转:sqlplus使用总结
为什么我要使用sqlplus:
SQLPLUS很多人用的并不多,在我观察周围来看,很多人都在使用PLSQL DEVELOPER,尤其是开发人员,更是如此,那学习SQLPLUS有啥好处呢?在我看来有如下三点
1、当我们要在UNIX平台用SHELL访问数据库(如:做一些后台操作,定时任务等等),这个时候SQLPLUS是唯一选择。
2、SQLPLUS 是ORACLE自带的工具,只要安装了数据库就有了,而PLSQL DEVELOPE等工具还要独立安装。并且由于是客户端工具,在网络故障或者是主机性能障碍情况下,往往根本就无法登陆进该工具。
3、每个工具都各有所长,SQLPLUS少了PLSQL DEVELOPER的可视化的方便性,自然有其他独到的优势,在下文中会简要说明。



--
登录数据库:
1.直接敲sqlplus并回车就是启动SQL*PLUS,输入user及password将使用户登陆到缺省的数据库。
请输入用户名:
2.sqlplus user/password@SERVICE_NAME 将连接到指定的数据库。
SQL> connect sys/oracle@192.168.1.204/icpdb
已连接。
SQL>
3.敲sqlplus /nolog就是使SQL*PLUS启动,但不登陆Oracle数据库。然后需要使用connect命令连接Oracle。
SQL>conn u/p[@ip:port/jiagulun]|[service_name]
----
sqlplus hr/hr ------>直接连,不走监听,直接在本地连
sqlplus / as sysdba ------>直接连,不走监听,直接在本地连
sqlplus hr/hr@jiagulun ------>走本地tnsname.ora,走监听
sqlplus hr/hr@ip:port/jiagulun ------>走监听,不走tnsname.ora
sqlplus命令:
--http://ss64.com/ora/syntax-sqlplus.html
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
|
@pathname Run (START) an SQL Script @MyScript.sql parameter1 parameter2 parameter3 In the SQL-Script, refer to the parameters as &1, &2, and &3. @ScriptName.sql will call sub-scripts from the current working directory of SQL*Plus. @C:\work\oracle\ScriptName.sql will call a sub-script from a specific directory. @@pathname Run (START) an SQL Script @@ will call a sub-script from the same directory as the main script. &variable A substitution variable &&variable A substitution variable valid for the session. / Execute (or re-execute) commands in the SQL*Plus buffer does not list commands before running. ACCEPT User input ACC[EPT] variable [NUM[BER]|CHAR|DATE] [FORMAT format] [DEFAULT default] [PROMPT text|NOPROMPT] [HIDE] APPEND Add text to the end of the current line in the buffer. A[PPEND] text_to_add BREAK Specify where and how formatting will change. BREAK ON {column|expr|ROW|REPORT} action BTITLE Place and format a title at the bottom of each page. BTITLE printspec [text|variable] BTITLE [OFF|ON] CHANGE Change text on the current line (change what you just typed.) C /oldval/newval CLEAR Clear the SQL*Plus screen and the screen buffer. CLEAR {BREAKS|BUFFER|COLUMNS|COMPUTES|SCREEN|SQL TIMING} COLUMN Change display width of a column. COMPUTE Calculate and display totals. CONNECT Connect to a database as a specified user: connect username/password@SID COPY Copy data from a query into a table (local or remote) DEFINE User variables: DEFINE varName = String Display a user variable: DEFINE varName Display all variables: DEFINE DEL Delete the current line in the SQL buffer. DEF show oracle default varibales; DESC[RIBE] Describe a table, column, view, synonym, function procedure, package or package contents. DISCONNECT Logoff (but don't exit) EDIT Load the