Debiased Contrastive Learning of Unsupervised Sentence Representations 论文精读
1. 介绍(Introduction)
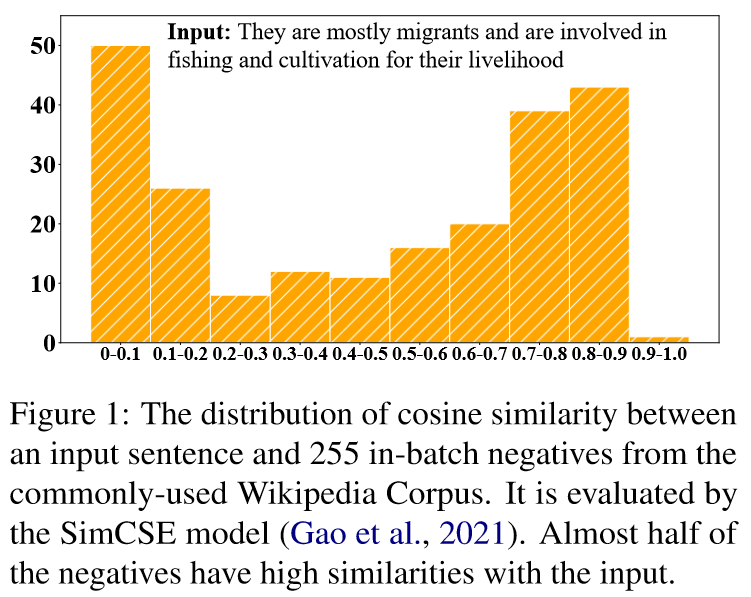
问题: 由PLM编码得到的句子表示在方向上分布不均匀, 在向量空间中占据一个狭窄的锥形区域, 这在很大程度上限制了它们的表达能力.
已有的解决办法: 对比学习. 对于一个原句, 构造他的正例(语义相似的句子)和负例(语义不相似的句子), 拉近语义相近的句子来提高对齐性,同时让语义不同的句子远离来使向量空间中的句子更均匀. 正例通常用数据增强的策略来获得. 由于没有真实标注的数据, 负例一般在一个batch中随机抽样得到. 但这可能会导致抽样偏差, 影响句子表示的学习. 表现在以下两个方面:
- 抽样的负例很可能是假负例, 他们在语义上其实是接近原句的. 如果简单地拉远些抽样得到的非负例, 很可能会损害句子表示的语义.
- 由于各向异性问题, 由PLMs得到的句子向量本身就在向量空间中仅占据一个狭窄的锥形区域, 从他们中随机抽取出的负例也不能完全反映表示空间的整体语义.
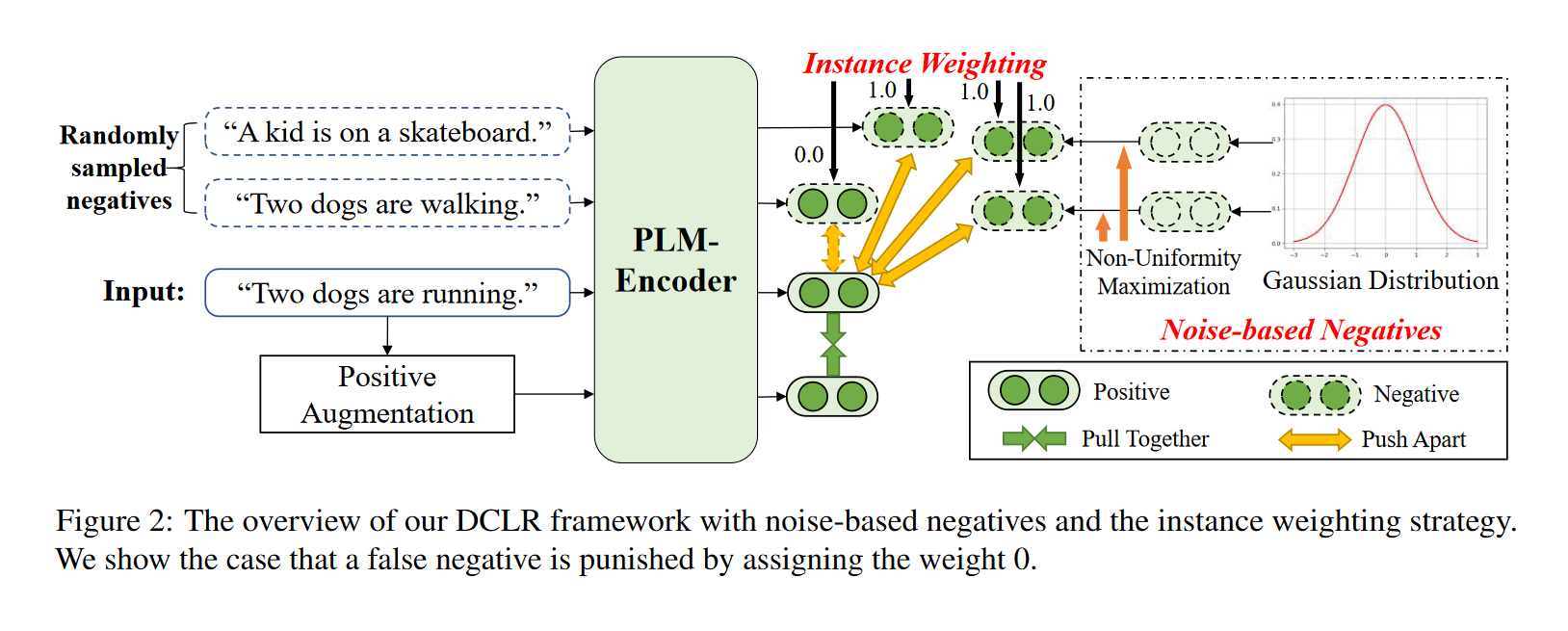
2. 方法(Approach)
DCLR(a general framework towards Debiased Contrastive Learning of unsupervised sentence Representations), 一种无监督句子表示的去偏向对比学习的一般框架。
