Spark学习之路 (五)Spark伪分布式安装[转]
JDK的安装
JDK使用root用户安装
上传安装包并解压
[root@hadoop1 soft]# tar -zxvf jdk-8u73-linux-x64.tar.gz -C /usr/local/配置环境变量
[root@hadoop1 soft]# vi /etc/profile#JAVA
export JAVA_HOME=/usr/local/jdk1.8.0_73
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH:$HOME/bin 验证Java版本
[root@hadoop1 soft]# java -version配置配置ssh localhost
检测
正常情况下,本机通过ssh连接自己也是需要输入密码的

生成私钥和公钥秘钥对
[hadoop@hadoop1 ~]$ ssh-keygen -t rsa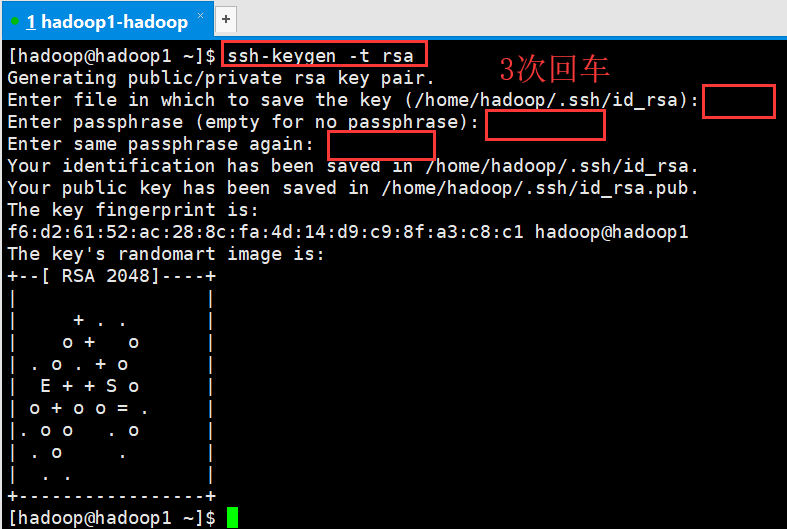
将公钥添加到authorized_keys
[hadoop@hadoop1 ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys赋予authorized_keys文件600的权限
[hadoop@hadoop1 ~]$ chmod 600 ~/.ssh/authorized_keys 修改Linux映射文件(root用户)
[root@hadoop1 ~]$ vi /etc/hosts
验证
[hadoop@hadoop1 ~]$ ssh hadoop1
此时不需要输入密码,免密登录设置成功。
安装Hadoop
使用hadoop用户
上传解压缩
[hadoop@hadoop1 ~]$ tar -zxvf hadoop-2.7.5-centos-6.7.tar.gz -C apps/创建安装包对应的软连接
为解压的hadoop包创建软连接
[hadoop@hadoop1 ~]$ cd apps/
[hadoop@hadoop1 apps]$ ll
总用量 4
drwxr-xr-x. 9 hadoop hadoop 4096 12月 24 13:43 hadoop-2.7.5
[hadoop@hadoop1 apps]$ ln -s hadoop-2.7.5/ hadoop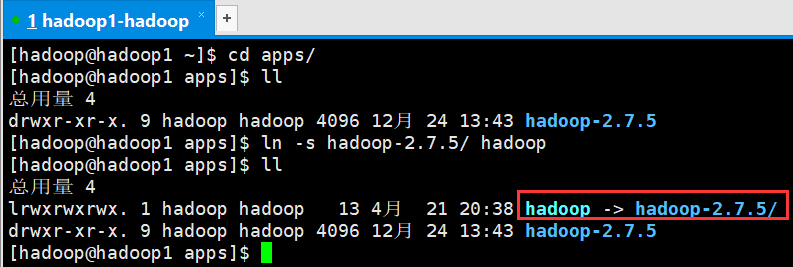
修改配置文件
进入/home/hadoop/apps/hadoop/etc/hadoop/目录下修改配置文件
(1)修改hadoop-env.sh
[hadoop@hadoop1 hadoop]$ vi hadoop-env.sh export JAVA_HOME=/usr/local/jdk1.8.0_73 
(2)修改core-site.xml
