吴裕雄--天生自然HADOOP操作实验学习笔记:mapreduce代码编程
实验目的
深入了解mapreduce的底层
了解IDEA的使用
学会通过本地和集群环境提交程序
实验原理
1.回忆mapreduce模型
前面进行了很多基础工作,本次实验是使用mapreduce的API进行简单的大数据业务处理。
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",和它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
mapreduce是一个计算框架,既然是做计算的框架,那么表现形式就是有个输入(input),mapreduce操作这个输入(input),通过本身定义好的计算模型,得到一个输出(output),这个输出就是我们所需要的结果。
我们要学习的就是这个计算模型的运行规则。在运行一个mapreduce计算任务时候,任务过程被分为两个阶段:map阶段和reduce阶段,每个阶段都是用键值对(key/value)作为输入(input)和输出(output)。而程序员要做的就是定义好这两个阶段的函数:map函数和reduce函数。
(1).Mapper
我们自定义的map(映射)需要继承Mapper类,如下面的代码,程序执行顺序是首先执行setup,然后对每一条数据循环遍历执行map方法,最后执行cleanup方法:
static class AppMap extends Mapper<LongWritable, Text, Text, Text> {
@Override
public void setup(Context context) throws IOException {
}
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
}
@Override
protected void cleanup(Context context) throws IOException,
InterruptedException {
}
}
(2).Reducer
和Mapper一样,我们自定义的reduce需要继承Reducer类,如下面的代码,程序执行顺序是首先执行setup,然后对每一个key对应的values循环遍历执行reduce方法,最后执行cleanup方法,下一节会详细解析:
static class AppReduce extends Reducer<Text, Text, Text, NullWritable> {
private ReducerChains<String[], String[]> globalChains = new ReducerChains<String[], String[]>();
@Override
public void setup(Context context) throws IOException,
InterruptedException {
}
@Override
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
}
@Override
protected void cleanup(Context context) throws IOException,
InterruptedException {
