消息中间件-RabbitMq相关概念及原理介绍【图文并茂】
消息中间件
消息中间件的作用
- 解耦:消息中间件在服务之间插入了一个隐含的、基于数据的接口层。两边的服务处理过程都要实现这一接口,这允许我们独立的扩展或修改两边的处理过程,只要确保他们遵守相同的规范约束即可
- 冗余(存储):消息中间件可以将数据持久化直到完全被处理
- 扩展性:因为消息中间件解耦了应用的处理过程,所以提高消息入队和处理的效率都是很容易的,只要另外增加处理过程即可,不需要修改代码和调节参数
- 削峰:在访问量骤增的情况下,服务仍然需要可用。但以此为标准设计程序又无疑是巨大的浪费。使用消息中间件可以使关键组件能够给支撑突然访问压力,不会因为突发的超负荷请求而完全崩溃
- 可恢复性、顺序保证(一定程度)、缓冲、异步通讯
Kafka
Kafka 和 RabbitMq 的异同
项目中同时用到了 Kafka 和 RabbitMq,因此需要作比较
Kafka 是一个分布式的消息流处理平台,拥有着极致的吞吐量,支持消息重新消费。非常适合应用在大数据领域。因此我们项目中的收数服务应用了 Kafka 来处理每天 10E 级的数据。
RabbitMq 则胜在拥有更灵活的交换器与队列的匹配规则(基于 topic 交换器 + # * 匹配关键字),还有 TTL+死信队列 实现的延时队列,及简单易上手的可靠性保障,因此在吞吐没有达到每秒几十万的而必须用 kafka 时,RabbitMq 是个很好的选择
RabbitMQ
基础
相关概念介绍
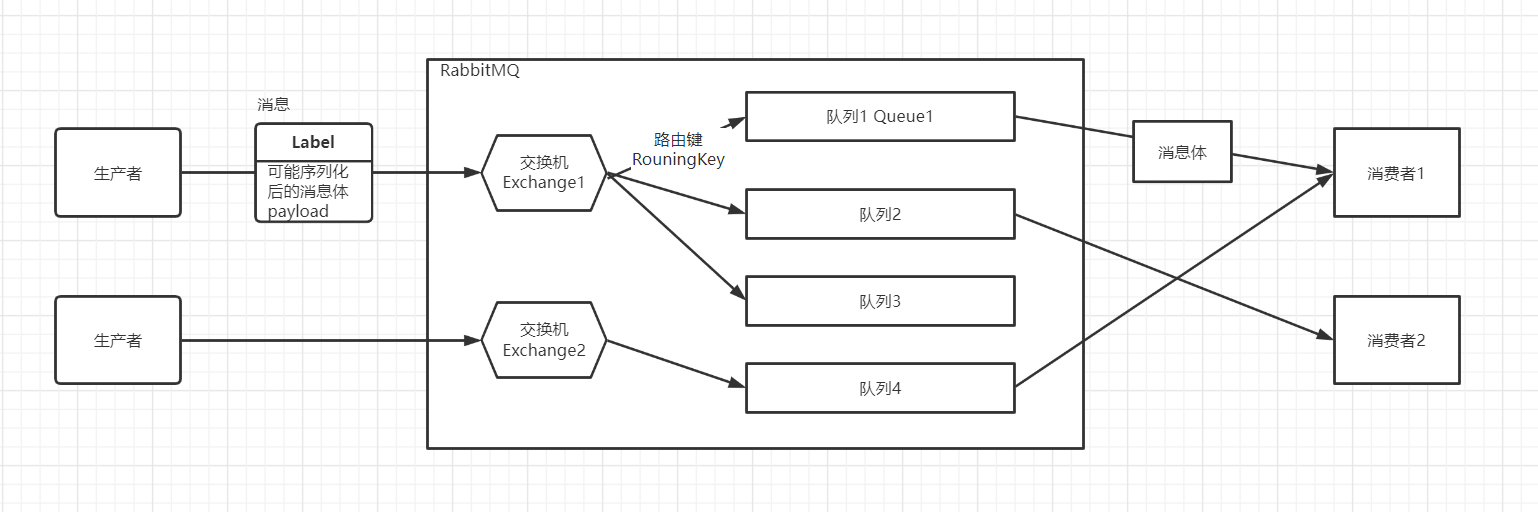
- 生产者:投递消息的一方,生产者创建消息,然后发布到 mq 中。消息一般分为两个部分:消息体和标签,消息体也可称为 payload,实际应用中,消息体一般是一个带有业务逻辑结构的数据。消息的标签用来表述这条消息,比如一个交换器名称和一个路由键
- 消费者:接收消息的一方,当消费者消费一条消息时,只是消费消息的消息体,消息路由的过程中,消息的标签会被丢弃,存入到队列中的只有消息体
- 队列:RabbitMq 消息最终存储在队列中,多个消费者可以订阅同一个队列,这时队列中的消息会被平均分摊。RabbitMq不支持队列层面的广播消费,Kafka 可以通过消费者组实现
- 交换器、路由键、绑定:生产者将消息发送到交换器,交换器根据 RoutingKey 和 BindingKey 将消息路由到队列,如果不能则返回给消费者或丢弃该消息
交换器类型
- fanout: 将消息路由到所有绑定的队列中
