决策树之Cart算法一
Contents
1. CART算法的认识
2. CART算法的原理
3. CART算法的实现
1. CART算法的认识
Classification And Regression Tree,即分类回归树算法,简称CART算法,它是决策树的一种实现,通
常决策树主要有三种实现,分别是ID3算法,CART算法和C4.5算法。
CART算法是一种二分递归分割技术,把当前样本划分为两个子样本,使得生成的每个非叶子结点都有两个分支,
因此CART算法生成的决策树是结构简洁的二叉树。由于CART算法构成的是一个二叉树,它在每一步的决策时只能
是“是”或者“否”,即使一个feature有多个取值,也是把数据分为两部分。在CART算法中主要分为两个步骤
(1)将样本递归划分进行建树过程
(2)用验证数据进行剪枝
2. CART算法的原理
上面说到了CART算法分为两个过程,其中第一个过程进行递归建立二叉树,那么它是如何进行划分的 ?
设 代表单个样本的
代表单个样本的 个属性,
个属性, 表示所属类别。CART算法通过递归的方式将
表示所属类别。CART算法通过递归的方式将 维的空间划分为不重
维的空间划分为不重
叠的矩形。划分步骤大致如下
(1)选一个自变量 ,再选取
,再选取 的一个值
的一个值 ,
, 把
把 维空间划分为两部分,一部分的所有点都满足
维空间划分为两部分,一部分的所有点都满足 ,
,
另一部分的所有点都满足 ,对非连续变量来说属性值的取值只有两个,即等于该值或不等于该值。
,对非连续变量来说属性值的取值只有两个,即等于该值或不等于该值。
(2)递归处理,将上面得到的两部分按步骤(1)重新选取一个属性继续划分,直到把整个 维空间都划分完。
维空间都划分完。
在划分时候有一个问题,它是按照什么标准来划分的 ? 对于一个变量属性来说,它的划分点是一对连续变量属
性值的中点。假设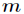 个样本的集合一个属性有
个样本的集合一个属性有 个连续的值,那么则会有
个连续的值,那么则会有 个分裂点,每个分裂点为相邻
个分裂点,每个分裂点为相邻
两个连续值的均值。每个属性的划分按照能减少的杂质的量来进行排序,而杂质的减少量定义为划分前的杂质减
去划分后的每个节点的杂质量划分所占比率之和。而杂质度量方法常用Gini指标,假设一个样本共有 类,那么
类,那么
一个节点 的Gini不纯度可定义为
的Gini不纯度可定义为

其中 表示属于
表示属于 类的概率,当Gini(A)=0时,所有样本属于同类,所有类在节点中以等概率出现时,Gini(A)
类的概率,当Gini(A)=0时,所有样本属于同类,所有类在节点中以等概率出现时,Gini(A)
最大化,此时 。
。
有了上述理论基础,实际的递归划分过程是这样的:如果当前节点的所有样本都不属于同一类或者只剩下一个样
本,那么此节点为非叶子节点,所以会尝试样本的每个属性以及每个属性对应的分裂点,尝试找到杂质变量最大
的一个划分,该属性划分的子树即为最优分支。
下面举个简单的例子,如下图

在上述图中,属性有3个,分别是有房情况,婚姻状况和年收入,其中有房情况和婚姻状况是离散的取值,而年
收入是连续的取值。拖欠贷款者属于分类的结果。
假设现在来看有房情况这个属性,那么按照它划分后的Gini指数计算如下