核心思想是改进随机负抽样策略, 以缓解抽样偏差问题:
- 设计了一种加权方法来惩罚训练过程中采样的假负例。用一个辅助模型(complementary model)来评估每个负例与原句之间的相似性,为相似性得分较高的负例分配较低的权重。
- 用基于随机高斯噪声随机初始化新负例来模拟整个语义空间内的采样,并设计了一种基于梯度的算法,将这些负例优化到最不均匀的点。
步骤:
从高斯分布初始化基于噪声负例,并利用基于梯度的算法, 通过考虑表示空间的均匀性来更新这些负例。
用辅助模型对这些基于噪声的负例和在batch中随机抽样的负例进行加权, 惩罚其中的假负例.
通过SimCSE中dropout的方式来获得正例, 并将其与上述加权负例相结合进行对比学习.
基于高斯噪声的负例的构建与优化:
- 构建: 对于每个输入句子\(x_i\),我们首先初始化\(k\)个来自高斯分布的噪声向量作为负例:
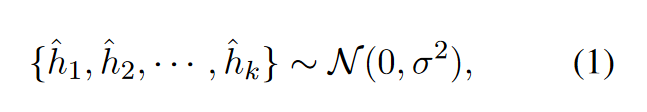
- 非均匀性损失(non-uniformity loss)来优化这些负例向量:
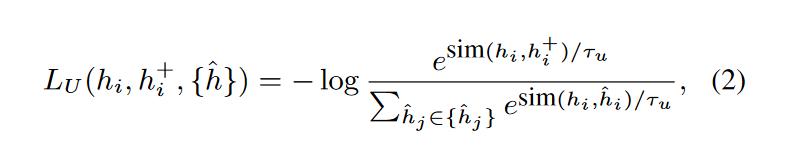
梯度下降:
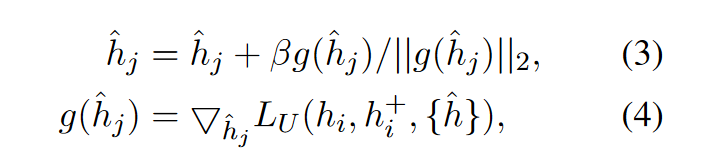
这样,基于噪声的负例将朝着句子表示空间的非均匀点进行优化. 通过学习对比这些负例, 可以进一步提高表征空间的均匀性, 这对于得到更有效的句子表示至关重要.
