numpy简单入门
声明:本文大量参考https://www.dataquest.io/mission/6/getting-started-with-numpy(建议阅读原文)
读取文件
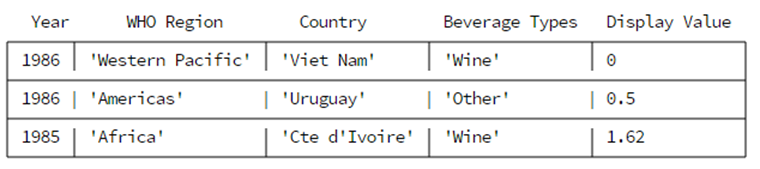
有一个名为world_alcohol.csv的文件,文件格式如下
|
Year,WHO region,Country,Beverage Types,Display Value 1986,Western Pacific,Viet Nam,Wine,0 1986,Americas,Uruguay,Other,0.5 1985,Africa,Cte d'Ivoire,Wine,1.62 |
文件内容的含义:(这是一份全球的饮料消耗记录表,第一列的意思是记录的年份,第二列指的是饮料的出产地,第三列指的是饮料的消耗地,第四列指的是饮料的类型,第五列指的是饮料的每人平均消耗量)
现在使用numpy的genfromtxt()函数来读取该文件,delimiter参数是用来指定每一行用来分隔数据的分隔符
import numpy
world_alcohol = numpy.genfromtxt('world_alcohol.csv', delimiter=',')
print(world_alcohol)
此时读取到的内容如下:
|
[[ nan nan nan nan nan] [ 1.98600000e+03 nan nan nan 0.00000000e+00] [ 1.98600000e+03 nan nan nan 5.00000000e-01] ..., [ 1.98600000e+03 nan nan nan 2.54000000e+00] [ 1.98700000e+03 nan nan nan 0.00000000e+00] [ 1.98600000e+03 nan nan nan 5.15000000e+00]] |
这是因为numpy在读取元素时,默认是按照float格式来读取的,对于不能转换为float类型的数据会读取为nan(not a number),对于留空的数据则显示为na(not available),为了正确的读取数据,可以通过增加参数:
- dtype参数用来指定读取数据的格式,这里的U75表示将每一个数据都读取为75个byte的unicode数据格式
- skip_header参数用来跳过文件的第一行
- delimiter参数用来指定每行数据的分隔符
import numpy
world_alcohol = numpy.genfromtxt('world_alcohol.csv', dtype='U75', skip_header=True, delimiter=',')
print(world_alcohol)
数组
可以通过array()函数来创建一个数组,在这里向量指的是变量只有一个列表,矩阵指的是具有多个列表的列表
创建一个向量:vector = numpy.array([10, 20, 30])
创建一个矩阵:matrix = numpy.array([[5,10,15],[20,25,30],[35,40,45]])
数组的属性:
- shape属性描述了该数组的结构
- dtype属性描述了元素的数据类型
|
print(vector.shape) 输出结果: (3,) 这是一个元组,表示vector变量是一个只有一行的向量,具有3个元素 print(matrix.shape) 输出结果: (3,3)表示matrix变量是一个3 × 3的矩阵,具有3行3列共9个元素 |
|
print(vector.shape) 输出结果: int64 |
数据类型大致有以下几种:
- bool -- 布尔类型,True或者False
- int -- 整型,分为int16, int32, int64,后面的数字表明数值的长度
- float -- 浮点型,分为float16, float32, float64,后面的数字表明数值的长度
- string -- 字符串类型,分为string或者unicode,它们的差异在于存储字符的方式
索引和分片
谨记一点:数组的索引是从0开始的
matrix = numpy.array([
[5,10,15],
[20,25,30],
[35,40,45]
])
print(matrix[1][1]) # 两种方式都可以索引数据,输出结果都是25,注意这里索引的是第二行第二个
print(matrix[1,1])
可以类似于使用切片来操作数据(将切片操作符 : 理解为‘全部’)
print(matrix[:,0]) # 输出全部行,第一列的数据 [ 5 20 35] print(matrix[0,:]) # 输出第一行,全部列的数据 [ 5 10 15] print(matrix[:,0:2]) # 输出全部行,前2列的数据[ [5, 10], [20, 25], [35, 40] ] print(matrix[1:3,:]) # 输出第2和第3行的全部列的数据 [ [20, 25, 30], [35, 40, 45] ] print(matrix[1:3,1]) # 输出第2,3行的第1列数据 [ [10], [25] ]
数组比较
将数组与一个值相比较的时候,实际上是把数组内的每个值都与该值比较,然后返回一个布尔值列表
vector = numpy.array([5, 10, 15, 20]) vector == 10 返回的是:[False, True, False, False]
对于矩阵也如此
matrix = numpy.array([
