Ubuntu 14.04下Hadoop2.4.1集群安装配置教程
一、环境
- 系统: Ubuntu 14.04 64bit
- Hadoop版本: hadoop 2.4.1 (stable)
- JDK版本: OpenJDK 7
- 台作为Master,另3台作为Slave。
所有主机的用户名都为hadoop,密码为123456.
二、网络主机配置
- 配置主机名和局域网IP
主机名与局域网IP地址对应如下:
|
主机名 |
局域网IP |
|
Master |
115.156.236.178 |
|
Slave1 |
115.156.236.199 |
|
Slave2 |
115.156.236.189 |
|
Slave3 |
115.156.236.215 |
- 修改主机名
首先选定哪台主机要作为Master(比如ip为 192.168.1.178 这台),然后在该主机的 /etc/hostname 中,修改机器名为Master,将其他主机命名为Slave1、Slave2、Slave3等。
sudo vi /etc/hostname
- 修改hosts
接着在 /etc/hosts中,把所有集群的主机信息都写进去。
sudo vi /etc/hosts

注意,该网络配置需要在所有主机上进行。
- 测试能否互相ping通
配置好后可以在各个主机上执行ping Master和ping Slave1测试一下,看是否相互ping通。

三、安装JDK
- 到官网下载Linux x64:
http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
将jdk-7u79-linux-x64.tar.gz解压至/home/hadoop目录下
tar zxvf jdk-7u79-linux-x64.tar.gz –C /home/hadoop
- 编辑环境变量:
sudo vi /etc/profile
在里面添加如下内容

- 使配置生效:
source
/etc/profile
- 测试:
java –version

四、SSH无密码登陆节点
- 安装ssh
sudo apt-get install openssh-server
如果无法正常安装,先试着执行下面的语句:
sudo apt-get update
- 编辑环境变量
sudo vi /etc/profile
修改后如下所示:

使配置生效:
source /etc/profile
- 配置namenode的ssh无密码自动登录
这个操作是要让Master节点可以无密码SSH登陆到Slave节点上。
首先生成 Master 的公匙,在 Master 节点终端中执行:
su hadoop
cd /home/hadoop
ssh-keygen –t rsa #生成公钥和私钥,一路回车
完成后会在/home/hadoop/目录下产生完全隐藏的文件夹.ssh。
然后执行:
cd .ssh # 进入.ssh目录
cp id_rsa.pub authorized_keys #生成authorized_keys文件
ssh localhost #测试无密码登陆
- 配置Master无密码访问Slave1、Slave2和Slave3
)将公钥传输到Slave1节点:
scp ~/.ssh/id_rsa.pub hadoop@Slave1:/home/hadoop/
scp时会要求输入Slave1上hadoop用户的密码(123456),输入完成后会提示传输完毕。
)接着在 Slave1节点上将ssh公匙保存到相应位置:
cp id_rsa.pub authorized_keys
)对其他的Slave节点,也要执行
将公匙传输到Slave节点、在Slave节点上保存到相应位置
这两步。
)最后在 Master 节点上就可以无密码SSH到Slave1节点了。
ssh Slave1

五、配置Hadoop
- 下载Hadoop2.4.1:https://archive.apache.org/dist/hadoop/common/
将hadoop-2.4.1.tar.gz保存至/home/Hadoop,然后解压:
tar zxvf jdk-7u79-linux-x64.tar.gz
- Master节点配置Hadoop
个配置文件, hadoop-env.sh 、slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
)文件hadoop-env.sh
配置jdk,添加下面一行:
export JAVA_HOME=/home/hadoop/jdk1.7.0_79
)文件slaves
个 Slave节点,那么该文件中就有3行内容:
Slave1
Slave2
Slave3
)文件core-site.xml,修改如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hadoop/tmp</value>
<description>Abase for other temporary directories. </description>
</property>
</configuration>
)文件hdfs-site.xml,因为有3个Slave,所以dfs.replication的值设为3。
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
)文件mapred-site.xml,这个文件不存在,首先需要从模板中复制一份:
cp mapred-site.xml.template mapred-site.xml
然后配置修改如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
)文件yarn-site.xml:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
- 将Hadoop复制到Slave节点
配置好后,将 Master 上的 Hadoop 文件复制到各个节点上(虽然直接采用 scp 复制也可以正确运行,但会有所不同,如符号链接 scp 过去后就有点不一样了。所以先打包再复制比较稳妥)。
)在Master执行:
cd /home/hadoop
sudo tar -zcf ./hadoop.tar.gz ./hadoop
scp ./hadoop.tar.gz Slave1:/home/hadoop
)在Slave1上执行:
sudo tar -zxf ~/hadoop.tar.gz -C /home/hadoop
sudo chown -R hadoop:hadoop /home/hadoop/hadoop
)然后在Master节点上就可以启动hadoop了。
cd ~/hadoop
bin/hdfs namenode -format # 首次运行需要执行初始化,后面不再需要
启动Hadoop集群:
sbin/start-dfs.sh
sbin/start-yarn.sh
- 查看进程
在Master节点通过jps查看Master的Hadoop进程:

