Hadoop是一种开源的适合大数据的分布式存储和处理的平台
“Hadoop能做什么?” ,概括如下:
1)搜索引擎:这也正是Doug Cutting设计Hadoop的初衷,为了针对大规模的网页快速建立索引;
2)大数据存储:利用Hadoop的分布式存储能力,例如数据备份、数据仓库等;
3)大数据处理:利用Hadoop的分布式处理能力,例如数据挖掘、数据分析等;
4)科学研究:Hadoop是一种分布式的开源框架,对于分布式系统有很大程度地参考价值。
Hadoop有三种不同的模式操作,分别为单机模式、伪分布模式和全分布模式。每种模式的详细介绍以及单机模式的安装请阅读我之前的博客:[Hadoop] 在Ubuntu系统上一步步搭建Hadoop(单机模式),伪分布式模式和全分布式模式的
Hadoop分布式文件系统(Hadoop Distributed File System,简称HDFS)是Hadoop的核心模块之一,它主要解决Hadoop的大数据存储问题,其思想来源与Google的文件系统GFS。HDFS的主要特点:
- 保存多个副本,且提供容错机制,副本丢失或宕机自动恢复。默认存3份。
- 运行在廉价的机器上。
- 适合大数据的处理。HDFS默认会将文件分割成block,64M为1个block。然后将block按键值对存储在HDFS上,并将键值对的映射存到内存中。如果小文件太多,那内存的负担会很重。
HDFS中的两个重要角色:
[Namenode]
1)管理文件系统的命名空间。
2)记录 每个文件数据快在各个Datanode上的位置和副本信息。
3)协调客户端对文件的访问。
4)记录命名空间内的改动或者空间本省属性的改动。
5)Namenode 使用事务日志记录HDFS元数据的变化。使用映像文件存储文件系统的命名空间,包括文件映射,文件属性等。
从社会学来看,Namenode是HDFS里面的管理者,发挥者管理、协调、操控的作用。
[Datanode]
1)负责所在物理节点的存储管理。
2)一次写入,多次读取(不修改)。
3)文件由数据库组成,一般情况下,数据块的大小为64MB。
4)数据尽量散步到各个节点。
从社会学的角度来看,Datanode是HDFS的工作者,发挥按着Namenode的命令干活,并且把干活的进展和问题反馈到Namenode的作用。
客户端如何访问HDFS中一个文件呢?具体流程如下:
1)首先从Namenode获得组成这个文件的数据块位置列表。
2)接下来根据位置列表知道存储数据块的Datanode。
3)最后访问Datanode获取数据。
注意:Namenode并不参与数据实际传输。
数据存储系统,数据存储的可靠性至关重要。HDFS是如何保证其可靠性呢?它主要采用如下机理:
1)冗余副本策略,即所有数据都有副本,副本的数目可以在hdfs-site.xml中设置相应的复制因子。
2)机架策略,即HDFS的“机架感知”,一般在本机架存放一个副本,在其它机架再存放别的副本,这样可以防止机架失效时丢失数据,也可以提供带宽利用率。
3)心跳机制,即Namenode周期性从Datanode接受心跳信号和快报告,没有按时发送心跳的Datanode会被标记为宕机,不会再给任何I/O请求,若是Datanode失效造成副本数量下降,并且低于预先设置的阈值,Namenode会检测出这些数据块,并在合适的时机进行重新复制。
4)安全模式,Namenode启动时会先经过一个“安全模式”阶段。
5)校验和,客户端获取数据通过检查校验和,发现数据块是否损坏,从而确定是否要读取副本。
6)回收站,删除文件,会先到回收站/trash,其里面文件可以快速回复。
7)元数据保护,映像文件和事务日志是Namenode的核心数据,可以配置为拥有多个副本。
8)快照,支持存储某个时间点的映像,需要时可以使数据重返这个时间点的状态。
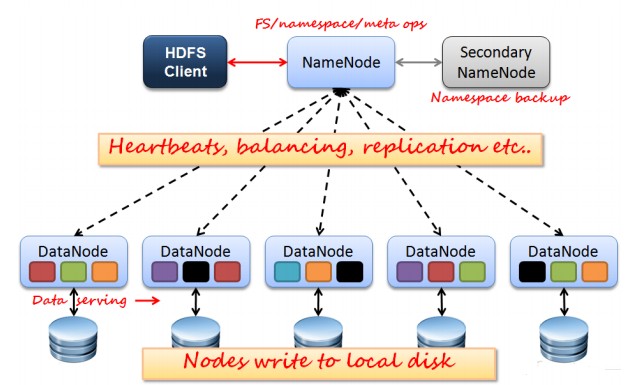
如上图所示,HDFS也是按照Master和Slave的结构。分NameNode、SecondaryNameNode、DataNode这几个角色。
NameNode:是Master节点,是大领导。管理数据块映射;处理客户端的读写请求;配置副本策略;管理HDFS的名称空间;
SecondaryNameNode:是一个小弟,分担大哥namenode的工作量;是NameNode的冷备份;合并fsimage和fsedits然后再发给namenode。
DataNode:Slave节点,奴隶,干活的。负责存储client发来的数据块block;执行数据块的读写操作。
热备份:b是a的热备份,如果a坏掉。那么b马上运行代替a的工作。
冷备份:b是a的冷备份,如果a坏掉。那么b不能马上代替a工作。但是b上存储a的一些信息,减少a坏掉之后的损失。
fsimage:元数据镜像文件(文件系统的目录树。)
edits:元数据的操作日志(针对文件系统做的修改操作记录)
namenode内存中存储的是=fsimage+edits。
Hadoop是一种开源的适合大数据的分布式存储和处理的平台的更多相关文章
- 【Python开发】Python 适合大数据量的处理吗?
