梯度下降算法实现原理(Gradient Descent)
概述
梯度下降法(Gradient Descent)是一个算法,但不是像多元线性回归那样是一个具体做回归任务的算法,而是一个非常通用的优化算法来帮助一些机器学习算法求解出最优解的,所谓的通用就是很多机器学习算法都是用它,甚至深度学习也是用它来求解最优解。所有优化算法的目的都是期望以最快的速度把模型参数θ求解出来,梯度下降法就是一种经典常用的优化算法。
梯度下降法的思想
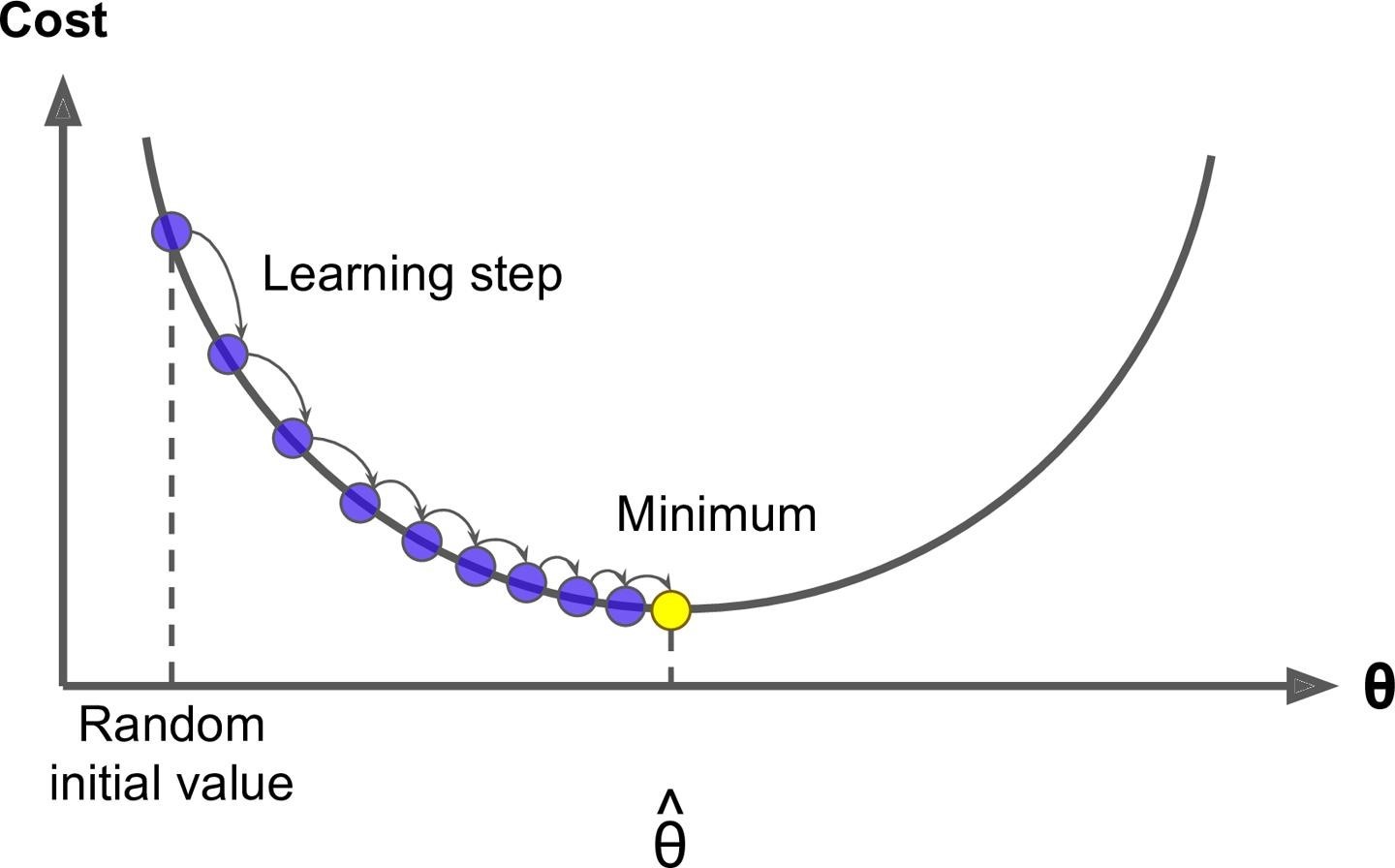
思想就类比于生活中的一些事情,比如你去询问你的一个朋友工资多少,他不会告诉你,但是他会让你去猜,然后告诉你猜的结果。你每说出一次答案,他就会说猜高了或是猜低了,这样下去你就会奔着对方的回答继续猜下去,总有一次能猜到正确答案。梯度下降法就是这样,你得去试很多次,而且我们在试的过程中还得想办法知道是不是在猜对的路上,说白了就是得到正确的反馈再调整。
一般你玩儿这样的游戏的时候,一开始第一下都是随机瞎猜一个对吧,那对于计算机来说是不是就是随机取值,也就是说你有θ =W1...Wn,这里θ强调一下不是一个值,而是一个向量就是一组 W,一开始的时候我们通过随机把每个值都给它随机出来。有了θ我们可以去根据算法就是公式去计算出来^y ,比如 y^ = Xθ ,然后根据计算^y 和真实y之间的损失,比如 MSE,然后调整θ再去计算MSE。
这个调整正如咱们前面说的肯定不是瞎调整,当然这个调整的方式很多,你可以整体θ每个值调大一点,也可以整体θ每个值调小一点,也可以一部分调大一部分调小。第一次θ 0我们可以得到第一次的 MSE 就是 Loss0,调整后第二次θ1对应可以得到第二次的 MSE 就是 Loss1,如果 loss 变小是不是调对了,就应该继续调,如果loss反而变大是不是调反了,就应该反过来调。