通过数据分析告诉你北京Python开发的现状
相信各位同学多多少少在拉钩上投过简历,今天突然想了解一下北京Python开发的薪资水平、招聘要求、福利待遇以及公司地理位置。既然要分析那必然是现有数据样本。本文通过爬虫和数据分析为大家展示一下北京Python开发的现状,希望能够在职业规划方面帮助到大家!!!
爬虫
爬虫的第一步自然是从分析请求和网页源代码开始。从网页源代码中我们并不能找到发布的招聘信息。但是在请求中我们看到这样一条POST请求
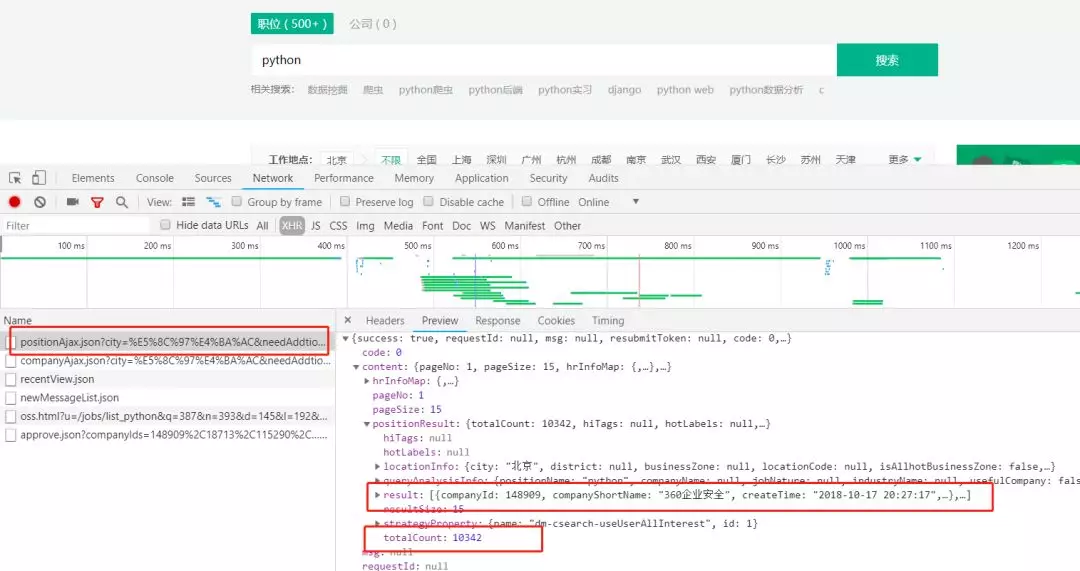
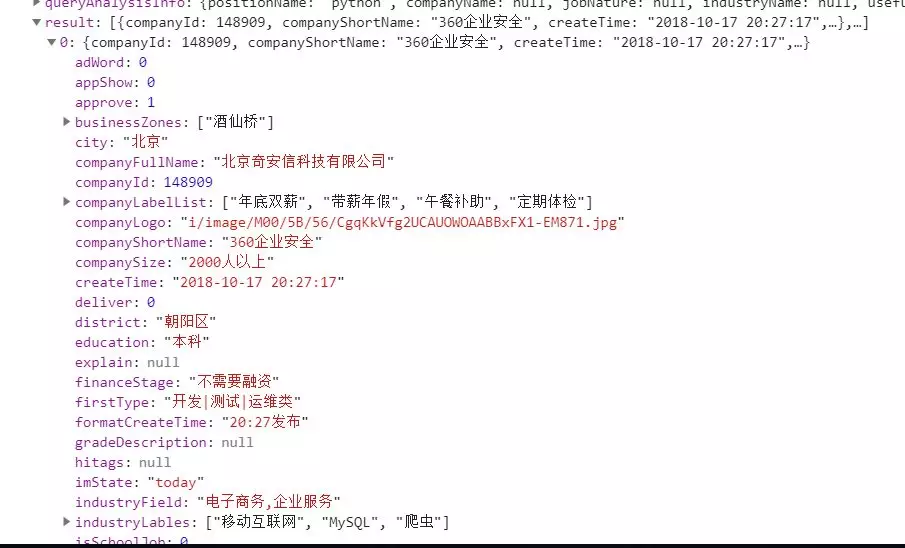
如下图我们可以得知
url:https://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false
请求方式:post
result:为发布的招聘信息
totalCount:为招聘信息的条数
通过实践发现除了必须携带headers之外,拉勾网对ip访问频率也是有限制的。一开始会提示 '访问过于频繁',继续访问则会将ip拉入黑名单。不过一段时间之后会自动从黑名单中移除。
针对这个策略,我们可以对请求频率进行限制,这个弊端就是影响爬虫效率。
其次我们还可以通过代理ip来进行爬虫。网上可以找到免费的代理ip,但大都不太稳定。付费的价格又不太实惠。
具体就看大家如何选择了
思路
通过分析请求我们发现每页返回15条数据,totalCount又告诉了我们该职位信息的总条数。
向上取整就可以获取到总页数。然后将所得数据保存到csv文件中。这样我们就获得了数据分析的数据源!