辅助模型(complementary model):
使用SOTA模型SimCSE作为辅助模型, 用于判断句子间的语义相似度. 具体的:
对于一个句子\(s_i\), 定义它的向量表示为\(h_i\), 从batch中随机抽取的负例为\(\set{\tilde{h}}\), 基于噪声构造的的负例为\(\set{\hat{h}}\), 对于来自\(\set{\tilde{h}}\)和\(\set{\hat{h}}\)的负例\(h^-\), 其权重为:
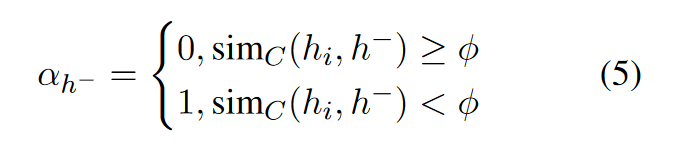
其中\(\phi\)是超参数, \(\text{sim}_C(h_i, h^-)\)表示SimCSE的相似度打分. 相当于直接舍弃了阈值小于\(\phi\)的负例.
对比学习的损失
最后, 对比学习的损失函数如下:
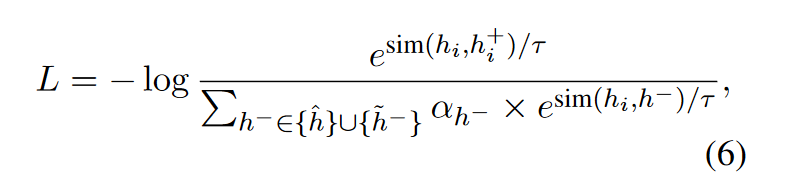