[5, 10, 15],
[20, 25, 30],
[35, 40, 45]
])
matrix == 25
结果如下:[
[False, False, False],
[False, True, False],
[False, False, False]
]
数组比较中还可以使用多条件
vector = numpy.array([5, 10, 15, 20]) equal_to_ten_and_five = (vector == 10) & (vector == 5) 输出:[False, False, False, False] equal_to_ten_or_five = (vector == 10) | (vector == 5) 输出:[True, True, False, False]
数组比较的最大用处是
一、用来选择数组或矩阵中的元素
matrix = numpy.array([
[5, 10, 15],
[20, 25, 30],
[35, 40, 45]
])
second_column_25 = (matrix[:,1] == 25)
print(matrix[second_column_25, :])
作用:提取出matrix中第二列中等于25的所有行,结果为[20, 25, 30]
二、替换元素
vector = numpy.array([5, 10, 15, 20]) equal_to_ten_or_five = (vector == 10) | (vector == 5) vector[equal_to_ten_or_five] = 50 print(vector) 输出:[50, 50, 15, 20]
原理如下:
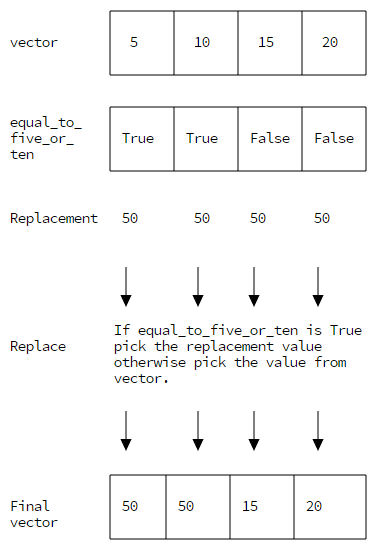
常用于替换空元素
譬如将world_alcohol中的第五列中的留空的数据都替换为字符串0:
is_value_empty = world_alcohol[:, 4] == ' ' world_alcohol[is_value_empty, 4] = '0'
数据类型转换
通过使用astype()函数来转换一个数组的数据类型
vector = numpy.array(["1", "2", "3"]) vector = vector.astype(float) print(vector) 结果:[1.0, 2.0, 3.0]
简单的运算
参考numpy的手册:http://docs.scipy.org/doc/numpy-1.10.1/index.html
挑出几个重要的运算函数:
- l sum() -- 计算一个向量中的全部元素的总和,或者是一个矩阵中的一个维度的总和
- l mean() -- 同上,计算的是平均值
- l max() -- 同上,计算的是最大值
vector = numpy.array([5, 10, 15, 20])
vector.sum() 结果为:50 matrix = numpy.array([ [5, 10, 15], [20, 25, 30], [35, 40, 45] ]) matrix.sum(axis=1) 结果:[30, 75, 120] 对于矩阵来说,需要指定axis参数,该参数等于1时表示计算的是每行,等于0时表示计算的是每列的总和
练习
使用world_alcohol.csv文件,计算在1986年里每个国家的饮料消耗量
import numpy
world_alcohol = numpy.genfromtxt('world_alcohol.csv', dtype='U75', skip_header=True, delimiter=',')
totals = {}
year = world_alcohol[world_alcohol[:, 0] == '1989', :] # 选择1989年的数据集
countries = set(world_alcohol[:,2]) # 选择全部国家
for each in countries: # 分别计算每个国家
consumption = year[year[:,2] == each, :]
consumption[consumption[:, 4] == '',4] = '0'
temp = consumption[:,4].astype(float) # 将留空的数据转变为浮点数0参与运算
country_consumption = temp.sum()
totals[each] = country_consumption
总结
使用numpy的比直接对一个列表集合的运算更加方便,主要优于以下几点:
- 更容易对数据进行计算
- 可以快速地进行数据索引和分片
- 可以快速地转换数据类型
然而,numpy有一些不足之处:
- 在同一个数据集中的数据必须具有相同的数据类型,在处理多数据集时会变得很困难
- 行和列都需要使用数字来索引,而不能使用别名,这样容易造成混淆
而Pandas解决了Numpy的几点不足
numpy简单入门的更多相关文章
- NumPy简单入门教程
# NumPy简单入门教程 NumPy是Python中的一个运算速度非常快的一个数学库,它非常重视数组.它允许你在Python中进行向量和矩阵计算,并且由于许多底层函数实际上是用C编写的,因此你可以体 ...
- 初学Python之爬虫的简单入门
初学Python之爬虫的简单入门 一.什么是爬虫? 1.简单介绍爬虫 爬虫的全称为网络爬虫,简称爬虫,别名有网络机器人,网络蜘蛛等等. 网络爬虫是一种自动获取网页内容的程序,为搜索引擎提供了重要的 ...
