Spark学习之编程进阶总结(一)
一、简介
这次介绍前面没有提及的 Spark 编程的各种进阶特性,会介绍两种类型的共享变量:累加器(accumulator)与广播变量(broadcast variable)。累加器用来对信息进行聚合,而广播变量用来高效分发较大的对象。在已有的 RDD 转化操作的基础上,我们为类似查询数据库这样需要很大配置代价的任务引入了批操作。为了扩展可用的工具范围,还会简单介绍 Spark 与外部程序交互的方式,比如如何与用 R 语言编写的脚本进行交互。
当任务需要很长时间进行配置,譬如需要创建数据库连接或者随机数生成器时,在多个数据元素间共享一次配置就会比较有效率,所以还会讨论如何基于分区进行操作以重用数据库连接的配置工作。
二、累加器
通常在向 Spark 传递函数时,比如使用 map() 函数或者用 filter() 传条件时,可以使用驱动器程序中定义的变量,但是集群中运行的每个任务都会得到这些变量的一份新的副本,更新这些副本的值也不会影响驱动器中的对应变量。Spark 的两个共享变量,累加器与广播变量,分别为结果聚合与广播这两种常见的通信模式突破了这一限制。
第一种共享变量,即累加器,提供了将工作节点中的值聚合到驱动器程序中的简单语法。累加器的一个常见用途是在调试时对作业执行过程中的事件进行计数。例如我们想知道输入文件中有多少空行。
- import org.apache.spark.SparkConf
- import org.apache.spark.SparkContext
- object Spark_6 {
- def main(args: Array[String]): Unit = {
- // 在Scala中累加空行
- val conf = new SparkConf().setAppName("test").setMaster("local")
- val sc = new SparkContext(conf)
- sc.setLogLevel("WARN") // 设置日志显示级别
- val input = sc.textFile("words.txt")
- val blankLines = sc.accumulator(0) // 创建Accumulator[Int]并初始化为0
- val callSigns = input.flatMap(line => {
- if(line==""){
- blankLines += 1 // 累加器加1
- }
- line.split(" ")
- })
- callSigns.saveAsTextFile("test") // 注意只有在运行saveAsTextFile()行动操作后才能看到正确的计数 Dubug看不到flatMap运行过程
- println("Blank Lines: "+blankLines.value)
- }
- }

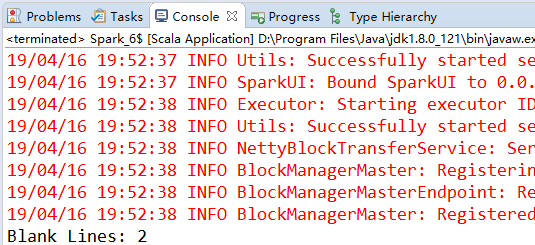
在这个示例中,我们创建了一个叫作 blankLines 的 Accumulator[Int] 对象,然后在输入中看到一个空行时就对其加 1。执行完转化操作之后,就打印出累加器中的值。注意,只有在运行 saveAsTextFile() 行动操作后才能看到正确的计数,因为行动操作前的转化操作flatMap() 是惰性的,所以作为计算副产品的累加器只有在惰性的转化操作 flatMap() 被saveAsTextFile() 行动操作强制触发时才会开始求值。
当然,也可以使用 reduce() 这样的行动操作将整个 RDD 中的值都聚合到驱动器中。只是我们有时希望使用一种更简单的方法来对那些与 RDD 本身的范围和粒度不一样的值进行聚合。聚合可以发生在 RDD 进行转化操作的过程中。在前面的例子中,我们使用累加器在读取数据时对空行进行计数,而没有分别使用 filter() 和 reduce() 。
总结起来,累加器的用法如下所示。
• 通过在驱动器中调用 SparkContext.accumulator(initialValue) 方法,创建出存有初始值的累加器。返回值为 org.apache.spark.Accumulator[T] 对象,其中 T 是初始值initialValue 的类型。
• Spark闭包里的执行器代码可以使用累加器的 += 方法(在Java中是 add )增加累加器的值。
• 驱动器程序可以调用累加器的 value 属性(在 Java 中使用 value() 或 setValue() )来访问累加器的值。
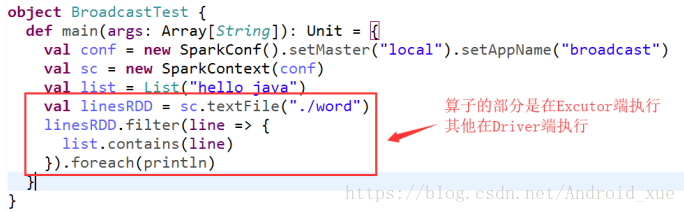
注意,工作节点上的任务不能访问累加器的值。从这些任务的角度来看,累加器是一个只写变量。在这种模式下,累加器的实现可以更加高效,不需要对每次更新操作进行复杂的通信。累加器在Driver端定义赋初始值,累加器只能在Driver端读取,在Excutor端更新。下图简单说明了什么是Driver(驱动器)端,什么是Excutor端。
三、广播变量
Spark 的第二种共享变量类型是广播变量,它可以让程序高效地向所有工作节点发送一个较大的只读值,以供一个或多个 Spark 操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,甚至是机器学习算法中的一个很大的特征向量,广播变量用起来都很顺手。
广播变量允许程序员保持只读变量,在每个机器上缓存,而不是用任务来发送它的副本。它们可以有效的方式给每个节点提供一个大的输入数据集的副本。spark尝试使用高效广播算法来分发广播变量以减少通信成本。注意,对象在广播后不应修改以确保所有节点获得广播变量的相同值 。
Broadcast 就是将数据从一个节点发送到其他的节点上; 例如 Driver 上有一张表,而 Executor 中的每个并行执行的Task (100万个Task) 都要查询这张表的话,那我们通过 Broadcast 的方式就只需要往每个Executor 把这张表发送一次就行了,Executor 中的每个运行的 Task 查询这张唯一的表,而不是每次执行的时候都从 Driver 中获得这张表!