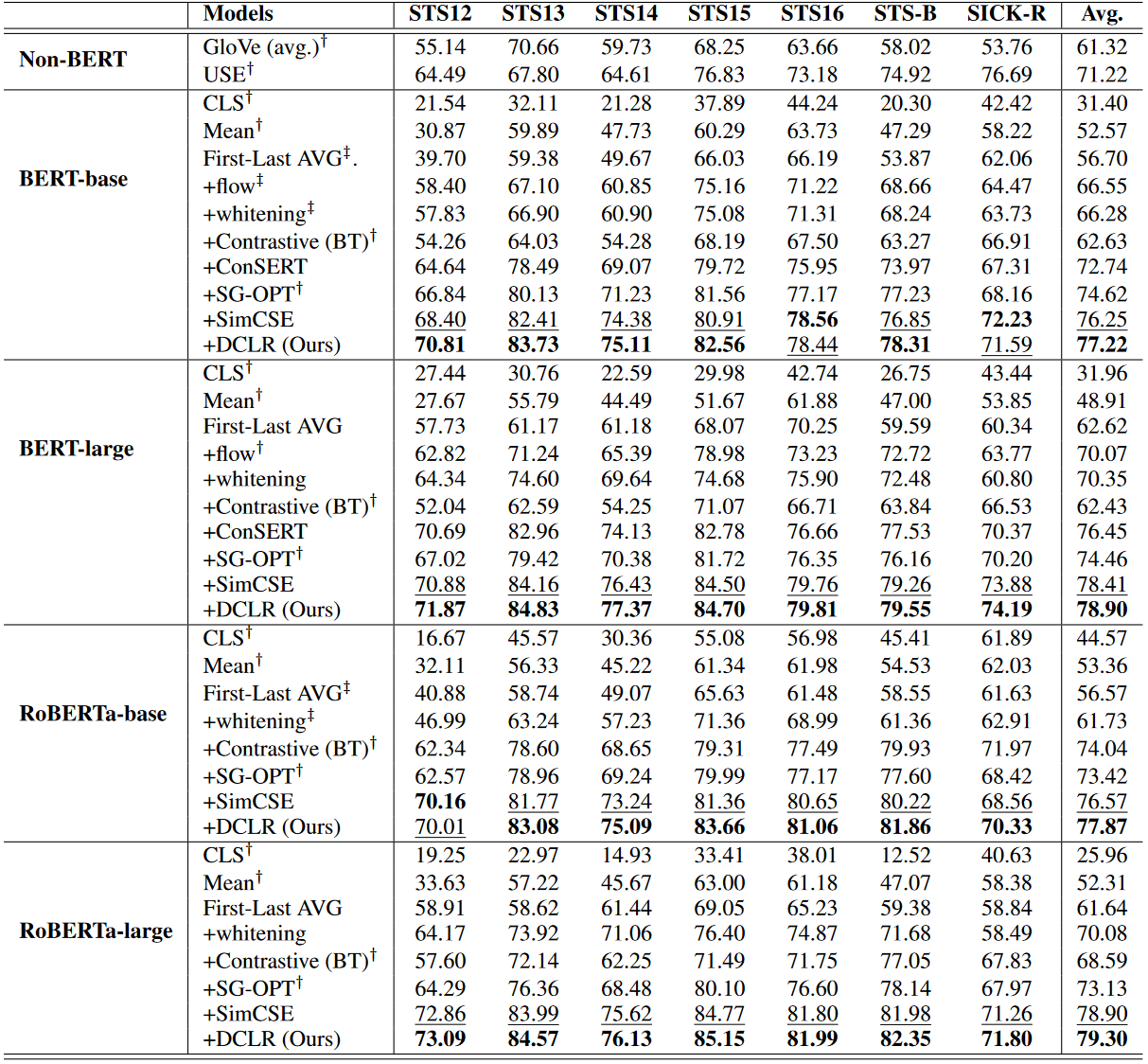
3. 性能(Performance)
4. 分析(Analysis)
4.1 超参数分析(Hyper-parameters Analysis)
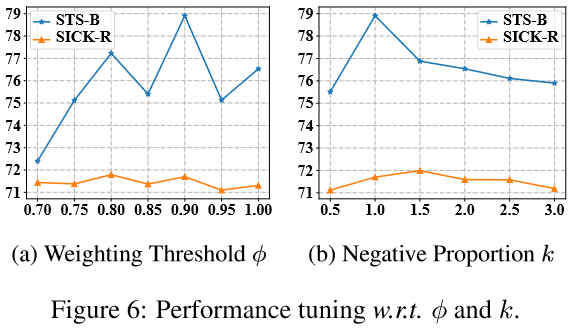
\(k\)表示基于噪声的负例数量与批量大小的比值.
4.2 均匀性分析(Uniformity Analysis)
用一下损失来评估句子表示的均匀性:
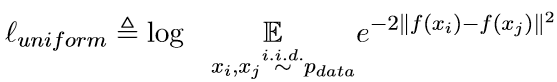
该损失值越小说明分布越均匀.
含义: 希望来自数据分布的句子之间欧氏距离的期望尽可能大.
与SimCSE的对比:
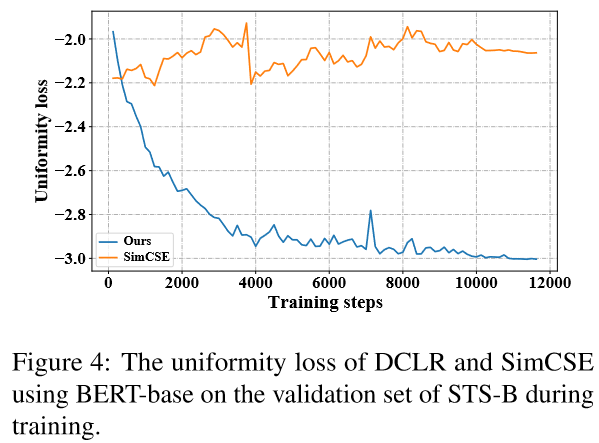
因为DCLR在表示空间之外对基于噪声的负例进行了采样, 这样可以更好地提高句子表示的均匀性.
有个问题, 文章没有对对齐性(Alignment)进行分析.
