python编程之进程
进程:运行中的程序
进程和操作系统的关系:进程是操作系统调度和资源分配的最小单位,是操作系统的结构基础。
那么为什么要有进程呢?
程序在运行时,会使用各种硬件资源,如果他们之间没有界限,那么程序之间的数据必然会产生混乱。所以为了实现资源的隔离,就有了进程的概念。
进程的调度方式:
1,先到先服务算法(FCFS)
先请求的进程就先进行处理。缺点:大作业先到,就会使后面的短作业不能得到及时处理。
2,短作业优先算法
处理起来简短的作业先进行处理。缺点:一些大的作业将会长时间得不到处理。
3,时间片轮转算法
给每个进程分配时间片,然后轮转者进行处理。缺点:一些重要任务将无法及时处理。
4,多级反馈算法
处理分多个级别,由高到低,高级别先执行,但是级别越低分配的时间越长。当一个进程进来时,先按FCFS在最高级别排队,当其在时间片内没有执行完成时,就把它放进下一个级别的,依次类推。因为低级别分配的时间更长,长进程就能得到更多的资源来完成处理。
进程的并行和并发
并行:多核处理器,同时进行多个进程的工作
并发:资源有限的情况下,比如单核处理器,多个进程交替使用资源
区别:并行是真正的同时运行,而并发只是宏观上看起来像是同时运行
进程的同步和异步
同步
import time
from multiprocessing import Process
# multiprocessing模块:综合处理进程的包
def func():
time.sleep(1)
return '同步' if __name__ == '__main__':
p = Process(target=func)
ret = func()
print(ret) # 像这种上个工作完成下面才能进行的,就叫做同步进程
异步
import time
from multiprocessing import Process
# multiprocessing模块:综合处理进程的包
def func():
time.sleep(1)
print('子进程') # 后打印 if __name__ == '__main__':
p = Process(target=func) # 创建一个进程对象 参数target传函数的名字
p.start() # 开始进程
print('父进程') # 先打印 # 像这种只是开始一个进程,而不管其结果,就进行自己接下来的工作的,就是异步进程
阻塞和非阻塞
阻塞:需要等待信息才能继续执行时,是会产生阻塞。例如:input输入时,time.sleep时等。
import time
input('>>>')
print('')
time.sleep(2)
print('')
非阻塞:和阻塞相反的状态。
进程三种状态之间的转换
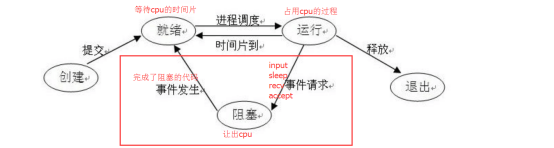
守护进程
守护进程:使守护进程在父进程执行完成后就结束,不会像正常的子进程那样,主进程在执行完成后还要等子进程执行完成。
1,守护进程的开启设置一定要放在进程开启之前
2,守护进程中不能再开启进程
举例
import time
from multiprocessing import Process def func():
while True:
time.sleep(10)
print('过去了10秒') if __name__ == '__main__':
p = Process(target=func)
p.daemon = True # 一定在进程开启之前设置
p.start()
for i in range(100):
time.sleep(1)
print('*'*i)
进程的几个方法和属性查看
# is_alive和terminate
import time
from multiprocessing import Process def func():
print('')
time.sleep(1)
print('') if __name__ == '__main__':
p = Process(target=func)
p.start()
print(p.is_alive()) # True 判断子进程是否还存在
time.sleep(0.1)
p.terminate() # 结束子进程 通过操作系统来完成
time.sleep(1)
print(p.is_alive())
# pid和name 属性查看
from multiprocessing import Process def func():
pass if __name__ == '__main__':
p = Process(target=func)
p.start()
print(p.pid) # 28716 查看子进程的进程id
print(p.name) # Process-1 查看子进程的进程名
进程锁
锁:在并发编程中,保证数据的安全。使多个进程不能同时对数据进行操作,从而造成数据处理逻辑混乱。
来一个买火车票的例子
创建ticket文件,里面模拟序列化内容:{"count": 4},定义4张票。
import time
import random
import json
from multiprocessing import Lock
from multiprocessing import Process def search():
with open('ticket') as f:
print('票数:%d' %json.load(f)['count']) def get(i):
with open('ticket') as f:
ticket_num = json.load(f)['count']
if ticket_num > 0:
time.sleep(random.random())
with open('ticket', 'w') as f:
json.dump({'count': ticket_num-1}, f)
print('%s,买到票了' %i)
else:
print('%s,没有票了' %i) def func(i, lock):
search()
lock.acquire() # 等待人来拿钥匙开门 没有人来就阻塞
get(i)
lock.release() # 处理完事情后离开关上门并放回钥匙 if __name__ == '__main__':
