sqlserver table partion
SQL SERVER 表分区实施步奏
1. 概要说明
SQL SERVER的表分区功能是为了将一个大表(表中含有非常多条数据)的数据根据某条件(仅限该表的主键)拆分成多个文件存放,以提高查询数据时的效率。创建表分区的主要步骤是1、确定需要以哪一个字段作为分区条件;2、拆分成多少个文件保存该表;3、分区函数(拆分条件);4、分区方案(按拆分函数拆分后需要对应到哪些文件组中去)。
下面就一步一步来说明如何创建表分区:
2. 准备工作
创建一个测试表

CREATE TABLE Sale(
[Id] [int] IDENTITY(1,1) NOT NULL, --自动增长
[Name] [varchar](16) NOT NULL,
[SaleTime] [datetime] NOT NULL,
CONSTRAINT [PK_Sale] PRIMARY KEY CLUSTERED --创建主键
(
[Id] ASC
)
)
插入测试数据
insert Sale ([Name],[SaleTime]) values ('张三','2009-1-1')
insert Sale ([Name],[SaleTime]) values ('李四','2009-2-1')
insert Sale ([Name],[SaleTime]) values ('王五','2009-3-1')
insert Sale ([Name],[SaleTime]) values ('钱六','2012-4-1')
insert Sale ([Name],[SaleTime]) values ('赵七','2012-6-1')
insert Sale ([Name],[SaleTime]) values ('张三','2012-6-1')
insert Sale ([Name],[SaleTime]) values ('李四','2012-7-1')
insert Sale ([Name],[SaleTime]) values ('王五','2012-8-1')
insert Sale ([Name],[SaleTime]) values ('钱六','2012-10-1')
insert Sale ([Name],[SaleTime]) values ('赵七','2012-10-1')
insert Sale ([Name],[SaleTime]) values ('张三','2012-11-1')
insert Sale ([Name],[SaleTime]) values ('李四','2013-12-1')
insert Sale ([Name],[SaleTime]) values ('王五','2014-12-1')
3. 实现步骤
主键设置
表分区需要先确定一个字段,按此字段的某个条件进行拆分,我们这里以Saletime列为例,按月为单位对Sale表进行拆分。因为需要拆分的列必须是主键,所以我们这里先删除原来建表时对ID字段创建的主键,改为SaleTime字段(注意用非聚集主键)
1)修改表

2)移除主键
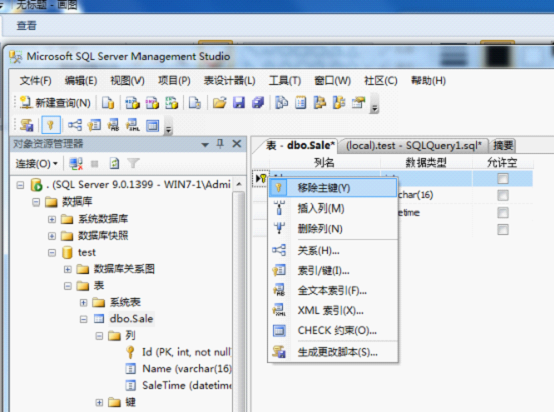