post请求的Form Data传了三个参数
first : 是否首页(并没有什么用)
pn:页码
kd:搜索关键字
no bb, show code
# 获取请求结果
# kind 搜索关键字
# page 页码 默认是1
def get_json(kind, page=1,):
# post请求参数
param = {
'first': 'true',
'pn': page,
'kd': kind
}
header = {
'Host': 'www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
# 设置代理
proxies = [
{'http': '140.143.96.216:80', 'https': '140.143.96.216:80'},
{'http': '119.27.177.169:80', 'https': '119.27.177.169:80'},
{'http': '221.7.255.168:8080', 'https': '221.7.255.168:8080'}
]
# 请求的url
url = 'https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false'
# 使用代理访问
# response = requests.post(url, headers=header, data=param, proxies=random.choices(proxies))
response = requests.post(url, headers=header, data=param)
response.encoding = 'utf-8'
if response.status_code == 200:
response = response.json()
# 请求响应中的positionResult 包括查询总数 以及该页的招聘信息(公司名、地址、薪资、福利待遇等...)
return response['content']['positionResult']
return None
接下来我们只需要每次翻页之后调用 get_json 获得请求的结果 再遍历取出需要的招聘信息即可
if __name__ == '__main__':
# 默认先查询第一页的数据
kind = 'python'
# 请求一次 获取总条数
position_result = get_json(kind=kind)
# 总条数
total = position_result['totalCount']
print('{}开发职位,招聘信息总共{}条.....'.format(kind, total))
# 每页15条 向上取整 算出总页数
page_total = math.ceil(total/15)# 所有查询结果
search_job_result = []
#for i in range(1, total + 1)
# 为了节约效率 只爬去前100页的数据
for i in range(1, 100):
position_result = get_json(kind=kind, page= i)
# 每次抓取完成后,暂停一会,防止被服务器拉黑
time.sleep(15)
# 当前页的招聘信息
page_python_job = []
for j in position_result['result']:
python_job = []
# 公司全名
python_job.append(j['companyFullName'])
# 公司简称
python_job.append(j['companyShortName'])
# 公司规模
python_job.append(j['companySize'])
# 融资
python_job.append(j['financeStage'])