直到 MSE 我们找到最小值时计算出来的θ^ 就是我们的最优解。这个就好比下山过程,我们把 loss 看出是曲线就是山谷,如果走过来就再往回调,所以是一个迭代的过程。
梯度下降法公式
这里梯度下降法的公式就是一个式子指导计算机迭代过程中如何去调整θ,不需要推导和证明,就是总结出来的。
公式: Wjt+1 = Wjt - η × gradientj
这里的 Wj就是θ中的某一个 j=0…n,这里的η就是图里的 learningstep,很多时候也叫学习率 learning rate,很多时候也用α表示,这个学习率我们可以看作是下山迈的步子的大小,步子迈的大下山就快。
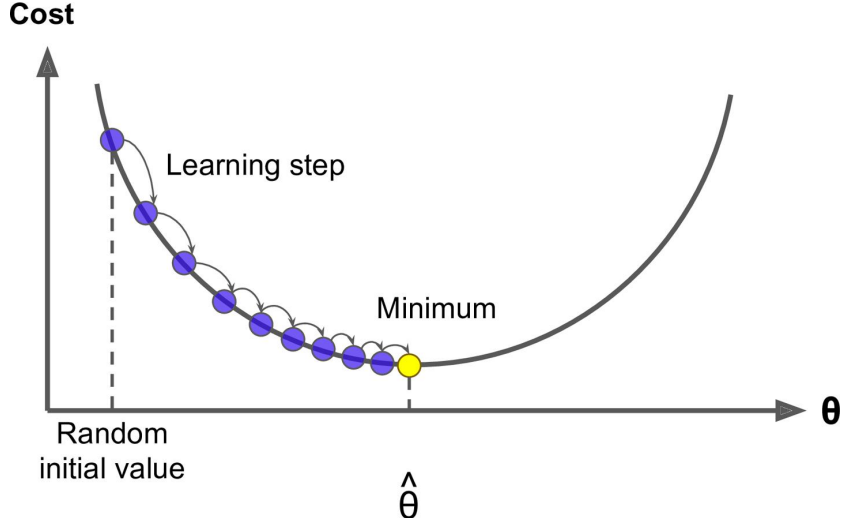
学习率一般都是正数,那么在山左侧梯度是负的,那么这个负号就会把 W 往大了调,如果在山右侧梯度就是正的,那么负号就会把 W 往小了调。每次 Wj 调整的幅度就是η*gradient,就是横轴上移动的距离。
如果特征或维度越多,那么这个公式用的次数就越多,也就是每次迭代要应用的这个式子 n+1 次,所以其实上面的图不是特别准,因为θ对应的是很多维度,应每一个维度都可以画一个这样的图,或者是一个多维空间的图。
W0t+1 =W0t - h×g0
W1t+1 =W1t - h × g1
Wjt+1 =Wjt - h × gj
Wnt+1 =Wnt - h × gn
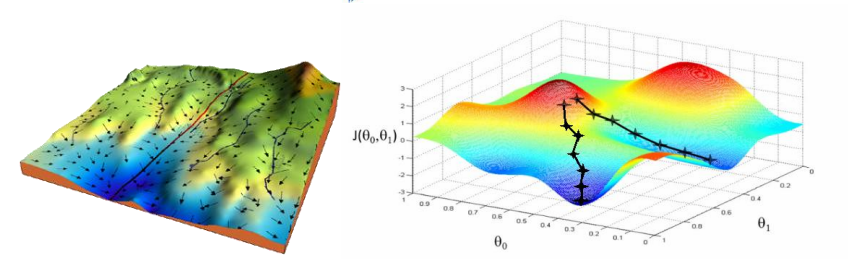
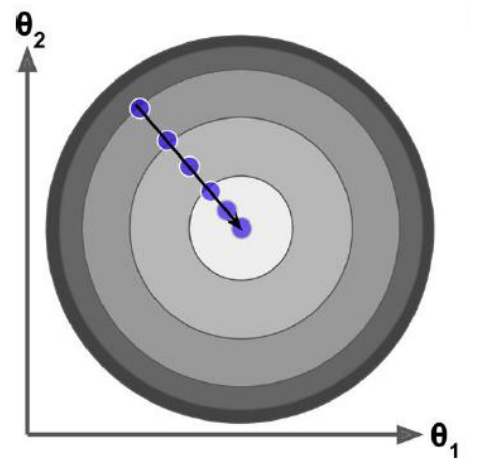
所以观察图我们可以发现不是某一个θ0 或θ1找到最小值就是最优解,而是它们一起找到 J 最小的时候才是最优解。
