1,HDFS体系结构
··· HDFS是采用master/slaves即主从结构模型来管理数据的。这种模型主要由四部分组成,分别是Client、NameNode、DataNode、SecondaryNameNode。一个HDFS集群包括一个 NameNode(HA除外)和若干个 DataNode以及一个SecondaryNameNode。其中,NameNode是名称节点,负责管理HDFS的文件命名空间和处理client的请求。DataNode负责保存实际的数据,并负责管理客户端的读写请求,在NameNode的调度下进行数据的增删改查和复制;DataNode会定期向NameNode发送心跳包来汇报自己的存活信息和块的信息。用户在使用Client进行 I/O操作时,与使用普通文件系统一样,但是在HDFS内部,HDFS会将存入的文件进行分块并保存在若干个DataNode上。SecondaryNameNode负责帮助把NameNode上的edit文件合并到fsimage文件,再发送给NameNode,实现冷备份。
2,HDFS组件
··· NameNode
· 管理系统的命名空间,并用fsimage和edit来保存。
· 在内存中保存块的位置信息。
· 实施副本冗余策略,以及处理客户端的请求。
··· DataNode
· 保存实际的数据。
· 提供数据的读写。
· 心跳机制(3秒)。汇报自身信息和数据信息。
··· SecondaryNameNode
· 帮助NameNode合并fsimage和edit文件。
· 实现冷备份。
· 检查点机制。
··· Client
· 为用户访问HDFS提供接口。可以不属于HDFS集群。
· 与NameNode交互,获取文件块的位置。
· 与DataNode交互,读写数据。
· 上传时分块,读取时分片。
3,HDFS工作机制
··· 心跳机制
· DataNode通过心跳机制向NameNode汇报自身存活信息(3秒);启动时会汇报数据块信息,此后每隔一个小时汇报一次
· NameNode通过心跳机制向DataNode发送指令。
· NameNode启动后会开启一个IPC服务,等待DataNode节点连接。DataNode启动后就会主动连接。
· 如果主节点长时间没有收到从节点发来的信息,就会认为从节点挂了。
· 超时时间:2*recheck + 10*heartbeat;recheck默认是5分钟,heartbeat默认是30秒,所以超时时间为10分钟30秒。
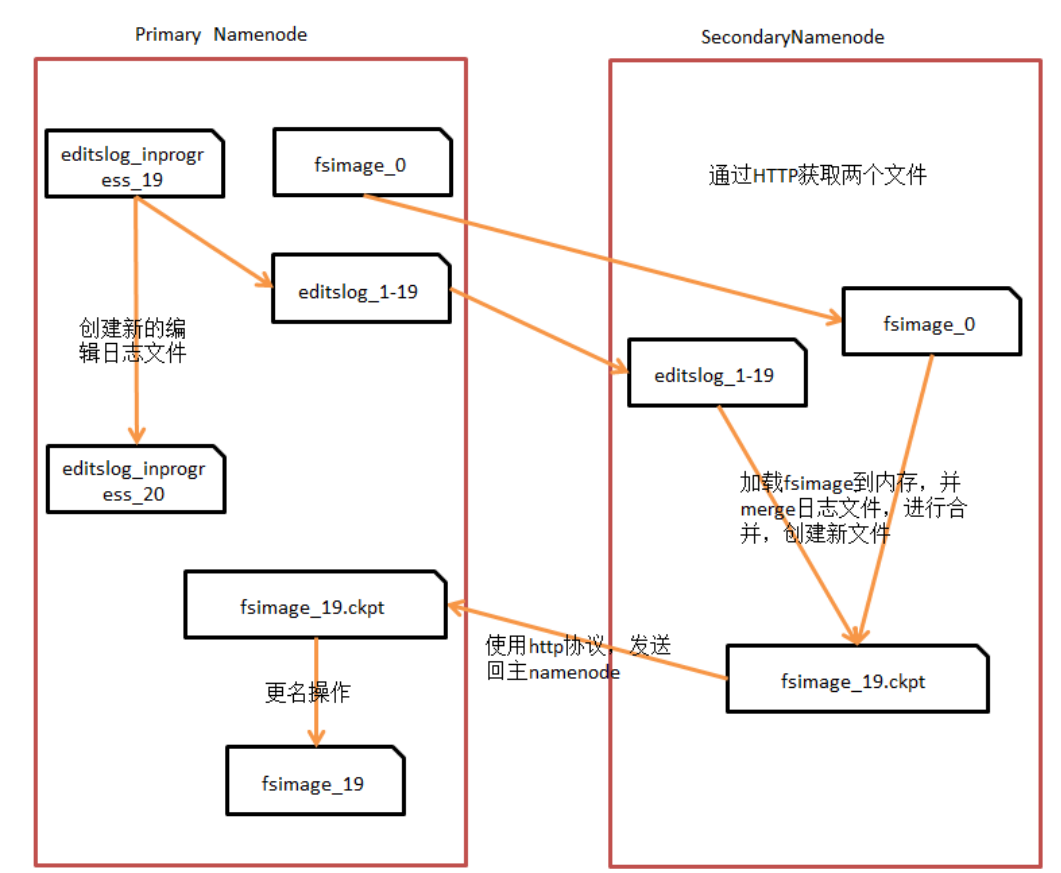
··· 检查点机制
· SecondaryNameNode负责合并fsimage和edit文件;减少edit文件大小,缩短启动时间,更快的推出安全模式。
