solr添加IK分词和自己定义词库
下载IK分词IK Analyzer 2012FF_hf1.zip
下载地址:http://yunpan.cn/cdvATy8899Lrw (提取码:c10d)
1、将IKAnalyzer2012FF_u1.jar包上传到服务器,复制到solr-4.10.4/example/solr-webapp/webapp/WEB-INF/lib目录下
2、在solr-4.10.4/example/solr-webapp/webapp/WEB-INF目录下创建目录classes,然后把IKAnalyzer.cfg.xml和stopword.dic拷贝到新创建的classes目录下即可
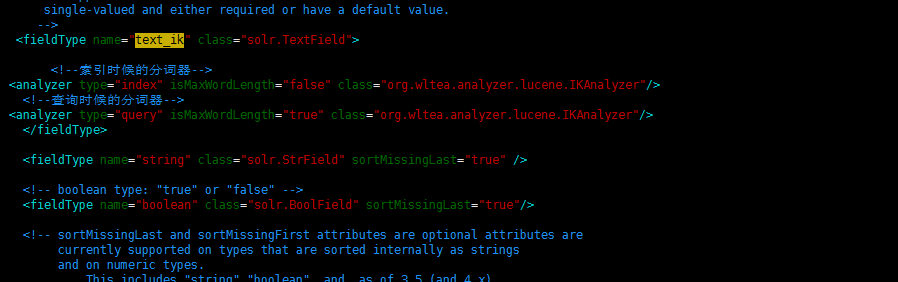
3:修改solr core的schema文件,默认是solr-4.10.4/example/solr/collection1/conf/schema.xml,添加如下配置
<fieldType name="text_ik" class="solr.TextField">
<!--索引时候的分词器-->
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<!--查询时候的分词器-->
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
4、启动solr集群

自定义词库
到sougou 下载对应的词库:http://pinyin.sogou.com/dict/
由于sougou 下载后的文件是scel 格式不能直接用,需要用工具转化下格式,推荐使用深蓝工具,下载地址
http://yunpan.cn/cmuyuQhCasFMR (提取码:6432)

然后将文件格式转化为dic结尾的。词库的文件格式必需是:无BOM的UTF-8格式,分词库可以为多个,以分号隔开即可。
将下载的词库复制到/home/hadoop/cloudsolr/solr-4.10.4/example/solr-webapp/webapp/WEB-INF/classes目录下

修改配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典
<entry key="ext_dict">ext.dic;</entry>
-->
<entry jey = "mingxing">mingxing.scel</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry> </properties>
重启solr集群
测试结果:
这样分词有一个问题:分词方式是按照maxword 的方式
集群启动的时候主节点不会报错。从节点会报错