学习率设置的学问
公式: Wjt+1 = Wjt - η × gradientj
根据我们上面讲的梯度下降法公式,我们知道η是学习率,设置大的学习率 Wj 每次调整的幅度就大,设置小的学习率 Wj 每次调整的幅度就小,然而如果步子迈的太大也会有问题其实,可能一下子迈到山另一头去了,然后一步又迈回来了,使得来来回回震荡。步子太小呢就一步步往前挪,也会使得整体迭代次数增加。
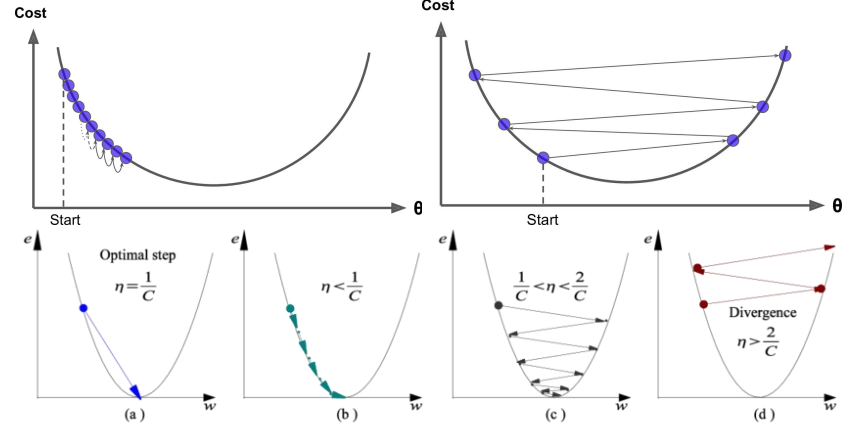
学习率的设置是门学问,一般我们会把它设置成一个比较小的正整数,0.1、0.01、0.001、0.0001,都是常见的设定数值,一般情况下学习率在整体迭代过程中是一直不变的数,但是也可以设置成随着迭代次数增多学习率逐渐变小,因为越靠近山谷我们就可以步子迈小点,省得走过,还有一些深度学习的优化算法会自己控制调整学习率这个值。
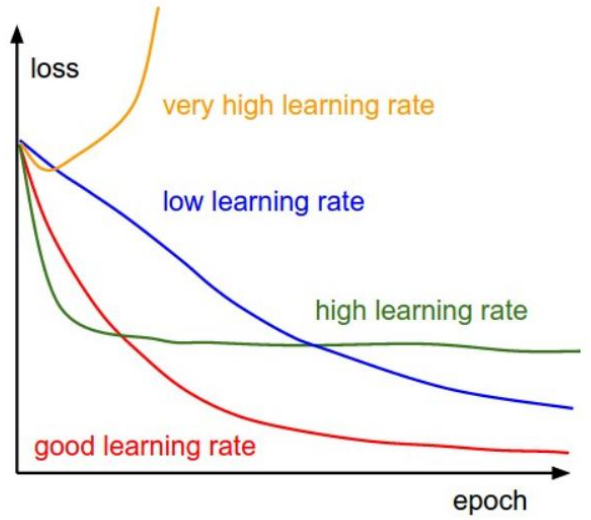
全局最优解

上图可以看出如果损失函数是非凸函数,梯度下降法是有可能落到局部最小值的,所以其实步长不能设置的太小太稳健,那样就很容易落入局部最优解,虽说局部最小也没大问题,因为模型只要是堪用的就好嘛,但是我们肯定还是尽量要奔着全局最优解去。
梯度下降法流程:
- 随机θ,随机一组数值W0...Wn
- 求梯度,为什么是梯度?因为梯度代表曲线某点上的切线的斜率,沿着切线往下下降就相当于沿着坡度最陡峭的方向下降
- if g<0, θ 变大,if g>0, θ 变小
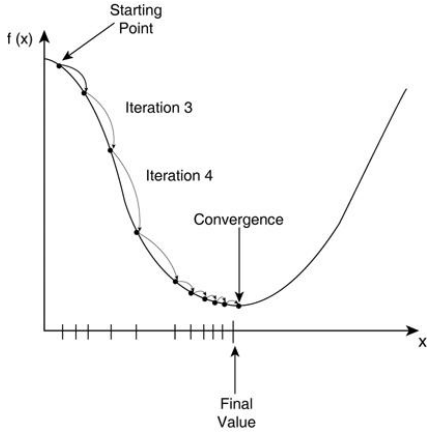
- 判断是否收敛 convergence,如果收敛跳出迭代,如果没有达到收敛,回第 2 步继续
Question?