- direct:将消息路由到 routingKey 与 bindingKey 完全匹配的队列中
- topic:将消息按照 bindingKey 规则匹配 routingKey ,到指定的队列
- routingKey 和 bindingKey 都是以 . 号分割多个单词的字符串
- BindingKey 可以使用 * 用来匹配一个单词。# 用来匹配 0 个或多个单词
- headers:不依赖路由键的匹配,而是使用一个键值对匹配,几乎不怎么用
队列的排他性
排他队列仅对首次声明他的连接可见,并在连接断开时自动删除。该连接下所有的信道(Channel) 都可以使用它
虚拟主机的作用
多租户场景,对外部而言各个虚拟主机是完全独立的,A主机的交换器不能绑定B主机的队列,权限也是隔离的
Qos
消费者消费速度限制,须配合手动 ack 一起使用,此时当 mq 检测到某个 channel 未 ack 的消息达到阈值后,就不会推送消息到该 cahnnel
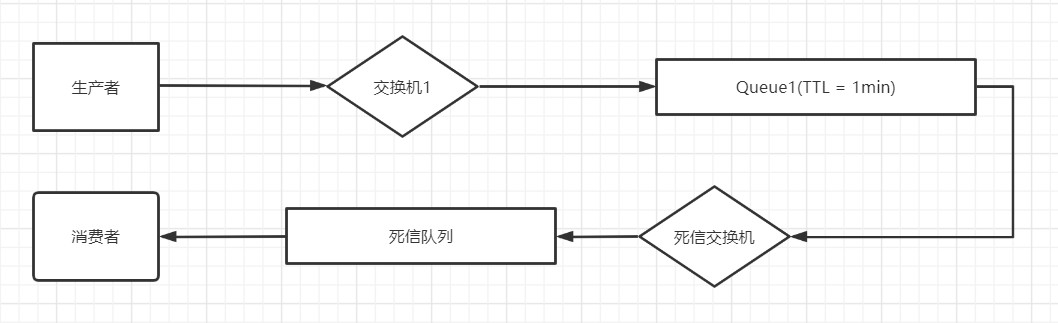
延时队列
可以结合死信队列 + 队列过期时间,模拟延时队列
如何保证消息不丢失
- 首先是消息本身:要确保写了正确的交换机名、路由键名,同时可以设置 mandetory = true 使得消息没找到合适的队列时可以返回给生产者(这样需要编码时添加 ReturnListener 的编码,不方便)。或者添加一个备份交换器,此交换器类型建议设置为 fanout,以保证消息可以被正确路由到队列
- 消费者服务:设置 autoAck = false,程序处理完毕后手动 Ack
- Mq:开启交换器、队列、消息的持久化。同时为了避免消息在落盘之前因为 Mq 宕机而丢失,采用镜像队列机制(高可用 mq)可以最大程度规避此问题
- 生产者服务:为了确保消息成功发送到 mq ,一般有两种方法
- 事物:开启当前 channel 的事物机制,每发送一条消息 commit 一下,如果捕捉到异常则 rollback 同时重新发送该消息。该方法实现简单,但会严重降低吞吐量(相比下一种降低 10 倍)
- 发送方确认机制:开启当前 channel 的发送方确认机制之后,生产者发送消息之后,可以立刻或者批量或者异步等待 mq 响应 ack 或者 nack 消息,在收到 nack 消息后做重发操作,其中立即处理和事物机制吞吐差不多,批量会面临一个消息 nack 这一批消息都重新发送的窘境,异步确认是最为推荐的机制
扩展
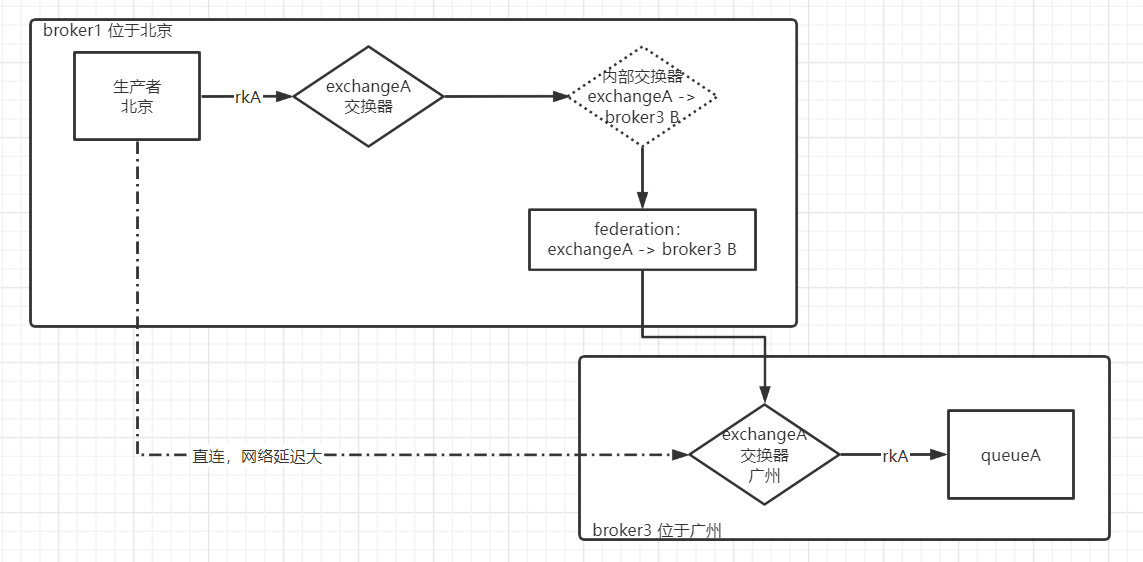