在Master节点上查看DataNode是否正常启动:
bin/hdfs dfsadmin -report
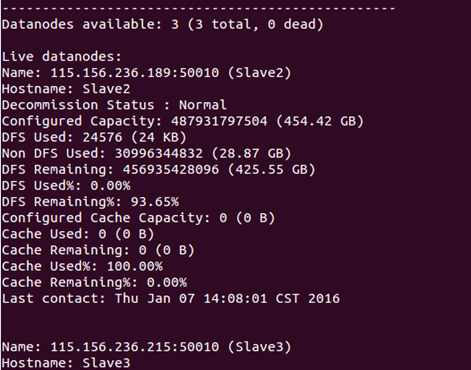
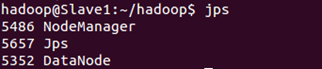
在Slave节点上通过jps查看Slave的Hadoop进程:
jps
也可以通过Web页面看到查看DataNode和NameNode的状态:
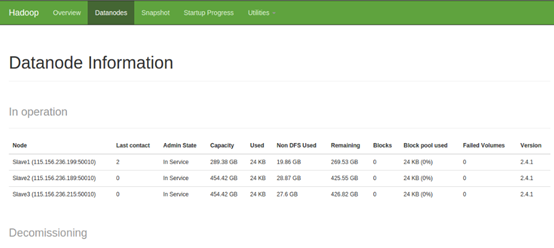
- 关闭Hadoop集群也是在Master节点上执行:
sbin/stop-dfs.sh
sbin/stop-yarn.sh
- 几个可能遇到的问题
)无法启动DataNode?
所以如果集群以前能启动,但后来启动不了,特别是 DataNode 无法启动,不妨试着删除所有节点(包括 Slave 节点)上的 tmp 文件夹:
rm -rf ~/Hadoop/tmp
bin/hdfs namenode –format
sbin/start-dfs.sh
sbin/start-yarn.sh
)ID不一致导致HDFS无法启动?
这个问题一般是由于两次或两次以上的格式化NameNode造成的,有两种方法可以解决,第一种方法是删除DataNode的所有资料;第二种方法是修改每个DataNode的namespaceID(位于/dfs/data/current/VERSION文件中)或修改NameNode的namespaceID(位于/dfs/name/current/VERSION文件中),使其一致。
)如何重启DataNode?
当Hadoop集群的某单个节点出现问题时,一般不必重启整个系统,只须重启这个节点,它会自动连入整个集群。
sbin/hadoop-daemon.sh start datanode
参考文献
http://www.linuxidc.com/Linux/2015-02/113486.htm
http://www.linuxidc.com/Linux/2013-09/90600.htm
http://blog.csdn.net/xiaotom5/article/details/8080585
http://book.51cto.com/art/201110/298602.htm
Ubuntu 14.04下Hadoop2.4.1集群安装配置教程的更多相关文章
- CentOS下Hadoop-2.2.0集群安装配置
对于一个刚开始学习Spark的人来说,当然首先需要把环境搭建好,再跑几个例子,目前比较流行的部署是Spark On Yarn,作为新手,我觉得有必要走一遍Hadoop的集群安装配置,而不仅仅停留在本地 ...
- Ubuntu 14.04 下的MAC OS X 主题安装
Ubuntu 14.04 下的MAC OS X 主题安装 安装 MAC OS X 主题会帮助你的 Ubuntu 14.04 看起来更像MAC OS X.在这里我们介绍的Macbuntu安装包包含了GT ...
- Hadoop-2.4.1 ubuntu集群安装配置教程
一.环境 系统: Ubuntu 14.04 32bit Hadoop版本: Hadoop 2.4.1 (stable) JDK版本: 1.7 集群数量:3台 注意事项:我们从Apache官方网站下载的 ...
- Linux基于Hadoop2.8.0集群安装配置Hive2.1.1及基础操作
前言 安装Apache Hive前提是要先安装hadoop集群,并且hive只需要在hadoop的namenode节点集群里安装即可,安装前需保证Hadoop已启(动文中用到了hadoop的hdfs命 ...
- Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS
摘自:http://www.powerxing.com/install-hadoop-cluster/ 本教程讲述如何配置 Hadoop 集群,默认读者已经掌握了 Hadoop 的单机伪分布式配置,否 ...
- Ubuntu 12.04下spark1.0.0 集群搭建(原创)
