爬虫实践---悦音台mv排行榜与简单反爬虫技术应用
由于要抓取的是悦音台mv的排行榜,这个排行榜是实时更新的,如果要求不停地抓取,这将有可能导致悦音台官方采用反爬虫的技术将ip给封掉。所以这里要应用一些反爬虫相关知识。
目标网址:http://vchart.yinyuetai.com/vchart/trends?area=ML
网站结构:
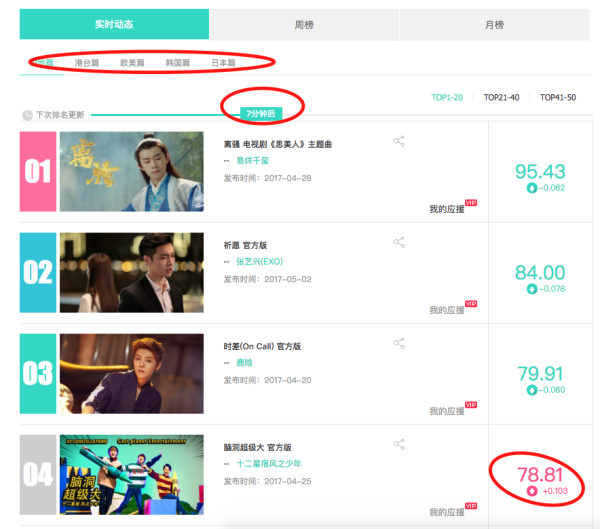
上面红线圈出来的地方都是需要注意的小细节:
首先 排行榜分为,内地、港台、欧美、韩国、日本五个地区
分别将其点开能够观察到url的变化为在最尾部加了一个参数:area=地区参数
很容易的就能知道参数列表:['ML','HT','US','JP','KR'] 分别对应着内地、香港、欧美、日本、以及韩国。发现这个规律之后,只要通过简单的对url的变化就能多次请求,筛选出想要的信息。
其次 可以发现,有的mv分数是呈现上升趋势,有的mv的分数是成下降趋势,这在网页的代码结构稍有不同。
最后,可以看到 这里mv的排行榜数据是实时更新的,所以爬虫程序要不停的在后台运行才能保证获得的数据是最新的,这样就会引起官方人员的注意,他们的反爬虫技术有可能就会将爬虫的IP封掉。
完整代码:
import requests
from bs4 import BeautifulSoup
import random def get_html(url):
try:
r = requests.get(url,timeout=30)
r.raise_for_status
r.encoding = 'utf-8'
return r.text
except:
return 'error' def get_agent():
'''
模拟header的user-agent字段,
返回一个随机的user-agent字典类型的键值对
'''
agents = ['Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv,2.0.1) Gecko/20100101 Firefox/4.0.1',
'Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)']
fakeheader = {}
fakeheader['User-agent'] = agents[random.randint(0, len(agents))]
return fakeheader def get_proxy():
'''
简单模拟代理池
返回一个字典类型的键值对,
'''
proxy = ["http://116.211.143.11:80",
"http://183.1.86.235:8118",
"http://183.32.88.244:808",
"http://121.40.42.35:9999",
"http://222.94.148.210:808"]
fakepxs = {}
fakepxs['http'] = proxy[random.randint(0, len(proxy))]
return fakepxs def get_content(url):
# 先打印一下表头
if url[-2:] == 'ML':
print('内地排行榜')
elif url[-2:] == 'HT':
print('香港排行榜')
elif url[-2:] == 'US':
print('欧美排行榜')
elif url[-2:] == 'KR':
print('韩国排行榜')
else:
print('日本排行榜') html = get_html(url)
soup = BeautifulSoup(html,'lxml')
li_list = soup.find_all('li',class_='vitem J_li_toggle_date ') for li in li_list:
content = {}
try:
# 判断分数升降
if li.find('h3',class_='desc_score'):
content['分数'] = li.find('h3',class_='desc_score').text
else:
content['分数'] = li.find('h3',class_='asc_score').text content['排名'] = li.find('div',class_='top_num').text
content['名字'] = li.find('a',class_='mvname').text
content['发布时间'] = li.find('p',class_='c9').text[5:]
content['歌手'] = li.find('a',class_='special').text
except:
return None print(content) def main():
base_url = 'http://vchart.yinyuetai.com/vchart/trends?area='
suffix = ['ML','HT','US','JP','KR']
for suff in suffix:
url = base_url + suff
print()
get_content(url) if __name__ == '__main__':
main()
输出结果:

爬虫实践---悦音台mv排行榜与简单反爬虫技术应用的更多相关文章
- 大众点评评论数据抓取 反爬虫措施有css文字映射和字体库反爬虫
大众点评评论数据抓取 反爬虫措施有css文字映射和字体库反爬虫 大众点评的反爬虫手段有那些: 封ip,封账号,字体库反爬虫,css文字映射,图形滑动验证码 这个图片是滑动验证码,访问频率高的话,会出 ...