Broadcast 是分布式的共享数据,默认情况下只要程序在运行 Broadcast 变量就会存在,因为 Broadcast 在底层是通过 BlockManager 管理的,Broadcast 是在创建 SparkContext 时被创建的!你也可以手动指定或者配置具体周期来销毁 Broadcast 变量!Broadcast 一般用于处理共享配置文件,通用的数据子,常用的数据结构等等;但是不适合存放太大的数据在Broadcast。Broadcast 不会内存溢出,因为其数据的保存的 Storage Level 是 MEMORY_AND_DISK 的方式(首先优先放在内存中,如果内存不够才放在磁盘上)虽然如此,我们也不可以放入太大的数据在 Broadcast 中,因为网络 I/O 和可能的单点压力会非常大!
没有广播的情况:通过网络传输把变量发送到每一个 Task 中,会产生4个Number的数据副本,每个副本都会占用一定的内存空间,如果变量比较大,会导致则极易出现OOM。
使用广播的情况:通过Broadcast把变量传输到Executor的内存中,Executor级别共享唯一的一份广播变量,极大的减少网络传输和内存消耗!
使用广播变量的过程很简单。
(1) 通过对一个类型 T 的对象调用 SparkContext.broadcast 创建出一个 Broadcast[T] 对象。任何可序列化的类型都可以这么实现。
(2) 通过 value 属性访问该对象的值(在 Java 中为 value() 方法)。
(3) 变量只会被发到各个节点一次,应作为只读值处理(修改这个值不会影响到别的节点)。
- val broadcastVar = sc.broadcast(Array(1, 2, 3))
- broadcastVar.value
注意事项:
能不能将一个RDD使用广播变量广播出去?不能,因为RDD是不存储数据的。可以将RDD的结果广播出去。广播变量只能在Driver端定义,不能在Executor端定义。在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
四、广播的优化
当广播一个比较大的值时,选择既快又好的序列化格式是很重要的,因为如果序列化对象的时间很长或者传送花费的时间太久,这段时间很容易就成为性能瓶颈。尤其是,Spark的 Scala 和 Java API 中默认使用的序列化库为 Java 序列化库,因此它对于除基本类型的数组以外的任何对象都比较低效。你可以使用 spark.serializer 属性选择另一个序列化库来优化序列化过程(后面会讨论如何使用 Kryo 这种更快的序列化库),也可以为你的数据类型实现自己的序列化方式(对 Java 对象使用 java.io.Externalizable 接口实现序列化,或使用 reduce() 方法为 Python 的 pickle 库定义自定义的序列化)。
Spark学习之编程进阶总结(一)的更多相关文章
- Spark学习之编程进阶——累加器与广播(5)
Spark学习之编程进阶--累加器与广播(5) 1. Spark中两种类型的共享变量:累加器(accumulator)与广播变量(broadcast variable).累加器对信息进行聚合,而广播变 ...
- Spark学习之编程进阶总结(二)
五.基于分区进行操作 基于分区对数据进行操作可以让我们避免为每个数据元素进行重复的配置工作.诸如打开数据库连接或创建随机数生成器等操作,都是我们应当尽量避免为每个元素都配置一次的工作.Spark 提供 ...
