MySQL Error 1215: Cannot add foreign key constraint
调度器 堆 优先级队列
堆和栈的理解和区别,C语言堆和栈完全攻略 http://c.biancheng.net/c/stack/
数据结构的堆和栈
在数据结构中,栈是一种可以实现“先进后出”(或者称为“后进先出”)的存储结构。假设给定栈 S=(a0,a1,…,an-1),则称 a0 为栈底,an-1 为栈顶。进栈则按照 a0,a1,…,an-1 的顺序进行进栈;而出栈的顺序则需要反过来,按照“后存放的先取,先存放的后取”的原则进行,则 an-1 先退出栈,然后 an-2 才能够退出,最后再退出 a0。
在实际编程中,可以通过两种方式来实现:使用数组的形式来实现栈,这种栈也称为静态栈;使用链表的形式来实现栈,这种栈也称为动态栈。
相对于栈的“先进后出”特性,堆则是一种经过排序的树形数据结构,常用来实现优先队列等。假设有一个集合 K={k0,k1,…,kn-1},把它的所有元素按完全二叉树的顺序存放在一个数组中,并且满足:
Python - DS Introduction - Tutorialspoint https://www.tutorialspoint.com/python_data_structure/python_data_structure_introduction.htm
Liner Data Structures
These are the data structures which store the data elements in a sequential manner.
- Array: It is a sequential arrangement of data elements paired with the index of the data element.
- Linked List: Each data element contains a link to another element along with the data present in it.
- Stack: It is a data structure which follows only to specific order of operation. LIFO(last in First Out) or FILO(First in Last Out).
- Queue: It is similar to Stack but the order of operation is only FIFO(First In First Out).
- Matrix: It is two dimensional data structure in which the data element is referred by a pair of indices.
Non-Liner Data Structures
These are the data structures in which there is no sequential linking of data elements. Any pair or group of data elements can be linked to each other and can be accessed without a strict sequence.
- Binary Tree: It is a data structure where each data element can be connected to maximum two other data elements and it starts with a root node.
- Heap: It is a special case of Tree data structure where the data in the parent node is either strictly greater than/ equal to the child nodes or strictly less than it’s child nodes.
- Hash Table: It is a data structure which is made of arrays associated with each other using a hash function. It retrieves values using keys rather than index from a data element.
- Graph: .It is an arrangement of vertices and nodes where some of the nodes are connected to each other through links.
栈 stack是线性的数据结构
堆 heap是非线性的数据结构
完全二叉树
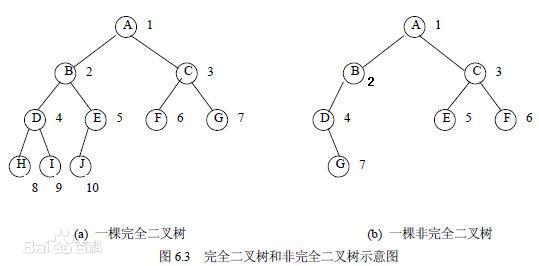
https://baike.baidu.com/item/完全二叉树/7773232
- 中文名
- 完全二叉树
- 外文名
- Complete Binary Tree
- 实 质
- 效率很高的数据结构
- 特 点
- 叶子结点只可能在最大的两层出现
- 性 质
- 度为1的点只有1个或0个
- 应用学科
- 计算机科学
算法思路
2>如果树不为空:层序遍历二叉树
2.1>如果一个结点左右孩子都不为空,则pop该节点,将其左右孩子入队列;
2.1>如果遇到一个结点,左孩子为空,右孩子不为空,则该树一定不是完全二叉树;
2.2>如果遇到一个结点,左孩子不为空,右孩子为空;或者左右孩子都为空;则该节点之后的队列中的结点都为叶子节点;该树才是完全二叉树,否则就不是完全二叉树;
class Stack:
def __init__(self):
self.stack = [] def add(self, dataval):
if dataval not in self.stack:
self.stack.append(dataval)
return True
else:
return False def peek(self):
return self.stack[-1] def remove(self):
if len(self.stack) <= 0:
return 'No element in the Stack'
else:
return self.stack.pop() AStack = Stack()
AStack.add('Mon')
AStack.peek()
print(AStack.peek())
AStack.add('Wed')
AStack.add('Thu')
print(AStack.peek())
AStack.remove() Python - Stack - Tutorialspoint https://www.tutorialspoint.com/python_data_structure/python_stack.htm
Python - Heaps - Tutorialspoint https://www.tutorialspoint.com/python_data_structure/python_heaps.htm
大顶堆 小顶堆
二元竞标赛(binary tournament)
"""Heap queue algorithm (a.k.a. priority queue). Heaps are arrays for which a[k] <= a[2*k+1] and a[k] <= a[2*k+2] for
all k, counting elements from 0. For the sake of comparison,
non-existing elements are considered to be infinite. The interesting
property of a heap is that a[0] is always its smallest element. Usage: heap = [] # creates an empty heap
heappush(heap, item) # pushes a new item on the heap
item = heappop(heap) # pops the smallest item from the heap
item = heap[0] # smallest item on the heap without popping it
heapify(x) # transforms list into a heap, in-place, in linear time
item = heapreplace(heap, item) # pops and returns smallest item, and adds
# new item; the heap size is unchanged Our API differs from textbook heap algorithms as follows: - We use 0-based indexing. This makes the relationship between the
index for a node and the indexes for its children slightly less
obvious, but is more suitable since Python uses 0-based indexing. - Our heappop() method returns the smallest item, not the largest. These two make it possible to view the heap as a regular Python list
without surprises: heap[0] is the smallest item, and heap.sort()
maintains the heap invariant!
