避坑之Hadoop安装伪分布式(Hadoop3.2.0/Ubuntu14.04 64位)
一.安装JDK环境(这个可以网上随意搜一篇教程了照着弄,这里不赘述)
安装成功之后
输入
输入:java -version
显示如下说明jdk安装成功(我这里是安装JDK8)

二.安装Hadoop3.2.0
1、官网下载http://mirror.bit.edu.cn/apache/hadoop/common/
2、安装
A.解压
sudo tar xzf hadoop-3.2.0.tar.gz
B.假如我们要把hadoop安装到/usr/local下
C.拷贝到/usr/local/下,文件夹为hadoop
sudo mv hadoop-3.2.0 /usr/local/hadoop
D.赋予用户对该文件夹的读写权限
sudo chmod 774 /usr/local/hadoop
三.配置Hadoop(JDK和Hadoop的路径)
1.配置~/.bashrc
输入:sudo gedit ~/.bashrc
添加如下代码:

之后保存退出
2.执行下面命名,使添加的环境变量生效:(如果报错,请看下面避坑一)
source ~/.bashrc
3.判断Hadoop是否安装成功
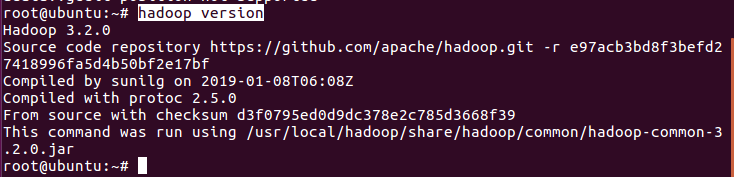
出现版本信息,说明成功
四,,接下来进行配置伪分布式(上面的Hadoop只是单机模式)
4.1修改hadoop配置文件
4.1.1修改配置文件core-site.xml(使用gedit etc/hadoop/core-site.xml).将configuration节点添加子节点,修改为下面内容:
<configuration>
<!--指定fs的缺省名称-->
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<!--指定HDFS的(NameNode)的缺省路径地址,localhost:是计算机名,也可以是ip地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录(以个人为准) -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
ps:如果没有该目录:/usr/local/hadoop/tmp,需要自己新建
4.1.2修改配置文件hdfs-site.xml(使用gedit etc/hadoop/hdfs-site.xml).将configuration节点添加子节点,修改为下面内容:
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/hdfs/data</value>
</property>
</configuration>
ps:如果没有该目录:/usr/local/hadoop/hdfs/name,需要自己新建
ps:如果没有该目录:/usr/local/hadoop/hdfs/data,需要自己新建
4.1.3 etc/hadoop目录下查看是否有配置文件mapred-site.xml。目录下默认情况下没有该文件,可通过执行如下命令:cp mapred-site.xml.template mapred-site.xml修改一个文件的命名,然后执行编辑文件命令:gedit mapred-site.xml并修改该文件内容:
<configuration>
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
4.1.4在etc/hadoop目录下执行gedit yarn-site.xml修改为:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
4.2同样使用source ~/.bashrc命令使配置文件生效。(如果报错,请看下面避坑一)
五:Hadoop的运行
5.1格式化namenode
第一次运行格式化namennode。执行hdfs namenode -format命令。
5.2启动hadoop hdfs (如果报错,请看避坑二)
执行start-dfs.sh命令。
5.3启动yarn ( 如果报错,请看避坑二)
执行start-yarn.sh命令。
5.4查看运行进程
使用jps命令,查看运行中java进程

