Spark通过打jar包形式提交任务
idea构建项目
- 创建一个maven项目,配置pom依赖,以及scala编译插件。 注意一定要保证,你的scala版本和spark版本和要提交的集群版本一致,要不很多莫名其妙的问题,scala如果你在window安装的版本就是和集群不一样,又懒得重新装,可以看 2 中,通过idea配置版本,并在编译插件里面指定好scala编译版本
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>sparkextract</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.4.8</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.8</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.8</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.12</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>4.7.2</version>
<configuration>
<scalaVersion>2.11.12</scalaVersion>
</configuration>
</plugin>
</plugins>
</build>
</project>
配置scala的SDK, idea选项栏 File -> Project Structure -> Global Libraries
点击 + 号,选择一致的scala版本
编辑你的代码, 需要注意,SparkConf里,不要配置master的内容,否则在submit提交的时候,指定的master会失效。
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount{
def main(args: Array[String]):Unit = {
// spark配置新建
val sparkConf = new SparkConf().setAppName("Operator")
// spark上下文对象
val spark: SparkContext = SparkContext.getOrCreate(sparkConf)
// wordcount逻辑开始
val inPath: String = "hdfs:///user/zhangykun0508/exe.log"
val outPath: String = "hdfs:///user/zhangykun0508/wc.out"
val file: RDD[String] = spark.textFile(inPath)
val result: RDD[(String, Int)] = file.flatMap(a => a.split(" ")).map(a => (a, 1)).reduceByKey(_ + _)
result.saveAsTextFile(outPath)
}
}
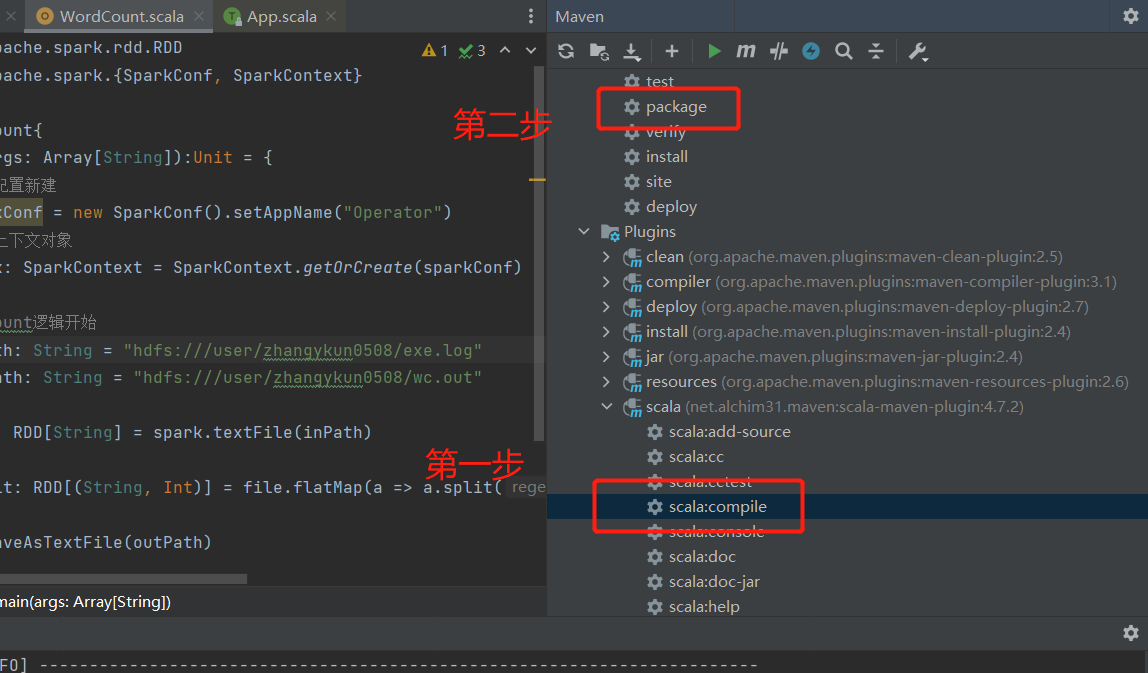
- 打jar包,注意先要用 scala插件编译,然后再用maven打包
任务提交
我这边提交的方式为提交到yarn上。将上一步打包好的jar文件,传到hadoop的节点,然后按以下命令执行
spark-submit \
--class WordCount \
--conf inPath=hdfs:///user/zhangykun0508/exe.log outPath=hdfs:///user/zhangykun0508 \
--master yarn \
--deploy-mode cluster \
./sparkextract.jar \
10
-- 命令解析
spark-submit \ # 执行spark-submit应用
--class WordCount \ # 指定本次任务的Main方法所在的类, 如果你的程序比较规范,记得要输入包名,如: com.zyk.sparktest.WordCount
--master yarn \ # 指定任务提交的方式为yarn
--deploy-mode cluster \ # 指定yarn的部署方式为 cluster, 即由yarn创建的 ApplicationMaster来运行创建driver
./sparkextract.jar \ # 指定你要执行的jar包
10 # 设置默认的任务数量
Spark通过打jar包形式提交任务的更多相关文章
- maven项目导出依赖的Jar包以及项目本身以jar包形式导出详细教程
一.maven项目已jar包形式导出 1.首先右键项目,选择Export 2.选择好项目,设置导出路径和jar名字即可: 二.导出maven项目所依赖的所有jar包 1.右键项目,选择Export 2 ...