SQL*Plus buffer into an editor. By default, saves the file to AFIEDT.BUF EXECUTE Run a single PLSQL statement EXEC :answer := EMP_PAY.BONUS('SMITH') EXIT [n] Commit, logoff and exit (n = error code) EXIT SQL.SQLCODE GET file Retrieve a previously stored command file. HELP topic Topic is an SQL PLUS command or HELP COMMANDS HOST Execute a host operating system command. HOST CD scripts INPUT Edit sql buffer - add line(s) to the buffer. LIST n m Edit sql buffer - display buffer lines n to m For all lines - specify m as LAST PAUSE message Wait for the user to hit RETURN. PRINT variable List the value of a bind variable or REF Cursor (see VARIABLE / SHOW) PROMPT message Echo a message to the screen. REMARK REMARK comment or --comment-- or /* comment */ RUN Execute (or re-execute) commands in the SQL*Plus buffer Lists the commands before running. RUNFORM Run a SQL*Forms application. SAVE file Save the contents of the SQL*Plus buffer in a command file. SAVE file [CRE[ATE] | REP[LACE] | APP[END]] SET Display or change SQL*Plus settings. SHOW List the value of a system variable (see PRINT) SHUTDOWN [ABORT|IMMEDIATE|NORMAL|TRANSACTIONAL] SPOOL file Store query results in file SPOOL OFF Turn off spooling SPOOL OUT sends file to printer SQLPLUS Start SQL*Plus and connect to a database. STA[RT] Run an SQL Script (see @) STARTUP [NoMOUNT|MOUNT|OPEN] TIMING Record timing data TIMING {START | SHOW | STOP} see CLEAR TIMING TTITLE Define a page title UNDEFINE Delete a user/substitution variable UNDEFINE varName (see DEFINE) VARIABLE Define a bind variable (Can be used in both SQLPlus and PL/SQL) VAR[IABLE] [variable {NUMBER|CHAR|CHAR(n)|REFCURSOR}] A RefCursor bind variable can be used to reference PL/SQL cursor variables in stored procedures. PRINT myRefCursor EXECUTE somePackage.someProcedure(:myRefCursor) VARIABLE on its own will display the definitions made. WHENEVER OSERROR Exit if an OS error occurs WHENEVER SQLERROR Exit if an SQL or PLSQL error occurs |
SQL*Plus Prompt:
To display the currently connected UserName and SID, instead of just SQL>
SET sqlprompt '&_user:&_connect_identifier > '
Add the line above to the file: $ORACLE_SID/sqlplus/admin/glogin.sql (this tip requires Oracle 10g or greater)
“Client Servers were a tremendous mistake and we are sorry that we sold it to you. Instead of applications running on the desktop and data sitting on the server, everything will be Internet based” ~ Larry Ellison, CEO, Oracle Corp.

一点演示:


--

--




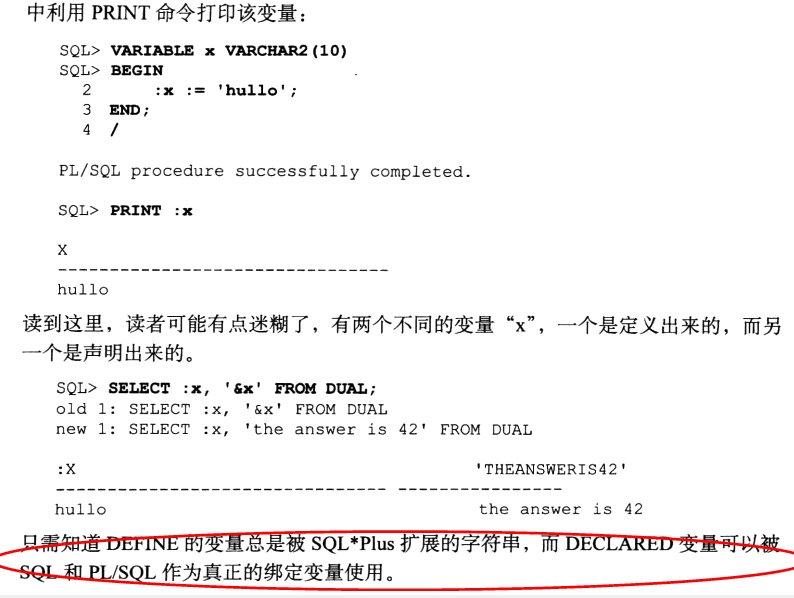







---sqlplus一些小特写
1 sqlplus工具特有的COPY功能
SQL*Plus Copy 命令的语法:
COPY {FROM database | TO database | FROM database TO database} {APPEND|CREATE|INSERT|REPLACE} destination_table [(column, column, column, ...)]