- Spark菜鸟学习营Day3 RDD编程进阶
Spark菜鸟学习营Day3 RDD编程进阶 RDD代码简化 对于昨天练习的代码,我们可以从几个方面来简化: 使用fluent风格写法,可以减少对于中间变量的定义. 使用lambda表示式来替换对象写 ...
- Spark函数式编程进阶
函数式编程进阶 1.函数和变量一样作为Scala语言的一等公民,函数可以直接复制给变量: 2.函数更长用的方式是匿名函数,定义的时候只需要说明输入参数的类型和函数体即可,不需要名称,但是匿名函数赋值给 ...
- Scala实战高手****第12课:Scala函数式编程进阶(匿名函数、高阶函数、函数类型推断、Currying)与Spark源码鉴赏
/** * 函数式编程进阶: * 1.函数和变量一样作为Scala语言的一等公民,函数可以直接赋值给变量 * 2.函数更常用的方式是匿名函数,定义的时候只需要说明输入参数的类型和函数体即可,不需要名称 ...
- Spark学习之RDD编程(2)
Spark学习之RDD编程(2) 1. Spark中的RDD是一个不可变的分布式对象集合. 2. 在Spark中数据的操作不外乎创建RDD.转化已有的RDD以及调用RDD操作进行求值. 3. 创建RD ...
- Scala函数式编程进阶
package com.dtspark.scala.basics /** * 函数式编程进阶: * 1,函数和变量一样作为Scala语言的一等公民,函数可以直接赋值给变量: * 2, 函数更长用的方式 ...
- spark 学习路线及参考课程
一.Scala编程详解: 第1讲-Spark的前世今生 第2讲-课程介绍.特色与价值 第3讲-Scala编程详解:基础语法 第4讲-Scala编程详解:条件控制与循环 第5讲-Scala编程详解:函数 ...
- Spark学习入门(让人看了想吐的话题)
这是个老生常谈的话题,大家是不是看到这个文章标题就快吐了,本来想着手写一些有技术深度的东西,但是看到太多童鞋卡在入门的门槛上,所以还是打算总结一下入门经验.这种标题真的真的在哪里都可以看得到,度娘一搜 ...
随机推荐
- Opencv3.1+python2.7的CentOS7安装
http://blog.csdn.NET/daunxx/article/details/50506625 转载注释:有些包名和系统包名并不匹配,yum install 找不到的时候,可以yum sea ...
- ruby the diference between gets and gets.chomp()
ruby the diference between gets and gets.chomp() 二者都是可以获取用户命令行输入的函数,但是 gets获取内容后,后面 附带了 多余的换行符号'\n'; ...
- add two nums
问题描述: 给定两个链表,计算出链表对应位置相加的和,如果和大于10要往后进位.用链表返回结果.其实上是一种大数加法.可以把一个大数倒着写存入链表,然后两个链表相加就是所需要的大数相加的和 输入 2 ...
- 爬虫之urllib包
urllib简介 简介 Python3中将python2.7的urllib和urllib2两个包合并成了一个urllib库 Python3中,urllib库包含有四个模块: urllib.reques ...
- java 通过HttpURLConnection与servlet通信
研究了一天才搞清楚,其实挺简单的,在这里记录下,以便以后参考. 一.创建一个servlet项目 主要包括(WEB-INF)里面有classes文件夹.lib文件夹.web.xml文件. 将写好的ser ...
- cocos2dx中的坐标系统
一. (1)OpenGL坐标系 Cocos2D-x以OpenGL和OpenGL ES为基础,所以自然支持OpenGL坐标系.该坐标系原点在屏幕左下角,x轴向右,y轴向上. (2)屏幕坐标系 屏幕坐标系 ...
- 软件及博客的markdown支持度的评测
软件 vscode vscode原生支持markdown,但对数学公式的支持不太好,用 $$包含的数学公式不支持换行,而且在数学公式里面不能输入中文 Typora 非常简洁优美的软件,只有预览页,没有 ...
- .NET开发微信小程序-生成二维码
1.生成小程序二维码功能 直接请求相应的链接.传递相应的参数 以生成商铺的付款码为例: var shopsId = e.ShopsId //付款码的参数 var codeModel = new fun ...
- linux进程、线程与cpu的亲和性(affinity)
参考:http://www.cnblogs.com/wenqiang/p/6049978.html 最近的工作中对性能的要求比较高,下面简单做一下总结: 一.什么是cpu亲和性(affinity) C ...
- Node.js中的异步I/O是如何进行的?
Node.js的异步I/O通过事件循环的方式实现.其中异步I/O又分磁盘I/O和网络I/O.在磁盘I/O的调用中,当发起异步调用后,会将异步操作送进libuv提供的队列中,然后返回.当磁盘I/O执行完 ...