- WebJars简介 —— 前端资源的jar包形式(以后接触到再深入总结)
对于日常的web开发而言,像css.js.images.font等静态资源文件管理是非常的混乱的.比如jQuery.Bootstrap.Vue.js等,可能每个框架使用的版本都不一样.一不注意就会出现 ...
- [Spark Core] Spark 使用第三方 Jar 包的方式
0. 说明 Spark 下运行job,使用第三方 Jar 包的 3 种方式. 1. 方式一 将第三方 Jar 包分发到所有的 spark/jars 目录下 2. 方式二 将第三方 Jar 打散,和我们 ...
- spark项目打jar包,不包含依赖包问题的解决方案
mvn clean package打包maven-archetype-webapp项目时,打包后的jar包含项目中引用的jar包(解压后,在WEB-INF有一个lib目录,该目录下有所有依赖包). m ...
- Springboot打包成jar包形式发布
1.修改配置文件pom.xml 添加打包形式设置为jar形式 <packaging>jar</packaging> 2.在build标签内添加内容如下 finalname为打包 ...
- 如何在gradle项目中添加额外非开源jar包并提交代码
前提:项目开发中,遇到一个地方需要用到公司自定义的jar包,然后要放到代码里又不方便提交到私服 具体实施: 首先在项目中增加一个 libs目录,然后把这种非开源又不在私服上的jar包扔进去, 然后打开 ...
- Flink源码剖析:Jar包任务提交流程
Flink基于用户程序生成JobGraph,提交到集群进行分布式部署运行.本篇从源码角度讲解一下Flink Jar包是如何被提交到集群的.(本文源码基于Flink 1.11.3) 1 Flink ru ...
- HDFS的java客户端操作代码(Windows上面打jar包,提交至linux运行)
1.通过java.net.URL实现屏幕显示demo1文件的内容 package Hdfs; import java.io.InputStream; import java.net.URL; impo ...
- [Android] Android工程以jar包形式向第三方应用提供服务
参考: http://www.cnblogs.com/0616--ataozhijia/p/4094952.html 以API 19为例: 系统默认提供的 android.jar整体大小为: 21.8 ...
- Eclipse中将java类打成jar包形式运行
记录一次帮助小伙伴将java类打成jar包运行 1.创建java project项目 file > new > project > java project 随便起一个项目名称,fi ...
随机推荐
- KingbaseES V8R6 锁等待检测
背景 对于多数数据库,dba技能之一就是查找锁.锁的存在有效合理的在多并发场景下保证业务有序进行.下面我们看一下KingbaseESV8R6中查找阻塞的方法. 1.找到"被阻塞者" ...
- 不建议升级windows11的理由
此文写于2022年9月13日,用于警告那些蠢蠢欲动想升级win11的伙伴. win11发布后,最亮眼的功能当然是自带"安卓模拟器",但作为一名程序开发者的我其实是不愿意马上尝鲜的, ...
- ProxySQL 密码管理
ProxySQL是一个协议感知的proxy.由于ProxySQL基于流量进行路由,当一个客户端连接ProxySQL时,它还无法识别它的目标主机组,因此ProxySQL需要对该客户端进行认证.基于此,需 ...
- 9. 第八篇 kube-controller-manager安装及验证
文章转载自:https://mp.weixin.qq.com/s?__biz=MzI1MDgwNzQ1MQ==&mid=2247483826&idx=1&sn=88f0cef6 ...
- 使用kuboard部署某一个应用的pod分布于不同的主机上
情况介绍 1.k8s集群有8个节点,3个节点是master,分别是master1,master2,master3. 5个worker节点,分别是worker1,worke2,worke3,worker ...
- 查看pod对应的DNS域名
单个pod # kubectl exec redis-pod-0 -n cluster-redis -- hostname -f redis-pod-0.redis-cluster-service.c ...
- Loki二进制命令帮助
Usage of config-file-loader: -auth.enabled Set to false to disable auth. (default true) -azure.accou ...
- Fluentd直接传输日志给kafka
官方文档地址:https://docs.fluentd.org/output/kafka td-agent版本自带包含out_kafka2插件,不用再安装了,可以直接使用. 若是使用的是Fluentd ...
- 我的 Kafka 旅程 - Consumer
kafka采用Consumer消费者Pull主动拉取数据的方式,当Broker无数据时,消费者空转.Kafka并不删除已消费的消息,各自独立的消费者可消费同一个Broker分区数据. 消费流程 1.消 ...
- 某云负载均衡获取客户端真实IP的问题
某云负载均衡真实IP的问题,我们这边已经遇到过两次了.而且每次和售后沟通的时候都大费周折,主要是要给售后说明白目前文档的获取真实IP是有问题的,他们觉得文档上说明的肯定没问题,售后要是不明白,他们不会 ...