USING query
Append - 向已有的目标表中追加记录,如果目标表不存在,自动创建,这种情况下和Create等效。
Create - 创建目标表并且向其中追加记录,如果目标表已经存在,则会返回错误。
Insert - 向已有的目标表中插入记录,与Append不同的是,如果目标表不存在,不自动创建而是返回错误。
Replace - 用查询出来的数据覆盖已有的目标表中的数据,如果目标表不存在,自动创建。
根据最近使用的经验来看,我认为好处有如下:
1、直接在不同数据库中进行拷贝动作,比传统方法需建DBLINK更方便易用多了。
2、DBLINK一旦建立,如果出于安全考虑,很可能要删除掉,否则会留下安全隐患(想着想着多想了一个理由)。
3、CREATE TABLE XXX AS SELECT * FROM XXX@dblink或
inser into table select *from xxx@dblink的方法必须要保证目标表没有该表或者已经有该表。 而COPY APPEND,REPLACE不存在自动创建,有存在则自动插入,灵活的多。(如果要判断了选择CRDATE,INSERT,可让我们有选择的余地)
4、在已经有数据的情况下,SQLPLUS的APPEND命令追加,比INSERT INTO SELECT 高效
5、如果不考虑性能,比如只是实时同步两库的参数配置小表,那在SHELL中批量写COPY+REPLACE语句,CRONTAB定时同步,就可以保证两库配置表是基本一致的,这个在大表不实用,在小表就一定大有用武之地!(这个是在自己多次反复同步配置表后,无意想到的)
此外我整了几个注意点:
1、这些都是直接路径读,所以COPY+APPEND,INSERT也是直接提交成功的,所有的动作操作后都无法回滚。
2、虽然主要适用于不同库之间,但是在同一库不同用户也使用,甚至同一库同一用户也一样(同用户表名要不一样),就是FROM TO写好则可。
3、写法习惯要注意,COPY+CREATE 后面不要增加TABLE的关键字,经常收到ORACLE语法误导,会多写了这个。
实验:
本机笔记本上10G环境测试可以连到测试环境9I数据库
|
1
2
3
4
5
|
Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - ProductionWith the Partitioning, OLAP and Data Mining optionsC:\Documents and Settings\fujitsu>tnsping dev_dbTNS Ping Utility for 32-bit Windows: Version 10.2.0.1.0 - Production on 15-11月-2009 10:43:26Copyright (c) 1997, 2005, Oracle. All rights reserved. |
已使用的参数文件:
C:\oracle\product\10.2.0\db_1\network\admin\sqlnet.ora
已使用 TNSNAMES 适配器来解析别名
Attempting to contact (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.29.102)(PORT = 1521))) (CONNECT_DATA = (SERVICE_NAME = fjpta)))OK (580 毫秒)
下面实验直接COPY命令
|
1
2
|
C:\Documents and Settings\fujitsu>sqlplus ljb/ljbSQL> copy from ljb/ljb@rqrq to vajs/vajs@dev_db create ljb_test using select * from ljb_test; |
数组提取/绑定大小为 15。(数组大小为 15)
将在完成时提交。(提交的副本为 0)
最大 long 大小为 80。(long 为 80)
表 LJB_TEST 已创建。
267 行选自 ljb@rqrq。
267 行已插入 LJB_TEST。
267 行已提交至 LJB_TEST (位于 vajs@dev_db)。
--这里注意,create ljb_test 我老是会根据ORACLE语法习惯写成create table ljb_test,忘记了SQLPLUS语法中没有这个TABLE关键字,这就是思维习惯了,呵呵。
这个等效的方法在ORACLE中如何实现,大家都知道,应该是 CREATE TABLE LJB_TEST AS SELECT * FROM LJB_TEST@DBLINK WHERE XXX条件,这个时候就一定要建DBLINK,多了一个步骤,而且大家一定有过没有权限建DBLINK或者是忘记DBLINK语法的经历,如此COPY命令就省事多了(此外我还想到另一种情况,就是DBLINK一旦建立了,就有可能被人使用,如果出于安全不想让人用,建立了还要立即删除了,如果用COPY命令,这个安全问题就无需考虑了)。
当我们要继续新插入数据该如何写呢?