}
}
(3).shuffle
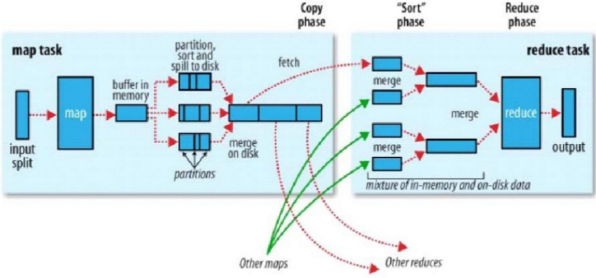
上图为hadoop官方给的shuffle示意图,所有的map输出后,首先会存在内存,或者溢写到磁盘,然后所有的数据会根据分区函数计算出每条记录应该被输入到哪个reduce,每一个reduce的所有数据会根据定义的函数进行分组、排序。shuffle过程是mapreduce的精髓所在。
2.IDEA选择
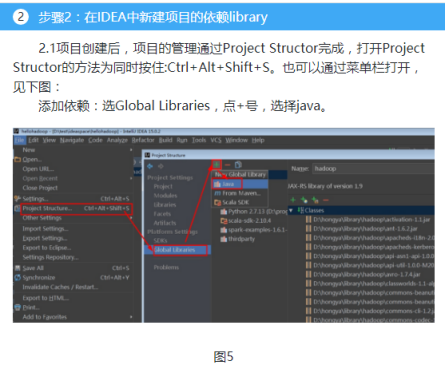
目前写java程序的IDEA注意是Eclipse,但是我们实验选择的是另一个IDEA,这两个IDEA的特点大家可以自行查阅资料,Eclipse管理项目类似于Ant,而IDEA类似于Maven。IDEA功能上比Eclipse更强大,而且后续的Spark无法使用Eclipse完成。我们会介绍如何使用IDEA进行创建项目、编写代码、项目打包发布、本地运行程序。
实验环境
1.操作系统
服务器:Linux_Centos
操作机:Windows_7
服务器默认用户名:root,密码:123456
操作机默认用户名:hongya,密码:123456
2.实验工具
IntelliJ IDEA

IDEA全称IntelliJ IDEA,是java语言开发的集成环境,IntelliJ在业界被公认为最好的java开发工具之一,尤其在智能代码助手、代码自动提示、重构、J2EE支持、Ant、JUnit、CVS整合、代码审查、创新的GUI设计等方面的功能可以说是超常的。IDEA是JetBrains公司的产品,这家公司总部位于捷克共和国的首都布拉格,开发人员以严谨著称的东欧程序员为主。
优点:
1、最突出的功能自然是调试(Debug),可以对Java代码,JavaScript,JQuery,Ajax等技术进行调试。其他编辑功能抛开不看,这点远胜Eclipse。
2、首先查看Map类型的对象,如果实现类采用的是哈希映射,则会自动过滤空的Entry实例。不像Eclipse,只能在默认的toString()方法中寻找你所要的key。
3、其次,需要动态Evaluate一个表达式的值,比如我得到了一个类的实例,但是并不知晓它的API,可以通过Code Completion点出它所支持的方法,这点Eclipse无法比拟。
4、最后,在多线程调试的情况下,Log on console的功能可以帮你检查多线程执行的情况。
缺点:
1、插件开发匮乏,比起Eclipse,IDEA只能算是个插件的矮子,目前官方公布的插件不足400个,并且许多插件实质性的东西并没有,可能是IDEA本身就太强大了。
2、在同一页面中只支持单工程,这为开发带来一定的不便,特别是喜欢开发时建一个测试工程来测试部分方法的程序员带来心理上的不认同。
3、匮乏的技术文章,目前网络中能找到的技术支持基本没有,技术文章也少之又少。
4、资源消耗比较大,建个大中型的J2EE项目,启动后基本要200M以上的内存支持,包括安装软件在内,差不多要500M的硬盘空间支持。(由于很多智能功能是实时的,因此包括系统类在内的所有类都被IDEA存放到IDEA的工作路径中)。
特色功能:
1、智能选择
2、丰富的导航模式
3、历史记录功能
4、JUnit的完美支持
5、对重构的优越支持
6、编码辅助
7、灵活的排版功能
8、XML的完美支持