而对于婚姻状况属性来说,它的取值有3种,按照每种属性值分裂后Gini指标计算如下

最后还有一个取值连续的属性,年收入,它的取值是连续的,那么连续的取值采用分裂点进行分裂。如下

根据这样的分裂规则CART算法就能完成建树过程。
建树完成后就进行第二步了,即根据验证数据进行剪枝。在CART树的建树过程中,可能存在Overfitting,许多
分支中反映的是数据中的异常,这样的决策树对分类的准确性不高,那么需要检测并减去这些不可靠的分支。决策
树常用的剪枝有事前剪枝和事后剪枝,CART算法采用事后剪枝,具体方法为代价复杂性剪枝法。可参考如下链接
剪枝参考:http://www.cnblogs.com/zhangchaoyang/articles/2709922.html
3. CART算法的实现
以下代码是网上找的CART算法的MATLAB实现。
CART function D = CART(train_features, train_targets, params, region) % Classify using classification and regression trees
% Inputs:
% features - Train features
% targets - Train targets
% params - [Impurity type, Percentage of incorrectly assigned samples at a node]
% Impurity can be: Entropy, Variance (or Gini), or Missclassification
% region - Decision region vector: [-x x -y y number_of_points]
%
% Outputs
% D - Decision sufrace [Ni, M] = size(train_features); %Get parameters
[split_type, inc_node] = process_params(params); %For the decision region
N = region(5);
mx = ones(N,1) * linspace (region(1),region(2),N);
my = linspace (region(3),region(4),N)' * ones(1,N);
flatxy = [mx(:), my(:)]'; %Preprocessing
[f, t, UW, m] = PCA(train_features, train_targets, Ni, region);
train_features = UW * (train_features - m*ones(1,M));;
flatxy = UW * (flatxy - m*ones(1,N^2));; %Build the tree recursively
disp('Building tree')
tree = make_tree(train_features, train_targets, M, split_type, inc_node, region); %Make the decision region according to the tree
disp('Building decision surface using the tree')
targets = use_tree(flatxy, 1:N^2, tree); D = reshape(targets,N,N);
%END function targets = use_tree(features, indices, tree)
%Classify recursively using a tree if isnumeric(tree.Raction)
%Reached an end node
targets = zeros(1,size(features,2));
targets(indices) = tree.Raction(1);
else
%Reached a branching, so:
%Find who goes where
in_right = indices(find(eval(tree.Raction)));
in_left = indices(find(eval(tree.Laction))); Ltargets = use_tree(features, in_left, tree.left);
Rtargets = use_tree(features, in_right, tree.right); targets = Ltargets + Rtargets;
end
%END use_tree function tree = make_tree(features, targets, Dlength, split_type, inc_node, region)
%Build a tree recursively if (length(unique(targets)) == 1),
%There is only one type of targets, and this generates a warning, so deal with it separately
tree.right = [];
tree.left = [];
tree.Raction = targets(1);
tree.Laction = targets(1);
break
end [Ni, M] = size(features);
Nt = unique(targets);
N = hist(targets, Nt); if ((sum(N < Dlength*inc_node) == length(Nt) - 1) | (M == 1)),
%No further splitting is neccessary
tree.right = [];
tree.left = [];
if (length(Nt) ~= 1),
MLlabel = find(N == max(N));
else
MLlabel = 1;
end
tree.Raction = Nt(MLlabel);
tree.Laction = Nt(MLlabel); else
%Split the node according to the splitting criterion
deltaI = zeros(1,Ni);
split_point = zeros(1,Ni);
op = optimset('Display', 'off');
for i = 1:Ni,
split_point(i) = fminbnd('CARTfunctions', region(i*2-1), region(i*2), op, features, targets, i, split_type);
I(i) = feval('CARTfunctions', split_point(i), features, targets, i, split_type);
end [m, dim] = min(I);
loc = split_point(dim); %So, the split is to be on dimention 'dim' at location 'loc'