3)新建主键
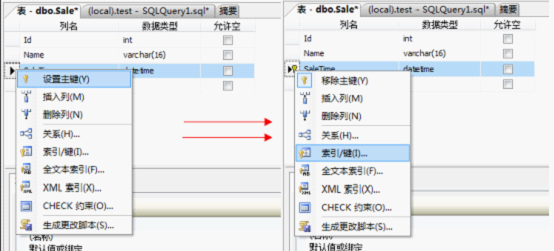
4)设置关联
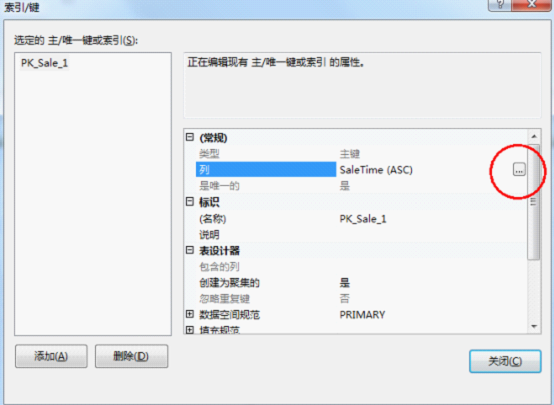
因为主键要求唯一性,所以这里需要做2个字段的关联主键(ID与SaleTime)
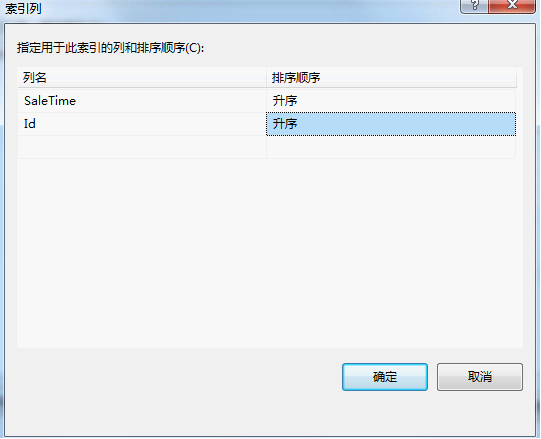
5)修改主键为非聚集
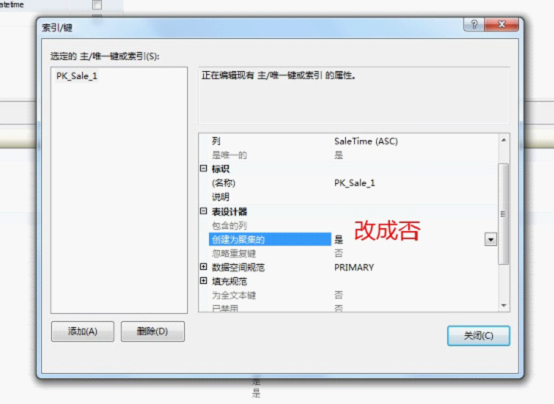
成功后的效果
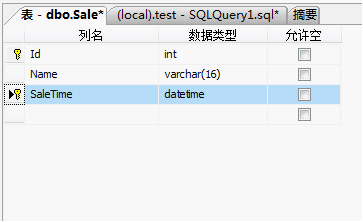
完成后记得保存表
创建文件组和数据文件
因为表分区时按照文件组为单位保存了,而实际数据是保存在这个文件组所包含的文件中的,所以为了高效率,可以一个文件组对应一个数据文件来保存数据,下面我们以月为单位创建文件组
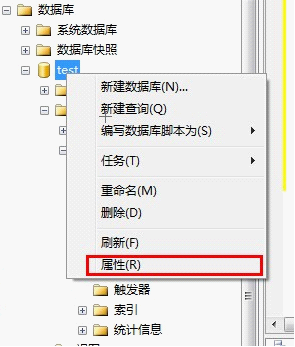


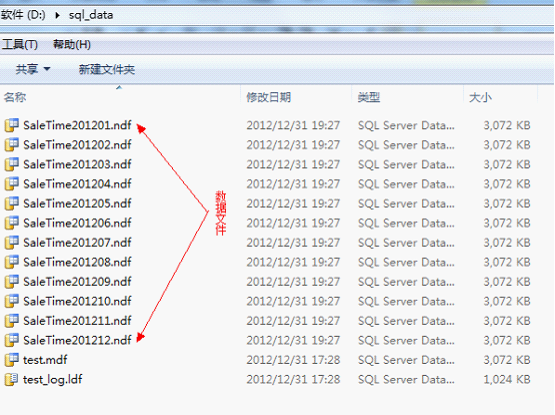
到这里已经把文件组和数据文件创建完毕并建立了对应关系,点击确定键后,在对应的目录下可以看到已经生成了我们设定的12个数据文件了。
创建分区函数(无法可视化实现)
-- 第四步 创建分区函数
CREATE PARTITION FUNCTION partfunSale (DATETIME)
AS RANGE RIGHT FOR VALUES ( '2012-02-01','2012-03-01','2012-04-01','2012-05-01','2012-06-01', '2012-07-01','2012-08-01','2012-09-01','2012-10-01','2012-11-01','2012-12-01'
)
上面这段的含义是创建一个以Datetime字段类型的分区函数,需要注意的是12个文件组对应11个Values,因为分区的规则是
文件组1 ———》2012-02-01之前的数据(日期>2012-02-01)
文件组2 ———》2012-02-01之后2012-03-01之前的数据(2012-02-01≤日期<2012-03-01)
文件组3 ———》2012-03-01之后2012-04-01之前的数据(2012-02-01≤日期<2012-03-01)
文件组4 ———》2012-04-01之后2012-05-01之前的数据(2012-02-01≤日期<2012-03-01)
文件组5 ———》2012-05-01之后2012-06-01之前的数据(2012-02-01≤日期<2012-03-01)
文件组6 ———》2012-06-01之后2012-07-01之前的数据(2012-02-01≤日期<2012-03-01)
文件组7 ———》2012-07-01之后2012-08-01之前的数据(2012-02-01≤日期<2012-03-01)
文件组8 ———》2012-08-01之后2012-09-01之前的数据(2012-02-01≤日期<2012-03-01)
文件组9 ———》2012-09-01之后2012-10-01之前的数据(2012-02-01≤日期<2012-03-01)