|
1
|
SQL> copy from ljb/ljb@rqrq to vajs/vajs@dev_db append vajs.ljb_test using select * from ljb.ljb_test |
数组提取/绑定大小为 15。(数组大小为 15)
将在完成时提交。(提交的副本为 0)
最大 long 大小为 80。(long 为 80)
267 行选自 ljb@rqrq。
267 行已插入 VAJS.LJB_TEST。
267 行已提交至 VAJS.LJB_TEST (位于 vajs@dev_db)。
查查看数据,本地10G环境ljb_test表记录267条
|
1
2
3
4
5
6
|
Connected to Oracle Database 10g Enterprise Edition Release 10.2.0.1.0Connected as ljbSQL> SELECT COUNT(*) FROM ljb_test; COUNT(*)---------- 267 |
9I测试环境ljb_test表记录534条,看来确实是APPEND进去了。
|
1
2
3
4
5
6
|
Connected to Oracle9i Enterprise Edition Release 9.2.0.7.0Connected as vajsSQL> SELECT COUNT(*) FROM ljb_test; COUNT(*)---------- 534 |
再看看LJB_TEST存在情况下,COPY +INSERT如何?
发现插入OK,记录增加到801,为了篇幅,步骤不贴!
那DROP 掉vajs 用户下的ljb_test表后呢?
|
1
|
SQL> copy from ljb/ljb@rqrq to vajs/vajs@dev_db insert vajs.ljb_test using select * from ljb.ljb_test |
数组提取/绑定大小为 15。(数组大小为 15)
将在完成时提交。(提交的副本为 0)
最大 long 大小为 80。(long 为 80)
ERROR:
ORA-00942: table or view does not exist
看出来这个INSERT 是一定需要有表存在的。不像APPEND,可以追加。
最后实验一下REPLACE(前面说过了,想依赖这个来实时同步两库的小记录配置表)
|
1
|
SQL> copy from ljb/ljb@rqrq to vajs/vajs@dev_db replace vajs.ljb_test using select * from ljb.ljb_test |
数组提取/绑定大小为 15。(数组大小为 15)
将在完成时提交。(提交的副本为 0)
最大 long 大小为 80。(long 为 80)
表 VAJS.LJB_TEST 已创建。
267 行选自 ljb@rqrq。
267 行已插入 VAJS.LJB_TEST。
267 行已提交至 VAJS.LJB_TEST (位于 vajs@dev_db)。
发现VAJS用户下被DROP的表被建立了,记录为267
|
1
2
3
4
5
6
|
Connected to Oracle9i Enterprise Edition Release 9.2.0.7.0Connected as vajsSQL> SELECT COUNT(*) FROM vajs.ljb_test; COUNT(*)---------- 267 |
--再执行一次!
|
1
|
SQL> copy from ljb/ljb@rqrq to vajs/vajs@dev_db replace vajs.ljb_test using select * from ljb.ljb_test |
数组提取/绑定大小为 15。(数组大小为 15)
将在完成时提交。(提交的副本为 0)
最大 long 大小为 80。(long 为 80)
表 VAJS.LJB_TEST 已删除。 ----呵呵,有表后的玄机就在这,不过是先删除表再插入表而已!
表 VAJS.LJB_TEST 已创建。
267 行选自 ljb@rqrq。
267 行已插入 VAJS.LJB_TEST。
267 行已提交至 VAJS.LJB_TEST (位于 vajs@dev_db)。
发现9I数据库的VAJS的ljb_test表记录保持不变,看来用来做同步,还真好用:)
|
1
2
3
4
5
6
|
Connected to Oracle9i Enterprise Edition Release 9.2.0.7.0Connected as vajsSQL> SELECT COUNT(*) FROM vajs.ljb_test; COUNT(*)---------- 267 |
最后,经过测试,发现传统CREATE TABLE XXX AS SELECT * FROM XXX@dblink 所花费的REDO最少
但是INSERT INTO XXX SELECT * FROM XXX@DBLINK却不如COPY +APPEND所花费的REDO少。
通过这个了解到,如果考虑新增数据,甚至COPY+APPND还有性能上的优势。
这个如何测试呢?我是测过了,但是考虑到文章的简洁,限于篇幅,贴出来又删除了。
请借鉴大家关注我的系列实验的第一贴,呵呵,整理还是会有派场的:)
2 利用SQLPLUS的自动PRINT功能+REF CURSOR可以实现SQL SERVER中的过程中写SELECT语句的写法
这个小节源于同事提出的问题,经大牛NEWKID兄指点后,正好整理出来,作为SQLPLUS的一个功能补充
接触过SQL SERVER的人都知道,在SQL SERVER中可以直接在过程中写如下:
|
1
2
3
|
BEGIN SELECT * FROM TEST where rownum=1;end; |
而这样写法在ORACLE的过程里是行不通的,一定会报“中缺少 INTO 子句”这样的错误,我最早接触的数据库是SQL SERVER,后来接触到ORACLE后,立即就对这个差异产生了困惑,那我们如果要这样实现,咋办呢?