1.. 如何随机?
2..怎么求梯度?
3..如何调整θ或W?
4..怎么判断收敛?
Answer
1..np.random.rand()或者 np.random.randn()
2..gradientj = \(\frac{∂Loss}{W_j}\)
3..Wit+1 = Wit - h × gradienti
4..判断收敛这里使用 g=0 其实并不合理,因为当损失函数是非凸函数的话 g=0 有可能是极大值对吗!所以其实我们判断 loss 的下降收益更合理,当随着迭代 loss 减小的幅度即收益不再变化就可以认为停止在最低点,收敛!
总结,讲解完梯度下降法流程同学们会发现这里仍然第 2 步不是很清楚怎么去做,但是其它步骤其实都已经清楚比如用编程如何去做对吧,下面就来讲第 2 步该怎么去进一步推导出来表达式。
损失函数的导函数
求解上面梯度下降的第 2 步,即我们要推导出损失函数的导函数来。
θ = θ - α · \(\frac{∂J(θ)}{∂θ}\)
下面公式推导 J(θ)是损失函数,q j 是某个特征维度 Xj 对应的权值系数,也可以写成 Wj。这里我们还是在接着之前的多元线性回归往下讲,所以损失函数是 MSE,所以下面公式表达的是因为我们的 MSE 中 X、y 是已知的,θ是未知的,而θ不是一个变量而是一堆变量,所以我们只能对含有一推变量的函数 MSE 中的一个变量求导,即偏导,下面就是对θj 求偏导。
\]
\]
\]
\]
\(x^2\) 的导数就是 2x,根据链式求导法则,我们可以推出第一步。然后是多元线性回归,所以 hθ(x) 就是 wTx 也是w0·x0+w1·x1+...+wn·xn亦是\(\sum_{n=0}^n{w_ix_i}\),到这里我们是对θj 来求偏导,那么和 Wj 没有关系的可以忽略不计,所以只剩下 Xj。
我们可以得到结论就是θj 对应的 gradient 与预测值^y 和真实值 y 有关,这里^y 和 y 是列向量,同时还与θj 对应的特征维度 Xj 有关,这里 Xj 是原始数据集矩阵的第 j 列。如果我们分别去对每个维度 W0...Wn 求偏导,即可得到所有维度对应的梯度值。
g0 = (hθ(x) - y)·X0
g1 = (hθ(x) - y)·X1
gj = (hθ(x) - y)·Xj
gn = (hθ(x) - y)·Xn
总结:
θjt+1 = θjt - η · gj = θjt - η · (hθ(x) - y) · xj
三种梯度下降法
三种梯度下降区别和优缺点
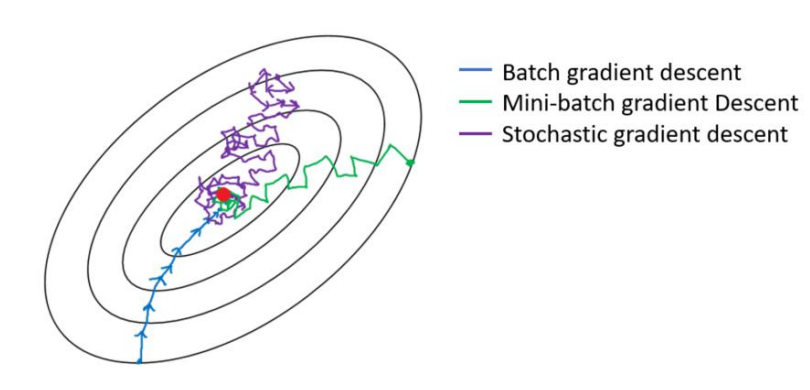
区别:其实三种梯度下降的区别仅在于第 2 步求梯度所用到的 X 数据集的样本数量不同!它们每次学习(更新模型参数)使用的样本个数,每次更新使用不同的样本会导致每次学习的准确性和学习时间不同。
全量梯度下降
Batch Gradient Descent
θjt+1 = θjt - η · \(\sum_{i=1}^m{(h_θ(x^i) - y^i)} · x^i_j\)
在梯度下降中,对于θ的更新,所有的样本都有贡献,也就是参与调整θ。其计算得到的是一个标准梯度。因而理论上来说一次更新的幅度是比较大的。如果样本不多的情况下,当然是这样收敛的速度会更快啦。全量梯度下降每次学习都使用整个训练集,因此其优点在于每次更新都会朝着正确的方向进行,最后能够保证收敛于极值点(凸函数收敛于全局极值点,非凸函数可能会收敛于局部极值点),但是其缺点在于每次学习时间过长,并且如果训练集很大以至于需要消耗大量的内存,并且全量梯度下降不能进行在线模型参数更新。
随机梯度下降
Stochastic Gradient Descent
θjt+1 = θjt - η · (hθ(x(i)) - y(i)) · xj(i)
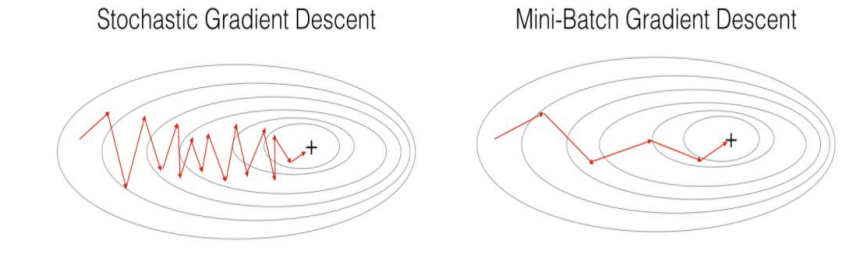
