R语言进行广州租房可视化
又到了一年一度的换租房的季节,在广州,想要找到一处好一点的租房真心不容易,不是采光不好,就是价格太贵,怎么才能找到合适自己的房子呢?于是我利用“造数”这个虫工具爬取了安居客网的广州租房的数据,通过分析,期望能找到合适的租房。
一、数据的获取
首先是数据的获取,这里我使用的是一个免费的爬虫工具“造数”,相关的使用方法在该平台上有详细教程,这里就不再赘述。今天要爬取的网站是安居客网的租房数据,页面是这样的:

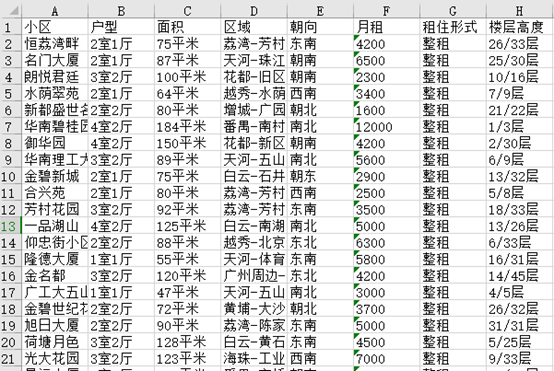
如图红框中所示,本次爬取的数据包含了小区名称、户型、面积、区域、朝向、租住形式、楼层高度等信息,爬取出来的数据是这样子,共计5346行
二、数据的清洗
1、预处理
将数据表通过Navicat导入到MySQL中,在字段中增加单价一列,
#增加单价这一列
ALTER TABLE house
ADD COLUMN 单价int(4) NULL;
UPDATE house SET 单价 = (select round(月租/面积))

2、缺失值的处理
1)“小区”这个字段中的缺失值的行总共6行,考虑到总数据有5346行,占比约为0.1%,且该字段重要性较低,此处选择不处理;
#去除小区为空的值
DELETE from house where 小区isnull
2)“单价”这个字段中,单价等于1元/(㎡*月)的值有4个,缺失率低,查询广州各区的平均租房情况,租房单价1元/(㎡*月)的情况不现实,考虑此字段重要性较高,故选择根据该区的平均单价进行均值填充;
3)“区域”这个字段中含有广州周边城市如佛山、东莞等城市,这样的字段总共有8个,不属于分析的对象,选择剔除这些值;
#去除字段“区域”中非广州地区的数据 8
DELETE from house where 区域like '%周边'
4)“租住形式”这个字段中,由于“合租”这个形式不能反映住房的具体价格情况,此处不属于分析的对象,共计16个,应该从结果中剔除掉,同时,由于剩下的数据均为“整租”形式,该字段没有分析的意义,故应该同时把该字段删除。
#去掉“租住形式”这一字段
alter table house drop column 租住形式
5)为了对房屋面积、单价和月租这样的连续属性进行分组,我在数据集里面增加了四列,分别是面积分组、月租分组和单价分组。
三、数据的概况与分析
1、户型分布
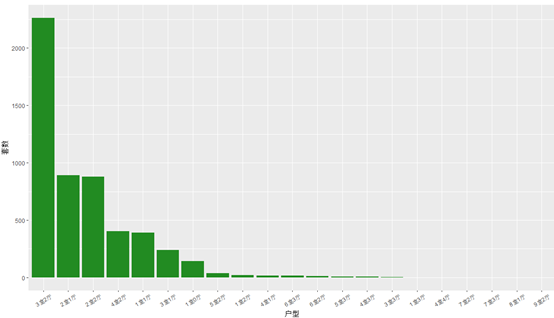
户型分布图
我们发现,只有少数几种户型的数量比较多,其余的都很少,这并不是正态分布,而是比较严重的偏态分布,属于长尾分布,所以,在这里,我们考虑将套数在50以下的户型统一归为一类,命名为“其他”。

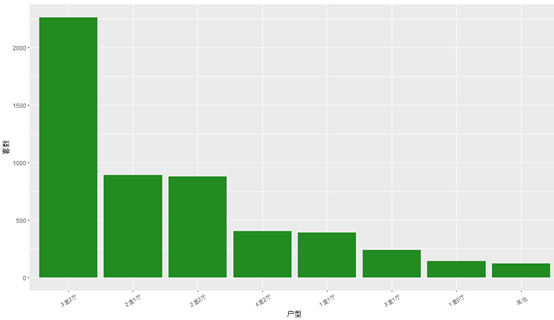
广州租房中房源最多的户型是3室2厅型,而且是远远高于其他,这与当下很多年轻人几个人合租一套大方(3室2厅)的现象相适应,当然也有可能是提供房源的房东有钱,买的就是这种大房。
2、租房面积分布