其实想想,这样的需求还真是有的:
1、以前我最早使用SQL SERVER的时候,喜欢把非常非常复杂逻辑的SQL查询语句整到过程中去,为啥,因为到时候执行查询的时候就不要复制粘贴一大段,如果名字起的好记些,我背都背住了,然后执行一下过程名就把我要的东西查询出来了,写什么上线操作步骤,文章也可精炼多了!
2、如果是前台展现语句能捕获输出的结果集,直接展现就OK了,否则还要插入到某表中,然后再展现某表,这个比较麻烦,(此外如果展现结果是动态的,字段在变化,岂不是要建立N张表去展现了?)
实验:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
SQL> drop table ljb_test;Table droppedSQL> create table ljb_test (id1 int,id2 int);Table createdSQL> insert into ljb_test select rownum,rownum+2 from dual connect by rownum<=5;5 rows insertedSQL> commit;Commit completeSQL> select * from ljb_test; ID1 ID2--------------------------------------- --------------------------------------- 1 3 2 4 3 5 4 6 5 7SQL> CREATE OR REPLACE PROCEDURE p_test ( p_min in number,p_max in number,p_ref OUT SYS_REFCURSOR) 2 AS 3 BEGIN 4 OPEN p_ref for SELECT * from ljb_test where id1>=p_min and id1<=p_max; 5 END p_test; 6 /过程已创建。SQL>SQL> SET AUTOPRINT ONSQL> VAR p_ref REFCURSOR;SQL> EXEC p_test(1,2,:p_ref);PL/SQL 过程已成功完成。 ID1 ID2---------- ---------- 1 3 2 4 |
此外大家一定对select * from table(dbms_xplan.display)这个写法不陌生,很多人一看就明白,这个是查看执行计划的语句(是在EXPLAIN PLAN FOR SQL语句后紧接着执行的命令),由此也可以得到启发,但是这样的查询出
来的结果集是由SELECT语句触发的,而非命令执行的。
table()典型例子如下:
|
1
2
3
4
5
|
SQL> CREATE or replace TYPE t_test AS OBJECT ( 2 id1 NUMBER 3 ,id2 NUMBER 4 ) 5 / |
类型已创建。
|
1
2
|
SQL> CREATE TYPE tb_test AS TABLE OF t_test 2 / |
类型已创建。
|
1
2
3
4
5
6
7
8
9
10
11
|
SQL> CREATE OR REPLACE FUNCTION f_test RETURN tb_test 2 AS 3 v_ret tb_test:=tb_test(); 4 BEGIN 5 FOR i IN 1..2 LOOP 6 v_ret.EXTEND; 7 v_ret(i) := t_test(i,i+2); 8 END LOOP; 9 RETURN v_ret;10 END f_test;11 / |
函数已创建。
|
1
2
3
4
5
|
SQL> select * from table(f_test); ID1 ID2---------- ---------- 1 3 2 4 |
TABLE()的方法就得先定义嵌套表,然后从表里用SELECT BULK COLLECT INTO取得数据(把table()典型子中那个循环改为SELECT取数据),再返回这个嵌套表,就能实现这个select * from ljb_test表的输出了,不过相对而言,当前需求用这个方法相比“SQLPLUS的自动PRINT功能+REF CURSOR”的方法有些不适当,因为非常繁琐!