9、动态语法检测
10、代码检查
等等。
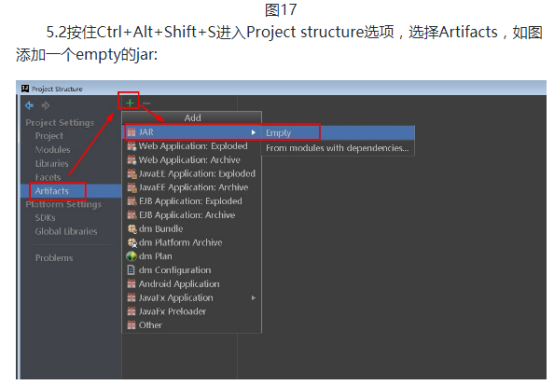
步骤1:准备工作空间,新建项目
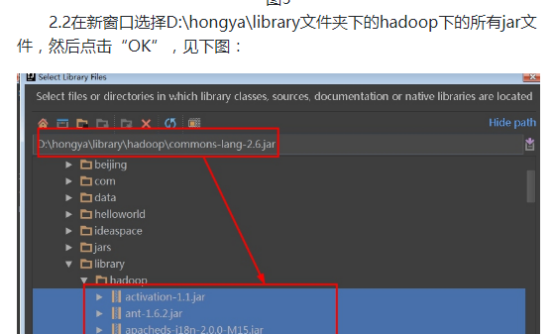
1.1准备工作空间,新建项目(实验中已经有了项目路径D:\hongya,但是为了更好的进行学习,我们可以自己新建一个项目路径D:\test),新建一个目录或者使用已经存在的目录作为工作空间,以后的项目模块都在这个目录下新建,这里新建的是D:\test\ideaspace\;新建一个目录或者使用已经存在的目录,存放以后的各种依赖软件,例如hadoop、spark、kafka等,这里新建的是D:\test\library\;见下图:
之后实验中我们会将hadoop的解压包放在library目录下,我们会将hadoop的依赖包放到一个hadoop目录下。
1.2双击桌面上的idea图标,打开idea工具,如果是第一次打开会提示你进行新建还是导入等操作,如果不是第一次,会显示上次关闭的项目。进入工具之后点击File|new|Project...。
1.3选择java项目,操作机中已经默认为安装好的Java jdk,直接点击“Next”即可。
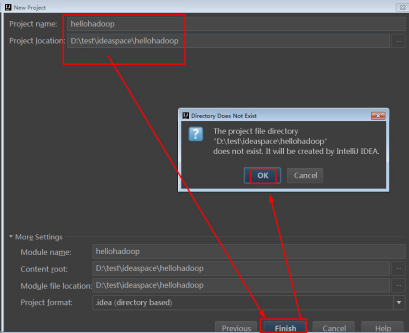
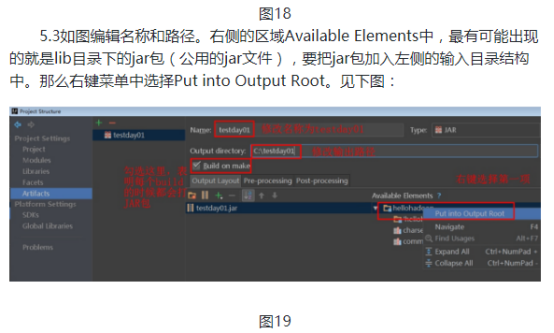
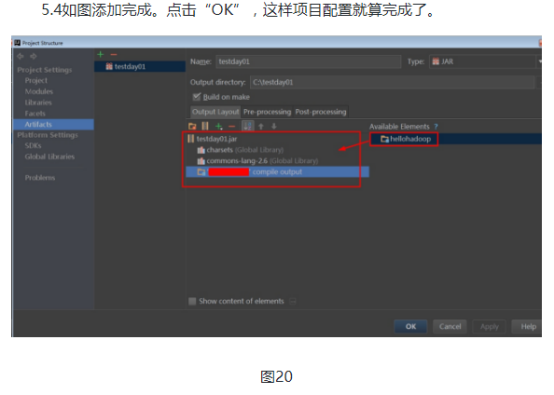
1.4然后出现的一个选择模板页面,不进行选择,直接点击next,进入如下页面,选择项目名称和路径,这里填写名称为“helloHadoop”,保存文件在刚刚创建的文件夹中,点击“finish”,对于弹出框选择“OK”。
项目名称:hellohadoop
项目路径:D:\test\ideaspace\hellohadoop


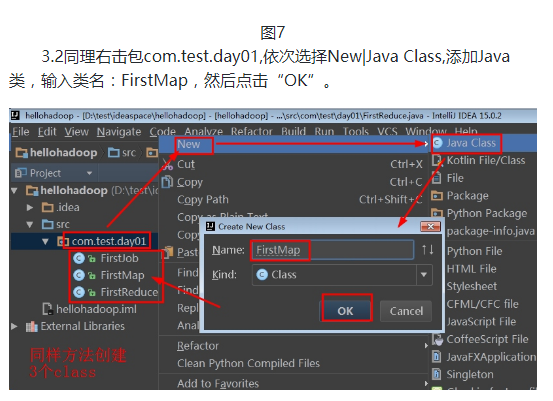
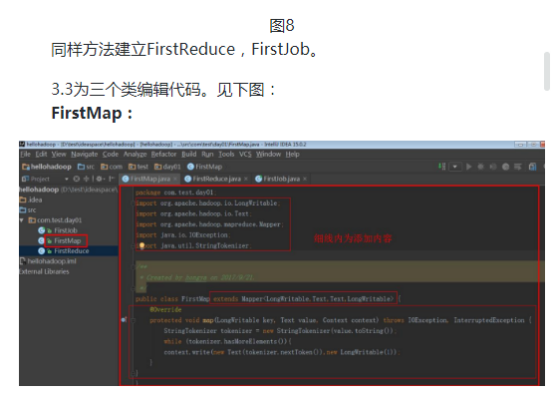
其代码为:
package com.test.day01;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.StringTokenizer;
/**
* Created by hongya on 2017/9/21.
*/
public class FirstMap extends Mapper<LongWritable,Text,Text,LongWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer tokenizer = new StringTokenizer(value.toString());
while (tokenizer.hasMoreElements()){
context.write(new Text(tokenizer.nextToken()),new LongWritable(1));
}
}
}

其代码为:
package com.test.day01;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Created by hongya on 2017/9/21.