我们发现,实际上面积范围在50-100平方米的房源最多,超过50%,其次是100-150平方米范围的房源,约占35%,总体超过85%,结合户型的分布为3室2厅的居多可以知道,广州的租房市场中面积在100平方米左右的房源最多。
3、租房区域的分布

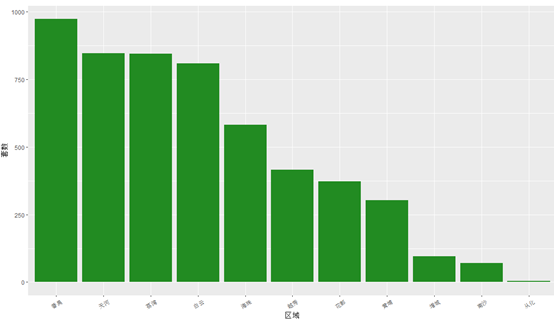
房源最多的地区居然是番禺,其次才是天河与荔湾白云这几个区的房源数量紧随其后。从化的租房市场很冷,只有少数几套房源。
4、租金和单价的分布
作为找租房的人来说,房租是一个特别重要的问题,接下来看一下广州的房租分布是怎样的:



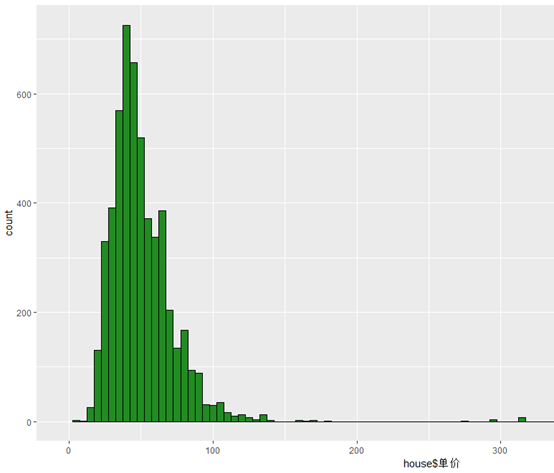
可以看出,广州的房租租金呈现偏态分布,租金主要集中在2000-5500元/月,而单价的分布也是偏态的分布,租金主要集中在25-65元/(平方米*月)。有趣的是有少数的房子租金达到了2万以上,单价也有到300元/(平方米*月)以上的房源,住这么好的房子的人肯定很有生活品质的追求,反正像这种租这么贵的房我是不可能的,这辈子都不可能租这么贵的房子的。
5、楼层的分布

其中,中层的房源占到了44.66%,高层和低层的都在25%~30%的范围内,这和人们的喜好程度有关,一般来说,顶层的房子冬天冷夏天热,低楼层比较潮湿,吵闹,像这种类型的房子,住起来都不是那么舒服,所以住的人就少了,房源也没那么多了。
6、广州各区的租房单价均价分布


租房每平方米单价最贵的前三名毫无意外地出现在了天河、越秀和海珠这三个主城区,都超过了55元/(平方米*月),天河甚至超过了70元/(平方米*月),而单价最低的是增城区,仅为23元/(平方米*月)左右的单价。
7、广州各区的房租均价分布

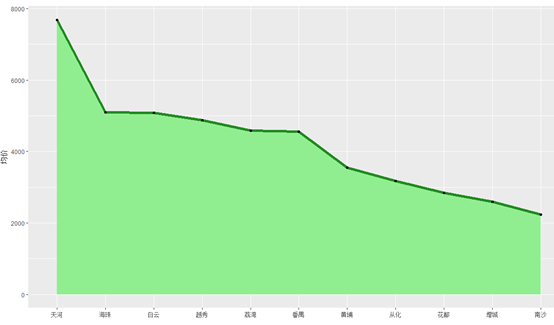
由图可知,天河的租金领跑广州,直逼8000元/月的房租真的让人望而生畏。而第二梯队的海珠、白云、越秀、荔湾和番禺这几个区,也均价也在4500-5200元/月之间,并不便宜,考虑到房源主要是3室2厅的大套房,这个价位也算正常。
四、聚类分析
这么多的房子,我们该如何把它们分类呢?即应该把哪些房源归为一类?这里我们就使用简单而快捷的k-means算法实现聚类的工作。但聚类前,需要明确该聚为几类?根据聚类原则:组内差距要小,组间差距要大。我们绘制不同类簇下的组内离差平方和图,聚类过程中,我们选择面积、月租和单价三个数值型变量:
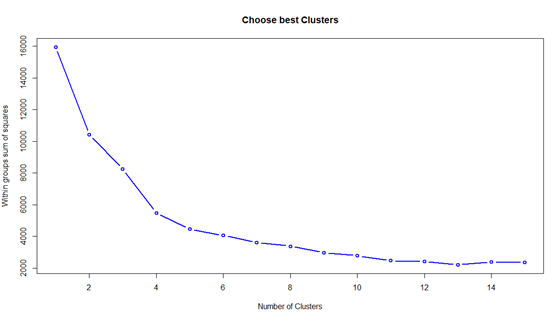
当把所有样本当作一类时,离差平方和达到最大,随着聚类数量的增加,组内离差平方和会逐渐降低,直到极端情况,每一个样本作为一类,此时组内离差平方和为0。从上图看,聚类数量在5次以上,组内离差平方降低非常缓慢,可以把拐点当作6,即聚为6类。