[hadoop@hadoop1 hadoop]$ vi core-site.xml <configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/hadoopdata</value>
</property>
</configuration>
(3)修改hdfs-site.xml
[hadoop@hadoop1 hadoop]$ vi hdfs-site.xml dfs的备份数目,单机用1份就行
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/hadoopdata/name</value>
<description>为了保证元数据的安全一般配置多个不同目录</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/hadoopdata/data</value>
<description>datanode 的数据存储目录</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
<description>HDFS 的数据块的副本存储个数, 默认是3</description>
</property>(4)修改mapred-site.xml
[hadoop@hadoop1 hadoop]$ cp mapred-site.xml.template mapred-site.xml
[hadoop@hadoop1 hadoop]$ vi mapred-site.xmlmapreduce.framework.name:指定mr框架为yarn方式,Hadoop二代MP也基于资源管理系统Yarn来运行 。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>(5)修改yarn-site.xml
[hadoop@hadoop1 hadoop]$ vi yarn-site.xml <property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>YARN 集群为 MapReduce 程序提供的 shuffle 服务</description>
</property>配置环境变量
千万注意:
1、如果你使用root用户进行安装。 vi /etc/profile 即可 系统变量
2、如果你使用普通用户进行安装。 vi ~/.bashrc 用户变量
#HADOOP_HOME
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.7.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:使环境变量生效
[hadoop@hadoop1 bin]$ source ~/.bashrc 查看hadoop版本
[hadoop@hadoop1 ~]$ hadoop version
创建文件夹
文件夹的路径参考配置文件hdfs-site.xml里面的路径