Federation 联邦交换器
假设一种场景:业务A的 clientA 位于北京,需要往位于广州的 exchangeA 发送一条消息,那网络延迟对吞吐量的影响是不容小觑的,如果设置了事务或者开启了消息发送确认,就更慢了
此时可以通过 Federation 插件解决,在 broker3 中为交换器 exchageA 与 broker1 建立一个单向的 Federation 连接,此时 F 会在 broker1 中创建一个同名交换器 exchangeA,同时创建一个内部交换器 exchageA -> broker3 B,还有一个队列 f:eA -> b3 B。并与交换器 eA -> b3 B 绑定,F 插件会在队列: f:eA -> b3 B 与 broker3 中的 exchangeA 建立 AMQP 连接来实时的消费队列中的消息。
这样部署在北京的生产者可以直接向 exchageA 发送消息,可以低延迟的收到回复。而后消息通过 F link 转发到 broker3 的 exchangeA 中,由消费者进行消费
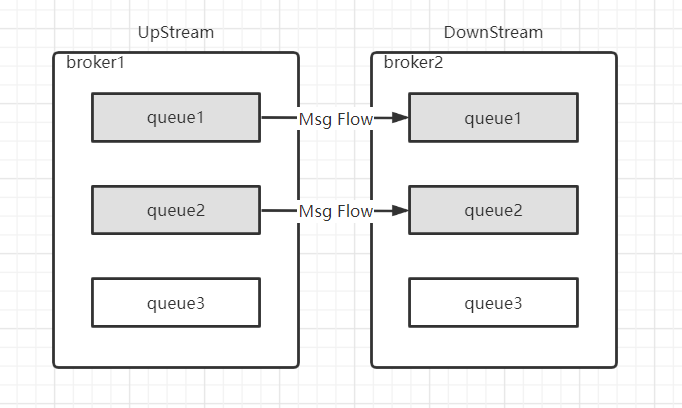
Federation Queue 联邦队列
联邦队列可以在多个 Broker 节点(或者集群)之间为单个队列提供负载均衡的能力。一个联邦队列可以连接一个或多个上游队列(upstream queue),并从上游队列中获取消息以满足本地消费者的消费需求
如图所示:队列 queue1 和 queue2 原本在 broker2 中,由于某种需求将其配置为 fedarated queue 并将 broker1 设置为 upstream queue 。此时 federation 插件会在 broker1 上创建同名的队列 queue1 和 queue2,当有消费者 clientA 连接 broker2 并消费 queue1 (queue2) 时,若队列中有消息则会直接消费,如果队列中没有消息,那么它会通过 Federation 从 broker1 中的 queue1(queue2) 中拉取消息,然后存储到本地。最后被 clientA 消费
同时 Federate Queue 支持双向联邦,一条消息可以在队列中被转发多次,以达到消息最终被转发到某一个消费力更强的 broker 中从而被消费
Shovel 铲子
与 Federation 具备的数据转发功能类似,Shovel 能够持续可靠的从一个 Broker 中的 queue 将消息转发到当前或另一个 Broker 中的 exchange 中(与 F 不同的是它将消息由队列转发至交换机,而 F 类似于在 B1 创建了一个代理,B1 一开始什么都不需要有)
