Python爬取mc皮肤【爬虫项目】
PS:另外很多人在学习Python的过程中,往往因为遇问题解决不了或者没好的教程从而导致自己放弃,为此我整理啦从基础的python脚本到web开发、爬虫、django、数据挖掘等【PDF等】需要的可以进Python全栈开发交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目可拿,不懂的问题有老司机解决哦,一起相互监督共同进步
import requests
import re
import time
import json
download_sucess = True
time.sleep(1.5)
pictures = input('你想下载多少张皮肤:')
while pictures.isdigit() == False:
print("请输入数字!")
pictures = input('你想下载多少张皮肤:')
Path = input('请输入保存的路径:')
print("请稍等......")
pictures = int(pictures)
for i in range(1,pictures+1):
url = 'https://littleskin.cn/skinlib/data?filter=skin&uploader=0&sort=likes&keyword=&page=' + str(i)
response = requests.get(url).json()
ids = re.findall("'tid': (.*?),",str(response))
for id in ids:
picture_url = 'https://littleskin.cn/preview/' + id + '.png'
picture_name = picture_url.strip('https://littleskin.cn/preview/')
picture = requests.get(picture_url).content
try:
with open(Path + '//%s'%picture_name,'wb') as file:
file.write(picture)
except FileNotFoundError:
download_sucess = False
print('路径不存在!')
break
if download_sucess == False:
print("下载失败!")
elif download_sucess == True:
print('下载完成!')最终效果:
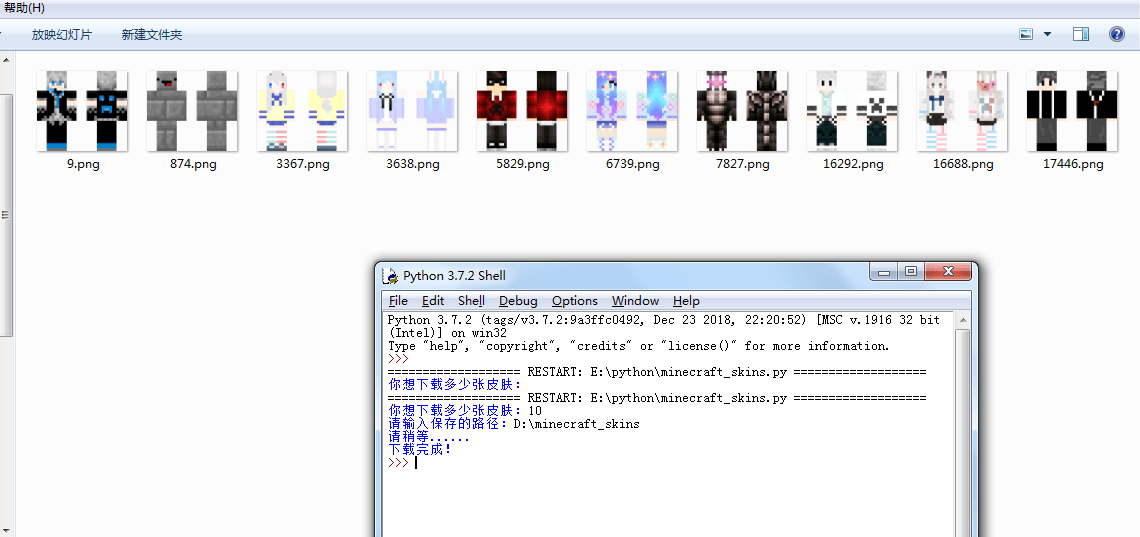
皮肤爬取的原理是通过 json 格式来查看网站的每一张图片的 id 号,再用拼接的方式组成一个图片地址,最后再用二进制的方式把图片存放在我们的文件夹里。希望各位能通过这篇文章学到东西。
总结:很多人在学习Python的过程中,往往因为遇问题解决不了或者没好的教程从而导致自己放弃,为此我整理啦从基础的python脚本到web开发、爬虫、django、数据挖掘等【PDF等】需要的可以进Python全栈开发交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目可拿,不懂的问题有老司机解决哦,一起相互监督共同进步
本文的文字及图片来源于网络加上自己的想法,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
Python爬取mc皮肤【爬虫项目】的更多相关文章
- 利用python爬取海量疾病名称百度搜索词条目数的爬虫实现
实验原因: 目前有一个医疗百科检索项目,该项目中对关键词进行检索后,返回的结果很多,可惜结果的排序很不好,影响用户体验.简单来说,搜索出来的所有符合疾病中,有可能是最不常见的疾病是排在第一个的,而最有 ...