spark1.0.0新版本的于2014-05-30正式发布啦,新的spark版本带来了很多新的特性,提供了更好的API支持,spark1.0.0增加了Spark SQL组件,增强了标准库(ML.str ...
- Ubuntu 14.04下MySQL服务器和客户端的安装
下面进行简单的配置 安装完成后通过修改/etc/mysql/my.cnf(此文件为mysql的配置文件).将文件中的binding-address=127.0.0.1注释掉.其它配置根据需要更改. H ...
- Ubuntu 14.10 下Ganglia监控Hadoop集群
前提是已经安装好Ganglia和Hadoop集群 1 Master节点配置hadoop-metrics2.properties # syntax: [prefix].[source|sink|jmx] ...
- Redis3.0.7 cluster/集群 安装配置教程
1.前言 环境:CentOS-6.7-i386-LiveDVD 安装的CentOs系统 节点: 6个节点,3个主节点.3个从节点(由于redis默认需要3个主节点,如果想每个主节点有一个从节点,这是最 ...
随机推荐
- window下如何使用Git上传代码到github远程服务器上(转)
注册账户以及创建仓库 首先你得有一个github账号,没有自行注册,登录成功后应该是这样 在页面上方用户菜单上选择 "+"->New repository 创建一个新的仓库 ...
- NLP+语义分析(四)︱中文语义分析研究现状(CIPS2016、角色标注、篇章分析)
摘录自:CIPS2016 中文信息处理报告<第二章 语义分析研究进展. 现状及趋势>P14 CIPS2016> 中文信息处理报告下载链接:http://cips-upload.bj. ...
- EDKII Build Process:EDKII项目源码的配置、编译流程[三]
<EDKII Build Process:EDKII项目源码的配置.编译流程[3]>博文目录: 3. EDKII Build Process(EDKII项目源码的配置.编译流程) -> ...
- dojo表格分页之各个参数代表的意义(一)
下面是dojo表格分页参数代表的意义 //每页可以显示10/15/20/25/30条记录 (1)pageSizes: [10, 15, 20, 25,30], //每页显示的记录从多少到多少,共多少条 ...
- R语言 文本挖掘 tm包 使用
#清除内存空间 rm(list=ls()) #导入tm包 library(tm) library(SnowballC) #查看tm包的文档 #vignette("tm") ##1. ...
- 利用Eclipse中的Maven构建Web项目报错(一)
利用Eclipse中的Maven构建Web项目 1.在进行上述操作时,pom.xml一直报错 <project xmlns="http://maven.apache.org/POM/4 ...
- java.util.zip.ZipException:ZIP file must have at least one entry
1.错误描述 java.util.zip.ZipException:ZIP file must have at least one entry 2.错误原因 由于在导出文件时,要将导出的文件压缩到压缩 ...
- WDF驱动的编译、调试、安装
编译和调试使用WDK编译,源代码应包括wdf.h,ntddk.h以及KMDF_VERSION=1,编译使用/GS.KMDF包括以下库:1). WdfDriverEntry.lib(编译时绑定):驱动入 ...
- fineuploader使用实例
1.Fine Uploader特点 Fine Uploader Features: A:支持文件上传进度显示. B:文件拖拽浏览器上传方式 C:Ajax页面无刷新. D:多文件上传. F:跨浏览器. ...
- CentOS中配置NFS服务
1.服务器端安装rpcbind.nfs-utils.nfs-server包 yum install nfs-utils -y 2.修改服务器端配置文件,添加需要共享的文件夹. vim /etc/exp ...