[hadoop@hadoop1 ~]$ mkdir -p /home/hadoop/data/hadoopdata/name
[hadoop@hadoop1 ~]$ mkdir -p /home/hadoop/data/hadoopdata/dataHadoop的初始化
[hadoop@hadoop1 ~]$ hadoop namenode -format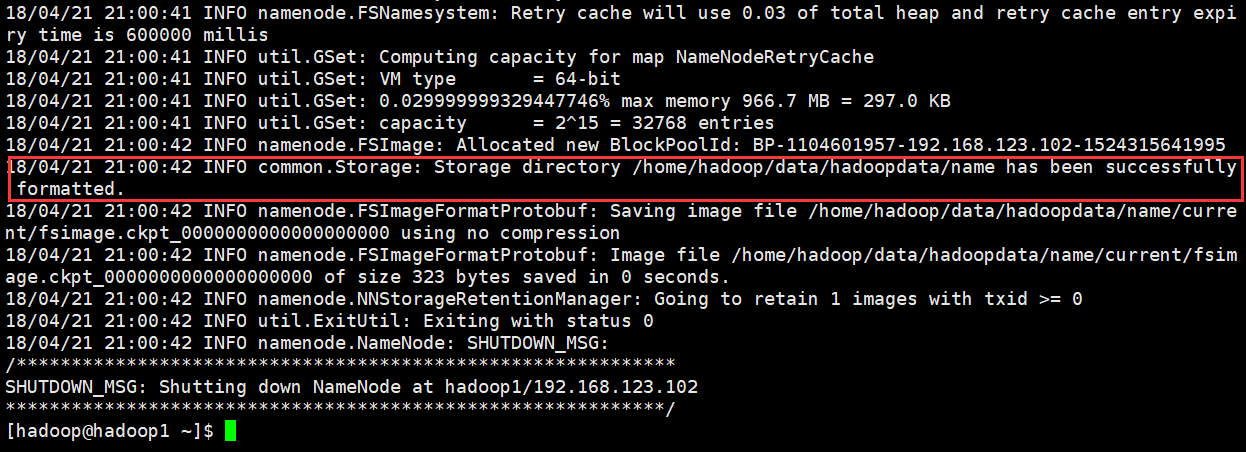
启动HDFS和YARN
[hadoop@hadoop1 ~]$ start-dfs.sh
[hadoop@hadoop1 ~]$ start-yarn.sh
检查WebUI
浏览器打开端口50070:http://hadoop1:50070
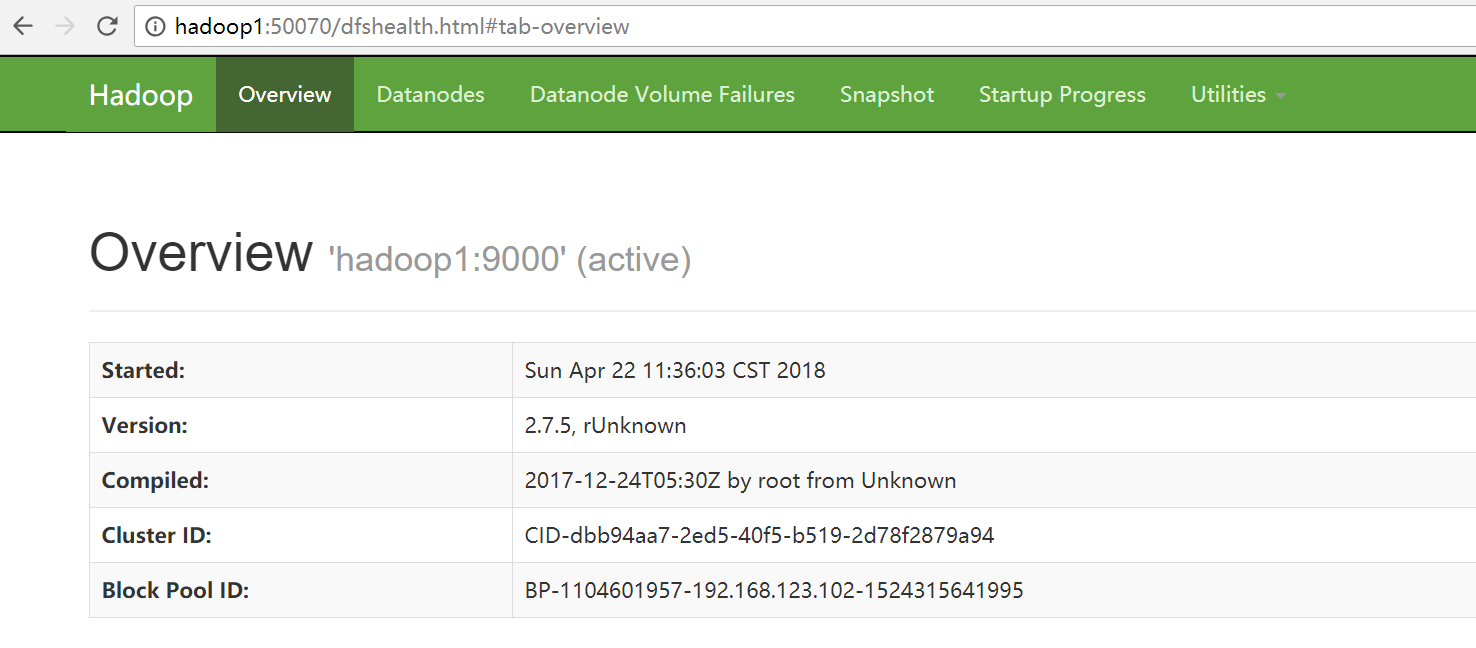
其他端口说明:
port 8088: cluster and all applications
port 50070: Hadoop NameNode
port 50090: Secondary NameNode
port 50075: DataNode
Scala的安装(可选)
使用root安装
下载
Scala下载地址http://www.scala-lang.org/download/all.html
选择对应的版本,此处在Linux上安装,选择的版本是scala-2.11.8.tgz
上传解压缩
[root@hadoop1 hadoop]# tar -zxvf scala-2.11.8.tgz -C /usr/local/配置环境变量
[root@hadoop1 hadoop]# vi /etc/profile#Scala
export SCALA_HOME=/usr/local/scala-2.11.8
export PATH=$SCALA_HOME/bin:$PATH保存并使其立即生效
[root@hadoop1 scala-2.11.8]# source /etc/profile验证是否安装成功
[root@hadoop1 ~]# scala -version
Spark的安装
下载安装包
下载地址:
http://spark.apache.org/downloads.html
http://mirrors.hust.edu.cn/apache/
https://mirrors.tuna.tsinghua.edu.cn/apache/
上传解压缩
[hadoop@hadoop1 ~]$ tar -zxvf spark-2.3.0-bin-hadoop2.7.tgz -C apps/
为解压包创建一个软连接
[hadoop@hadoop1 ~]$ cd apps/
[hadoop@hadoop1 apps]$ ls
hadoop hadoop-2.7.5 spark-2.3.0-bin-hadoop2.7