六.web管理界面
6.1MapReduce管理界面:http://localhost:8088/
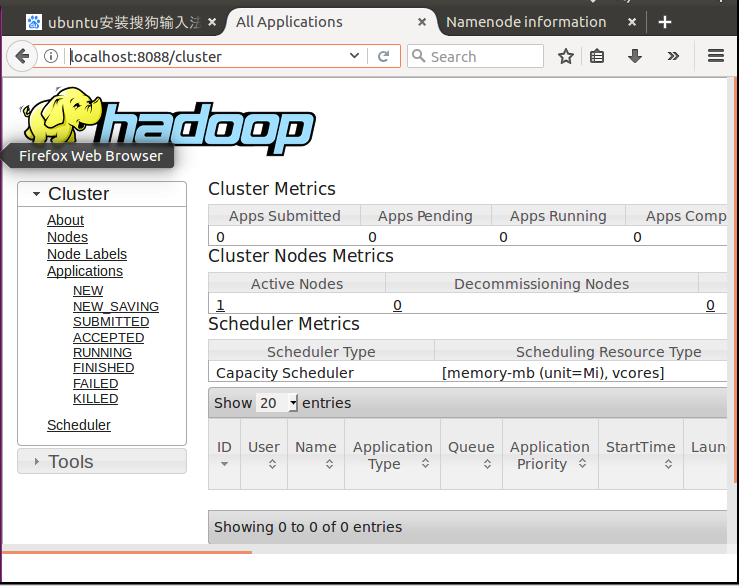
6.2HDFS管理界面:http://localhost:50070/
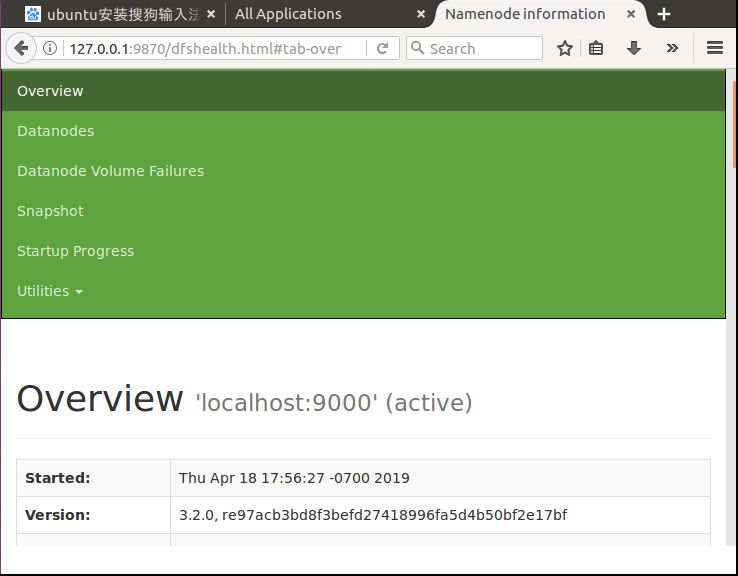
如果显示如下页面,请看避坑三

七.退出
可执行stop-all.sh 命令,一次性关闭所有hadoop进程,也可以通过stop-dfs.sh stop-yarn.sh分别关闭进程
避坑一:bashrc命令报错
两种方法解决此问题:
1.在当前用户下添加环境变量:将环境变量添加到文件:~/.bashrc下,
然后source ~/.bashrc即可。
2.首先进入root用户:sudo su -或者sudo -s,
然后将环境变量添加到/etc/profile或者/root/.bashrc或者/etc/bash.bashrc文件,然后source该文件即可。
避坑二:start-dfs.sh或者start-yarn.sh报错
报错如下

在/hadoop/sbin路径下:
将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
还有,start-yarn.sh,stop-yarn.sh顶部也需添加以下
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
修改后重启 ./start-dfs.sh,成功!