# 所属区域
python_job.append(j['district'])
# 职称
python_job.append(j['positionName'])
# 要求工作年限
python_job.append(j['workYear'])
# 招聘学历
python_job.append(j['education'])
# 薪资范围
python_job.append(j['salary'])
# 福利待遇
python_job.append(j['positionAdvantage'])page_python_job.append(python_job)# 放入所有的列表中
search_job_result += page_python_job
print('第{}页数据爬取完毕, 目前职位总数:{}'.format(i, len(search_job_result)))
# 每次抓取完成后,暂停一会,防止被服务器拉黑
time.sleep(15)
ok! 数据我们已经获取到了,最后一步我们需要将数据保存下来
# 将总数据转化为data frame再输出
df = pd.DataFrame(data=search_job_result,
columns=['公司全名', '公司简称', '公司规模', '融资阶段', '区域', '职位名称', '工作经验', '学历要求', '工资', '职位福利'])
df.to_csv('lagou.csv', index=False, encoding='utf-8_sig')
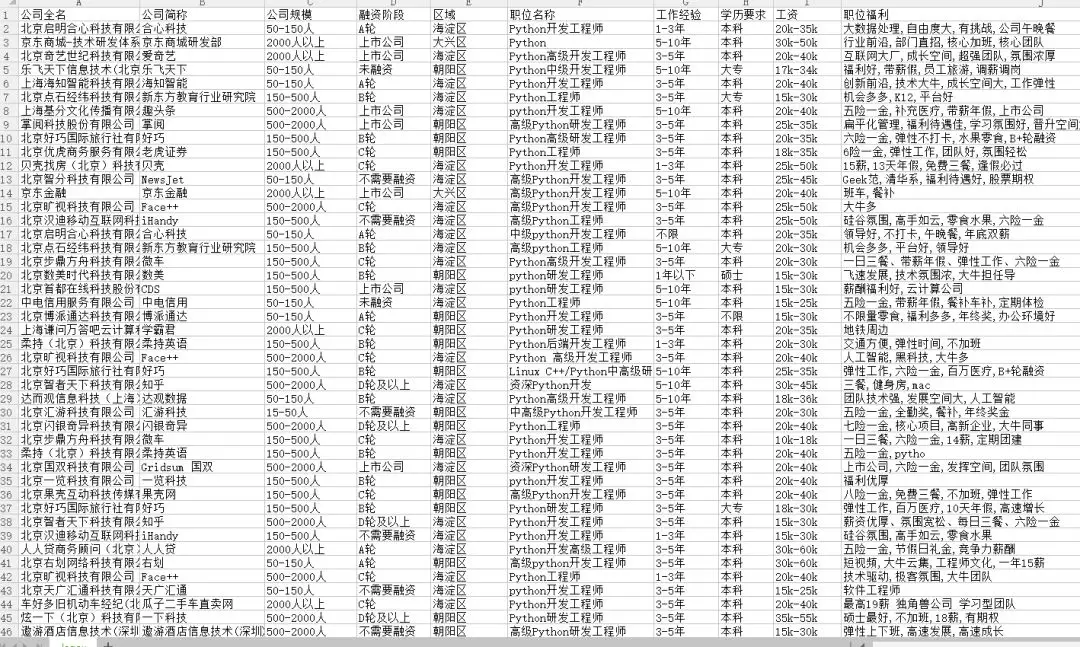
运行main方法直接上结果:
数据分析
通过分析cvs文件,为了方便我们统计,我们需要对数据进行清洗
比如剔除实习岗位的招聘、工作年限无要求或者应届生的当做 0年处理、薪资范围需要计算出一个大概的值、学历无要求的当成大专
# 读取数据
df = pd.read_csv('lagou.csv', encoding='utf-8')
# 数据清洗,剔除实习岗位
df.drop(df[df['职位名称'].str.contains('实习')].index, inplace=True)
# print(df.describe())
# 由于CSV文件内的数据是字符串形式,先用正则表达式将字符串转化为列表,再取区间的均值
pattern = '\d+'
df['work_year'] = df['工作经验'].str.findall(pattern)
# 数据处理后的工作年限
avg_work_year = []
# 工作年限
for i in df['work_year']:
# 如果工作经验为'不限'或'应届毕业生',那么匹配值为空,工作年限为0
if len(i) == 0:
avg_work_year.append(0)
# 如果匹配值为一个数值,那么返回该数值
elif len(i) == 1:
avg_work_year.append(int(''.join(i)))
# 如果匹配值为一个区间,那么取平均值
else:
num_list = [int(j) for j in i]
avg_year = sum(num_list)/2
avg_work_year.append(avg_year)
df['工作经验'] = avg_work_year# 将字符串转化为列表,再取区间的前25%,比较贴近现实
df['salary'] = df['工资'].str.findall(pattern)
# 月薪
avg_salary = []
for k in df['salary']:
int_list = [int(n) for n in k]
avg_wage = int_list[0]+(int_list[1]-int_list[0])/4
avg_salary.append(avg_wage)