其原理是通过消费队列中的数据同时将数据发送给交换器来实现数据转发, Shovel 同时也支持源数据为交换器或者目标数据为队列。实际上两者都是通过补足虚拟的队列或者交换器实现的
案例:消息堆积的治理
消息堆积严重时,可以选择清空队列,或者添加空消费者丢弃部分消息。但对于重要的数据而言,此举不可行
另一种方案是增加下游的消费能力,但是这种优化代码的方案在紧急时刻缺失“远水解不了近渴”
那么合理的优化方案是(一备一):
- 创建一个额外的队列 queue2,通过 shovel 与原队列 queue1 绑定,当 queue1 中的消息达到阈值 A 时,通过 shovel 将消息转发到 queue2,
- 当 queue1 中的消息减少到阈值 B 时,停止 shovel 转发
- 当 queue1 中的消息减少到阈值 C 时,将 queue2 的消息又转发到 queue1 中
- 当 queue1 中的消息增加到阈值 B 时,停止 shove 转发。这样 3 4 循环以逐步将多余消息消费
如果需要一备多的场景,可以使用镜像队列或 Federation
原理
存储机制
不管是持久化还是非持久化的消息都可以被写入到硬盘。持久化的消息在到达队列时就被写入到磁盘,并且如果可以,持久化的消息也在内存中保存一份备份,当内存吃紧的时候从内存中清除。非持久化的消息一般只保存在内存中,当内存吃紧的时候会被换入磁盘中,以节省内存空间。这两种消息的落盘处理都在 RabbitMq 的“持久层”完成
“持久层”实际上是一个逻辑概念,实际包含两个部分:队列索引 rabbit_queue_index 和消息存储 rabbit_msg_store
rabbit_queue_index 负责维护队列中落盘的消息,包括消息的存储地点、是否已交付给消费者、是否已 Ack,每个队列与之对应的 rabbit_queue_index
rabbit_msg_store 以键值对的形式存储消息,它被所有队列共享,在每个节点有且只有一个
消息(包括消息体、属性和 headers)可以存储在两者中的任意一个。一般通过 queue_index_embed_msg_below 配置一个大小阈值,较小的消息存储在 rabbit_queue_index 中,较大的消息存储在 rabbit_msg_store 中
队列的结构
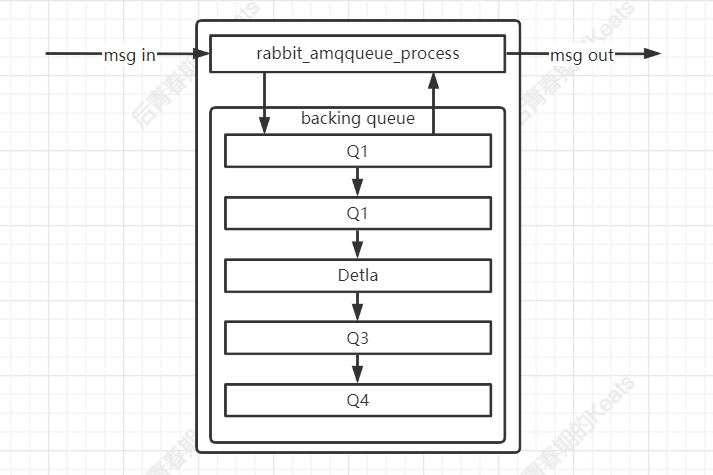