梯度下降算法每次从训练集中随机选择一个样本来进行学习。批量梯度下降算法每次都会使用全部训练样本,因此这些计算是冗余的,因为每次都使用完全相同的样本集。而随机梯度下降算法每次只随机选择一个样本来更新模型参数,因此每次的学习是非常快速的,并且可以进行在线更新。随机梯度下降最大的缺点在于每次更新可能并不会按照正确的方向进行,因此可以带来优化波动(扰动)。
不过从另一个方面来看,随机梯度下降所带来的波动有个好处就是,对于类似盆地区域(即很多局部极小值点)那么这个波动的特点可能会使得优化的方向从当前的局部极小值点跳到另一个更好的局部极小值点,这样便可能对于非凸函数,最终收敛于一个较好的局部极值点,甚至全局极值点。由于波动,因此会使得迭代次数(学习次数)增多,即收敛速度变慢。不过最终其会和全量梯度下降算法一样,具有相同的收敛性,即凸函数收敛于全局极值点,非凸损失函数收敛于局部极值点。
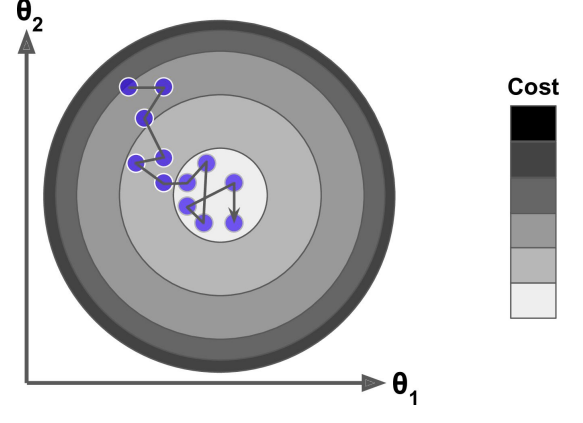
小批量梯度下降
Mini-Batch Gradient Descent
θjt+1 = θjt - η · \(\sum_{i=1}^b{(h_θ(x^i) - y^i)} · x^i_j\)
注:b = batch_size
Mini-batch 梯度下降综合了 batch 梯度下降与 stochastic 梯度下降,在每次更新速度与更新次数中间取得一个平衡,其每次更新从训练集中随机选择 batch_size,batch_size< m 个样本进行学习。相对于随机梯度下降算法,小批量梯度下降算法降低了收敛波动性,即降低了参数更新的方差,使得更新更加稳定。相对于全量梯度下降,其提高了每次学习的速度。并且其不用担心内存瓶颈从而可以利用矩阵运算进行高效计算。一般而言每次更新随机选择[50,256]个样本进行学习,但是也要根据具体问题而选择,实践中可以进行多次试验,选择一个更新速度与更次次数都较适合的样本数。
梯度下降法的问题与挑战
虽然梯度下降算法效果很好,并且广泛使用,但是不管用上面三种哪一种,都存在一些挑战与问题需要解决:
- 选择一个合理的学习速率很难。如果学习速率过小,则会导致收敛速度很慢。如果学习速率过大,那么其会阻碍收敛,即在极值点附近会振荡。
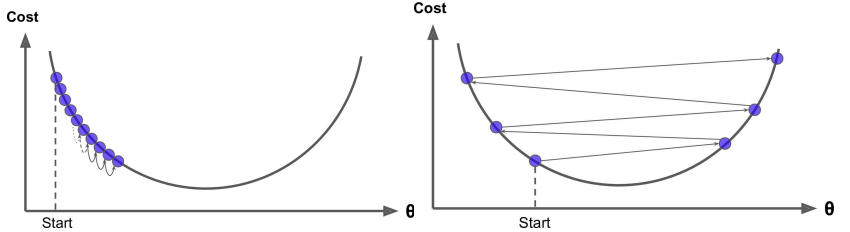
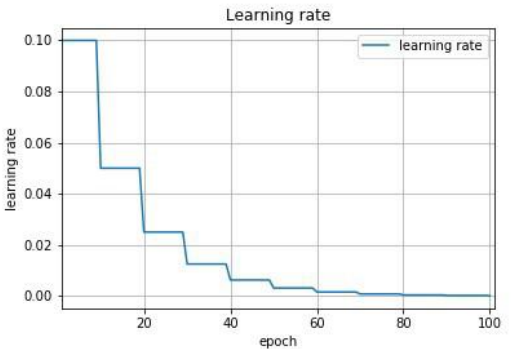
- 学习速率调整(又称学习速率调度,Learning rate schedules 试图在每次更新过程中,改变学习速率,如退火。一般使用某种事先设定的策略或者在每次迭代中衰减一个较小的阈值。无论哪种调整方法,都需要事先进行固定设置,这边便无法自适应每次学习的数据集特点。
- 模型所有的参数每次更新都是使用相同的学习速率。如果数据特征是稀疏的或者每个特征有着不同的取值统计特征与空间,那么便不能在每次更新中每个参数使用相同的学习速率,那些很少出现的特征应该使用一个相对较大的学习速率。

- 对于非凸目标函数,容易陷入那些次优的局部极值点中,如在神经网路中。那么如何避免呢。Dauphin 指出更严重的问题不是局部极值点,而是鞍点(These saddle points are usually surrounded by a plateau of the same error, which makes it notoriously hard for SGD to escape, as the gradient is close to zero in all dimensions.)
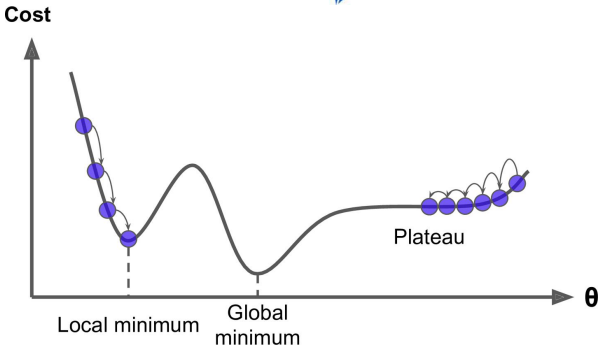
轮次和批次
轮次:epoch,轮次顾名思义是把我们已有的训练集数据学习多少轮