文件组10 ———》2012-10-01之后2012-11-01之前的数据(2012-02-01≤日期<2012-03-01)
文件组11 ———》2012-11-01之后2012-12-01之前的数据(2012-02-01≤日期<2012-03-01)
文件组12 ———》2012-12-01之后的数据(2012-02-01≤日期<2012-03-01)
创建分区方案(无法可视化实现)
将创建的分区函数与文件组进行关联
-- 第四步 创建分区方案(注意要比分区函数多一项)
CREATE PARTITION SCHEME partschSale
AS PARTITION partfunSale
TO (
Saletime201201,
Saletime201202,
Saletime201203,
Saletime201204,
Saletime201205,
Saletime201206,
Saletime201207,
Saletime201208,
Saletime201209,
Saletime201210,
Saletime201211,
Saletime201212 )
关联到表(无法可视化实现)
将设置好的分区方案与具体的表进行关联
-- 第五步 设置分区方案到指定表
CREATE CLUSTERED INDEX CT_Sale ON Sale([SaleTime]) ON partschSale([SaleTime])
其中Sale是表名,SaleTime是拆分时依据的字段,partschSale是分区方案
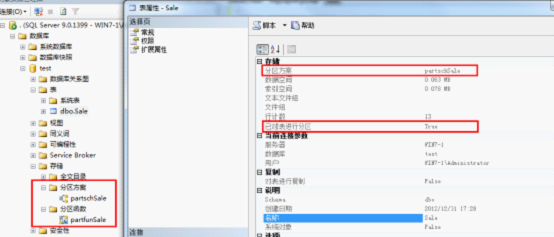
创建好了以后在数据库中右键表名点击属性可以查看到类似如下的效果表示创建成功
统计各数据组中包含的数据条数
-- 统计所有分区表中的记录总数
select $PARTITION.partfunSale(SaleTime) as 分区编号,count(id) as 记录数from Sale group by $PARTITION.partfunSale(SaleTime)
sqlserver table partion的更多相关文章
- How to do if sqlserver table identity column exceed limited ?
script: select a.TABLE_NAME,a.COLUMN_NAME,a.DATA_TYPE, (CASE a.DATA_TYPE when 'int' then 'limited be ...
- Mysql –>EF edmx(model first)–> Sql server table
一.mysql environment When we create an new database,first We need draw er diagram for somebody to sho ...
- mybatis 自动生成文件配置
maven 依赖配置: <!-- sql server --><dependency> <groupId>com.microsoft.sqlserver</g ...