lock = Lock() # 创建一个锁对象
for i in range(10):
p = Process(target=func, args=(i, lock))
p.start()
进程锁实例
信号量
信号量:和进程锁类似它也是限定多进程的并发,但它可以指定能同时进行的进程数,而不单单是一次只能一个。
import time
import random
from multiprocessing import Process
from multiprocessing import Semaphore def func(p, S):
S.acquire() # 和进程锁相同,等待钥匙开门 只是这里同时开了4道门
print('%s办理取钱' %p)
time.sleep(random.randint(1, 10))
S.release() # 和进程锁相同,关门并放回钥匙
print('%s完成办理' %p) if __name__ == '__main__':
sem = Semaphore(4) # 创建一个信号量对象,指定能同时接收的信号量为4
for i in range(20):
Process(target=func, args=(i, sem)).start()
信号量例子
事件
事件:异步阻塞 用于主进程控制其他进程的执行。
1,waite 事件实例化之后默认为阻塞
2,set 将阻塞状态变为非阻塞
3,clear 将非阻塞状态变为阻塞
4,is_set 判断事件的阻塞状态 True为非阻塞 False为阻塞
import time
import random
from multiprocessing import Process
from multiprocessing import Event def traffic_light(e):
while True:
if e.is_set():
time.sleep(3)
print('红灯亮')
e.clear()
else:
time.sleep(3)
print('绿灯亮')
e.set() def car(i, e):
e.wait()
print(i) if __name__ == '__main__':
event = Event() # 创建一个事件对象
Process(target=traffic_light, args=(event,)).start()
for i in range(100):
if i % random.randint(2, 5) == 0:
time.sleep(random.randint(1, 3))
Process(target=car, args=(i, event)).start()
事件例子
队列
队列:先进先出 实现不同进程之间的通信
queue = Queue() 不限定队列的长度 queue = Queue(10) 限定队列的长度为10
1,put 放入数据 当队列有限制且数据放满时,阻塞
2,get 取出数据 当队列为空时,阻塞
import time
from multiprocessing import Process
from multiprocessing import Queue def producer(q):
for i in range(50):
q.put('包子%d' %i) def consumer(q):
while True:
time.sleep(1)
print(q.get()) if __name__ == '__main__':
queue = Queue(10)
Process(target=producer, args=(queue,)).start()
Process(target=consumer, args=(queue,)).start()
队列例子
JoinableQueue
创建可连接的共享进程队列。这就像是一个Queue对象,但队列允许项目的使用者通知生产者项目已经被成功处理。通知进程是使用共享的信号和条件变量来实现的。
JoinableQueue() 实例化后放数据和取数据和队列相同
join:接收数据处理完成后的消息,判断全部完成后再结束进程
task_done:完成处理后告诉对应的数据生产者
import time
import random
from multiprocessing import Process
from multiprocessing import JoinableQueue def producer(q):
for i in range(20):
q.put('数据%d' %i) # 生产数据
time.sleep(random.randint(1, 3))
q.join() # 接收数据处理完成后的消息,全部完成后结束进程 def consumer(q):
while True:
print(q.get()) # 消费数据
q.task_done() # 完成处理后告诉对应的生产者 if __name__ == '__main__':
queue = JoinableQueue()
p1 = Process(target=producer, args=(queue,))
p1.start()
p2 = Process(target=producer, args=(queue,))
p2.start()
c1 = Process(target=consumer, args=(queue,))
c1.daemon = True # 守护进程
c1.start()
c2 = Process(target=consumer, args=(queue,))
c2.daemon = True # 守护进程
c2.start()
c3 = Process(target=consumer, args=(queue,))
c3.daemon = True # 守护进程
c3.start() p1.join() # 阻塞,子进程p1结束后停止阻塞
p2.join() # 阻塞,子进程p2结束后停止阻塞
例子
管道
管道:双向通信 但是数据不安全 相当于没有锁的队列
send:发送数据
recv:接收数据 当管道另一边关闭,且管道中没有内容时就会报错(EOFError)