修改后重启 ./start-yarn.sh

避坑三:localhost:50070报错
hadoop3.X的webUI已经改到端口 localhost:9870
避坑之Hadoop安装伪分布式(Hadoop3.2.0/Ubuntu14.04 64位)的更多相关文章
- Ubuntu14.04 64位机上安装cuda8.0 cudnn5.0操作步骤 - 网络资源是无限的
查看Ubuntu14.04 64位上显卡信息,执行: lspci | grep -i vga lspci -v -s 01:00.0 nvidia-smi 第一条此命令可以显示一些显卡的相关信息:如果 ...
- Ubuntu14.04(64位)安装ATI_Radeon_R7_M265显卡驱动
电脑型号:Dell inspiron 14-5447 笔记本 显卡配置:集成显卡Intel核心显卡,Cpu是i5-4210U;独立显卡ATI_Radeon_R7_M265 网上关于ATI/Intel双 ...
- ubuntu14.04 64位 安装Tomcat
ubuntu14.04 64位 安装Tomcat 1 下载Tomcat 在htt://www.tomcat.apache.org官网上下载apache-tomcat-7.0.57.tar.gz 2 解 ...
- ubuntu14.04 64位 安装eclipse
ubuntu14.04 64位 安装eclipse 1 在官网上下载eclipse http://www.eclipse.org/downloads/下载eclipse-jee-luna-SR1-li ...
- ubuntu14.04 64位 安装JDK1.7
ubuntu14.04 64位 安装JDK1.7 1 新建文件夹 youhaidong@youhaidong:~$ sudo mkdir /usr/lib/jvm 2 解压文件 youhaidong@ ...
- Ubuntu14.04 64位机上安装OpenCV2.4.13(CUDA8.0)版操作步骤
Ubuntu14.04 64位机上安装CUDA8.0的操作步骤可以参考http://blog.csdn.net/fengbingchun/article/details/53840684,这里是在已经 ...
- Ubuntu14.04 64位机上安装cuda8.0+cudnn5.0操作步骤
查看Ubuntu14.04 64位上显卡信息,执行: lspci | grep -i vga lspci -v -s 01:00.0 nvidia-smi 第一条此命令可以显示一些显卡的相关信息:如果 ...
- ubuntu14.04 64位安装H3C iNode客户端
环境: OS:ubuntu14.04LTS 64位 iNode: iNode2.40-R0162 for linux(iNode只有32位的,而且是很久以前的版本) 安装方法: 第一种: 检查本机是6 ...
- ubuntu14.04 64位 安装H3C iNode客户端
环境: OS: ubuntu14.04LTS 64位 iNode: iNode2.40-R0162 for linux(iNode只有32位的,而且是很久以前的版本) 安装方法: 第一种: 主要参考 ...
随机推荐
- python面试的100题(18)
函数 52.python常见的列表推导式? 列表推导式书写形式: [表达式 for 变量 in 列表] 或者 [表达式 for 变量 in 列表 if 条件] 参考地址:https://www.cnb ...
- Java类、方法、属性等
java是面向对象的编程语言 Object,就是指面向对象的对象,对象就是类的具体实例. 在java里,对象是类的一个具体实例.就像:人,指一个类.张三.李四.王五等则是一个个具体的实例,也就是jav ...
- 组合数取mod
组合数取mod 条件mod是质数,inv 是逆元,fac是阶层: 用于n在10^5左右 maxn=100505: ll fact[maxn],inv[maxn]; ll Pow(ll x,ll n){ ...
- SQLserver各种时间取值格式
叫大哥 SQLServer提取日期中的年月日及其他格式 SQLServer提取日期中的年月日及其他格式 提取年:datepart(yy,getdate())提取月:datepart(mm,getd ...
- C++——绪论
计算机语言的发展 1.机器语言(二进制).汇编语言.比较难以理解和识记,与人类语言之间的差距太大: 2.高级语言,可以写出类似于人类思维的语句,可以有人们习惯的表达方式: 3.面向对象的语言,描述客观 ...
- SpringBoot集成flowable碰见DMN不能初始化
在idea创建了SpringBoot项目,集成flowable,运行的时候DMN引擎初始化失败,花了一天时间也没解决. 抱着试试的态度重新建立一个项目,加入同样的依赖,成功运行. 但把成功运行的项目配 ...
- Safari 导航栏
目录 引子 隐藏 Safari 导航栏 显示 Safari 导航栏 iPhone 系统占比 参考资料 引子 最近在 iPhone 的 Safari 查看 h5 页面时,发现有些平台的页面向下滚动时,顶 ...
- mysql-sql逻辑查询顺序
1.sql逻辑执行顺序(物理执行顺序可能会因索引而不同) SELECT 7 DISTINCT 8 FROM 1 JOIN 2 ON 3 WHERE 4 GROUP BY 5 ...
- AcWing 906. 区间分组
//1.将所有区间按左端点从小到大排序 //2.从前往后处理每个区间,判断能否将其放到某个现有的组中 //判断某一组的最后一个区间的右端点是否小于该区间的左端点 //如果大于或等于,就开新组,如果小于 ...
- D. Easy Problem dp(有衔接关系的dp(类似于分类讨论) )
D. Easy Problem dp(有衔接关系的dp(类似于分类讨论) ) 题意 给出一个串 给出删除每一个字符的代价问使得串里面没有hard的子序列需要付出的最小代价(子序列不连续也行) 思路 要 ...