批次:batch,批次这里指的的我们已有的训练集数据比较多的时候,一轮要学习太多数据,那就把一轮次要学习的数据分成多个批次,一批一批数据的学习。
举个例子,这就好比有一本唐诗 300 首需要大家背诵,如果要给你一周时间要你背诵完,或许你很聪明可以背完,但是估计也不敢说一下子全都记得特别牢,甚至到可以出口成章的地步吧。那通常人是怎么做的呢?是不是就是接下来多花几周,重复之前一周的动作,把 300 首唐诗多背几次,比如花 10 周把 300 首唐诗全部倒背如流了,然后又花了 10 周时间把 300 首唐诗又背诵到了滚瓜烂熟的地步终于可以出口成唐诗了。那么刚提到的 10 周、又 10 周放在 AI 领域那么就是所谓的训练了10个轮次又 10 个轮次,总共 20 个轮次。
再回顾上面一段话,我们假设你很聪明,也就是 AI 训练的电脑性能处理能力非常好,如果是普通人或者一般的电脑,很有可能一周都不可能背诵完 300 首,也就是内存一下子装不下那么大的数据量,或者处理器计算能力没有那么快。当数据量大的情况下,这是很常见的现在,那么为了可以顺利背下来 300 首唐诗到举一反三出口成章的地方,也就是为了训练出来 model 模型,我们只能把一个轮次需要的数据分成多个批次来一点点计算,放到背唐诗的例子中,说白了就是一周背不下来 300 首唐诗,那么我们就一周背 50 首唐诗吧比如说,这样我们就需要 6 个批次把一轮数据背完,一个批次所需要的数据batch_size 就是50。
还有就是对于三种梯度下降来说,全量梯度下降就是每一轮次用到全量的数据,然后一次迭代就是一个轮次,然后用全量数据计算梯度来更新一下 W。随机梯度下降每一个轮次也需要计算所有数据,但是有多少数据就会分为多少个批次,即是一个批次一次迭代,就只用一条数据计算梯度来更新一下 W,所以随机梯度下降一个轮次中的更新 W 的次数等于样本总数。最后就是 mini-batch 梯度下降,每一个轮次也需要计算所有数据,但是轮次分成多 少 个 批 次 取 决 于 batch_size , batch_size 大 需 要 的 轮 次 就 少 , 比 如batch_size=num_samples,那就等价于全量批量梯度下降,batch_size=1 那就等价于随机梯度下降。
代码实战梯度下降法与优化
全量梯度下降
创建数据集 X、y
点击查看代码
np.random.seed(1)
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
X_b = np.c_[np.ones((100, 1)), X
创建超参数
点击查看代码
learning_rate = 0.001
n_iterations = 1000
1. 初始化 θ,w0...wn,正太分布创建
点击查看代码
theta = np.random.randn(2, 1)
点击查看代码
# 4,不会设置阈值,直接设置超参数,迭代次数,迭代次数到了,我们就认为收敛了
for _ in range(n_iterations):
# 2,接着求梯度 gradient
gradients = X_b.T.dot(X_b.dot(theta)-y)
# 3,应用公式调整 theta 值,theta_t + 1 = theta_t - grad * learning_rate
theta = theta - learning_rate *
上面代码值得一提的是,X_b.T是X的转置,也就是n行m列的矩阵,然后(X_b.dot(theta)-y)是一个 m 行 1 列的列向量,这样矩阵乘以向量会得到一个 n 行一列的列向量,相当于一下子计算出来所有维度对应的梯度值。然后第 3 步直接去应用所有的梯度到所有的 theta 上面。
#### 随机梯度下降
创建数据集 X、y
点击查看代码
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