· 两个文件的合并周期,称之为检查点机制。
· 在hdfs-site.xml中配置。默认1个小时合并一次;或者txid执行次数达到100万次,每1小时检查一次txid文件。
··· 机架感知
· 在部署hadoop集群时,节点之间的距离会影响数据备份的速度。
· 第一个副本在client所在的节点,如果client在集群外,则随机选一个。
· 第二个副本与第一个副本在不同的机架,节点随机选一个。
· 第三个副本与第二个副本在同一个机架,但是在不同的节点。
4,HDFS启动过程
··· NameNode启动时会将fsimage读入内存,然后执行editLog文件中的各项操作,使内存中的元数据保持最新。然后创建一个新的fsimage文件和一个空的editLog文件,此后的操作都写入新的editLog文件中。在这个过程中NameNode处于安全模式,只能对外提供读操作,不能进行写操作;启动结束后就可以进入正常状态,可读写。
··· 集群模式启动时会启动slaves文件中记录的主机中的DataNode进程。DataNode启动时会主动向NameNode发送自己保存的块的信息,此后每隔一个小时发送一次。
5,读数据流程
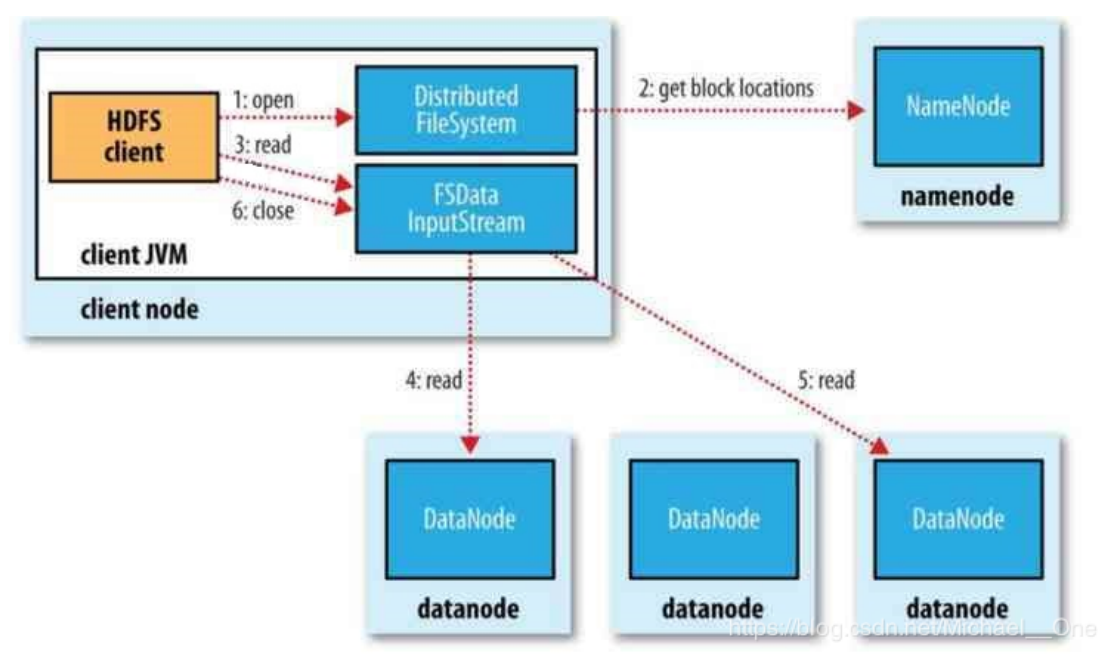
··· 1,client通过FileSystem对象的open方法来打开要读取的文件(编写的代码),对于HDFS来说,这个对象是DistributedFileSystem,他通过RPC调用NameNode,来确定文件起始块的位置。
··· 2,对于每一个块,NameNode会返回存有该块的DataNode的地址,并按照距离client的远近来排序。
··· 3,DistributedFileSystem是的实例会返回一个FSDataInputStream对象给client,以便读取数据;然后client就可以调用FSDataInputStream实例的read方法来获取数据。
··· 4,FSDataInputStream随即连接与第一个块距离最近的DataNode,通过反复调用read方法将数据从DataNode传输到client;当传输到块的末端时,FSDataInputStream关闭与DataNode的连接,并寻找下一个块的最佳DataNode。
··· 5,读取时是按块读取的,当client读取完成时就会调用FSDataInputStream的close方法。
··· 6,如果读取的过程中出现错误,数据损坏,则会到其他DataNode副本上读取数据,并将损坏的DataNode汇报给NameNode。
6,写数据流程
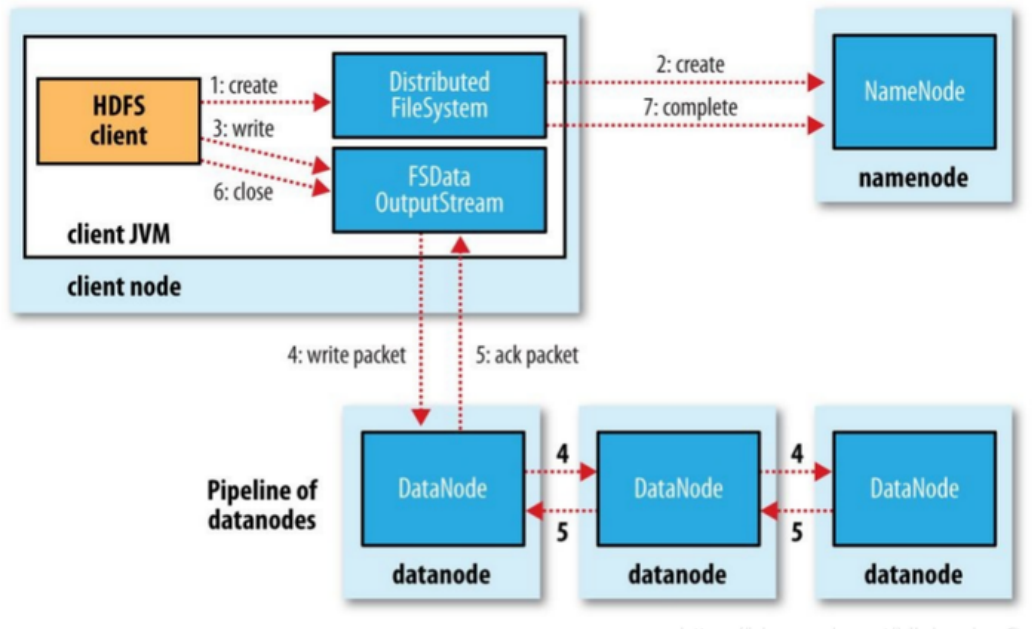