如果一定要用select * from table()来处理,具体如下(t_test 和 tb_test 的type就不再重复建立了)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
SQL> CREATE OR REPLACE FUNCTION f_test(p_min IN NUMBER,p_max IN NUMBER) RETURN tb_test 2 AS 3 v_ret tb_test:=tb_test(); 4 BEGIN 5 SELECT t_test(id1,id2) 6 BULK COLLECT INTO v_ret 7 FROM ljb_TEST WHERE id1>=p_min AND id1<=p_max; 8 9 RETURN v_ret;10 END f_test;11 /Function createdSQL> select * from table(f_test(1,2)); ID1 ID2---------- ---------- 1 3 2 4 |
3 SQLPLUS SPOOL 功能
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
SQL> select count(*) from dba_tables where owner='YXL'; COUNT(*)---------- 4SQL> SPOOL c:drop_table.sqlSQL> SELECT 'DROP TABLE '|| table_name ||';' FROM dba_tables where owner='YXL';'DROPTABLE'||TABLE_NAME||';'--------------------------------------------------------------------------------DROP TABLE TEST_YXL;DROP TABLE TEST_YXL1;DROP TABLE YXL_TEST;DROP TABLE YXL_TEST1;SQL> SPOOL OFFSQL> show userUSER 为 "YXL"SQL> @c:\drop_table.sqlSP2-0734: 未知的命令开头 "SQL> SELEC..." - 忽略了剩余的行。SP2-0734: 未知的命令开头 "'DROPTABLE..." - 忽略了剩余的行。表已删除。表已删除。表已删除。表已删除。SP2-0734: 未知的命令开头 "SQL> SPOOL..." - 忽略了剩余的行。 |
以上spool+@执行命令脚本可以写进SHELL中,轻松实现定时批量对数据库进程操作的任务。
注:大家可能注意到执行过程中有一点错误提示,虽然不影响最终的正确结果,但是却甚为不美观。原因在于
|
1
|
SQL> edit c:\drop_table.sql |
会发现drop_table.sql中的记录如下:
|
1
2
3
4
5
6
7
8
|
SQL> SELECT 'DROP TABLE '|| table_name ||';' dba_tables where owner='YXL';'DROPTABLE'||TABLE_NAME||';' --------------------------------------------------------------------------------DROP TABLE TEST_YXL; DROP TABLE TEST_YXL1; DROP TABLE YXL_TEST; DROP TABLE YXL_TEST1; SQL> SPOOL OFF |
其实实际上,我们只要有如下的结果就足矣了:
|
1
2
3
4
|
DROP TABLE TEST_YXL; DROP TABLE TEST_YXL1; DROP TABLE YXL_TEST; DROP TABLE YXL_TEST1; |
现在这个是批量删除命令,出错无非就不执行,还好,要是进行与sqlldr进程结合的操作,那出错sqlldr就
会出错了。咋办呢,继续看下面
4 其他相关参数实验
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
set echo offset feedback offset newpage noneset pagesize 5000set linesize 500set verify offset pagesize 0set term offset trims onset linesize 600set heading offset timing offset verify offset numwidth 38SPOOL c:\delete_table.sqlSELECT 'DELETE '|| table_name ||';' from dba_tables where owner='LJB' and rownum<=3;SPOOL OFF |
查看
|
1
2
3
4
5
|
SQL> SELECT 'DELETE '|| table_name ||';' from dba_tables where owner='LJB' and rownum<=3;DELETE TEST_ABCD;DELETE TEST222;DELETE TEST111;SQL> SPOOL OFF |
看上去好像还有点小问题,咋有这个SQL>的东东头尾两个啊,呵呵,用上sqlplus -s 参数进sqlplus后,再操作就消失了,最终结果就变成是很清爽的如下了
|
1
2
3
|
DELETE TEST_ABCD;DELETE TEST222;DELETE TEST111; |
参数重点说明几个,其他就不实验了,一一罗列出简单在附录中说明
1、sqlplus 的s 参数(大小写不区分)
大家平时可能没有注意到使用这个参数,这个参数是干什么用的呢,原来-s的这个含义表示silent,将交互动作的提示符给隐藏了。
下面做个实验一看便知。
|
1
2
3
4
5
6
7
8
9
|
C:\Documents and Settings\fujitsu>sqlplus -s ljb/ljbselect * from ljb_test; ID1 ID2---------- ---------- 1 3exitC:\Documents and Settings\fujitsu>sqlplus ljb/ljbSQL*Plus: Release 10.2.0.1.0 - Production on 星期日 11月 15 14:03:26 2009Copyright (c) 1982, 2005, Oracle. All rights reserved. |