4.3 消融实验(Ablation Study)
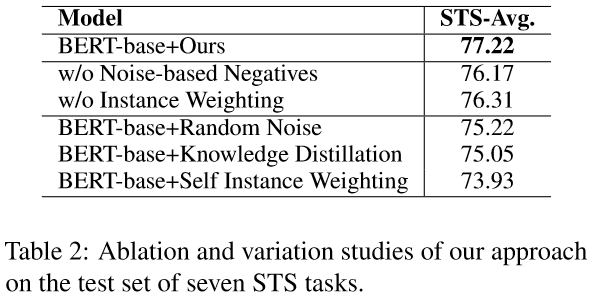
随机噪声(Random Noise): 直接生成基于噪声的负例, 不进行基于梯度的优化.
知识蒸馏(Knowledge Distillation): 利用SimCSE作为教师模型,在训练时将知识蒸馏到学生模型中.
自加权(Self Instance Weighting): 采用模型本身作为辅助模型来生成权重.
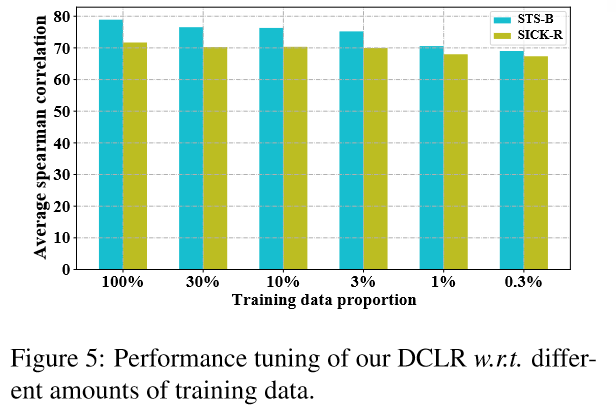
4.4 少样本下的性能(Performance under Few-shot Settings)
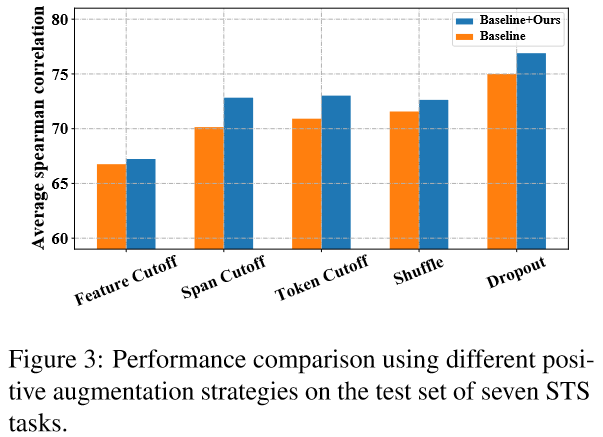
4.5 采用其他正例生成策略(Debiased Contrastive Learning on Other Methods)
DCLR主要关注的是对比学习中的负例采样策略, 因此在构建正例时, 有多种数据增强策略可选. 文中测试了3种:
- 乱序(Token Shuffing): 随机打乱输入序列中token的顺序
- 删词(Feature/Token/Span Cutoff): 随机去掉输入中的features/tokens/token spans.
- Dropout: 即SimCSE中正例的生成方式.
Debiased Contrastive Learning of Unsupervised Sentence Representations 论文精读的更多相关文章
- 论文解读(CDCL)《Cross-domain Contrastive Learning for Unsupervised Domain Adaptation》
论文信息 论文标题:Cross-domain Contrastive Learning for Unsupervised Domain Adaptation论文作者:Rui Wang, Zuxuan ...
- 论文解读(PCL)《Prototypical Contrastive Learning of Unsupervised Representations》
论文标题:Prototypical Contrastive Learning of Unsupervised Representations 论文方向:图像领域,提出原型对比学习,效果远超MoCo和S ...
- 论文解读(Debiased)《Debiased Contrastive Learning》
论文信息 论文标题:Debiased Contrastive Learning论文作者:Ching-Yao Chuang, Joshua Robinson, Lin Yen-Chen, Antonio ...