··· 1,client通过FileSystem对象的create方法来创建一个新文件;对于hdfs系统,DistributedFileSystem对NameNodeRPC创建一个RPC调用,在文件系统的命名空间中新建一个文件,此时该文件中还没有相应的数据块。
··· 2,NameNode执行各种不同的检查,以确保这个文件不存在,以及客户端有创建文件的权限。如果检查失败则向客户端抛出一个IOException;如果成功,则DistributedFileSystem向客户端返回一个FSDataOutputStream对象,于是客户端就可以开始写数据了。
··· 3,客户端在写入数时,FSOutputStream将它分成一个个数据包(packet),并写入内部的 数据队列(data queue)。DataStreamer线程负责处理数据队列,向NameNode请求上传一个block(0~128M),NameNode这时会为这个文件分配一个数据块,并返回给客户端一组DataNode。
··· 4,以默认3个副本为例,这三个DataNode会构成一个管道;DataStreamer将数据流式传输到管道中的第一个DataNode的内存中,这个DataNode在把数据包写入到本地磁盘的同时,会将这个数据包发送到第二个DataNode;同样,第二个DataNode也会发送给第三个DataNode。DateStreamer在将一个个packet流式传输到第一个DataNode后,还会将此packet移动到 确认队列(ack queue)中。DataNode写入数据成功后,会向ResponseProcessor线程发送一个成功的信息回执,当收到所有DataNode的确认信息后,ResponseProcessor线程会将该数据包从确认队列中删除。
··· 5,如果任何DataNode在写入数据时发生故障。首先会关闭管道,然后把确认队列中的所有数据移动到数据队列中的最前端,以确保故障节点下游DataNode的不会漏掉 任何一个数据包;为一个正常的DataNode的当前数据块创建一个标识,并把该标识传给NameNode,以便故障DataNode在恢复后可以删除保存的部分数据块;删除故障的DataNode,正常的两个DataNode构成新的管道,并把余下的数据写入新的管道中;NameNode发现副本不足,会在一个新的DataNode上创建副本。
7,DataStreamer线程与Packet
··· 1,client会写数据到流内部的一个缓冲区中,然后数据被分成多个packet,每个packet的大小是64k字节;而每个packet又由一组chunk和这组chunk对应得checksum组成,每个chunk大小为512字节,而checksum是对chunk计算的校验和。