连接到:
|
1
2
3
4
5
6
|
Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - ProductionWith the Partitioning, OLAP and Data Mining optionsSQL> select * from ljb_test; ID1 ID2---------- ---------- 1 3 |
2、set heading off可以将列名去掉
|
1
2
3
4
|
C:\Documents and Settings\fujitsu>sqlplus -s ljb/ljbset heading offselect * from ljb_test; 1 3 |
具体其他详细参数设置说明,这里我就不一一实验了,理解上面脚本的其他参数设置可以去相关文档搜索。此外还有其他各类参数,有兴趣也可一并研究。
5:edit命令
| 使用sqlplus重新edit上一次输入的命令时,没反应,可以随便输入东西,退不出来。可是临时文件已经生成了。咋办 ? |
edit后默认编辑器是ed,可用def命令查看;退出ed用
|
1
2
3
|
.wq |
改变编辑器:
(1)在 sqlplus 中输入:
DEFINE _EDITOR=vi
缺点是每次进 sqlplus 都得改,比较麻烦。
(2)如果你所用的用户对 $ORACLE_HOME 下的文件有修改权限,可修改 $ORACLE_HOME/sqlplus/admin/glogin.sql ,在最后一行也是加上DEFINE _EDITOR=vi即可,这样 vi 就变成默认编辑器了。
6:sqlplus环境配置
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
define _editor=viset serveroutput on size 1000000set trimspool onset long 5000set linesize 100set pagesize 9999column plan_plus_exp format a80column global_name new_value gnameset termout offdefine gname=idlecolumn global_name new_value gnameselect lower(user) || '@' || substr( global_name, 1, decode( dot, 0, length(global_name), dot-1) ) global_name from (select global_name, instr(global_name,'.') dot from global_name );set sqlprompt '&gname> 'set termout on |
sqlplus 每次启动前,会读login.sql(若有的话) ,glogin.sql
login.sql只对某特定用户生效,它的优先级高于glogin.sql,glogin.sql是全局设置。
所以,同一个环境变量,比如linesize ,glogin.sql 和login.sql 都有设置,则login.sql 中的设置起作用。
glogin.sql 的文件位置固定,在$ORACLE_HOME/sqlplus/admin 下面
login.sql的位置不固定,一般将login.sql放在运行sqlplus 的当前目录(用pwd查看当前目录),即:/home/oralce
于是在glogin.sql中加入了那段脚本,直接在命令行用sqlplus连接数据库,果然自动执行了那段代码,然后将glogin.sql还原,又将login.sql拷贝到cmd窗口的当前目录,直接在命令行用sqlplus连接数据库,果然自动执行了login.sql脚本,再回来看Thomas Kyte大师对这个脚本的描述,终于是彻底明白了。
这样每次登录sqlplus后都会进行一些初始设置,从提示符也能很方便的知道当前连接的是哪个用户,而且连接不同的用户登录后这个提示符还能动态的变,而手动执行这个脚本的话没这个效果,应当是每次登录都会重新读取login.sql这个脚本,所以才会刷新提示符。
参考:
敬彬实验<四> SQLPLUS探讨:
http://blog.sina.com.cn/s/blog_62e437c40100g2jt.html
http://blog.itpub.net/1708925/viewspace-628494
http://leoguan.blog.51cto.com/816378/632488
sqlplus命令使用大全:
http://sysadm.blog.51cto.com/180447/30802
行云无名:http://blog.csdn.net/buffoon/article/details/422372
大牛博客:http://www.cnblogs.com/lds85930/archive/2008/07/07/1237526.html
david dai(常用命令总结) :http://blog.csdn.net/tianlesoftware/article/details/5040984
还不算晕(sqlplus常用命令):http://blog.csdn.net/haibusuanyun/article/details/11180137
网站:
http://ss64.com/ora/syntax-sqlplus.html
图书:
Oracle_SQLPlus_The_Definitive_Guide_2nd_Edition
Oracle官方文档:
http://docs.oracle.com/cd/E11882_01/server.112/e16604/toc.htm
http://www.orafaq.com/wiki/SQL*Plus
| SQL*Plus User's Guide and Reference |
本文出自 “从运维到ETL” 博客,请务必保留此出处http://fuwenchao.blog.51cto.com/6008712/1363400
转:sqlplus使用总结的更多相关文章
- oracle日常——sqlplus客户端登录
1.进入cmd 2.命令--sqlplus--提示输入帐号与密码 3.进入后,就可以直接键入sql命令 ps.sql命令后面需要添加分号后才可以回车执行
- SqlPlus中退格键和方向键的设置
参见:http://www.cnblogs.com/wjx515/p/3717986.html http://blog.csdn.net/jacky0922/article/details/765 ...