df['月工资'] = avg_salary# 将学历不限的职位要求认定为最低学历:大专\
df['学历要求'] = df['学历要求'].replace('不限','大专')
数据通过简单的清洗之后,下面开始我们的统计
绘制薪资直方图
# 绘制频率直方图并保存
plt.hist(df['月工资'])
plt.xlabel('工资 (千元)')
plt.ylabel('频数')
plt.title("工资直方图")
plt.savefig('薪资.jpg')
plt.show()

结论:北京市Python开发的薪资大部分处于15~25k之间
公司分布饼状图
# 绘制饼图并保存
count = df['区域'].value_counts()
plt.pie(count, labels = count.keys(),labeldistance=1.4,autopct='%2.1f%%')
plt.axis('equal') # 使饼图为正圆形
plt.legend(loc='upper left', bbox_to_anchor=(-0.1, 1))
plt.savefig('pie_chart.jpg')
plt.show()
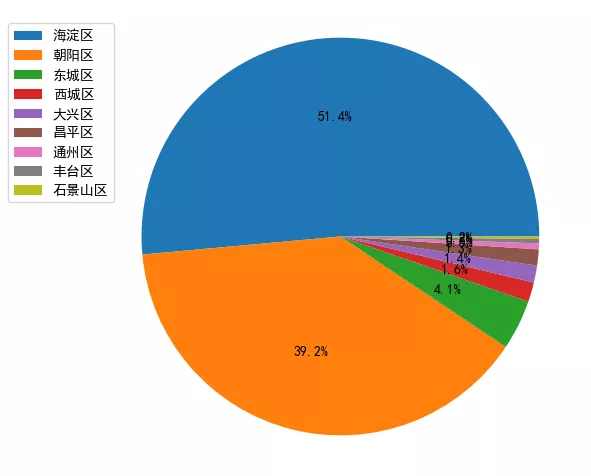
结论:Python开发的公司最多的是海淀区、其次是朝阳区。准备去北京工作的小伙伴大概知道去哪租房了吧
学历要求直方图
# {'本科': 1304, '大专': 94, '硕士': 57, '博士': 1}
dict = {}
for i in df['学历要求']:
if i not in dict.keys():
dict[i] = 0
else:
dict[i] += 1
index = list(dict.keys())
print(index)
num = []
for i in index:
num.append(dict[i])
print(num)
plt.bar(left=index, height=num, width=0.5)
plt.show()
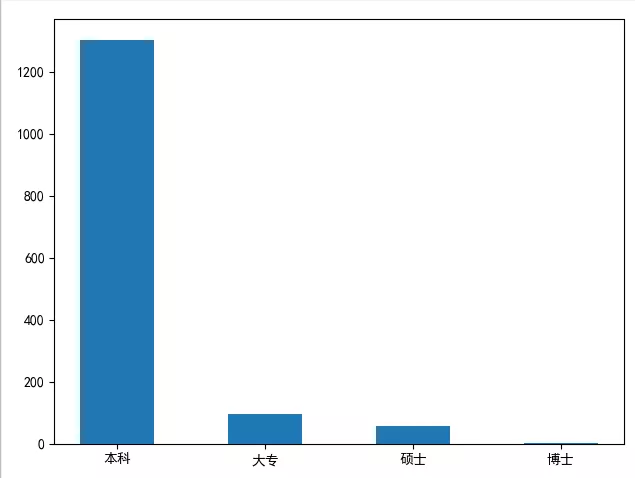
结论:在Python招聘中,大部分公司要求是本科学历以上。但是学历只是个敲门砖,如果努力提升自己的技术,这些都不是事儿
福利待遇词云图
# 绘制词云,将职位福利中的字符串汇总
text = ''
for line in df['职位福利']:
text += line
# 使用jieba模块将字符串分割为单词列表
cut_text = ' '.join(jieba.cut(text))
#color_mask = imread('cloud.jpg') #设置背景图
cloud = WordCloud(
background_color = 'white',
# 对中文操作必须指明字体
font_path='yahei.ttf',
#mask = color_mask,
max_words = 1000,
max_font_size = 100
).generate(cut_text)# 保存词云图片
cloud.to_file('word_cloud.jpg')
plt.imshow(cloud)
plt.axis('off')
plt.show()

结论:弹性工作是大部分公司的福利,其次五险一金少数公司也会提供六险一金。团队氛围、扁平化管理也是很重要的一方面。
至此,此次分析到此结束。有需要的同学也可以查一下其他岗位或者地区的招聘信息哦~
希望能够帮助大家定位自己的发展和职业规划。
通过数据分析告诉你北京Python开发的现状的更多相关文章
- 北京Python开发培训怎么选?
北京的地理优势和经济优势基本无需多言,作为全国机会最多的地方,吸引了无数的北漂前赴后继.作为中国互联网中心之一,北京有海量Python岗位正在等待大家淘金. 近几年中,Python一直是市场上最受欢迎 ...