- Python爬取LOL英雄皮肤
Python爬取LOL英雄皮肤 Python 爬虫 一 实现分析 在官网上找到英雄皮肤的真实链接,查看多个后发现前缀相同,后面对应为英雄的ID和皮肤的ID,皮肤的ID从00开始顺序递增,而英雄ID跟 ...
- 爬虫实战(二) 用Python爬取网易云歌单
最近,博主喜欢上了听歌,但是又苦于找不到好音乐,于是就打算到网易云的歌单中逛逛 本着 "用技术改变生活" 的想法,于是便想着写一个爬虫爬取网易云的歌单,并按播放量自动进行排序 这篇 ...
- Python爬取 | 王者荣耀英雄皮肤海报
这里只展示代码,具体介绍请点击下方链接. Python爬取 | 王者荣耀英雄皮肤海报 import requests import re import os import time import wi ...
- 【Python爬虫案例】用Python爬取李子柒B站视频数据
一.视频数据结果 今天是2021.12.7号,前几天用python爬取了李子柒的油管评论并做了数据分析,可移步至: https://www.cnblogs.com/mashukui/p/1622025 ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- 萌新学习Python爬取B站弹幕+R语言分词demo说明
代码地址如下:http://www.demodashi.com/demo/11578.html 一.写在前面 之前在简书首页看到了Python爬虫的介绍,于是就想着爬取B站弹幕并绘制词云,因此有了这样 ...
- Python爬取招聘信息,并且存储到MySQL数据库中
前面一篇文章主要讲述,如何通过Python爬取招聘信息,且爬取的日期为前一天的,同时将爬取的内容保存到数据库中:这篇文章主要讲述如何将python文件压缩成exe可执行文件,供后面的操作. 这系列文章 ...
- Python爬取豆瓣《复仇者联盟3》评论并生成乖萌的格鲁特
代码地址如下:http://www.demodashi.com/demo/13257.html 1. 需求说明 本项目基于Python爬虫,爬取豆瓣电影上关于复仇者联盟3的所有影评,并保存至本地文件. ...
随机推荐
- 吴裕雄--天生自然HADOOP操作实验学习笔记:分布式资源调度系统yarn的安装
实验目的 复习配置hadoop初始化环境 复习配置hdfs的配置文件 学会配置hadoop的配置文件 了解yarn的原理 实验原理 1.yarn是什么 前面安装好了hdfs文件系统,我们可以根据需求进 ...
- 分享10个免费或便宜的Photoshop替代工具
说到编辑照片和图像文件,一般很多人都使用photoshop软件.然而,使用现在的最新版本Photoshop CC每月最低也要支付980日元,感觉使用门槛有点高的人应该不少吧. 有一篇文章,推荐了10个 ...
- 一键安装最新内核并开启 BBR 脚本
最近,Google 开源了其 TCP BBR 拥塞控制算法,并提交到了 Linux 内核,从 4.9 开始,Linux 内核已经用上了该算法.根据以往的传统,Google 总是先在自家的生产环境上线运 ...
- 获取WEB图片
public string GetJpgFile(string strFileServerPath ,string strReportDir) { string strPath = "&qu ...
- JS实现简易计算器的7种方法
先放图(好吧比较挫) 方法一:最容易版 <!DOCTYPE html> <html lang="zh-CN"> <head> <meta ...
- 【spring boot】SpringBoot初学(3)– application配置和profile隔离配置
前言 github: https://github.com/vergilyn/SpringBootDemo 说明:我代码的结构是用profile来区分/激活要加载的配置,从而在一个project中写各 ...
- Jekyll 摘要
在 Windows 上安装 Requirements Permalink Ruby version 2.4.0 or above, including all development headers ...
- JAVA8List排序,(升序,倒序)
List<Integer> integerList = Arrays.asList(4, 5, 2, 3, 7, 9); List<Integer> collect = int ...
- Mysql 出现许多问号的问题
建数据库的时候,已经选择了编码格式为UTF-8 但是用PDM生成的脚本导进去的时候却奇怪的发现表和表的字段的编码格式却是GBK,一个一个却又觉得麻烦,在网上找了一下办法 一个是修改表的编码格式的 AL ...
- 最短路-B - 六度分离
B - 六度分离 1967年,美国著名的社会学家斯坦利·米尔格兰姆提出了一个名为“小世界现象(small world phenomenon)”的著名假说,大意是说,任何2个素不相识的人中间最多只隔着6 ...