组合方法(ensemble method) 与adaboost提升方法
组合方法:
我们分类中用到非常多经典分类算法如:SVM、logistic 等,我们非常自然的想到一个方法。我们是否可以整合多个算法优势到解决某一个特定分类问题中去,答案是肯定的!
通过聚合多个分类器的预測来提高分类的准确率。这样的技术称为组合方法(ensemble method) 。组合方法由训练数据构建一组基分类器,然后通过对每一个基分类器的预測进行权重控制来进行分类。
考虑25个二元分类组合,每一个分类误差是0.35 。假设全部基分类器都是相互独立的(即误差是不相关的),则在超过一半的基分类器预測错误组合分类器才会作出错误预測。这样的情况下的组合分类器的误差率:

下图对角线表示全部基分类器都是等同的情况,实线是基分类器独立时情况。

组合分类器性能优于单个分类器必须满足两个条件:(1)基分类器之间是相互独立的 (2) 基分类器应当好于随机推測分类器。实践上非常难保证基分类器之间全然独立。可是在基分类器轻微相关情况下。组合方法能够提高分类的准确率。
组合方法分为两类:(from http://scikit-learn.org/stable/modules/ensemble.html)
Two families of ensemble methods are usually distinguished:
In averaging methods, the driving principle is to build several estimators independently and then to average their predictions. On average, the combined estimator is usually better than any of the single base estimator because its variance
is reduced.Examples: Bagging
methods, Forests of randomized trees,
...By contrast, in boosting methods, base estimators are built sequentially and one tries to reduce the bias of the combined estimator. The motivation is to combine several weak models to produce a powerful ensemble.
Examples: AdaBoost, Gradient
Tree Boosting, ...
以下主要说说Adaboost算法。
先介绍强可学习与弱可学习,假设存在一个多项式的学习算法可以学习它而且正确率非常高,那么就称为强可学习,相反弱可学习就是学习的正确率仅比随机推測稍好。
提升方法有两个问题:1. 每一轮怎样改变训练数据的权重或概率分布 2. 怎样将弱分类器整合为强分类器。
非常朴素的思想解决提升方法中的两个问题:第1个问题-- 提高被前一轮弱分类器错误分类的权值,而减少那些被正确分类样本权值 ,这样导致结果就是 那些没有得到正确分类的数据,因为权值加重受到后一轮弱分类器的更大关注。 第2个问题 adaboost 採取加权多数表决方法,加大分类误差率小的弱分类器的权值,使其在表决中起到较大的作用,相反较小误差率的弱分类的权值,使其在表决中较小的作用。
详细说来,整个Adaboost 迭代算法就3步:
- 初始化训练数据的权值分布。
假设有N个样本,则每个训练样本最開始时都被赋予同样的权重:1/N。
- 训练弱分类器。
详细训练过程中,假设某个样本点已经被准确地分类,那么在构造下一个训练集中,它的权重就被减少;相反,假设某个样本点没有被准确地分类,那么它的权重就得到提高。然后,权重更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
- 将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在终于的分类函数中起着较大的决定作用,而减少分类误差率大的弱分类器的权重,使其在终于的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在终于分类器中占的权重较大,否则较小。
Adaboost算法流程
给定一个训练数据集T={(x1,y1), (x2,y2)…(xN,yN)},当中实例 ,而实例空间
,而实例空间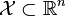 ,yi属于标记集合{-1,+1}。Adaboost的目的就是从训练数据中学习一系列弱分类器或基本分类器。然后将这些弱分类器组合成一个强分类器。
,yi属于标记集合{-1,+1}。Adaboost的目的就是从训练数据中学习一系列弱分类器或基本分类器。然后将这些弱分类器组合成一个强分类器。
Adaboost的算法流程例如以下:
- 步骤1. 首先,初始化训练数据的权值分布。
每个训练样本最開始时都被赋予同样的权重:1/N。

- 步骤2. 进行多轮迭代,用m = 1,2, ..., M表示迭代的第多少轮
a. 使用具有权值分布Dm的训练数据集学习。得到基本分类器:

b. 计算Gm(x)在训练数据集上的分类误差率
由上述式子可知。Gm(x)在训练数据集上的误差率em就是被Gm(x)误分类样本的权值之和。

由上述式子可知。em <= 1/2时。am >= 0,且am随着em的减小而增大。意味着分类误差率越小的基本分类器在终于分类器中的作用越大。

d.
更新训练数据集的权值分布(目的:得到样本的新的权值分布),用于下一轮迭代

使得被基本分类器Gm(x)误分类样本的权值增大,而被正确分类样本的权值减小。
就这样,通过这种方式,AdaBoost方法能“聚焦于”那些较难分的样本上。
当中。Zm是规范化因子。使得Dm+1成为一个概率分布:

- 步骤3. 组合各个弱分类器

从而得到终于分类器,例如以下:

在《统计学习方法》p140页有一个实际计算的样例能够自己计算熟悉算法过程。
Adaboost的误差界
通过上面的样例可知。Adaboost在学习的过程中不断降低训练误差e,直到各个弱分类器组合成终于分类器,那这个终于分类器的误差界究竟是多少呢
其实,Adaboost 终于分类器的训练误差的上界为:

以下,咱们来通过推导来证明下上述式子。
当G(xi)≠yi时,yi*f(xi)<0。因而exp(-yi*f(xi))≥1。因此前半部分得证。
关于后半部分。别忘了:

整个的推导步骤例如以下:

这个结果说明。能够在每一轮选取适当的Gm使得Zm最小,从而使训练误差下降最快。
接着。咱们来继续求上述结果的上界。
对于二分类而言,有例如以下结果:

当中。
继续证明下这个结论。
由之前Zm的定义式跟本节最開始得到的结论可知:

而这个不等式
值得一提的是,假设取γ1, γ2… 的最小值,记做γ(显然,γ≥γi>0,i=1,2,...m)。则对于全部m,有:

这个结论表明。AdaBoost的训练误差是以指数速率下降的。另外。AdaBoost算法不须要事先知道下界γ,AdaBoost具有自适应性。它能适应弱分类器各自的训练误差率 。在统计学习方法第八章 中有关于这部分比較具体的讲述能够參考!
!
在一个简单数据集上的adaboost 的实现(来自机器学习实战)
from numpy import*
def loadSimpData():
datMat = matrix([[ 1. , 2.1],
[ 2. , 1.1],
[ 1.3, 1. ],
[ 1. , 1. ],
[ 2. , 1. ]])
classLabels = [1.0, 1.0, -1.0, -1.0, 1.0]
return datMat,classLabels def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):
retArray = ones((shape(dataMatrix)[0],1))
if threshIneq =='lt':
retArray[dataMatrix[:,dimen]<= threshVal] = -1.0
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0
return retArray def buildStump(dataArr,classLabels,D):
dataMatrix = mat(dataArr)
labelMat = mat(classLabels).T
m,n = shape(dataMatrix)
numSteps = 10.0 ; bestStump = {} ; bestClasEst = mat(zeros((m,1)))
minError = inf
for i in range(n):
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max()
stepSize = (rangeMax- rangeMin)/numSteps
for j in range(-1,int(numSteps)+1):
for inequal in ['lt','gt']:
threshVal = (rangeMin + float(j)* stepSize)
predictedVals = stumpClassify(dataMatrix, i, threshVal, inequal)
errArr = mat(ones((m,1)))
errArr[predictedVals == labelMat]=0
weightedError = D.T *errArr
# print "split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError)
if weightedError < minError:
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump,minError,bestClasEst def adaBoostTrainDS(dataArr,classLabels,numIt=40):
weakClassArr = []
m = shape(dataArr)[0]
D = mat(ones((m,1))/m) #init D to all equal
aggClassEst = mat(zeros((m,1)))
for i in range(numIt):
bestStump,error,classEst = buildStump(dataArr,classLabels,D)#build Stump
print "D:",D.T
alpha = float(0.5*log((1.0-error)/max(error,1e-16)))#calc alpha, throw in max(error,eps) to account for error=0
bestStump['alpha'] = alpha
weakClassArr.append(bestStump) #store Stump Params in Array
print "classEst: ",classEst.T
expon = multiply(-1*alpha*mat(classLabels).T,classEst) #exponent for D calc, getting messy
D = multiply(D,exp(expon)) #Calc New D for next iteration
D = D/D.sum()
#calc training error of all classifiers, if this is 0 quit for loop early (use break)
aggClassEst += alpha*classEst
print "aggClassEst: ",aggClassEst.T
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1)))
errorRate = aggErrors.sum()/m
print "total error: ",errorRate
if errorRate == 0.0: break
return weakClassArr,aggClassEst if __name__ == "__main__":
D = mat(ones((5,1))/5)
datMat,classLabels = loadSimpData()
buildStump(datMat, classLabels, D)
adaBoostTrainDS(datMat, classLabels, 10)
输出结果:
D: [[ 0.2 0.2 0.2 0.2 0.2]]
classEst: [[-1. 1. -1. -1. 1.]]
aggClassEst: [[-0.69314718 0.69314718 -0.69314718 -0.69314718 0.69314718]]
total error: 0.2