X_b = np.c_[np.ones((100, 1)), X]
设置超参数,n_epochs 是迭代的轮次,m 是样本总数,也就是每个轮次迭代的批次
点击查看代码
n_epochs = 10000
m = 100
learning_rate = 0.001
1,初始化 theta,w0...wn,正太分布创建
点击查看代码
theta = np.random.randn(2, 1)
这里是双层 for 循环,第一层 for 循环是分轮次来计算,第二层 for 循环是分批次来计算random_index = np.random.randint(m)是随机的从数据集中取一条数据的索引,然后根据索引来切片操作取随机出来数据的 Xi 和 yi,每次 W 更新所需要的梯度的求解只用到一条样本的信息。
点击查看代码
for epoch in range(n_epochs):
for i in range(m):
# 2, 求 gradient Xi.T * (Xi * theta - yi)
random_index = np.random.randint(m)
xi = X_b[random_index:random_index+1]
yi = y[random_index:random_index+1]
gradients = xi.T.dot(xi.dot(theta)-yi)
# 3, 调整 theta
theta = theta - learning_rate *
小批量梯度下降
创建数据集 X、y
点击查看代码
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
X_b = np.c_[np.ones((100, 1)), X]
设置超参数,n_epochs 是迭代的轮次,m 是样本总数,batch_size 是每个批次迭代需要的数据量,然后 num_batches 是一轮需要多少个迭代需要相除再向上取整
点击查看代码
learning_rate = 0.001
n_epochs = 10000
m = 100
batch_size = 10
num_batches = int(m/batch_size)
1,初始化 theta,w0...wn,正太分布创建
点击查看代码
theta = np.random.randn(2, 1)
和之前代码差别无非就是切片取出来的是 batch_size 个样本数据,然后求解梯度而已
点击查看代码
for epoch in range(n_epochs):
for i in range(num_batches):
# 2, 求 gradient Xi.T * (Xi * theta - yi)
random_index = np.random.randint(m)
x_batch = X_b[random_index:random_index+batch_size]
y_batch = y[random_index:random_index+batch_size]
gradients = x_batch.T.dot(x_batch.dot(theta)-y_batch)
# 3, 调整 theta
theta = theta - learning_rate * gradient
至此,就基本介绍完了梯度下降法的基本思想和算法流程
梯度下降算法实现原理(Gradient Descent)的更多相关文章
- 采用梯度下降优化器(Gradient Descent optimizer)结合禁忌搜索(Tabu Search)求解矩阵的全部特征值和特征向量
[前言] 对于矩阵(Matrix)的特征值(Eigens)求解,采用数值分析(Number Analysis)的方法有一些,我熟知的是针对实对称矩阵(Real Symmetric Matrix)的特征 ...