- 用IntelliJ IDEA创建Gradle项目简单入门
Gradle和Maven一样,是Java用得最多的构建工具之一,在Maven之前,解决jar包引用的问题真是令人抓狂,有了Maven后日子就好过起来了,而现在又有了Gradle,Maven有的功能它都 ...
- [原创]MYSQL的简单入门
MYSQL简单入门: 查询库名称:show databases; information_schema mysql test 2:创建库 create database 库名 DEFAULT CHAR ...
- Okio 1.9简单入门
Okio 1.9简单入门 Okio库是由square公司开发的,补充了java.io和java.nio的不足,更加方便,快速的访问.存储和处理你的数据.而OkHttp的底层也使用该库作为支持. 该库极 ...
- emacs最简单入门,只要10分钟
macs最简单入门,只要10分钟 windwiny @2013 无聊的时候又看到鼓吹emacs的文章,以前也有几次想尝试,结果都是玩不到10分钟就退出删除了. 这次硬着头皮,打开几篇文章都看完 ...
- 【java开发系列】—— spring简单入门示例
1 JDK安装 2 Struts2简单入门示例 前言 作为入门级的记录帖,没有过多的技术含量,简单的搭建配置框架而已.这次讲到spring,这个应该是SSH中的重量级框架,它主要包含两个内容:控制反转 ...
- Docker 简单入门
Docker 简单入门 http://blog.csdn.net/samxx8/article/details/38946737
- Springmvc整合tiles框架简单入门示例(maven)
Springmvc整合tiles框架简单入门示例(maven) 本教程基于Springmvc,spring mvc和maven怎么弄就不具体说了,这边就只简单说tiles框架的整合. 先贴上源码(免积 ...
随机推荐
- 错误与修复:ASP.NET无法检测IE10,导致_doPostBack未定义JavaScript错误,恒处于FF5卷动条位置
浏览器版本号继续升级过程中.IE9诞生了,IE10 也即将问世,火狐5和6已经发布了,而7和8也快出现了,Opera已经到了11,Chrome还在继续,我也不知道,应该总在14和50之间吧.不管怎样, ...
- python(4) - 装饰器
由于函数也是一个对象,既然是对象就可以将它赋给变量,通过变量来调用该函数 def now(): print('2016-01-01') f = now #注意,这里不能带(),函数带上()表示执行函数 ...
- Mac OS X 配置 Apache+Mysql+PHP 详细教程
网上的教程已经有很多,这里简洁的记录一下.以 Mac OS X Mavericks 10.9.X 为例. 先附上如何进入指定目录文件夹,按键盘 Command + Shift + G ,然后输入指定目 ...
- 神奇的CSS3选择器
话说园子里也混迹多年了,但是基本没写过blog,写点基础的,那就从css3选择器开始吧. Css3选择器 先说下,为什么提倡使用选择器. 使用选择器可以将样式与元素直接绑定起来,在样式表中什么样式与什 ...
- Java对Excel表格的操作
import java.io.File;//引入类import java.io.IOException;import java.util.Scanner;import jxl.Cell;import ...
- 如何更好的理解(pageX,pageY,clientX,clientY,eventX,eventY,scrollX,scrollY,screenX,screenY,event.offsetX,event.offsetY,offsetLeft,style.left)
1 pageX,pageY:鼠标指针相对于当前窗口的X,Y坐标,计算区域包括窗口自身的控件和滚动条.(火狐特有) 2 event.clientX,event.clientY:鼠标指针相对于当前窗口的X ...
- Crontab使用mailx的一点发现
要用到Crontab定时任务去执行一个Shell脚本监控Linux系统资源并且当一些数字超过预设的话发送邮件警告.首先是linux的sendmail功能无法满足我们使用SMTP服务器并且指定发送者(E ...
- PHP学习笔记--入门篇
PHP学习笔记--入门篇 一.Echo语句 1.格式 echo是PHP中的输出语句,可以把字符串输出(字符串用双引号括起来) 如下代码 <?php echo "Hello world! ...
- JavaScript学习笔记(11)——HTML DOM Event对象
w3cshool:时间参考手册:http://www.w3school.com.cn/jsref/dom_obj_event.asp
- java新手笔记34 连接数据库
1.JdbcUtil package com.yfs.javase.jdbc; import java.sql.Connection; import java.sql.DriverManager; i ...