··· 2,当client写入的流数据达到一个packet的长度时,这个packet就会被构建出来,然后放入dataQueue队列中;然后DataStreamer会不断的从dataQueue队列中取出packet,发送到DataNode管道中的第一个DataNode,并将该packet从dataQueue队列移动到ackQueue队列。
··· 创建packet:client写数据时,当长度满足一个chunk大小(512B)时,便会创建一个packet对象,然后向packet对象中写checksum和实际数据;每满足一个chunk时就会向packet对象中写入上诉信息;直到 达到一个packet大小(64KB),就会将该packet放入dataQueue队列中,等待DataStreamer线程取出。
注意事项
· client(客户端)就是我们写代码所在的机器,可以不属于HDFS集群。
· HDFS中的分块是实际的物理分块,而MapReduce中的分片是逻辑分片。
· hdfs中不适合存储小文件,因为一个块的元数据大约为150字节,1亿个块无论大小都会占用20G左右的内存。
· 由于fsimage的访问承受能力有限,所以先把修改操作保存到edit文件,再在空闲时合并到fsimage。
· hdfs的安全模式相当于维护模式,不允许添加和修改hdfs上的文件。默认是关闭的可以通过hdfs dfsadmin -safemode enter打开(enter | leave | get | wait)。
· NameNode的fsimage不会保存块在哪个DataNode,即NameNode不会在磁盘中保存块的位置信息,而是在每次启 动时由DataNode汇报块的信息,然后NameNode将这些信息保存在内存中。
- HDFS原理介绍
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.是根据google发表的论文翻版的.论文为GFS(Google File System)Googl ...
- HDFS 原理、架构与特性介绍--转载
原文地址:http://www.uml.org.cn/sjjm/201309044.asp 本文主要讲述 HDFS原理-架构.副本机制.HDFS负载均衡.机架感知.健壮性.文件删除恢复机制 1:当前H ...
- Hadoop之HDFS原理及文件上传下载源码分析(上)
HDFS原理 首先说明下,hadoop的各种搭建方式不再介绍,相信各位玩hadoop的同学随便都能搭出来. 楼主的环境: 操作系统:Ubuntu 15.10 hadoop版本:2.7.3 HA:否(随 ...