*/
public class FirstReduce extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0;
for (LongWritable value : values) {
sum += value.get();
}
context.write(key,new LongWritable(sum));
}
}
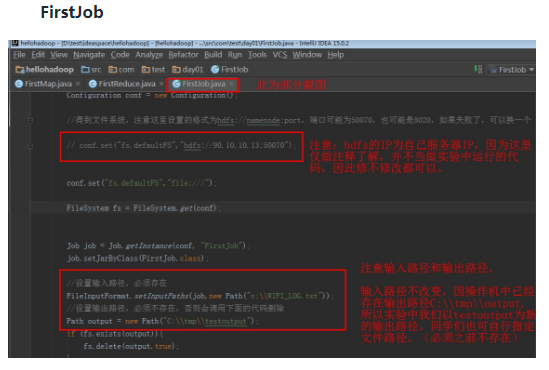

package com.test.day01;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* Created by hongya on 2017/9/21.
*/
public class FirstJob {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//新建配置类
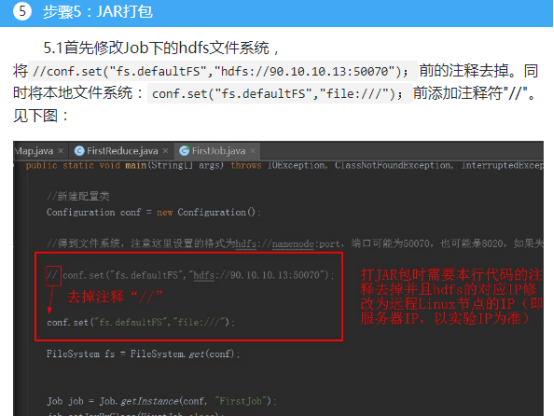
Configuration conf = new Configuration();
//得到文件系统,注意这里设置的格式为hdfs://namenode:port,端口可能为50070,也可能是8020,如果失败了,可以换一个
// conf.set("fs.defaultFS","hdfs://90.10.10.13:50070");
conf.set("fs.defaultFS","file:///");
FileSystem fs = FileSystem.get(conf);
Job job = Job.getInstance(conf, "FirstJob");
job.setJarByClass(FirstJob.class);
//设置输入路径,必须存在
FileInputFormat.setInputPaths(job,new Path("c:\\WIFI_LOG.txt"));
//设置输出路径,必须不存在,否则会调用下面的代码删除
Path output = new Path("C:\\tmp\\testoutput");
if (fs.exists(output)){
fs.delete(output,true);
}
FileOutputFormat.setOutputPath(job, output);
//设置map和reduce的类,为刚刚定义的类
job.setMapperClass(FirstMap.class);
job.setReducerClass(FirstReduce.class);
// 设置输入输出的key、value格式类
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//等待程序执行完成
job.waitForCompletion(true);
}
}
“Ctrl+S”进行保存。
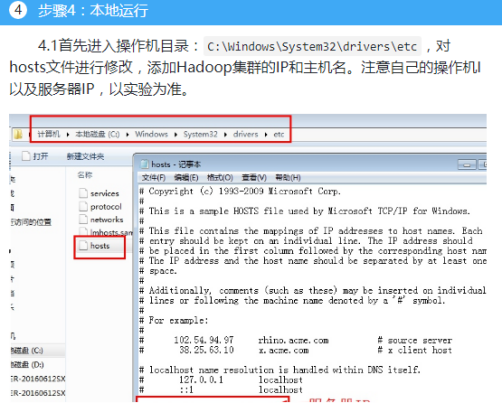

4.2使用xshell连接服务器,连接成功之后输命令开启集群,相关命令如下:(这里就不做截图过多解释,可以参考之前的实验,本次实验主要是在操作机进行,对于集群开启无太多关系,同学们复习一下命令即可)
修改映射为90.10.10.13 standalone
vi /etc/hosts
免密码设置
ssh-keygen
将公钥复制到远程主机上
ssh-coyp-id 90.10.10.13
关闭防火墙
service iptables stop
同步时间
date -s 10:00
进入安装包目录
cd $HADOOP_HOME