配置文件信息如下:
IK的lib文件已经上传

改配置的都配置了,启动还是报错:
{msg=SolrCore 'collection1' is not available due to init failure: Could not load conf for core collection1: Plugin init failure for [schema.xml] fieldType "text_ik": Cannot load analyzer: org.wltea.analyzer.lucene.IKAnalyzer. Schema file is /configs/myconf/schema.xml,trace=org.apache.solr.common.SolrException: SolrCore 'collection1' is not available due to init failure: Could not load conf for core collection1: Plugin init failure for [schema.xml] fieldType "text_ik": Cannot load analyzer: org.wltea.analyzer.lucene.IKAnalyzer. Schema file is /configs/myconf/schema.xml
at org.apache.solr.core.CoreContainer.getCore(CoreContainer.java:745)
at org.apache.solr.servlet.SolrDispatchFilter.doFilter(SolrDispatchFilter.java:347)
问题原因:
配置了IK分词后,没有同步到zk,删掉zkdata 里面的数据重新启动zk即可
solr添加IK分词和自己定义词库的更多相关文章
- [Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例二.
为了更好的排版, 所以将IK分词器的安装重启了一篇博文, 大家可以接上solr的安装一同查看.[Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例一: http://ww ...
- Solr:Slor初识(概述、Windows版本的安装、添加IK分词器)
1.Solr概述 (1)Solr与数据库相比的优势 搜索速度更快.搜索结果能够按相关度排序.搜索内容格式不固定等 (2)Lucene与Solr的区别 Lucene提供了完整的查询引擎和索引引擎,目的是 ...
- python jieba分词(结巴分词)、提取词,加载词,修改词频,定义词库 -转载
转载请注明出处 “结巴”中文分词:做最好的 Python 中文分词组件,分词模块jieba,它是python比较好用的分词模块, 支持中文简体,繁体分词,还支持自定义词库. jieba的分词,提取关 ...
- [Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例一.
在这里一下讲解着三个的安装和配置, 是因为solr需要使用tomcat和IK分词器, 这里会通过图文教程的形式来详解它们的安装和使用.注: 本文属于原创文章, 如若转载,请注明出处, 谢谢.关于设置I ...
- Solr和IK分词器的整合
IK分词器相对于mmseg4J来说词典内容更加丰富,但是没有mmseg4J灵活,后者可以自定义自己的词语库.IK分词器的配置过程和mmseg4J一样简单,其过程如下: 1.引入IKAnalyzer.j ...
- Solr——配置IK分词器
首先需要的准备好jdk1.8和tomcat8以及ik分词器(ik分词器是5.x的版本,和solr4.10搭配的版本不一样,虽然是5.x的版本但是也是能使用在solr7.2版本上的) 分享链接https ...
- SCWS中文分词,向xdb词库添加新词
SCWS是个不错的中文分词解决方案,词库也是hightman个人制作,总不免有些不尽如人意的地方.有些词语可能不会及时被收入词库中. 幸好SCWS提供了词库XDB导出导入词库的工具(phptool_f ...
- [Linux] linux下安装配置 zookeeper/redis/solr/tomcat/IK分词器 详细实例.
今天 不知自己装的centos 出现了什么问题, 一直卡在 启动界面, 找了半天没找见原因(最后时刻还是发现原因, 只因自己手欠一怒之下将centos删除了, 而且选择的是在本地磁盘也删除. ..让我 ...
- Solr添加paoding分词器
1.Solr3.6.2 并可运行 paoding-analysis3.0.jar 下载 2.1 解压{$Solr-Path}/example/webapp 下的solr.war文件,解压到当前文件夹 ...
随机推荐
- robotium学习
20140424 控件种类:spinner:下拉菜单,可以选择:TabHost:可以左右滑动,比如电话本:Gallery:rogressbar进度条;DatePicker;CheckBox,Radio ...
- __iomem作用
最近在看网卡驱动时查看ioremap函数发现调用最低层用__iomem修饰了ioremap的第一个参数(unsigned int)ioremap(S3C24XX_PA_CS8900, SZ_1M) + ...
- 2019杭电多校第三场hdu6606 Distribution of books(二分答案+dp+权值线段树)
Distribution of books 题目传送门 解题思路 求最大值的最小值,可以想到用二分答案. 对于二分出的每个mid,要找到是否存在前缀可以份为小于等于mid的k份.先求出这n个数的前缀和 ...
- mysql优化3:BTree索引和Hash索引
一.BTree索引 注:名叫btree索引,大的方面看,都用的平衡树,但具体的实现上,各引擎稍有不同,比如,严格地说,NDB引擎使用的是T-tree,Myisam和innodb中默认用B-tree索引 ...
- JOGL图形形状
图形对象 要访问程序特定于硬件和操作系统平台,以及其他语言编写,比如C和C++(原生应用)库,Java使用一种称为Java本地接口(JNI)编程框架的工作. JOGL内部使用此接口,如图中下面的图表来 ...
- 用户态和内核态&操作系统
用户态和内核态 内核态:cpu可以访问内存的所有数据,包括外围设备,例如硬盘,网卡,cpu也可以将自己从一个程序切换到另一个程序. 用户态:只能受限的访问内存,且不允许访问外围设备,占用cpu的能力被 ...
- 多个串的最长公共子串 SPOJ - LCS2 后缀自动机
题意: 求多个串的最长公共子串 这里用的是O(n)的后缀自动机写法 我后缀数组的专题有nlog(n)写法的 题解: 对于其中的一个串建立后缀自动机 然后对于后缀自动机上面的每一个节点求出每一个节点最长 ...
- runtime和runloop问答
Runtime 01 问题: objc在向一个对象发送消息时,发生了什么? 解答: 根据对象的 isa 指针找到类对象 id,在查询类对象里面的 methodLists 方法函数列表,如果没有在好到, ...
- opencv2.4.9+vs2012安装配置
需要下载并安装vs2012 http://pan.baidu.com/s/1qXP76CO 第一次启动会提示要求输入激活序列号,请输入:YKCW6-BPFPF-BT8C9-7DCTH-QXG ...
- 随笔记录 yum -y clean all出错解决方案
出现以下问题的解决方案: 使用解决方案之前,要先确定一下几种情况: 1.检查光盘是否挂载 2.ISO映像文件是否使用正确 解决方案1: rm -rf /var/cache/yum/* yum repo ...