close: 关闭管道口 一般在进程中用不到的管道口就可以先关闭掉
import time
from multiprocessing import Pipe
from multiprocessing import Process def func1(p):
open1, open2 = p
open2.close()
for i in range(100):
time.sleep(0.1)
open1.send(i)
open1.close() def func(p, i):
open1, open2 = p
open1.close()
while True:
try:
print(i, open2.recv())
except EOFError:
open2.close()
break if __name__ == '__main__':
open1, open2 = Pipe() # 创建一个管道,得到一个元组,里面的两个元素相当于管道的两端
pr1 = Process(target=func1, args=((open1, open2),)).start()
p1 = Process(target=func, args=((open1, open2), 1)).start()
p2 = Process(target=func, args=((open1, open2), 2)).start()
p3 = Process(target=func, args=((open1, open2), 3)).start()
open1.close()
open2.close()
管道例子
进程池
进程池:因为设备的硬件资源有限,所以不能无限的开启进程,更合理的协调进程数和硬件之间的关系,才能拥有更高的数据处理效率
进程池就是为了合理利用资源,减小进程调度难度,节省过多进程开启消耗的时间。
import time
import random
from multiprocessing import Pool
from multiprocessing import Process def func(s):
s += 1 if __name__ == '__main__':
pool = Pool(9) # 进程池对象,参数指定同时处理的进程数,一般是CPU核数加一
start = time.time()
pool.map(func, range(100)) # 循环处理100个任务
pool.close() # 不允许再添加任务
pool.join()
print(time.time() - start) # 0.13385581970214844
start = time.time()
lis = []
for i in range(100):
p = Process(target=func, args=(i,))
p.start()
lis.append(p)
[j.join() for j in lis]
print(time.time() - start) # 2.0339081287384033
进程池和普通进程效率对比
import time
import random
from multiprocessing import Pool
def func(s):
time.sleep(random.randint(1, 3))
s += 1
print(s) if __name__ == '__main__':
pool = Pool(9)
for i in range(10):
ret = pool.apply(func, args=(i,)) # 同步提交任务 可以接收子进程的返回值
print(ret)
print('主进程') # 最后打印
if __name__ == '__main__':
pool = Pool(9)
for i in range(20):
pool.apply_async(func, args=(i,)) # 异步提交任务 也可以接收子进程返回值
pool.close()
pool.join() # 阻塞 否则主进程会直接结束
回调函数
多用于爬虫,处理高I/O操作
import os
from multiprocessing import Pool def func(s):
return s*'*' def call(arg): # 回调函数,在主进程中执行,参数只能接收子进程的返回值
print('回调函数%s' %os.getpid()) # 回调函数20828
print(arg) if __name__ == '__main__':
pool = Pool(5)
print('主进程%s' %os.getpid()) # 主进程20828
for i in range(10):
pool.apply_async(func, args=(i,), callback=call) # callback设置回调函数,将开启的子进程的返回值作为参数传给函调函数
pool.close()
pool.join()
Manger模块
提供多种数据类型用于进程之间的数据共享,但是不够安全
from multiprocessing import Manager
from multiprocessing import Process def func(dic):
dic['count'] -= 1 if __name__ == '__main__':
manager = Manager() # 创建Manager对象
d = manager.dict({'count': 100}) # 对象.数据类型 创建共享数据类型
lis = []
for i in range(100):
p = Process(target=func, args=(d,))
p.start()
lis.append(p)
[j.join() for j in lis]
print(d) # 打印{'count': 2} 数据不安全
python编程之进程的更多相关文章
- python编程系列---进程池的优越性体验
1.通过multiprocessing.Process()类创建子进程 import multiprocessing, time, os, random def work(index): " ...
