨论了事件处理器中对象生命周期的问题,在进入新的讨论之前,首先让我们总结一下,我们已经实现了哪些内容.下面的类图描述了我们已经实现的组件及其之间的关系,貌似系统已经变得越来越复杂了. 其 ...
- ASP.NET Core Web API下事件驱动型架构的实现
mvp 原创博文:http://www.cnblogs.com/daxnet/p/8082694.html
- NET Core Web API下事件驱动型架构CQRS架构中聚合与聚合根的实现
NET Core Web API下事件驱动型架构在前面两篇文章中,我详细介绍了基本事件系统的实现,包括事件派发和订阅.通过事件处理器执行上下文来解决对象生命周期问题,以及一个基于RabbitMQ的事件 ...
- Azure AD(二)调用受Microsoft 标识平台保护的 ASP.NET Core Web API 下
一,引言 上一节讲到如何在我们的项目中集成Azure AD 保护我们的API资源,以及在项目中集成Swagger,并且如何把Swagger作为一个客户端进行认证和授权去访问我们的WebApi资源的?本 ...
- Docker容器环境下ASP.NET Core Web API应用程序的调试
本文主要介绍通过Visual Studio 2015 Tools for Docker – Preview插件,在Docker容器环境下,对ASP.NET Core Web API应用程序进行调试.在 ...
- 在Mac下创建ASP.NET Core Web API
在Mac下创建ASP.NET Core Web API 这系列文章是参考了.NET Core文档和源码,可能有人要问,直接看官方的英文文档不就可以了吗,为什么还要写这些文章呢? 原因如下: 官方文档涉 ...
随机推荐
- shell 颜色控制系列
shell脚本里,经常用的颜色控制,如下 格式:echo -e "\033[字背景颜色:文字颜色m字符串\033[0m" eg:echo -e "\033[41;36m ...
- static关键字的使用总结
1.对于static关键字的使用的时候对于修饰变量的时候,它相当于一个全局变量: 2.对于static修饰一个函数的时候他是在类被加载的时候首先会被类加载,并且只能加载一次,并且这个方法可以不需要通过 ...
- Java架构工程师知识图,你都知道么?
1.工程化专题 (团队大于3个人之后,你需要去考虑团队合作,科学管理) 2.源码分析专题 (好的程序员,一行代码一个设计就能看出来,源码分析带你品味代码,感受架构) 大家可以点击加入群:69757 ...
- Qt msvc Modules
3D ActiveQt container ActiveQt server Bluetooth Concurrent Core Enginio Declarative Gui Help Locatio ...
- ACdream 1015 Double Kings 树的重心
思路:删除根结点,其最大子树的节点最少.求一次树的重心即可. AC代码 #include <cstdio> #include <cmath> #include <ccty ...
- nyoj161 取石子 (四) 威佐夫博弈
思路:详细证明见博弈总结 如何判断威佐夫博弈的奇异局势? 对于状态(a, b),c = b - a,如果是奇异局势必定满足 a == c * (1+√5)/ 2. AC代码 #include < ...
- http协议——cookie详解
http是无状态的,所以引入了cookie来管理服务器与客户端之间的状态 与cookie相关的http首部字段有: 1.Set-Cookie:它一个响应首部字段,从服务器发送到客户端,当服务器想开始通 ...
- SpringBoot CGLIB AOP解决Spring事务,对象调用自己方法事务失效.
对于像我这种喜欢滥用AOP的程序员,遇到坑也是习惯了,不仅仅是事务,其实只要脱离了Spring容器管理的所有对象,对于SpringAOP的注解都会失效,因为他们不是Spring容器的代理类,Sprin ...
- 浅谈JavaScript位操作符
因为ECMAscript中所有数值都是以IEEE-75464格式存储,所以才会诞生了位操作符的概念. 位操作符作用于最基本的层次上,因为数值按位存储,所以位操作符的作用也就是操作数值的位.不过位操作符 ...
- CWnd *和HWnd转换
CWnd *和HWnd转换 CWnd*得到HWnd CWnd wnd; HWND hWnd; hWnd = wnd.m_hWnd; // or ...