- Python3 网络爬虫:漫画下载,动态加载、反爬虫这都不叫事
一.前言 作者:Jack Cui 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做案例的人,却不知道如何去学习更加高深的知识.那 ...
- Python 有道翻译 爬虫 有道翻译API 突破有道翻译反爬虫机制
py2.7 #coding: utf-8 import time import random import hashlib import requests while(1): url = 'http: ...
- 简单的抓取淘宝关键字信息、图片的Python爬虫|Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇)
Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇) 淘宝改字段,Bugfix,查看https://github.com/hunterhug/taobaoscrapy.git 由于Gith ...
- 【Python3爬虫】常见反爬虫措施及解决办法(一)
这一篇博客,是关于反反爬虫的,我会分享一些我遇到的反爬虫的措施,并且会分享我自己的解决办法.如果能对你有什么帮助的话,麻烦点一下推荐啦. 一.UserAgent UserAgent中文名为用户代理,它 ...
- 爬虫---Beautiful Soup 反反爬虫事例
前两章简单的讲了Beautiful Soup的用法,在爬虫的过程中相信都遇到过一些反爬虫,如何跳过这些反爬虫呢?今天通过知乎网写一个简单的反爬中 什么是反爬虫 简单的说就是使用任何技术手段,阻止别人批 ...
- 极验反爬虫防护分析之slide验证方式下图片的处理及滑动轨迹的生成思路
本文要分享的内容是去年为了抢鞋而分析 极验(GeeTest)反爬虫防护的笔记,由于篇幅较长(为了多混点CB)我会按照我的分析顺序,分成如下四个主题与大家分享: 极验反爬虫防护分析之交互流程分析 极验反 ...
- 大型企业都在用的Python反爬虫手段,破了它!
SVG 映射反爬虫 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做案例的人,却不知道如何去学习更加高深的知识.那么针对这三类人 ...
- python爬虫实践(二)——爬取张艺谋导演的电影《影》的豆瓣影评并进行简单分析
学了爬虫之后,都只是爬取一些简单的小页面,觉得没意思,所以我现在准备爬取一下豆瓣上张艺谋导演的“影”的短评,存入数据库,并进行简单的分析和数据可视化,因为用到的只是比较多,所以写一篇博客当做笔记. 第 ...
随机推荐
- js call的方法
call 方法 请参阅 应用于:Function 对象 要求 版本 5.5 调用一个对象的一个方法,以另一个对象替换当前对象. call([thisObj[,arg1[, arg2[, [,.argN ...
- 异常-----freemarker.template.TemplateException: Error executing macro: write
freemarker自定义标签 1.错误描述 六月 05, 2014 11:31:35 下午 freemarker.log.JDK14LoggerFactory$JDK14Logger error 严 ...
- CodeForces 940E
题意略. 这个题目我开始题意理解得有点问题.本题的实质是在这个数列中选择一些数字,使得选出的这些数字之和最大,用dp来解. 我们先要明确:当我选择数列长度为2 * c时,不如把这个长度为2 * c的劈 ...
- Python编程核心内容之一——Function(函数)
Python版本:3.6.2 操作系统:Windows 作者:SmallWZQ 截至上篇随笔<Python数据结构之四--set(集合)>,Python基础知识也介绍好了.接下来准备干 ...
- 【BZOJ3993】星际战争(网络流,二分答案)
[BZOJ3993]星际战争(网络流,二分答案) 题面 Description 3333年,在银河系的某星球上,X军团和Y军团正在激烈地作战.在战斗的某一阶段,Y军团一共派遣了N个巨型机器人进攻X军团 ...
- LightOJ1282 Leading and Trailing
题面 给定两个数n,k 求n^k的前三位和最后三位 Input Input starts with an integer T (≤ 1000), denoting the number of test ...
- 下载文件,blob方式
<!doctype html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 8Manage:“消费升级”缘何剑指企业一体化管理变革?
[导读]提到消费升级,大家都会想起美学.个性化.品质等标签,近年来经济发展所伴随的消费需求转型在逐渐凸显,开始从粗狂型到精细化,如:关注产品性价比.服务个性化等内容.企业在消费升级下应该如何应对呢?8 ...
- hadoop-eclipse-plugin-2.x.x 插件编译
在网上找的hadoop for eclipse 插件都不能用,决定自己去编译一个.Hadoop 提供了一个 Eclipse 插件以方便用户在 Eclipse 集成开发环境中使用 Hadoop,如管理 ...
- scala开发环境安装
安装JDK java 运行环境 ,这里不详说了,熟悉java的朋友应该都会,我们主要关注下Scala的安装. 安装scala 1.下载scala http://yunpan.cn/c ...