- 论文解读(SimCLR)《A Simple Framework for Contrastive Learning of Visual Representations》
1 题目 <A Simple Framework for Contrastive Learning of Visual Representations> 作者: Ting Chen, Si ...
- 论文解读(gCooL)《Graph Communal Contrastive Learning》
论文信息 论文标题:Graph Communal Contrastive Learning论文作者:Bolian Li, Baoyu Jing, Hanghang Tong论文来源:2022, WWW ...
- 论文解读(MLGCL)《Multi-Level Graph Contrastive Learning》
论文信息 论文标题:Structural and Semantic Contrastive Learning for Self-supervised Node Representation Learn ...
- A Simple Framework for Contrastive Learning of Visual Representations
目录 概 主要内容 流程 projection head g constractive loss augmentation other 代码 Chen T., Kornblith S., Norouz ...
- ICLR2021对比学习(Contrastive Learning)NLP领域论文进展梳理
本文首发于微信公众号「对白的算法屋」,来一起学AI叭 大家好,卷王们and懂王们好,我是对白. 本次我挑选了ICLR2021中NLP领域下的六篇文章进行解读,包含了文本生成.自然语言理解.预训练语言模 ...
- 论文解读(S^3-CL)《Structural and Semantic Contrastive Learning for Self-supervised Node Representation Learning》
论文信息 论文标题:Structural and Semantic Contrastive Learning for Self-supervised Node Representation Learn ...
- 论文解读(GCA)《Graph Contrastive Learning with Adaptive Augmentation》
论文信息 论文标题:Graph Contrastive Learning with Adaptive Augmentation论文作者:Yanqiao Zhu.Yichen Xu3.Feng Yu4. ...
随机推荐
- 使用Wireshark完成实验2-TCP
1.打开Google Chorme,进入https://gaia.cs.umass.edu/wireshark-labs/alice.txt 2.将文本保存,进入https://gaia.cs.uma ...
- 在linux环境下自动执行python脚本
有时候编辑的py文件,需要进行自动执行时,可以用以下方式进行定时 00 09 * * * /usr/local/bin/python3 /udata/ubi/uenbi_py/trade_all_da ...
- python机器学习——PCA降维算法
背景与原理: PCA(主成分分析)是将一个数据的特征数量减少的同时尽可能保留最多信息的方法.所谓降维,就是在说对于一个$n$维数据集,其可以看做一个$n$维空间中的点集(或者向量集),而我们要把这个向 ...
- token能放在cookie中吗
能. token一般是用来判断用户是否登录的, 它内部包含的信息有: uid(用户唯一的身份标识). time(当前时间的时间戳). sign(签名,token 的前几位以哈希算法压缩成的一定长度的十 ...
- oracle表中增加字段sql
declare v_Count1 int := 0; v_Count2 int := 0;begin select count(1) into v_Count1 from user_all_table ...
- MySQL innodb存储引擎的数据存储结构
InnoDB存储引擎的数据存储结构 B+ 树 为什么选择B+树? 因为B+树的叶子节点存储了所有的data,所以它的非叶子节点可以存储更多的key,使得树更矮:树的高度几乎就是I/O的次数,所以选择更 ...
- core程序实现文件下载
已知本地文件名,返回给前台流 string filepath = path +"/" + filename +".txt"; if(System.IO.File ...
- JS实现中英文混合文字友好截取功能
众所周知,一个汉字等于两个英文字母的长度.那么,从汉字或者英文字母中截取相同长度文字则显示的长度则不一样.此时用户体验会不好.那么怎么解决呢?往下看 <script> /** * JS实现 ...
- Linux系列---【U盘插入后,linux系统如何查看U盘中的内容?】
U盘插入后,linux系统如何查看U盘中的内容? 1.插入U盘 2.输入命令查看U盘是否插入成功 sudo fdisk -l 输入上面命令后,在最下面Device Boot一栏查看自己的U盘所在的分区 ...
- down_interruptible()获取信号量
信号量(Semaphore)是操作系统中最典型的用于同步和互斥的手段,信号量的值可以是0.1或者n.信号量与操作系统中的经典概念PV操作对应. P(S):①将信号量S的值减1,即S=S-1:②如果S≥ ...