- 拉勾网python开发要求爬虫
#今日目标 **拉勾网python开发要求爬虫** 今天要爬取的是北京python开发的薪资水平,招聘要求,福利待遇以及公司的地理位置. 通过实践发现除了必须携带headers之外,拉勾网对ip访问频 ...
- Web 开发和数据科学家仍是 Python 开发的两大主力
由于 Python 2 即将退役,使用 Python 3 的开发者大约为 90%,Python 2 的使用量正在迅速减少.而去年仍有 1/4 的人使用 Python 2. Web 开发和数据科学家仍是 ...
- python开发第一篇:初识python
一. Python介绍 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为AB ...
- Python开发【前端】:HTML
HTML HTML是英文Hyper Text Mark-up Language(超文本标记语言)的缩写,他是一种制作万维网页面标准语言(标记).相当于定义统一的一套规则,大家都来遵守他,这样就可以让浏 ...
- Python开发【第六篇】:模块
模块,用一砣代码实现了某个功能的代码集合. 类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合.而对于一个复杂的功能来,可能需要多个函数才 ...
- Python开发【第二篇】:初识Python
Python开发[第二篇]:初识Python Python简介 Python前世今生 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏 ...
- python 开发之路 - 入门
一. python 介绍 Python是著名的"龟叔"Guido van Rossum在1989年圣诞节期间,为了打发无聊的圣诞节而编写的一个编程语言.1991年 发布Python ...
- Python开发【第十篇】:模块
模块,用一砣代码实现了某个功能的代码集合. 类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合.而对于一个复杂的功能来,可能需要多个函数才 ...
随机推荐
- Java 学习笔记 (四) Java 语句优化
这个问题是从headfirst java看到的. 需求: 一个移动电话用的java通讯簿管理系统,要求最有效率的内存使用方法. 下面两段程序的优缺点,哪个占用内存更少. 第一段: Contact[]c ...
- kv_storage.go
package storage //kv 存储引擎实现 import ( "github.com/cznic/kv" "io" ) //kv 存 ...
- WebP 在减少图片体积和流量上的效果如何?MIP技术实践分享
作者 | Jackson 编辑 | 尾尾 不论是 PC 还是移动端,图片一直占据着页面流量的大头,在图片的大小和质量之间如何权衡,成为了长期困扰开发者们的问题.而 WebP 技术的出现,为解决该问题提 ...
- Linux 系统目录结构说明
在刚开始接触Linux系统时,对其目录结构迷茫的很,尤其是很少使用或者刚开始接触Linux系统的同学:我也是最近项目需要开始上手,所以查看了些资料,特整理出来供大家互相学习: 1.目录结构总揽 以下是 ...
- 【Android Studio安装部署系列】目录
概述 从刚开始使用Android Studio到现在,下面所有目录下的操作,当时习惯性的把每一个整理成一个文档(其实就是简单文字描述+截图):有些地方当时是一知半解,现在会稍微明白一些.正好赶上现在有 ...
- java数据结构和算法01(数组的简单使用)
一直都对这一块没有什么想法,加上不怎么理解,只是懂个大概:最近突然感觉对数据结构和算法这块有点儿兴趣,决定还是尽量详细的看看这些结构和算法: 话说什么事数据结构和算法呢?现在我也说不上来,等我学的差不 ...
- Spring:(二)DI依赖注入方式
DI 依赖注入 DI(Dependency Injection)依赖注入,说简单一点就将类里面的属性在创建类的过程中给属性赋值,即将对象依赖属性(简单值,集合,对象)通过配置设值给该对象. 属性注入的 ...
- 女朋友也能看懂的Zookeeper分布式锁原理
前言 关于分布式锁,在互联网行业的使用场景还是比较多的,比如电商的库存扣减,秒杀活动,集群定时任务执行等需要进程互斥的场景.而实现分布式锁的手段也很多,大家比较常见的就是redis跟zookeep ...
- 使用kibana可视化报表实时监控你的应用程序,从日志中找出问题,解决问题
先结果导向,来看我在kibana dashborad中制作的几张监控图. 一:先睹为快 dashboard1:监控几个维度的日志,这么点日志量是因为把无用的清理掉了,而且只接入了部分应用. <1 ...
- HighChar 案例
Highchars //前台 <script> $(function () { //showChat(); initChat(); showPie(); initPie(); }) fun ...