通常队列由 rabbit_amqqueue_process 和 backing_queue 这两部分组成,rabbit_amqqueue_process 负责协议的相关消息处理,backing_queue 是消息存储的具体形式和引擎,消息入队列之后,不是固定不变的,它会随着系统的负载不断的流动,有以下四种状态
- alpha:消息内容和消息索引都存储在内存中
- beta:消息索引存储在内存中,消息内容存储在磁盘中
- gamma:消息内容存储在磁盘中,消息索引存储在内存和磁盘中
- delta:消息内容和消息索引都存储在磁盘中
对于持久化的消息,消息内容和消息索引必须先保存在磁盘上,才会处于上述状态的一种,而 gamma 状态的消息是只有持久化的消息才会有的状态。对于 durable 为 true 的消息,在开启 publish confirm 机制后,只有到了 gamma 状态才会确认消息已被接收
如图所示:Q1 和 Q4 仅存储 alpha 状态的消息,Q2 和 Q3 存储 beta 和 gamma 状态的消息,Detla 存储 detla 状态的消息,当消费者消费消息时,会先从 Q4 从获取,如果成功则返回,如果 Q4 为空则按照一定的规则从上面的队列中转移消息到 Q4 后获取
通常负载正常时,对于不需要保证消息可靠不丢失的情况,极有可能消息只处于 alpha 状态。对于需要持久化的消息,只有当消息处于 gamma 状态时才会确认消息已接收。
惰性队列
惰性队列会尽可能的将消息存储在硬盘之中,而在消费者消费到相应的消息才会加载到内存中。惰性队列会将接收到的消息直接存储到文件系统中,而不管消息是持久化的还是非持久化的,这样可以减少内存的损耗
流控

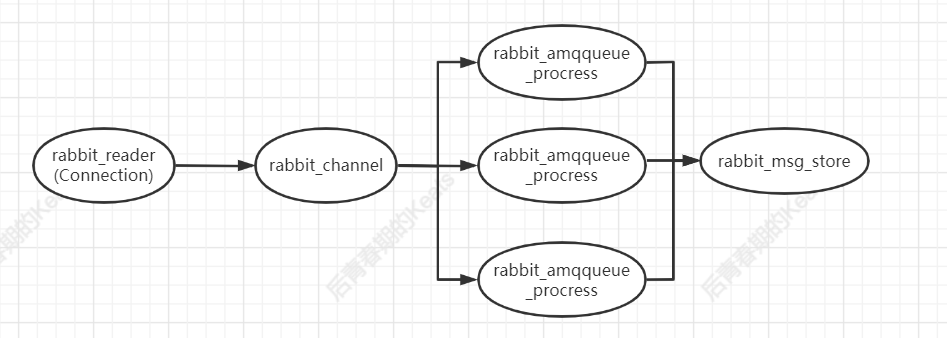
RabbitMq 的流控链如上图所示
- rabbit_reader:connection 的处理进程,负责接收、解析 AMQP 协议数据包等
- rabbit_channel:Channel 的处理进程,负责处理 AMQP 协议中的各种方法,进行路由解析等
- rabbit_amqqueue_process:队列的处理进程,负责实现队列的所有逻辑
- rabbit_msg_store:负责实现队列的持久化
当 connection 处于 flow 状态,而 connection 没有一个 channel 处于 flow 状态,说明 channel 出现了性能瓶颈,一般是因为处理大量较小的非持久化消息时出现