- 机器学习-随机梯度下降(Stochastic gradient descent)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- 批量梯度下降(Batch gradient descent) C++
At each step the weight vector is moved in the direction of the greatest rate of decrease of the err ...
- 随机梯度下降法(Stochastic gradient descent, SGD)
BGD(Batch gradient descent)批量梯度下降法:每次迭代使用所有的样本(样本量小) Mold 一直在更新 SGD(Stochastic gradientdescent)随机 ...
- 临近梯度下降算法(Proximal Gradient Method)的推导以及优势
邻近梯度下降法 对于无约束凸优化问题,当目标函数可微时,可以采用梯度下降法求解:当目标函数不可微时,可以采用次梯度下降法求解:当目标函数中同时包含可微项与不可微项时,常采用邻近梯度下降法求解.上述三种 ...
- 随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )的公式对比、实现对比[转]
梯度下降(GD)是最小化风险函数.损失函数的一种常用方法,随机梯度下降和批量梯度下降是两种迭代求解思路,下面从公式和实现的角度对两者进行分析,如有哪个方面写的不对,希望网友纠正. 下面的h(x)是要拟 ...
- 【转】 随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )的公式对比、实现对比
梯度下降(GD)是最小化风险函数.损失函数的一种常用方法,随机梯度下降和批量梯度下降是两种迭代求解思路,下面从公式和实现的角度对两者进行分析,如有哪个方面写的不对,希望网友纠正. 下面的h(x)是要拟 ...
- 近端梯度算法(Proximal Gradient Descent)
L1正则化是一种常用的获取稀疏解的手段,同时L1范数也是L0范数的松弛范数.求解L1正则化问题最常用的手段就是通过加速近端梯度算法来实现的. 考虑一个这样的问题: minx f(x)+λg(x) x ...
- 机器学习-随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )
梯度下降(GD)是最小化风险函数.损失函数的一种常用方法,随机梯度下降和批量梯度下降是两种迭代求解思路,下面从公式和实现的角度对两者进行分析,如有哪个方面写的不对,希望网友纠正. 下面的h(x)是要拟 ...
随机推荐
- Apache Flink系列-④有状态函数
有状态函数:独立于平台的有状态无服务器堆栈 这是一种在现代基础设施上创建高效.可扩展且一致的应用程序的简单方法,无论规模大小. 有状态函数是一种API,它通过为无服务器架构构建的运行时简化了分 ...
- 《图解UE4渲染体系》Part 1 多线程渲染
上回书<Part 0 引擎基础>说到,我们粗略地知道UE4是以哪些类来管理一个游戏场景里的数据的,但这仅仅是我们开始探索UE4渲染体系的一小步. 本回主要介绍UE4渲染体系中比较宏观顶层的 ...
- synchronized锁及其锁升级
点赞再看,养成习惯,微信搜索「小大白日志」关注这个搬砖人. 文章不定期同步公众号,还有各种一线大厂面试原题.我的学习系列笔记. 多线程加锁有两种方式 利用Sychronized关键字 利用Lock接口 ...
- 攻防世界-MISC:stegano
这是攻防世界新手练习区的第五题,题目如下: 点击附件1下载,得到一个pdf文件,打开后内容如下: 把pdf文件里的内容复制到记事本上,发现一串A和B的字符串,不知道是什么(真让人头大) 参考一下WP, ...
- XCTF练习题---MISC---can_has_stdio?
XCTF练习题---MISC---can_has_stdio? flag:flag{esolangs_for_fun_and_profit} 解题步骤: 1.观察题目,下载附件 2.打开发现是由tra ...
- WPFApplication类
Application类 应用程序类Application,以下代码自动生成且在程序中不可见,定义程序入口点方法以及程序启动程序,整个程序生命周期为执行完Main()方法里的程序.对于自定义的应用程序 ...
- 使用 Vert.X Future/Promise 编写异步代码
Future 和 Promise 是 Vert.X 4.0中的重要角色,贯穿了整个 Vert.X 框架.掌握 Future/Promise 的用法,是用好 Vert.X.编写高质量异步代码的基础.本文 ...
- Java 18为什么要指定UTF-8为默认字符集
在Java 18中,将UTF-8指定为标准Java API的默认字符集.有了这一更改,依赖于默认字符集的API将在所有实现.操作系统.区域设置和配置中保持一致. 做这一更改的主要目标: 当Java程序 ...
- C++基础-5-运算符重载(加号,左移,递增,赋值,关系,函数调用)
5. 运算符重载 5.1 加号运算符重载 1 #include<iostream> 2 using namespace std; 3 4 // 加号运算符重载 5 6 class Per ...
- 打造一款高逼格的Vim神器
点击上方"开源Linux",选择"设为星标" 回复"学习"获取独家整理的学习资料! 作者:枫上雾棋 链接:https://segmentfa ...