[hadoop@hadoop1 apps]$ ln -s spark-2.3.0-bin-hadoop2.7/ spark进入spark/conf修改配置文件
[hadoop@hadoop1 apps]$ cd spark/conf/复制spark-env.sh.template并重命名为spark-env.sh,并在文件最后添加配置内容
[hadoop@hadoop1 conf]$ cp spark-env.sh.template spark-env.sh
[hadoop@hadoop1 conf]$ vi spark-env.shexport JAVA_HOME=/usr/local/jdk1.8.0_73
export SCALA_HOME=/usr/share/scala-2.11.8
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.7.5
export HADOOP_CONF_DIR=/home/hadoop/apps/hadoop-2.7.5/etc/hadoop
export SPARK_MASTER_IP=hadoop1
export SPARK_MASTER_PORT=7077配置环境变量
[hadoop@hadoop1 conf]$ vi ~/.bashrc #SPARK_HOME
export SPARK_HOME=/home/hadoop/apps/spark
export PATH=$PATH:$SPARK_HOME/bin保存使其立即生效
[hadoop@hadoop1 conf]$ source ~/.bashrc启动Spark
[hadoop@hadoop1 ~]$ ~/apps/spark/sbin/start-all.sh 
查看进程
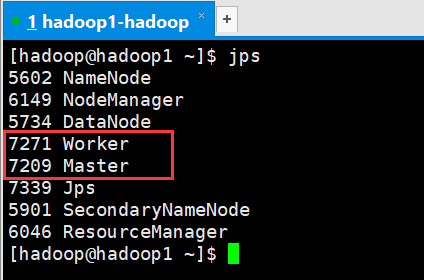
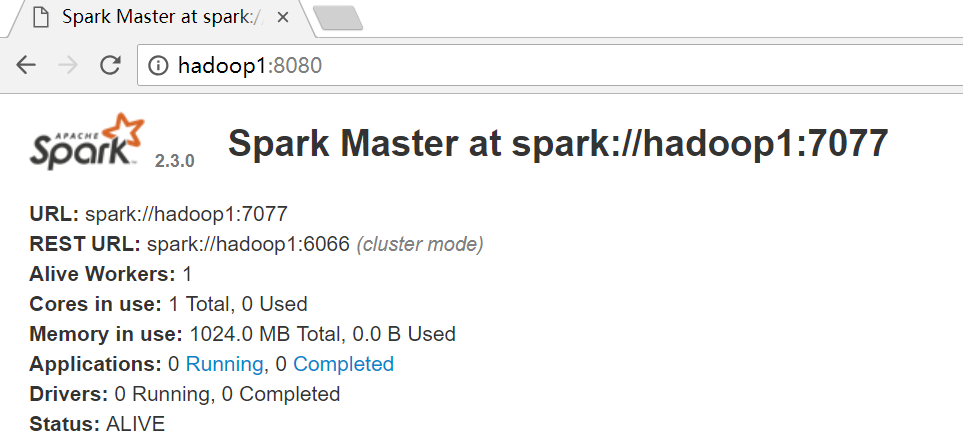
查看web界面
http://hadoop1:8080/
Spark学习之路 (五)Spark伪分布式安装[转]的更多相关文章
- Hbase学习记录(1)|伪分布式安装
概述 Hbase –Haddop Database 是一个高性能,高可靠性.面向列.可伸缩的分布式存储系统. Hbase利用HDFS作为文件存储系统,利用MapReduce来处理Hbase的海量数据, ...
- 【Hadoop学习之二】Hadoop伪分布式安装
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 伪分布式就 ...
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- Hadoop大数据初入门----haddop伪分布式安装
一.hadoop解决了什么问题 hdfs 解决了海量数据的分布式存储,高可靠,易扩展,高吞吐量mapreduce 解决了海量数据的分析处理,通用性强,易开发,健壮性 yarn 解决了资源管理调度 二. ...