""" # Original code by Kevin O'Connor, augmented by Tim Peters and Raymond Hettinger __about__ = """Heap queues [explanation by François Pinard] Heaps are arrays for which a[k] <= a[2*k+1] and a[k] <= a[2*k+2] for
all k, counting elements from 0. For the sake of comparison,
non-existing elements are considered to be infinite. The interesting
property of a heap is that a[0] is always its smallest element. The strange invariant above is meant to be an efficient memory
representation for a tournament. The numbers below are `k', not a[k]: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 In the tree above, each cell `k' is topping `2*k+1' and `2*k+2'. In
a usual binary tournament we see in sports, each cell is the winner
over the two cells it tops, and we can trace the winner down the tree
to see all opponents s/he had. However, in many computer applications
of such tournaments, we do not need to trace the history of a winner.
To be more memory efficient, when a winner is promoted, we try to
replace it by something else at a lower level, and the rule becomes
that a cell and the two cells it tops contain three different items,
but the top cell "wins" over the two topped cells. If this heap invariant is protected at all time, index 0 is clearly
the overall winner. The simplest algorithmic way to remove it and
find the "next" winner is to move some loser (let's say cell 30 in the
diagram above) into the 0 position, and then percolate this new 0 down
the tree, exchanging values, until the invariant is re-established.
This is clearly logarithmic on the total number of items in the tree.
By iterating over all items, you get an O(n ln n) sort. A nice feature of this sort is that you can efficiently insert new
items while the sort is going on, provided that the inserted items are
not "better" than the last 0'th element you extracted. This is
especially useful in simulation contexts, where the tree holds all
incoming events, and the "win" condition means the smallest scheduled
time. When an event schedule other events for execution, they are
scheduled into the future, so they can easily go into the heap. So, a
heap is a good structure for implementing schedulers (this is what I
used for my MIDI sequencer :-). Various structures for implementing schedulers have been extensively
studied, and heaps are good for this, as they are reasonably speedy,
the speed is almost constant, and the worst case is not much different
than the average case. However, there are other representations which
are more efficient overall, yet the worst cases might be terrible. Heaps are also very useful in big disk sorts. You most probably all
know that a big sort implies producing "runs" (which are pre-sorted
sequences, which size is usually related to the amount of CPU memory),
followed by a merging passes for these runs, which merging is often
very cleverly organised[1]. It is very important that the initial
sort produces the longest runs possible. Tournaments are a good way
to that. If, using all the memory available to hold a tournament, you
replace and percolate items that happen to fit the current run, you'll
produce runs which are twice the size of the memory for random input,
and much better for input fuzzily ordered. Moreover, if you output the 0'th item on disk and get an input which
may not fit in the current tournament (because the value "wins" over
the last output value), it cannot fit in the heap, so the size of the
heap decreases. The freed memory could be cleverly reused immediately
for progressively building a second heap, which grows at exactly the
same rate the first heap is melting. When the first heap completely
vanishes, you switch heaps and start a new run. Clever and quite
effective! In a word, heaps are useful memory structures to know. I use them in
a few applications, and I think it is good to keep a `heap' module
around. :-) --------------------
[1] The disk balancing algorithms which are current, nowadays, are
more annoying than clever, and this is a consequence of the seeking
capabilities of the disks. On devices which cannot seek, like big
tape drives, the story was quite different, and one had to be very
clever to ensure (far in advance) that each tape movement will be the
most effective possible (that is, will best participate at
"progressing" the merge). Some tapes were even able to read
backwards, and this was also used to avoid the rewinding time.
Believe me, real good tape sorts were quite spectacular to watch!
From all times, sorting has always been a Great Art! :-)
""" 数据结构与算法(4)——优先队列和堆 - 我没有三颗心脏 - 博客园 https://www.cnblogs.com/wmyskxz/p/9301021.html
https://baike.baidu.com/item/优先队列/9354754?fr=aladdin
- 中文名
- 优先队列
- 外文名
- priority queue
- 特 点
- 元素被赋予优先级
- 类 型
- 数据结构
- 定 义
- 一种先进先出的数据结构,元素在队列尾追加,而从队列头删除
- 实现方式
- 通常采用堆数据结构
优先队列的应用
- 数据压缩:赫夫曼编码算法;
- 最短路径算法:Dijkstra算法;
- 最小生成树算法:Prim算法;
- 事件驱动仿真:顾客排队算法;
- 选择问题:查找第k个最小元素;
- 等等等等....
heapq — Heap queue algorithm — Python 3.8.2 documentation https://docs.python.org/3.8/library/heapq.html
This module provides an implementation of the heap queue algorithm, also known as the priority queue algorithm.