- Nodejs之mssql模块的封装
在nodejs中,mssql模块支持sqlserver数据库操作.今天将mssql模块的某些功能封装为一个类,方便以后调用.封装的功能有执行存储过程,执行查询语句操作等.如果本篇文章对大家有帮助,那就 ...
- sqlserver -- 解决sqlserver2008“Prevent saving changes that require table re_creation(阻止保存要求重新创建表的更改)”的问题
电脑重装了sqlserver2008 R2(英文版)后,新建数据表,新建字段,发现有个字段类型设置错了,想修改字段类型,而该表已经保存好了,即保存后修改字段属性.但无法保存修改后的设置,提示“Savi ...
- SQLSERVER truncate table之后是否会重置表的自增值
SQLSERVER truncate table之后是否会重置表的自增值 今天清理业务库数据的时候,开发人员说可以使用truncate table把两个表的所有数据清理掉 这两个表都有自增ID,都做了 ...
- SQLServer temporary table and table variable
Temporary tables are created in tempdb. The name "temporary" is slightly misleading, for ...
- SqlServer存储过程传入Table参数
今天是周日,刚好有空闲时间整理一下这些天工作业务中遇到的问题. 有时候我们有这样一个需求,就是在后台中传过来一个IList<类>的泛型集合数据,该集合是某个类的实例集合体,然后将该集合中的 ...
- 实战:sqlserver 2008 扩展事件-XML转换为标准的table格式
--假设已经存在Event Session删除 IF EXISTS (SELECT * FROM sys.server_event_sessions WHERE name='MonitorLongQu ...
随机推荐
- PHP安全相关的配置(1)
PHP作为一门强大的脚本语言被越来越多的web应用程序采用,不规范的php安全配置可能会带来敏感信息泄漏.SQL注射.远程包含等问题,规范的安全配置可保障最基本的安全环境.下面我们分析几个会引发安全问 ...
- C# 正则表达式 判断各种字符串(如手机号)
using System; using System.Text.RegularExpressions; namespace MetarCommonSupport { /// <summary&g ...
- Android自动化测试中AccessibilityService获取控件信息(1)
Android自动化测试中AccessibilityService获取控件信息(1) 分类: android自动化测试2014-03-24 15:31 3455人阅读 评论(16) 收藏 举报 and ...
- lwip:与tcp发送相关的选项和函数
1. 禁用Nagle tpcb->flags |= TF_NODELAY 2. tcp_write仅enqueue packet,而不会启动发送. 在tcp_write后调用tcp_output ...
- JSON: JSON 用法
ylbtech-JSON: JSON 用法 1. JSON Object creation in JavaScript返回顶部 1. <!DOCTYPE html> <html> ...
- java 使用jxl poi 操作excel
java操作excel 创建.修改 xls 文件 JAVA操作Excel文件 Java生成和操作Excel文件 java导出Excel通用方法 Java 实现导出excel表 POI Java PO ...
- [UE4]封装、继承、多态
面向对象编程的三大特征 一.封装 公开能做什么,隐藏如何做.封装的目的是减少类之间的依赖. 二.继承 让一个类拥有另一个类的状态和行为,前者可以不加修改地完全复用后者的实现,也可以对有些行为做出自己的 ...
- 利用Red Blob游戏介绍A*算法
转自:http://gad.qq.com/program/translateview/7194337 在游戏中,我们经常想要找到从一个位置到另一个位置的路径.我们不只是想要找到最短距离,同时也要考虑旅 ...
- OpenGL 多线程共享纹理
1:opengl 多线程共享纹理纹理: //解码时候使用opengl进行绘制,需要构建队列和两个线程,分别用于解码数据并且填充纹理和渲染. 主线程常见两个共享上下文: main() { ⋯⋯⋯⋯ gH ...
- spark1.0属性配置以及spark-submit简单使用
在spark1.0中属性支持三种配置方式: 1.代码 在代码中构造SparkConf时指定master.appname或者key-value等 val conf = new SparkConf(); ...