当 connection 处于 flow 状态,并且若干个 channel 处于 flow 状态,但是没有任何一个对应的队列处于 flow 状态。说明一个或多个队列出现了性能瓶颈,这可能是将消息存入队列时 CPU 占用过高,或者将消息持久化到磁盘时 I/O 过高,这种情况一般会在处理大量较小的持久化消息时出现
当 connection、channel、若干队列都是 flow 状态时,意味着在消息持久化时出现了性能瓶颈,这种情况一般在发送大量的较大持久化消息时最容易出现
打破队列的瓶颈
向一个队列中推送消息时,往往会在 rabbit_amqqueue_process(即队列进程中)产生性能瓶颈。那如何破局,提高 rabbit 的性能呢
如图所示,因为 rabbit_amqqueue_process 是队列独享的,而在代码层面实现多个队列会增加业务的复杂度,因此可以通过封装拆分队列的逻辑来解决
镜像队列
如果 RabbitMq 只有一个 Broker 节点,那么该节点的失效将会导致整体服务的暂时不可用,并且有可能导致消息的丢失。可以将消息设置为持久化,并且将消息所属的队列 durable 属性设置为 true,但这仍无法避免缓存导致的问题,因为消息在发送之后到存盘之前有一个短暂的时间窗。通过 publish confirm 机制可以保证消息落盘后确认(前文有提到,broker 会在消息进入 gamma 阶段也即消息体存盘、消息索引磁盘和内存都有的时候,通知生产者消息发送成功),尽管如此,我们仍不希望 Broker 单点导致的服务不可用问题
镜像队列机制可以将队列镜像到集群中的其他 broker 上,如果集群中的一个 broker 失效了,队列能自动的切换到镜像中的另外一个节点保证服务的可用性,每一个镜像队列都包含一个主节点 master,和若干个从节点 slave,相应的结构图如下
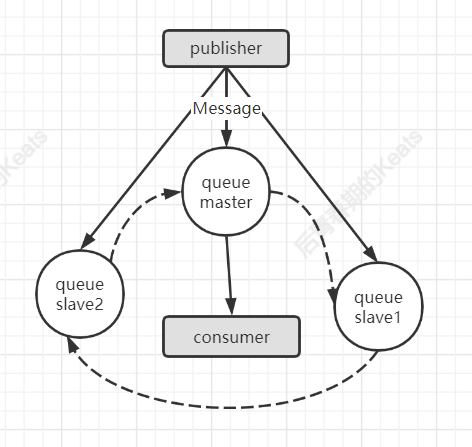
slave 会准确按照 master 的执行命令的顺序进行动作,如果 master 宕机,"资历最老"(加入时间最长)的 slave 会提升成 master,发送到镜像队列的消息会同时发送给 master 和 slave(图中实线),除发送消息外的所有动作只会和 master 打交道,然后由 master 同步给 slave(图中虚线)。同步采用的是一种称为组播 GM(Guaranteed Multicast) 的方式,GM模块的实现是一种可靠的组播通讯协议,该协议能保证组播消息的原子性,即保证组中活着的节点要么都收到消息要么都收不到,它的实现大致如图上所示,所有节点形成一个循环链表,master 发出的消息最终会再次收到,以此确认组中所有节点都收到。