堆队列 优先级队列
MySQL Error 1215: Cannot add foreign key constraint的更多相关文章
- Laravel 5.5 迁移报错:General error: 1215 Cannot add foreign key constraint
问题 之前一直用的 Laravel 5.4,数据库也是直接写 sql 的,感觉可定制性更强,顺便锻炼下 sql.这次改用了 Laravel 5.5,索性用迁移建库试试,结果报错如下: SQLSTATE ...
- 异常处理:1215 - Cannot add foreign key constraint
最近在做新生入学系统,学生表中包括新生的班级,专业等信息,班级,专业就需要和班级表,专业表进行关联,但是在添加外键的过程中却出现了“Cannot add foreign key constraint” ...
- mysql--sqlalchemy.exc.IntegrityError: (IntegrityError) (1215, 'Cannot add foreign key constraint'
今天在使用mysql时遇到的问题,最后发现问题是,数据类型与外键数据类型不同,改正过来就没有问题了.
- 数据库建表的时候报 “1215 Cannot add foreign key constraint”
很大原因是因为: 引用表中的字段类型和被引用的主键的类型不统一. 比如说学生表中有一个班级ID字段引用班级表. 班级表的ID是int类型,学生表中的班级ID是Varchar类型. 肯定会提示上述121 ...
- MySQL添加外键时报错 ERROR 1215 (HY000): Cannot add foreign key constraint
1.数据类型 2.数据表的引擎 数据表 mysql> show tables; +------------------+ | Tables_in_market | +--------- ...
- mysql执行带外键的sql文件时出现mysql ERROR 1215 (HY000): Cannot add foreign key constraint的解决
ERROR 1215 (HY000): Cannot add foreign key constraint 最近在建表时遇到了这个错误,然后找了下找到了解决办法,记录下: 本来是要建两张表: 1 2 ...
- Navicat MYSQL 建立关联表 保存时遇到 cannot add foreign key constraint
首先建立user表,如下图 然后建立message表,userid用作外键,关联user表的id 点击上面的外键按钮,添加外键如下 结果保存时报错: cannot add foreign key co ...
- Cannot add foreign key constraint @ManyToMany @OneToMany
最近在使用shiro做权限管理模块时,使用的时user(用户)-role(角色)-resource(资源)模式,其中user-role 是多对多,role-resource 也是多对多.但是在使用sp ...
- ERROR 1215 (HY000): Cannot add foreign key constraint
MySQL中在为一个varchar类型数据列添加外键时,会发生上面所示的错误,这里我google了一下,感觉它们碰到的问题跟我这个说的有点不相干,尝试了多种方式后来才发现是:主表(table1)所对应 ...
随机推荐
- photoshop制作简单ico图标
新建16 * 16透明画布 字体20px 半径4px
- TCP三次握手原则
“已失效的连接请求报文段”的产生在这样一种情况下: client发出的第一个连接请求报文段并没有丢失,而是在某个网络结点长时间的滞留了,以致延误到连接释放以后的某个时间才到达server. 本来这是一 ...
- 【代码审计】iZhanCMS_v2.1 后台存在多个SQL注入漏洞分析
0x00 环境准备 iZhanCMS官网:http://www.izhancms.com 网站源码版本:爱站CMS(zend6.0) V2.1 程序源码下载:http://www.izhancms ...
- Ansible 实战:一键安装 LNMP
Ansible 配置文件 : [root@center /data/ansiblework]# cat ansible.cfg [defaults] remote_user = root remote ...
- HTML 引用
关于 HTML 引用: (1) <q> 和 <blockquote> 用于实现长短不一的引用语(2) <q> 用于短的引用,<blockquote> 用 ...
- ClamAV病毒软件的安装和使用
ClamAV 杀毒是Linux平台最受欢迎的杀毒软件,ClamAV属于免费开源产品,支持多种平台,如:Linux/Unix.MAC OS X.Windows.OpenVMS.ClamAV是基于病毒扫描 ...
- #define #undef
#include <stdio.h> int main( void ) { #define MAX 200 printf("MAX= %d\n",MAX); #unde ...
- Android Security Internals
- android studio下生成jni头文件
cd app/src/main javah -d jni -classpath ../../build/intermediates/classes/debug net.sourceforge.lame ...
- MySQL DROP 大表时的注意事项
对于表的删除,因为InnoDB引擎会在table cache层面维护一个全局独占锁一直到DROP TABLE完成为止,这样,对于表的其他操作会被HANG住.对于较大的表来说,DROP TABLE操作可 ...