D: [[ 0.5 0.125 0.125 0.125 0.125]]
classEst: [[ 1. 1. -1. -1. -1.]]
aggClassEst: [[ 0.27980789 1.66610226 -1.66610226 -1.66610226 -0.27980789]]
total error: 0.2
D: [[ 0.28571429 0.07142857 0.07142857 0.07142857 0.5 ]]
classEst: [[ 1. 1. 1. 1. 1.]]
aggClassEst: [[ 1.17568763 2.56198199 -0.77022252 -0.77022252 0.61607184]]
total error: 0.0
參考:统计学习方法、机器学习实战、http://blog.csdn.net/v_july_v/article/details/40718799
组合方法(ensemble method) 与adaboost提升方法的更多相关文章
- 统计学习方法c++实现之七 提升方法--AdaBoost
提升方法--AdaBoost 前言 AdaBoost是最经典的提升方法,所谓的提升方法就是一系列弱分类器(分类效果只比随机预测好一点)经过组合提升最后的预测效果.而AdaBoost提升方法是在每次训练 ...
- 【机器学习实战】第7章 集成方法 ensemble method
第7章 集成方法 ensemble method 集成方法: ensemble method(元算法: meta algorithm) 概述 概念:是对其他算法进行组合的一种形式. 通俗来说: 当做重 ...
- Boosting(提升方法)之AdaBoost
集成学习(ensemble learning)通过构建并结合多个个体学习器来完成学习任务,也被称为基于委员会的学习. 集成学习构建多个个体学习器时分两种情况:一种情况是所有的个体学习器都是同一种类型的 ...
- 机器学习理论提升方法AdaBoost算法第一卷
AdaBoost算法内容来自<统计学习与方法>李航,<机器学习>周志华,以及<机器学习实战>Peter HarringTon,相互学习,不足之处请大家多多指教! 提 ...
- 提升方法-AdaBoost
提升方法通过改变训练样本的权重,学习多个分类器(弱分类器/基分类器)并将这些分类器进行线性组合,提高分类的性能. AdaBoost算法的特点是不改变所给的训练数据,而不断改变训练数据权值的分布,使得训 ...
- 机器学习——提升方法AdaBoost算法,推导过程
0提升的基本方法 对于分类的问题,给定一个训练样本集,求比较粗糙的分类规则(弱分类器)要比求精确的分类的分类规则(强分类器)容易的多.提升的方法就是从弱分类器算法出发,反复学习,得到一系列弱分类器(又 ...
- Adaboost提升算法从原理到实践
1.基本思想: 综合某些专家的判断,往往要比一个专家单独的判断要好.在"强可学习"和"弱科学习"的概念上来说就是我们通过对多个弱可学习的算法进行"组合 ...
- Ensemble Learning 之 Adaboost
Boosting Boosting 是一种提升方法,将一系列弱学习器组合成为强学习器.基于样本权重的 Boosting 的工作流程是这样的,给定初始训练集构建一个基学习器,根据基学习器对训练样本的分布 ...
- Boosting(提升方法)之GBDT
一.GBDT的通俗理解 提升方法采用的是加法模型和前向分步算法来解决分类和回归问题,而以决策树作为基函数的提升方法称为提升树(boosting tree).GBDT(Gradient Boosting ...
随机推荐
- codeforces 340B Maximal Area Quadrilateral(叉积)
事实再一次证明:本小菜在计算几何上就是个渣= = 题意:平面上n个点(n<=300),问任意四个点组成的四边形(保证四条边不相交)的最大面积是多少. 分析: 1.第一思路是枚举四个点,以O(n4 ...
- 《C++ primer》--第1,2章小结
来源:http://blog.csdn.net/wangqiulin123456/article/details/8483853 1.变量初始化: 定义变量时,应该给变量赋初始值,除非确定将 ...
- Windows Server 2012 R2 设置 smtp 服务器
Windows Server 2012/2012 R2:安装和配置 SMTP 服务器 安装 SMTP 服务器 以下是安装 SMTP 服务器功能的步骤: 打开“服务器管理器”:单击键盘上的 Window ...
- java --- 设计模式 --- 动态代理
Java设计模式——动态代理 java提供了动态代理的对象,本文主要探究它的实现, 动态代理是AOP(面向切面编程, Aspect Oriented Programming)的基础实现方式, 动态代理 ...
- 关于python中的__new__方法
在上篇中,简单的比较了下new方法和init方法,然后结合网上的东西看了一点,发现..看书有的时候说的并不全面. __new__方法是一个类方法,主要作用是来指导如何生成类的实例, 主要用于,当需要生 ...
- Using NuGet without committing packages to source control(在没有把包包提交到代码管理器的情况下使用NuGet进行还原 )
外国老用的语言就是谨慎,连场景都限定好了,其实我们经常下载到有用NuGet引用包包然而却没法编译的情况,上谷歌百度搜又没法使用准确的关键字,最多能用到的就是nuget跟packages.config, ...
- 有趣的库:pipe(类似linux | 管道)库
pipe并不是Python内置的库,如果你安装了easy_install,直接可以安装它,否则你需要自己下载它:http://pypi.python.org/pypi/pipe 之所以要介绍这个库,是 ...
- 使用arm开发板搭建无线mesh网络(一)
由于项目的需要,老板让我使用arm开发板(友善之臂的tiny6410)搭建无线mesh网络.一般而言,无线自组织网络的网络设备都是由用户的终端设备来充当,这些终端设备既要处理用户的应用数据,比如娱乐, ...
- Apache Spark是什么?
简单地说, Spark是发源于美国加州大学伯克利分校AMPLab的大数据分析平台,它立足于内存计算,从多迭代批量处理出发,兼顾数据仓库. 流处理和图计算等多种计算范式,是大数据系统领域的全栈计算平台. ...
- Linux下的paste合并命令详解
paste单词意思是粘贴.该命令主要用来将多个文件的内容合并,与cut命令完成的功能刚好相反. 粘贴两个不同来源的数据时,首先需将其分类,并确保两个文件行数相同.paste将按行将不同文件行信息放在一 ...