Python 适合大数据量的处理吗? python 能处理数据库中百万行级的数据吗? 处理大规模数据时有那些常用的python库,他们有什么优缺点?适用范围如何? 需要澄清两点之后才可以比较全面的看这 ...
- i3s 一种开源的三维地理数据规范 简单解读
i3s,esri主推到ogc的一种三维开源GIS数据标准. 版权声明:原创.博客园/B站/小专栏/知乎/CSDN @秋意正寒 转载请标注原地址并声明转载: https://www.cnblogs.co ...
- 即兴小探华为开源行业领先大数据虚拟化引擎openLooKeng
@ 目录 概述 定义 背景 特点 架构 关键技术 应用场景 安装 单台部署 集群部署 命令行接口 连接器 MySQL连接器 ClickHouse连接器 概述 定义 openLooKeng 官网地址 h ...
- Hadoop第三天---分布式文件系统HDFS(大数据存储实战)
1.开机启动Hadoop,输入命令: 检查相关进程的启动情况: 2.对Hadoop集群做一个测试: 可以看到新建的test1.txt和test2.txt已经成功地拷贝到节点上(伪分布式只有一个节 ...
- GIS+=地理信息+行业+大数据——基于云环境流处理平台下的实时交通创新型app
应用程序已经是近代的一个最重要的IT创新.应用程序是连接用户和数据之间的桥梁,提供即时訪问信息是最方便且呈现的方式也是easy理解的和令人惬意的. 然而,app开发人员.尤其是后端平台能力,一直在努力 ...
- 一脸懵逼学习HBase---基于HDFS实现的。(Hadoop的数据库,分布式的,大数据量的,随机的,实时的,非关系型数据库)
1:HBase官网网址:http://hbase.apache.org/ 2:HBase表结构:建表时,不需要指定表中的字段,只需要指定若干个列族,插入数据时,列族中可以存储任意多个列(即KEY-VA ...
- 为什么MongoDB适合大数据的存储?
NoSQL数据库都被贴上不同用途的标签,如MongoDB和CouchDB都是面向文档的数据库,但这并不意味着它们可以象JSON(JavaScript Object Notation,JavaScrip ...
- 大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池
第0章 预备知识0.1 Scala0.1.1 Scala 操作符0.1.2 拉链操作0.2 Spark Core0.2.1 Spark RDD 持久化0.2.2 Spark 共享变量0.3 Spark ...
- 大数据学习笔记之初识Hadoop
1.Hadoop概述 1.1 Hadoop名字的由来 Hadoop项目作者的孩子给一个棕黄色的大象样子的填充玩具的命名 Hadoop的官网:http://hadoop.apache.org . 1.2 ...
随机推荐
- Java实现附近地点搜索
Java,Mysql-根据一个给定经纬度的点,进行附近500米地点查询–合理利用算法 最近做一个项目:需要查询一个站点(已知该站点经纬度)1km-10km范围内的其它站点.所以,我首先想到的是,对每条 ...
- PDA开发数据由本地上传至DB
private void btnUpLoad_Click(object sender, EventArgs e) { if (!System.IO.File.Exists(LoadFile)) { M ...
- [译] NSScanner:一个陌生的条件判断利器!
NSScanner官方文档 NSScanner类是一个类簇的抽象父类,该类簇为一个从NSString对象扫描值的对象提供了程序接口. NSScanner对象把NSString 对象的的字符解释和转化成 ...
- BASE64Decoder小解
BASE64Decoder小解 Base64 是网络上最常见的用于传输8Bit 字节代码的编码方式之一,大家可以查看RFC2045 -RFC2049 ,上面有MIME 的详细规范. Base64 要求 ...
- 求剁手的分享,如何简单开发js图表
前段时间做的一个项目里需要用到js图表,在网上找了下,大概找到了highcharts.fusioncharts这些国外产品. 因为都收费,虽然有盗版,我也不敢用,万一被找上们来就砸锅卖铁了要.自己写j ...
- ffdshow 源代码分析 3: 位图覆盖滤镜(设置部分Settings)
===================================================== ffdshow源代码分析系列文章列表: ffdshow 源代码分析 1: 整体结构 ffds ...
- 安卓TV开发(前言)— AndroidTV模拟器初识与搭建
原文:http://blog.csdn.net/sk719887916/article/details/39612577skay 前言:移动智能设备的发展,推动了安卓另一个领域,包括智能电视和智能家居 ...
- HBase快照
CDH是Cloudera的完全开源分布式Apache Hadoop及相关项目(包括Apache HBase).CDH的当前版本(4.2)引入的一个HBase新特性最近加入到了主干中,允许用户对指定表进 ...
- HBase中缓存的优先级
ava代码 // Instantiate priority buckets BlockBucket bucketSingle = new BlockBucket(bytesToFree, bloc ...
- Lease问题
经过查明原来是lease引发的问题.不过查问题的过程让我们耽误了很多修复故障的时间,很是不爽. 起因:datanode和regionserver以及master同时挂掉 现象:datanode重启后, ...