- Hadoop之HDFS原理及文件上传下载源码分析(下)
上篇Hadoop之HDFS原理及文件上传下载源码分析(上)楼主主要介绍了hdfs原理及FileSystem的初始化源码解析, Client如何与NameNode建立RPC通信.本篇将继续介绍hdfs文 ...
- 【Hadoop】HDFS原理、元数据管理
1.HDFS原理 2.元数据管理原理
- HDFS 原理、架构与特性介绍
本文主要讲述 HDFS原理-架构.副本机制.HDFS负载均衡.机架感知.健壮性.文件删除恢复机制 1:当前HDFS架构详尽分析 HDFS架构 •NameNode •DataNode •Senc ...
- HDFS原理及操作
1 环境说明 部署节点操作系统为CentOS,防火墙和SElinux禁用,创建了一个shiyanlou用户并在系统根目录下创建/app目录,用于存放 Hadoop等组件运行包.因为该目录用于安装had ...
- hadoop学习之HDFS原理
HDFS原理 HDFS包括三个组件: NameNode.DataNode.SecondaryNameNode NameNode的作用是存储元数据(文件名.创建时间.大小.权限.与block块映射关系等 ...
- 读Hadoop3.2源码,深入了解java调用HDFS的常用操作和HDFS原理
本文将通过一个演示工程来快速上手java调用HDFS的常见操作.接下来以创建文件为例,通过阅读HDFS的源码,一步步展开HDFS相关原理.理论知识的说明. 说明:本文档基于最新版本Hadoop3.2. ...
- 【转载】经典漫画讲解HDFS原理
分布式文件系统比较出名的有HDFS 和 GFS,其中HDFS比较简单一点.本文是一篇描述非常简洁易懂的漫画形式讲解HDFS的原理.比一般PPT要通俗易懂很多.不难得的学习资料. 1.三个部分: 客户 ...
- 临近年关,修复ASPNETCore因浏览器内核版本引发的单点登陆故障
临近年关,咨询师提出360,搜狗急速浏览器无法单点登陆到公司核心产品WD, 报重定向过多. 现象 经过测试, 出现单点登陆故障的是搜狗,360等主打双核(默认Chrome内核)的浏览器, 较新式的Ed ...
- 2019CSP初赛游记
Day 0 作为一个初三的小蒟蒻…… 对于J+S两场比赛超级紧张的…… 教练发的神奇的模拟卷…… 我基本不会…… 就这样吧…… Day 1 Morning 不知道怎么就进了考场…… 周围坐的全是同学( ...
- Java入门 - 语言基础 - 11.switch_case
原文地址:http://www.work100.net/training/java-switch-case.html 更多教程:光束云 - 免费课程 switch_case 序号 文内章节 视频 1 ...
- 做.net的成为 微软mvp 是一个目标吧。
mvp 的评比 需要好多好多 绩效考核 比如博客排名,比如发表的文章数.
- selenium,测试套件的使用
学习 selenium-webdriver 已经一段时间了,最近学习到,测试用例的批量执行,和测试套件的使用,有点自己的理解,不晓得对不对,希望大家指正! 写一个测试用例 baidu.py c ...
- os模块常用方法笔记
os模块是程序和系统文件之间的交互接口,可以实现对文件的创建.删除等功能,以下对os模块的功能做一个笔记,方便以后学习和查找. import os os.getcwd() #获取当前工作目录,即当前p ...
- URL各部分详解
就以下面这个URL为例,介绍下普通URL的各部分组成 http://www.aspxfans.com:8080/news/index.asp?boardID=5&ID=24618&pa ...
- ArrayList.subList方法使用总结
ArrayList.subList方法使用总结 示例 List<String> list=new ArrayList<>(); list.add("d"); ...
- BP的matlab实现
%2015.04.26 Kang Yongxin ----v 2.0 %完成作业中BP算法,采用批量方式更新权重 %% %输入数据格式 %x 矩阵 : 样本个数*特征维度 %y 矩阵 :样本个数*类别 ...
- linux --- 杀掉特定端口进程与启用SSH服务
Linux下端口被占用解决 有时候关闭软件后,后台进程死掉,导致端口被占用.下面以JBoss端口8083被占用为例,列出详细解决过程. 解决方法: 1.查找被占用的端口 netstat -tln ne ...