- sqlplus运行sql文件
当sql文件的数据比较多的时候,pl/sql运行比较慢,可以通过oracle的sqlplus进行导入: sqlplus user/password@tnsname@sqlfile.sql; 注意如果文 ...
- sqlplus连接oracle失败分析和解决
背景: 多台Linux服务器需要安装Oracle客户端,实现和Oracle数据库连接做业务处理. 安装完第一台后,直接将安装的目录压缩并复制到其他几台机器上,启动sqlplus连接数据库时,一直提示输 ...
- 在Oracle SQLplus下建用户 建表
在建表之前最好新建一个用户,因为在sys用户下的表格不允许删除列, 所以最好不要在sys用户下建表. 一.在Oracle SQLplus下建用户: 1.以dba身份登陆SQLplus: [oracle ...
- oracle sqlplus 格式化输出
1- show pagesize ###显示页行数 set pagesize 300 ###显示页行数为300 2- show linesize ###显示行宽度 set li ...
- win2012,oracle11g,sqlplus切换实例的方法
问题环境:windows 2012 r2 64位 ,oracle 11.2.0.4,多个实例. 在这种情况下, sqlplus "/as sysdba" 默认登录的是系统后面安装 ...
- (转)sqlplus中文显示乱码的问题
sqlplus中文显示乱码的问题 2010-07-19 11:33:26 分类: LINUX 在windows下sqlplus完全正常,可是到linux下,sqlplus中文显示就出问题了,总是显示“ ...
- SQLPlus 在连接时通常有四种方式
1. sqlplus / as sysdba 操作系统认证,不需要数据库服务器启动listener,也不需要数据库服务器处于可用状态.比如我们想要启动数据库就可以用这种方式进入 sqlpl ...
- oracle使用sqlplus创建表空间
一.打开命令行窗口,输入以下命令:sqlplus /nolog 回车后,将出现提示符 SQL>, 这时输入conn / as sysdba 一般即可登录,如果失败的话,可以试一下用conn sy ...
随机推荐
- c++ primer plus 第三章 课后题答案
#include<iostream> using namespace std; int main() { ; int shen_gao; cout <<"Please ...
- mint18
ubuntu16.04用了一段时间,果然遇到祖传内部错误.然后虚拟机遇到2次重启后卡死在黑屏闪光标位置.但是用系统盘准备重装,执行到分区这步放弃,重启,居然有能启动. 作为开发机,实在有点胆战心惊,虽 ...
- TCP-IP详解:Nagle算法
在使用一些协议通讯的时候,比如Telnet,会有一个字节字节的发送的情景,每次发送一个字节的有用数据,就会产生41个字节长的分组,20个字节的IP Header 和 20个字节的TCP Header, ...
- zzuli1427 NO.6校赛----数字转换
1427: 数字转换 Time Limit: 1 Sec Memory Limit: 128 MBSubmit: 572 Solved: 153 SubmitStatusWeb Board Des ...
- 最齐全的Android studio 快捷键(亲测可用)
Action Mac OSX Win/Linux 注释代码(//) Cmd + / Ctrl + / 注释代码(/**/) Cmd + Option + / Ctrl + Alt + / 格式化代码 ...
- Error Code: 1175. You are using safe update mode and you tried to ......
MySQL提示的错误信息: Error Code: 1175. You are using safe update mode and you tried to update a table witho ...
- python daal test
import os import sys from daal.algorithms import low_order_moments from daal.data_management import ...
- vue打包后图片找不到情况
打包之前需要修改如下配置文件: 配置文件一:build>>>utils.js (修改publicPath:"../../" , 这样写是处理打包后找不到静态文件( ...
- java并发编程:线程安全管理类--原子操作类--AtomicReferenceFieldUpdater<T,V>
1.类 AtomicReferenceFieldUpdater<T,V> public abstract class AtomicReferenceFieldUpdater<T,V& ...
- HDU 3226 背包
转载自:http://www.cppblog.com/dango/archive/2010/08/26/124881.aspx 貌似是01背包的强化版.但是感觉这样写好理解些.就是01背包拓展了.