开启集群命令
sbin/start-all.sh
查看进程
jps
查看集群是否开启
浏览器输入URL:90.10.10.13:50070
4.3本次试验不必关心太多代码的逻辑,只需要知道每一步的目的和基本设置即可,特别是main方法设置的几个参数必须弄清楚,每个参数的意义可以根据代码的注释进行理解。
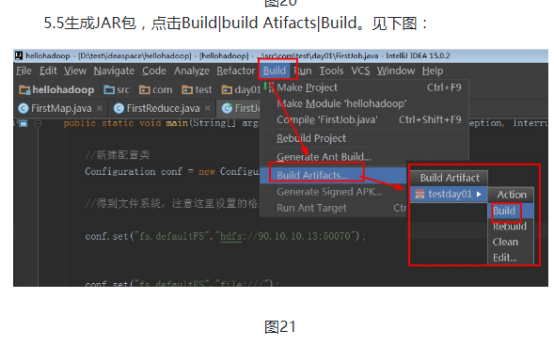
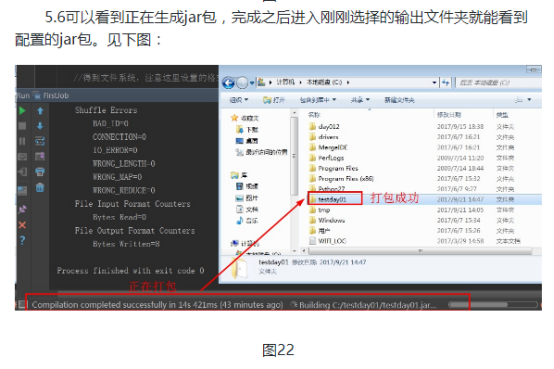
4.4回到IDEA工具,点击RunJob类的main方法左边的绿色三角形运行,提交程序:

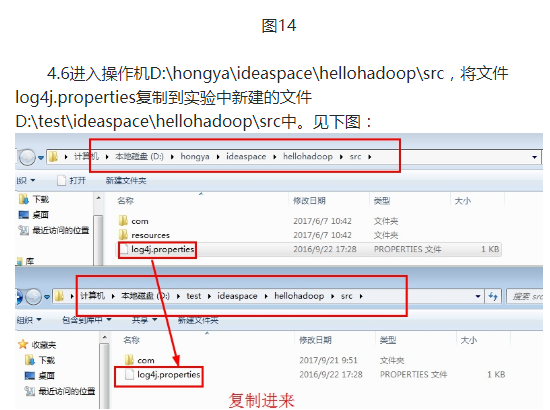
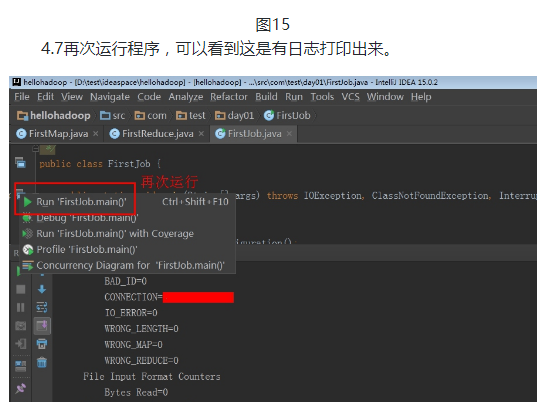
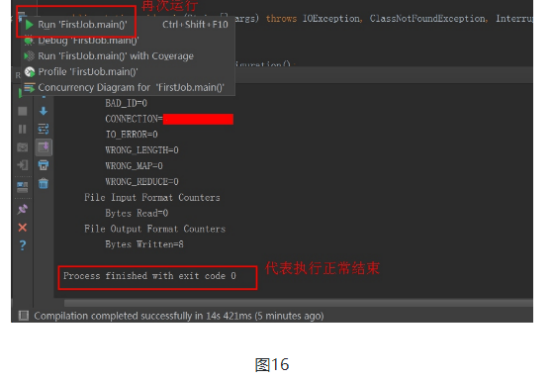
吴裕雄--天生自然HADOOP操作实验学习笔记:mapreduce代码编程的更多相关文章
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hive安装
实验目的 了解hive的原理和安装方式 学习使用MySQL数据库 使用hive进行基本操作 实验原理 1.Hive Hive是一个数据仓库技术,包括解释器.编译器.优化器,一次将一个sql语句装化为m ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:pig简介
实验目的 了解pig的该概念和原理 了解pig的思想和用途 了解pig与hadoop的关系 实验原理 1.Pig 相比Java的MapReduce API,Pig为大型数据集的处理提供了更高层次的抽象 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hadoop框架认识以及基本操作
实验目的 了解Hadoop的概念和原理 学习HDFS架构原理 熟悉mapreduce框架 熟悉mapred和yarn命令 实验原理 1.hadoop和hadoop生态系统 hadoop的思想来源是Go ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:使用hive操作hbase
实验目的 熟悉hive和hbase的操作 熟悉hadoop.hbase.hive.zookeeper的关系 熟练大数据环境的搭建 学会分析日志排除问题 实验原理 1.hive整合hbase原理 前面大 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:分布式及RPC通信简介
实验目的 掌握GOF设计模式的代理模式 了解掌握socket编程.java反射.动态代理 了解NIO.多线程 掌握hadoop的RPC框架使用API 实验原理 1.什么是RPC 在hadoop出现以前 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hbase学生选课案例
实验目的 复习hbase的shell操作和javaAPI操作 了解javaWeb项目的MVC设计 学会dao(数据库访问对象)和service层的代码编写规范 学会设计hbase表格 实验原理 前面我 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hbase的javaAPI应用