可能有人会觉得,消费者都是从 master 读取消息的,broker 之间是不是没有得到有效的负载均衡?其实不然,负载均衡是对整个 broker 而言,对整个机器而言的,而消费者消费的是队列,只要确保队列的 master 节点均匀的散落在不同的 broker 上,即可确保很大程度的负载均衡
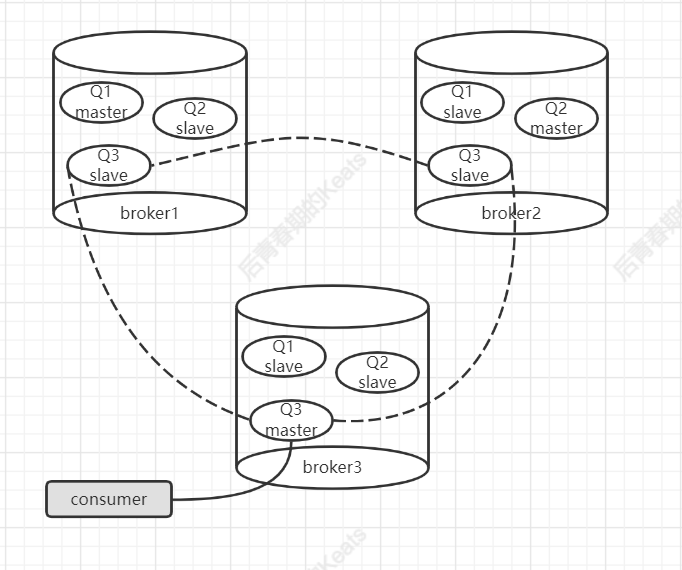
RabbitMq 的镜像队列机制同时支持事物和 publisher confirm 两种机制,在事物机制中,只有当前事物在所有节点中都执行之后,才会返回 OK,同样的在 publisher confirm 机制,只有当所有镜像都接收该消息并处于 gamma 状态时,才会通知生产者
消息中间件-RabbitMq相关概念及原理介绍【图文并茂】的更多相关文章
- RabbitMQ组成及原理介绍-3
rabbitmq作为成熟的企业消息中间件,实现了应用程序间接口调用的解耦,提高系统的吞吐量. 1.RabbitMQ组成 是由 LShift 提供的一个 Advanced Message Queuing ...
- 高性能消息队列 CKafka 核心原理介绍(上)
欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~ 作者:闫燕飞 1.背景 Ckafka是基础架构部开发的高性能.高可用消息中间件,其主要用于消息传输.网站活动追踪.运营监控.日志聚合.流式 ...
- 分布式系统消息中间件——RabbitMQ的使用进阶篇
分布式系统消息中间件--RabbitMQ的使用进阶篇 前言 上一篇文章 (https://www.cnblogs.com/hunternet/p/9668851.html) 简单总结了分布式系 ...
- rabbitMQ消息队列原理
MQ:Message Queue,消息队列,是一种应用程序对应用程序的通信方法:应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们. 1 rabbitMQ入 ...
- RabbitMQ 集群原理和完善
一.RabbitMQ集群方案的原理 RabbitMQ这款消息队列中间件产品本身是基于Erlang编写,Erlang语言天生具备分布式特性(通过同步Erlang集群各节点的magic cookie来实现 ...