indices = 1:M;
tree.Raction= ['features(' num2str(dim) ',indices) > ' num2str(loc)];
tree.Laction= ['features(' num2str(dim) ',indices) <= ' num2str(loc)];
in_right = find(eval(tree.Raction));
in_left = find(eval(tree.Laction)); if isempty(in_right) | isempty(in_left)
%No possible split found
tree.right = [];
tree.left = [];
if (length(Nt) ~= 1),
MLlabel = find(N == max(N));
else
MLlabel = 1;
end
tree.Raction = Nt(MLlabel);
tree.Laction = Nt(MLlabel);
else
%...It's possible to build new nodes
tree.right = make_tree(features(:,in_right), targets(in_right), Dlength, split_type, inc_node, region);
tree.left = make_tree(features(:,in_left), targets(in_left), Dlength, split_type, inc_node, region);
end end
在Julia中的决策树包:https://github.com/bensadeghi/DecisionTree.jl/blob/master/README.md
决策树之Cart算法一的更多相关文章
- 决策树算法一:hunt算法,信息增益(ID3)
决策树入门 决策树是分类算法中最重要的算法,重点 决策树算法在电信营业中怎么工作? 这个工人也是流失的,在外网转移比处虽然没有特征来判断,但是在此节点处流失率有三个分支概率更大 为什么叫决策树? 因为 ...
- 监督学习——决策树理论与实践(下):回归决策树(CART)
介绍 决策树分为分类决策树和回归决策树: 上一篇介绍了分类决策树以及Python实现分类决策树: 监督学习——决策树理论与实践(上):分类决策树 决策树是一种依托决策而建立起来的一种 ...
- 机器学习技法-决策树和CART分类回归树构建算法
课程地址:https://class.coursera.org/ntumltwo-002/lecture 重要!重要!重要~ 一.决策树(Decision Tree).口袋(Bagging),自适应增 ...
- 决策树之 CART
继上篇文章决策树之 ID3 与 C4.5,本文继续讨论另一种二分决策树 Classification And Regression Tree,CART 是 Breiman 等人在 1984 年提出的, ...
- 机器学习之决策树三-CART原理与代码实现
决策树系列三—CART原理与代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/9482885.html ID ...
- 机器学习:决策树(CART 、决策树中的超参数)
老师:非参数学习的算法都容易产生过拟合: 一.决策树模型的创建方式.时间复杂度 1)创建方式 决策树算法 既可以解决分类问题,又可以解决回归问题: CART 创建决策树的方式:根据某一维度 d 和某一 ...
- 决策树之CART算法
顾名思义,CART算法(classification and regression tree)分类和回归算法,是一种应用广泛的决策树学习方法,既然是一种决策树学习方法,必然也满足决策树的几大步骤,即: ...
- 《机器学习实战》学习笔记第九章 —— 决策树之CART算法
相关博文: <机器学习实战>学习笔记第三章 —— 决策树 主要内容: 一.CART算法简介 二.分类树 三.回归树 四.构建回归树 五.回归树的剪枝 六.模型树 七.树回归与标准回归的比较 ...
- 决策树2 -- CART算法
声明: 1,本篇为个人对<2012.李航.统计学习方法.pdf>的学习总结.不得用作商用,欢迎转载,但请注明出处(即:本帖地址). 2,因为本人在学习初始时有非常多数学知识都已忘记.所以为 ...
随机推荐
- 提取nmap扫描出来的xml文件
代码: <?php $file_path = "xiamen_scan_ok.xml"; $file = fopen($file_path, "r"); ...
- php去除字符串中的HTML标签
php自带的函数可以去除/删除字符串中的HTML标签/代码. strip_tags(string,allow):函数剥去 HTML.XML 以及 PHP 的标签. 参数:string,必填,规定要检查 ...
- [cpu]cpu unused pin应该怎样从硬件和软件上处理
Micro Community 1. This is a common question with lots of replies and lots of opinions. Preferred op ...
- [git]使用vimdiff做git代码比较
#git 如何实现vimdiffgit config --global diff.tool vimdiff git config --global difftool.prompt false git ...
- ubuntu linux下建立stm32开发环境: GCC安装以及工程Makefile建立
http://blog.csdn.net/embbnux/article/details/17616809
- sam9260 adc module
/* * driver/char/at91_adc.c * * Copyright (C) 2007 Embedall Technology Co., Ltd. * * Analog-to-digit ...
- js 的数值限制可能引起的问题
源于:https://raw.github.com/ruanyf/jstutorial/gh-pages/grammar/number.md 1. 根据国际标准IEEE 754,64位浮点数格式的64 ...
- 虚拟机或真机调试React Native, 开启开发者菜单
虚拟机调试呼出开发者菜单,只需按下Ctrl+M组合键即可: 对于真机,通常摇晃手机可呼出,也可以在cmd输入adb shell input keyevent 82呼出菜单.如果还是不行,可能是系统管家 ...
- Hadoop HDFS分布式文件系统 常用命令汇总
引言:我们维护hadoop系统的时候,必不可少需要对HDFS分布式文件系统做操作,例如拷贝一个文件/目录,查看HDFS文件系统目录下的内容,删除HDFS文件系统中的内容(文件/目录),还有HDFS管理 ...
- so在genymotation中错误问题
genymotation的android模拟器运行起来非常快,但是有些项目安装到上面不是crash,log一般是so文件调用失败的信息,或则直接提示INSTALL_FAILED_CPU_ABI_INC ...