实验目的 进一步了解hbase的操作 熟悉使用IDEA进行java开发 熟悉hbase的javaAPI 实验原理 前面已经了解通过hbase的shell操作hbase,确实比较难以使用,另外通过hiv ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hbase的shell应用v2.0
HRegion 当表的大小超过设置值的时候,HBase会自动地将表划分为不同的区域,每个区域包含所有行的一个子集.对用户来说,每个表是一堆数据的集合,靠主键来区分.从物理上来说,一张表被拆分成了多块, ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hive DDL
实验目的 了解hive DDL的基本格式 了解hive和hdfs的关系 学习hive在hdfs中的保存方式 学习一些典型常用的hiveDDL 实验原理 有关hive的安装和原理我们已经了解,这次实验我 ...
随机推荐
- Codeforces_712_B
http://codeforces.com/problemset/problem/712/B 水,判断奇偶即可. #include<iostream> #include<string ...
- TensorFlow中使用GPU
TensorFlow默认会占用设备上所有的GPU以及每个GPU的所有显存:如果指定了某块GPU,也会默认一次性占用该GPU的所有显存.可以通过以下方式解决: 1 Python代码中设置环境变量,指定G ...
- BZOJ 1046 [HAOI2007]上升序列(LIS + 贪心)
题意: m次询问,问下标最小字典序的长度为x的LIS是什么 n<=10000, m<=1000 思路: 先nlogn求出f[i]为以a[i]开头的LIS长度 然后贪心即可,复杂度nm 我们 ...
- 题解【CF1303D Fill The Bag】
\[ \texttt{Preface} \] 不开 long long 见祖宗. \[ \texttt{Description} \] 你有一个 \(n\) 码的袋子,你还有 \(m\) 个盒子,第 ...
- tensorboard的简单使用
1. 首先保证你已有程序,下面是MLP实现手写数字分类模型的代码实现. 不懂的可以对照注释理解. #输入数据是28*28大小的图片,输出为10个类别,隐层大小为300个节点 from tensorfl ...
- golang 引入 和 创建 包
/* 单个包: improt "包目录的路径" 多个包: improt ("包目录的路径", "包目录的路径") improt ( &quo ...
- crul 命令访问公网 dns解析错误 程序报错
今天机房几台服务器都无法访问公网接口,原因是——解析公网域名出错,具体情况如下 ping 公网ip或者域名 都没有问题 curl 公网域名 出错 curl -4 访问公网域名没有问题 综合分析 ...
- Eclipse 无法引用到Maven 解决方法
问题描述:打开Eclipse进入java EE视图下,发现原有的Maven Dependencies目录不存在,显示的是org.maven.ide.eclipse.MAVEN2_CLASSPATH_C ...
- 简单ts文件结构
一.ts文件结构 DEMO{ 1. .vscode:特有文件夹,调试的配置文件,启动浏览器 2. Js:放ts编译后的文件,不管 3. Ts:放ts文件,敲代码 4. tsconfig.json:ts ...
- NOIP幂次方
#include<stdio.h> ] = { ,,,,,,,,,,,,,,, };//由题意n最大为20000,所以最多会用到2的14次方 //为了防止mid+1出错,故写到15次方 i ...