- 一.Kylin的伪分布式安装
一.伪分布式安装kylin 2018年4月15日 15:06 安装需要的环境 1. hadoop集群环境:由于安装的是CDH5.14.0的版本,所以相关组件都是跟5.14.0相关 2. spark采用 ...
- HBase伪分布式安装(HDFS)+ZooKeeper安装+HBase数据操作+HBase架构体系
HBase1.2.2伪分布式安装(HDFS)+ZooKeeper-3.4.8安装配置+HBase表和数据操作+HBase的架构体系+单例安装,记录了在Ubuntu下对HBase1.2.2的实践操作,H ...
- 指导手册02:伪分布式安装Hadoop(ubuntuLinux)
指导手册02:伪分布式安装Hadoop(ubuntuLinux) Part 1:安装及配置虚拟机 1.安装Linux. 1.安装Ubuntu1604 64位系统 2.设置语言,能输入中文 3.创建 ...
- hadoop伪分布式安装之Linux环境准备
Hadoop伪分布式安装之Linux环境准备 一.软件版本 VMare Workstation Pro 14 CentOS 7 32/64位 二.实现Linux服务器联网功能 网络适配器双击选择VMn ...
- Hadoop开发第3期---Hadoop的伪分布式安装
一.准备工作 1. 远程连接工具的安装 PieTTY 是在PuTTY 基础上开发的,改进了Putty 的用户界面,提供了多语种支持.Putty 作为远程连接linux 的工具,支持SSH 和telne ...
随机推荐
- oracle面试基础
. 对于一个存在系统性能的系统,说出你的诊断处理思路 ). 做statspack收集系统相关信息 了解系统大致情况/确定是否存在参数设置不合适的地方/查看top event/查看top sql等 ). ...
- 浅谈ActionResult之FileResult
FileResult是一个基于文件的ActionResult,利用FileResult,我们可以很容易的将某个物理文件的内容响应给客户端,ASP.NET MVC定义了三个具体的FileResult,分 ...
- 用赋值表达式作为bool值
enum Status { stOk, stQuit, stError }; int main() { Status status; int n; bool b1 = (status = stOk); ...
- C++解析Json,使用JsonCpp读写Json数据
JSON(JavaScript Object Notation, JS 对象标记) 是一种轻量级的数据交换格式.通常用于数据交换或存储. JsonCpp是一个基于C++语言的开源库,用于C++程序的J ...
- 本地开发环境伪装成SSL连接的实现
本地ssl开发测试实现1,在外网服务器上使用测试域名和t.test.cn,用let's encrypt申请 证书并正常运行2,修改本地服务器host文件,将t.kennylee.vip指向127.0. ...
- Unity 编辑器开发SceneView GUI控制
前几天项目需要就做了个类似于Collider EditCollider的功能 下面是我做的效果 基础代码如下: public class ExportCFGInputWindow : EditorWi ...
- 用PHP&JS实现的ID&密码校验程序
声明:本程序纯粹是本人在学习过程中突发奇想做的,并未考虑任何可行性,实用性,只是留下来供以后参考. 前端页面 sign.html <!DOCTYPE html> <html> ...
- CSS选择器有哪几种?举例轻松理解CSS选择器
CSS选择器汇总(清爽版) 1.元素选择器 标签名{ } 2.id选择器 #id属性值{ } 3.类选择器 ·class属性值{ } 4.选择器分组(并集选择器) 作用:通过它可以同时选中多个选择器对 ...
- php利用七牛云的对象存储完成图片上传-高效管理图片
在搭建个人博客时,大家都会买一台云服务器.可是图片的存放一直是一个问题,冷月帮大家找到一个免费的第三方平台对象存储-七牛云.大家可以把图片上传到七牛云的对象存储,大大节约服务器的压力. 首先,大家在使 ...
- 谈谈:这次疫情对一个普通iOS开发者的影响!
“2019年已经很难了,2020年开局0-5那就更难了啊!”大家应该都很清楚,这次疫情对于国家的整体经济体系影响非常大,但是要说有多大,我也不了解,毕竟我只是个程序员!但是对iOS开发者影响有多大,我 ...