安装Hadoop系列 — 新建MapReduce项目
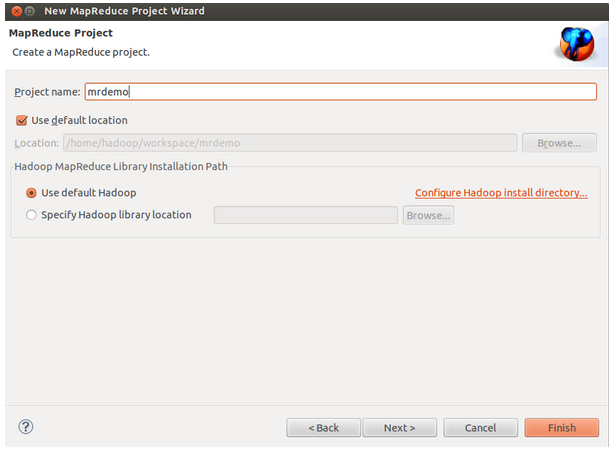
1、新建MR工程

依次点击 File → New → Ohter… 选择Mapper,自动继承Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>



package com.mrdemo; import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
//conf.set("fs.defaultFS", "hdfs://192.168.6.77:9000");
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
hello hadoop
jobtracker
maptracker
reducetracker
task
namenode
datanode
block
beautiful world
hadoop:
HDFS
MapReduce
hdfs://localhost:9000/user/yyq/output01
Run As → Run Configurations… ,在Arguments中配置运行参数,例如程序的输入参数:

Run As -> Run on Hadoop ,执行完成后可以看到如下信息:
安装Hadoop系列 — 新建MapReduce项目的更多相关文章
- hadoop系列三:mapreduce的使用(一)
转载请在页首明显处注明作者与出处 http://www.cnblogs.com/zhuxiaojie/p/7224772.html 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的 ...
- hadoop系列四:mapreduce的使用(二)
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- 安装Hadoop系列 — 导入Hadoop源码项目
将Hadoop源码导入Eclipse有个最大好处就是通过 "ctrl + shift + r" 可以快速打开Hadoop源码文件. 第一步:在Eclipse新建一个Java项目,h ...
- 安装Hadoop系列 — 安装Hadoop
安装步骤如下: 1)下载hadoop:hadoop-1.0.3 http://archive.apache.org/dist/hadoop/core/hadoop-1.0.3/ 2)解压文 ...
- 安装Hadoop系列 — 安装JDK-8u5
安装步骤如下: 1)下载 JDK 8 从http://www.oracle.com/technetwork/java/javasebusiness/downloads/ 选择下载JDK的最新版本 JD ...
- 安装Hadoop系列 — eclipse plugin插件编译安装配置
[一].环境参数 eclipse-java-kepler-SR2-linux-gtk-x86_64.tar.gz //现在改为eclipse-jee-kepler-SR2-linux-gtk-x86_ ...
- 新建MapReduce项目
添加各种jar包 /usr/local/hadoop/share/hadoop/.. 这几个文件夹下的jar包以及它们子目录lib下的所有jar包 将/usr/local/hadoop/etc/had ...
- 安装Hadoop系列 — 安装Eclipse
1.下载 Eclipse从 http://www.eclipse.org/downloads/index-developer.php下载合适版本,如:Eclipse IDE for C/C++ Dev ...
- 安装Hadoop系列 — 安装SSH免密码登录
配置ssh免密码登录 1) 验证是否安装ssh:ssh -version显示如下的话则成功安装了OpenSSH_6.2p2 Ubuntu-6ubuntu0.1, OpenSSL 1.0.1e 11 ...
随机推荐
- COM原理
1, 进程内组件:服务程序杯加载到客户的进程空间,通常是DLL的形式.本地组件:服务程序与与客户程序在同一台电脑上,通常是EXE.远程组件: 服务程序与与客户程序在不同的电脑上,可以是DLL模块也可是 ...
- 【Linux】rsync同步文件 & 程序自启动
rsync使用 1. 为什么使用rsync? rsync解决linux系统下文件同步时, 增量同步问题. 使用场景: 线上需要定时备份数据文件(视频资源), 使用rsync完成每天的增量备份. 参见: ...
- GC日志补充
根据日志,确实发生了FullGC,计算资源被耗光 Java HotSpot(TM) 64-Bit Server VM (24.79-b02) for windows-amd64 JRE (1.7.0_ ...
- WinForm窗体间如何传值的几种方法
(转) 窗体间传递数据,无论是父窗体操作子窗体,还是子窗体操作符窗体,有以下几种方式: 公共静态变量: 使用共有属性: 使用委托与事件: 通过构造函数把主窗体传递到从窗体中: 一.通过静态变量 特点: ...
- Spring MVC - log4j 配置
http://blog.csdn.net/yhqbsand/article/details/8764388
- php安装libevent
libevent扩展安装 libevent-2.0.16-stable.tar http://libevent.org/ [plain] view plaincopy cd libevent-2.0. ...
- angularJs--$apply和$watch,$digest方法的意思
这个视图对应的控制器是 这样的话,这个date变量,是不会发生改变的,没有触发脏检查,所以这时候要$apply方法,所有自定义的方法都要用$apply来触发脏检查 这样那个日期就会变化了 $diges ...
- css中overflow:hidden的属性 可能会导致js下拉菜单无法显示
css中overflow:hidden属性导致ExtJS中无法显示下拉滚动条 overflow属性: visible 默认.内容不会被修剪,会呈现在元素之外. hidden 内容会被修剪,但是浏览器不 ...
- Python-Day1 Python基础学习
一.Python3.5.X安装 1.Windows Windows上找度娘搜索“Python for windows下载”就OK了,安装的时候可以勾选设置环境变量,也可以安装完手动设置,这样在cmd中 ...
- linux学习笔记(1)-文件处理相关命令
列出文件和目录 ls (list) #ls 在终端里键入ls,并回车,就会列出当前目录的文件和目录,但是不包括隐藏文件和目录 #ls -a 列出当前目录的所有文件 #ls -al 列出当前目的所有文件 ...