- Python 多进程编程之 进程间的通信(在Pool中Queue)
Python 多进程编程之 进程间的通信(在Pool中Queue) 1,在进程池中进程间的通信,原理与普通进程之间一样,只是引用的方法不同,python对进程池通信有专用的方法 在Manager()中 ...
- Python 多进程编程之 进程间的通信(Queue)
Python 多进程编程之 进程间的通信(Queue) 1,进程间通信Process有时是需要通信的,操作系统提供了很多机制来实现进程之间的通信,而Queue就是其中的一个方法----这是操作系统开辟 ...
- python并发编程之进程、线程、协程的调度原理(六)
进程.线程和协程的调度和运行原理总结. 系列文章 python并发编程之threading线程(一) python并发编程之multiprocessing进程(二) python并发编程之asynci ...
- python线程和进程编程对比
import timefrom concurrent.futures import ThreadPoolExecutor,as_completedfrom concurrent.futures imp ...
- Python笔记_第四篇_高阶编程_进程、线程、协程_5.GPU加速
Numba:高性能计算的高生产率 在这篇文章中,笔者将向你介绍一个来自Anaconda的Python编译器Numba,它可以在CUDA-capable GPU或多核cpu上编译Python代码.Pyt ...
- python中的进程、线程(threading、multiprocessing、Queue、subprocess)
Python中的进程与线程 学习知识,我们不但要知其然,还是知其所以然.你做到了你就比别人NB. 我们先了解一下什么是进程和线程. 进程与线程的历史 我们都知道计算机是由硬件和软件组成的.硬件中的CP ...
- Python::OS 模块 -- 进程参数
os模块的简介请参看 Python::OS 模块 -- 简介 os模块的文件和目录操作 Python::OS 模块 -- 文件和目录操作 os模块的进程管理 Python::OS 模块 -- 进程管理 ...
- Python::OS 模块 -- 进程管理
os模块的简介参看 Python::OS 模块 -- 简介 os模块的文件相关操作参看 Python::OS 模块 -- 文件和目录操作 os模块的进程参数 Python::OS 模块 -- 进程参数 ...
随机推荐
- Java1.8新特性 - Stream流式算法
一. 流式处理简介 在我接触到java8流式数据处理的时候,我的第一感觉是流式处理让集合操作变得简洁了许多,通常我们需要多行代码才能完成的操作,借助于流式处理可以在一行中实现.比如我们希望对一个包 ...
- 一个不错的插件(软件).NET开发
http://www.gcpowertools.com.cn/products/default.htm 葡萄城 先记录一下!
- span元素和div元素的浮动效果
首先看一段代码: <style> #right {margin: 10px;float:right;color:red;} #left {float:left;color:blue;} & ...
- LintCode_68 二叉树后序遍历
题目 给出一棵二叉树,返回其节点值的后序遍历. 思路 后序比较麻烦 需要另外一个变量来记录当前节点入栈的次数 设计pair<TreeNode*, int> p; p.first 为二叉树节 ...
- Spring_自动组件扫描和 基于注解配置bean
自动组件扫描 启用Spring组件扫描功能. 使用@Component注释来表示这是类是一个自动扫描组件. package com.tanlei.dao; import org.springfram ...
- 大数据技术之Kafka
Kafka概述 1.1 消息队列 (1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除) 点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息 ...
- Directx11教程(50) 输出depth/stencil buffer的内容
原文:Directx11教程(50) 输出depth/stencil buffer的内容 有时候,我们需要查看depth/stencil buffer的内容,比如上一章中,我们要查看sten ...
- Directx11教程(7) 画一个颜色立方体
原文:Directx11教程(7) 画一个颜色立方体 前面教程我们通过D3D11画了一个三角形,本章我们将画一个颜色立方体,它的立体感更强.主要的变动是ModelClass类,在Model ...
- quarts之Cron表达式示例
cron表达式含义及范例如下: 字段名 允许的值 允许的特殊字符 秒 0- ...
- @Transactional注解事务
打了这个注解的类或者方法表示该类里面的所有方法或者这个方法的事务由spring处理,来保证事务的原子性,即方法里面对数据库操作,如果失败则spring负责回滚操作,成功提交操作 一.特性 1.serv ...