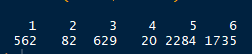
6类房子的数量如上所示。紧接着按照聚类的结果,查看各类中的区域分布:


各户型的平均面积:

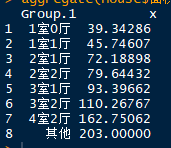
按照聚类结果,比较各类中房子的平均面积和、平均价格和平均单价

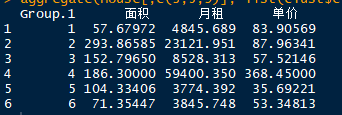
从平均水平来看,我们大体可以将5300多套房源合成为如下几种说法:
a、单身公寓型(1室1厅、2室1厅),属于第1类。平均面积比较小,精装修,所以单价单价也不低,但总租金比较合理,是白领们喜欢的公寓类型,主要分布在天河、越秀等市中心。
b、豪宅型(4室2厅),属于第2类。租金非常高,典型的区域有番禺、白云等地,租金很高,单价也很高,面积超过了250平方米,是典型的豪宅。
c、大户型(4室2厅、3室2厅),属于第3类。典型的区域有天河、番禺等地等地。
d、地段型(面积适中,租金高),属于第4类。典型的区域是天河市中心,在比较好的商业地段,在地铁口的可能性也比较高。
e、大众蜗居型(房源最多,是租房的主流),属于第5类,典型的区域是番禺、荔湾、花都等城郊区域,租金相对来说比较合适,居住条件也相对比较好,是租房人中最青睐的类型。
f、精装小户型(面积较小,租金较低),属于第六类,典型的区域有天河、白云、荔湾、海珠,在海珠和天河的该房类型一般为城中村房经过装修后的,房源也相对来说比较多,是毕业生的首选。
最后绘制面积与单价的散点图,并按聚类进行划分:

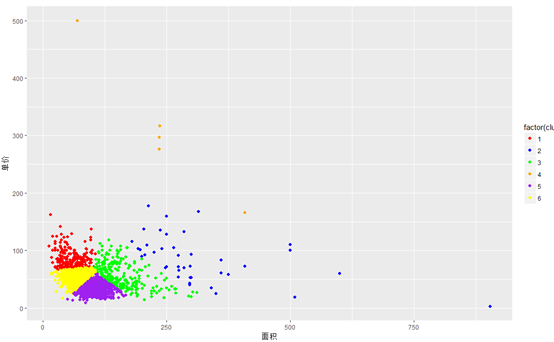
五、总结
通过分析之后得到,租房市场中,比较适合刚毕业不久的学生的房子类型是精装小户型,这样的房子,主要分布在天河、白云、荔湾、海珠,在海珠和天河的该房类型一般为城中村房,相对来说,天河和海珠的居住条件差了些,但好在交通便利,如果不能接受居住条件差一些的,那就需要去到白云和荔湾区区找了,好在现在地铁也有,交通也不算不方便,只是在路上会耽搁一些时间,看个人取舍了。今天就到了啦。
R语言进行广州租房可视化的更多相关文章
- 利用R语言进行交互数据可视化(转)
上周在中国R语言大会北京会场上,给大家分享了如何利用R语言交互数据可视化.现场同学对这块内容颇有兴趣,故今天把一些常用的交互可视化的R包搬出来与大家分享. rCharts包 说起R语言的交互包,第一个 ...
- R语言学习笔记 之 可视化地研究参议员相似性
基于相似性聚类 很多时候,我们想了解一群人中的一个成员与其他成员之间有多么相似.例如,假设我们是一家品牌营销公司,刚刚完成了一份有潜力新品牌的研究调查问卷.在这份调查问卷中,我们向一群人展示了新品牌的 ...
- 用R语言完成的交通可视化报告
http://sztocc.sztb.gov.cn/roadcongmore.aspx最终实现这几个图:1. 实时道路交通可视化2. 实时道路拥堵排名3. 历史路况时间序列图4. 每日每小时道况热力图 ...
- [2]R语言在数据处理上的禀赋之——可视化技术
本文目录 Java的可视化技术 R的可视化技术 二维做图利器plot的参数配置 *权限机制 *plot独有的参数 *plot的type介绍 *title介绍 *公共参数集合--par *par的权限机 ...
- 数据分析和R语言的那点事儿_1
最近遇到一些程序员同学向我了解R语言,有些更是想转行做数据分析,故开始学习R或者Python之类的语言.在有其他编程语言的背景下,学习R的语法的确是一件十分简单的事.霸特,如果以为仅仅是这样的话那就图 ...
- 第六篇:R语言数据可视化之数据分布图(直方图、密度曲线、箱线图、等高线、2D密度图)
数据分布图简介 中医上讲看病四诊法为:望闻问切.而数据分析师分析数据的过程也有点相似,我们需要望:看看数据长什么样:闻:仔细分析数据是否合理:问:针对前两步工作搜集到的问题与业务方交流:切:结合业务方 ...
- 第五篇:R语言数据可视化之散点图
散点图简介 散点图通常是用来表述两个连续变量之间的关系,图中的每个点表示目标数据集中的每个样本. 同时散点图中常常还会拟合一些直线,以用来表示某些模型. 绘制基本散点图 本例选用如下测试数据集: 绘制 ...
- 第四篇:R语言数据可视化之折线图、堆积图、堆积面积图
折线图简介 折线图通常用来对两个连续变量的依存关系进行可视化,其中横轴很多时候是时间轴. 但横轴也不一定是连续型变量,可以是有序的离散型变量. 绘制基本折线图 本例选用如下测试数据集: 绘制方法是首先 ...
- 第三篇:R语言数据可视化之条形图
条形图简介 数据可视化中,最常用的图非条形图莫属,它主要用来展示不同分类(横轴)下某个数值型变量(纵轴)的取值.其中有两点要重点注意: 1. 条形图横轴上的数据是离散而非连续的.比如想展示两商品的价格 ...
随机推荐
- NX二次开发-设置WCS位置UF_CSYS_set_wcs
NX9+VS2012 UF_initialize(); //输入X向量Y向量输出一个3*3矩阵 ] = {0.0, 0.0, 1.0}; ] = {0.0, 1.0, 0.0}; ]; UF_MTX3 ...
- 【latex】latex基础
文档边距.间距调整 边距调整 \usepackage{geometry} %设置页边距的宏包 \geometry{left=3.0cm,right=2.5cm,top=2.5cm,bottom=2.5 ...
- hdu多校第五场1006 (hdu6629) string matching Ex-KMP
题意: 给你一个暴力匹配字符串公共前缀后缀的程序,为你对于某个字符串,暴力匹配的次数是多少. 题解: 使用扩展kmp构造extend数组,在扩展kmp中,设原串S和模式串T. extend[i]表示T ...
- mysql数据库中的索引介绍与优化(转)
一.什么是索引? 索引用来快速地寻找那些具有特定值的记录,所有MySQL索引都以B-树的形式保存.如果没有索引,执行查询时MySQL必须从第一个记录开始扫描整个表的所有记录,直至找到符合要求的记录.表 ...
- Java--会移动、反弹的球
package firstpack; import java.awt.*; public class MyStar { public static void main(String[] args) { ...
- IK 用java 代码实现分词
需要导入IK 对应的jar 包 IKAnalyzer2012.jar lucene-core-4.10.jar public static void main(String[] args) throw ...
- tcp_tw_recycle和tcp_timestamps的一些知识(转)
现在很多公司都用LVS做负载均衡,通常是前面一台LVS,后面多台后端服务器,这其实就是NAT,当请求到达LVS后,它修改地址数据后便转发给后端服务器,但不会修改时间戳数据,对于后端服务器来说,请求的源 ...
- jdk源码阅读
转载https://www.cnblogs.com/mh-study/p/10078548.html 1.java.lang 1) Object 12) String 13) AbstractStri ...
- 自学之linux的基本命令
cd cd 用于进入指定文件夹 cd ..用于回到上个文件夹 ls ls用于列出文件夹里的所有元素 ls/home/ 列出home文件夹的元素 ls -l 可以看到文件名,拥有者是谁,什么时候修改的 ...
- Red and Black 模板题 /// BFS oj22063
题目大意: Description There is a rectangular room, covered with square tiles. Each tile is colored eithe ...