- 分布式系统消息中间件——RabbitMQ的使用思考篇
分布式系统消息中间件--RabbitMQ的使用思考篇 前言 前面的两篇文章分布式系统消息中间件--RabbitMQ的使用基础篇与分布式系统消息中间件--RabbitMQ的使用进阶篇,我们简单介 ...
- MySQL数据切分的相关概念和原理详解
对于数据切分,我们可能还不是很熟悉,但是它对于MySQL数据库来说也是相当重要的一门技术,本文我们就详细介绍一下MySQL数据库的数据切分的相关知识,接下来就让我们一起来了解一下这部分内容. 什么是数 ...
- 消息队列介绍、RabbitMQ&Redis的重点介绍与简单应用
消息队列介绍.RabbitMQ&Redis的重点介绍与简单应用 消息队列介绍.RabbitMQ.Redis 一.什么是消息队列 这个概念我们百度Google能查到一大堆文章,所以我就通俗的讲下 ...
- 消息中间件——RabbitMQ(一)Windows/Linux环境搭建(完整版)
前言 最近在学习消息中间件--RabbitMQ,打算把这个学习过程记录下来.此章主要介绍环境搭建.此次主要是单机搭建(条件有限),包括在Windows.Linux环境下的搭建,以及RabbitMQ的监 ...
随机推荐
- Docker Harbor私有仓库部署与管理 (超详细配图)
Docker Harbor私有仓库部署与管理 1.Harbor 介绍 2.Harbor部署 3.Harbor管理 1.Harbor 介绍: 什么是 Harbor ? Harbor 是 VMware 公 ...
- docker 介绍及安装操作
docker 介绍及安装操作 1.docker概述 2.docker安装及操作 1.docker概述: Docker是一个开源的应用容器引擎,基于go语言开发并遵循了apache2.0协议开源 是在L ...
- Linux常用命令精华讲解 上部 (下部下回分解)不要催很忙的
Linux常用命令讲解 1.Linux命令基础 2.Linux命令帮助 3.目录与文件的基操 1.Shell是系统中运行的一种特殊程序在用户和内核之间充当"翻译官"的角色,登录li ...
- epoll反应堆模型实现
epoll反应堆模型demo实现 在高并发TCP请求中,为了实现资源的节省,效率的提升,Epoll逐渐替代了之前的select和poll,它在用户层上规避了忙轮询这种效率不高的监听方式,epoll的时 ...
- Linux中使用systemctl操作服务、新建自定义服务
Linux有12种Unit,对于个人来讲,用的最多的是Service Unit,下面的Unit均指Service Unit(服务单元) # 启动Unit systemctl start appname ...
- 5个不常提及的HTML技巧
2021年你需要知道的HTML标签和属性 Web开发人员都在广泛的使用HTML.无论你使用什么框架或者选择哪个后端语言,框架在变,但是HTML始终如一.尽管被广泛使用,但还是有一些标签或者属性是大部分 ...
- 10、Linux基础--find、正则、文本过滤器grep
笔记 1.晨考 1.每个月的3号.5号和15号,而且这天是星期六时执行 00 00 3,5,15 * 6 2.每天的3点到15点,每隔3分钟执行一次 */3 3-15 * * * 3.每周六早上2点半 ...
- Solution -「AGC 036D」「AT 5147」Negative Cycle
\(\mathcal{Descriprtion}\) Link. 在一个含 \(n\) 个结点的有向图中,存在边 \(\lang i,i+1,0\rang\),它们不能被删除:还有边 \(\l ...
- archery关闭导出功能
https://github.com/hhyo/Archery/issues/1367 进入docker容器,找到sqlquery.html.修改showExport相关配置为以下内容. {% if ...
- SQL Server 索引结构
索引是数据库的基础,只有先搞明白索引的结构,才能搞明白索引运行的逻辑 本文通过 索引表.数据页.执行计划.IO统计.B+Tree 来尽可能的介绍 SQL 语句中 WHERE 部分,和 SELECT 部 ...